
热门标签
热门文章
- 1pytorch安装、环境搭建及在pycharm中的设置_pytorct在
- 2人工智能怎么入门好 Python编程开发如何学_python是如何开发人工智能
- 3DockerCompose的介绍以及使用docker-compose部署微服务_chmod +x /usr/local/bin/docker-compose
- 4【Java八股文总结】之面试题(一)_提供的实量数量(0)少于指定的占位符数(1) log.error
- 5Docker实战一 Docker部署微服务_docker部署微服务项目
- 6【Centos7搭建rustdesk-server】_rustdesk centos部署
- 7【SE】Week7 : Silver Bullet & Cathedral and Bazaar & Big Ball of Mud & Waterfall ...
- 8开发工具:推荐一款非常好用的SSH客户端WindTerm_windterm功能
- 9JVM虚拟机内存区域思维导图-------《深入理解Java虚拟机》2020第三版_深入理解jvm虚拟机第三版 思维导图
- 10MySQL left join、right join和join的区别_mysql left join 和join的区别
当前位置: article > 正文
Transformer使用RobertaTokenizer时解决TypeError: not NoneType_importerror: cannot import name 'robertatokenizer'
作者:知新_RL | 2024-03-16 12:37:55
赞
踩
importerror: cannot import name 'robertatokenizer' from 'transformers' (/hom
问题描述
在使用bert-base-uncased时,只需要下载四个文件链接下载就可以正常使用。但是当我用roberta时下载相同的四个文件会报错TypeError
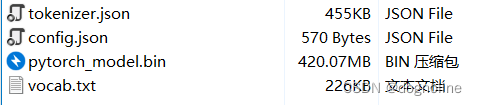
运行以下代码不报错,报错的话检查一下文件目录有没有出错
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(your_file_path)
- 1
- 2
使用roberta-large时,执行运行以下代码会报错
from transformers import RobertaTokenizer tokenizer = RobertaTokenizer.from_pretrained(your_file_path) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1742, in from_pretrained resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1858, in _from_pretrained tokenizer = cls(*init_inputs, **init_kwargs) File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/models/roberta/tokenization_roberta.py", line 171, in __init__ **kwargs, File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 185, in __init__ with open(merges_file, encoding="utf-8") as merges_handle: TypeError: expected str, bytes or os.PathLike object, not NoneType

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
解决
一般出现这个错误就是在路径下没有需要的文件,经过检查发现Roberta比Bert要多一个文件,我之前没有下载,现在重新下载放到目录中去。
注意: 路径是包含这五个文件的文件夹目录
下载官方文档中的merges.txt文件

from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(your_file_path)
- 1
- 2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/249525
推荐阅读
相关标签

