
- 1【数据库】索引 视图 触发器 分页查询
- 2WPF Command
- 3MathType7最新软件产品秘钥2024中文版_mathtype7.8产品密钥
- 4Android手机连接电脑adb调试配置
- 5利用人工智能模型学习Python爬虫_如何利用人工智能生成python爬虫代码教程
- 6UE4(Unreal Engine 4)基本概念_unreal4
- 7CLion 的使用(一)_clion删除源文件时出现的两个选项是什么意思
- 8NTFS For (mac读写NTFS磁盘工具)V14.2.359简体中文版_ntfs write mac 14
- 9Android兼容之鸿蒙系统使用Profiler分析系统时Crash_android studio profiler使用崩溃
- 10如何在Android studio创建虚拟机_android studio虚拟器
Sora会改变自动驾驶的终局吗?
赞
踩

本文授权转载自-智车星球微信公众号
作者 | 邓娅
编辑 | 朱雅茜
这场AI热给自动驾驶带来的新课题,已然摆在眼前。
“我们团队目前最重要的工作就是复现Sora”,清华大学助理教授剑寒(化名)告诉「智车星球」,他的主要研究方向是机器人相关的计算机视觉,“不止我们,从2月16日(Sora发布当天)开始,基本所有在这个赛道的人都在转方向。”
关于原子弹,最有价值的情报就是它可以被造出来。
这句话再次被Sora印证。
不过在剑寒看来,这很正常,“科研界可能有100种前瞻方向,不可能都尝试,OpenAI出来的效果这么好,大家开始学习他的做法,这没有什么问题。就像世界上有这么多材料,尝试到用钨做灯丝呈现出了很好的效果,大家都会跟进。”
除了技术端,资本端的跟进也很迅速。
券商的朋友甚至等不及春节假期结束就找到我,询问是否能介绍相关专家交流一下Sora对自动驾驶的影响。
这场关于“大模型+自动驾驶”能否产生新的化学反应的讨论,再次因为OpenAI带来了新一轮的热度。
1
—
新的仿真路线
此次Sora的推出,展示出了明显优于此前生成式视觉模型的成果,这也让不少人对其在自动驾驶仿真领域的应用产生了期待。

△知名连续创业者Gabor Cselle在测试关于美丽东京白雪皑皑的提示词后,得出的结论是Sora在长镜头上表现得更好。
在51Sim CEO鲍世强看来,Sora 已经展现出了多视角长时长下一致性较高的图像,场景的真实度和细节也很好。
“其实从仿真的角度看,生成式视频模型做的事和游戏引擎没有本质区别,只是一个是更可控的显式的,一个是数据驱动的隐式的。游戏引擎的一个劣势是如果要达到较强的真实感门槛较高,需要建模大量的高质量资产,优点是可控制性和可编辑性较强,世界完全受控。但 Sora的可编辑性以及可控性从目前的展示来看还不确认,我认为挑战还是比较大。” 鲍世强解释道。“
目前,合成数据主要分为三个路线——物理仿真与图形渲染路线、基于神经辐射场(NeRF、3DGaussion 等)的场景重建路线以及基于世界模型的生成路线。

“基于世界模型的生成路线还处于发展的早期阶段,与视频创作领域不同,智驾场景落地确定性要求比较高,需要呈现出一致性和物理规律,如何可控的生成更多有价值的Corner Case 还有待深入探讨,但后续发展空间是巨大的。“ 鲍世强告诉[智车星球]。
目前,在这条垂直赛道上,国内已经有企业在做相关研究。
去年9月,极佳科技和清华大学的研究人员就推出了真实世界驱动的自动驾驶世界模型DriveDreamer。
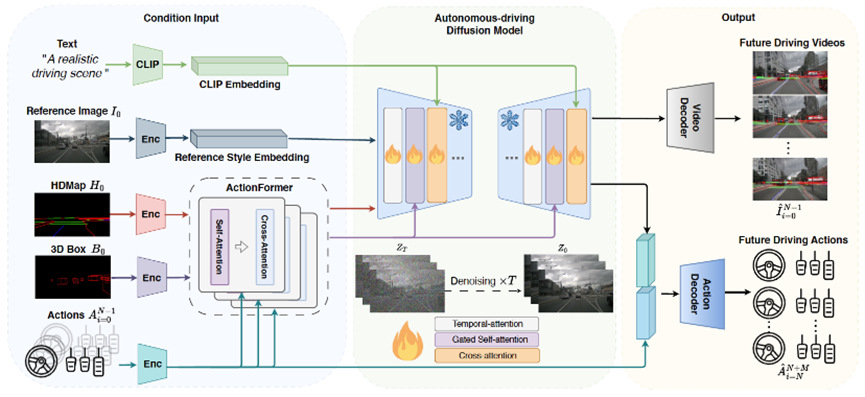
△DriveDreamer 总体结构框图
据极佳科技CEO黄冠介绍,DriveDreamer使用了数十亿图像数据预训练的 Diffusion model 作为基础模型,并利用百万张自动驾驶场景图像帧进行模型训练,在此过程中引入了数十亿可学习参数。
DriveDreamer能够生成符合交通结构化信息的视频;可以根据文本描述改变生成视频的天气、时间等;可以根据输入的驾驶动作生成不同的未来驾驶场景视频。
“现在已经有不少客户基于DriveDreamer做数据生成、闭环仿真,Sora的出现也让我们对这个方向更确定。当然,目前还有准确性、精细度等各方面的工程问题需要继续提升。” 黄冠解释道。
2
—
大模型“加速”自动驾驶
虽然文本视频生成大模型完全进入自动驾驶量产环节还有不少需要提升的地方,但大模型对于自动驾驶是否有加成,在业内人士看来是一个需要做质疑的讨论。
“在过去一年多的时间内,这已经是被广泛验证的事情。”长城汽车AI Lab负责人杨继峰告诉「智车星球」,“大模型在自动驾驶领域,首先被证实效果的领域是数据重建,基于此诞生了新的场景生成在仿真领域的机会;Sora无疑规模更大也更通用,但是在自动驾驶领域的落地还需要进一步探索,特别是针对空间和语音应用。然后影响到的end to end,以及最近很热的LLM-based driving agent类型的大模型算法架构。”
简单来说,就是通过增加推理能力来处理复杂场景从而提高性能,并通过极大地简化模型开发来降低成本。
自动驾驶软件的初创公司Ghost Autonomy(曾获得OpenAI创业基金500万美元投资,旨在将大规模、多模态的大语言模型引入自动驾驶领域)的模型工程师Prannay Khosla也在文章《One Model To Rule The Road?》中提到,大语言模型(LLMs,广义上被称为基础模型)正在改变自动驾驶开发的多个环节。
首先是在理解及标注数据层面,Prannay Khosla提到模型工程的核心是数据问题,即更好的数据产生更好的模型,“更好的数据”不仅仅是关于规模,还有完备性。训练集必须代表现实世界中可能遇到的每一个概念,例如,每一种车道标记类型、每一种道路配置、每一种障碍物、建筑类型等。收集所有这些数据不仅昂贵,而且还需要进行复杂的数据挖掘,从而标注相关样本以开发出完备的训练集。人类需要数十万小时来开发这些训练集,但是它们仍然不完备。
而大型模型在解决这个问题上已被证明特别有用,能够通过语言接口对复杂问题进行zero-shot泛化(即解决从未在相关数据集上训练过的新任务),以更低的代价对数据集进行整理和标注。在这种应用中,大型模型可能不用于最终产品的推理,但用于帮助训练最终交付的模型。
其次,大模型能提升可解释性。早期的自动驾驶被庞大的代码库所主导,导致在复杂场景中难以进行调试。LLMs提供了一种与神经网络中的注意力层进行交互的新途径,使得在驾驶系统内部实现提示和可解释性成为可能。同样,这里的大型模型是一个工具,帮助开发和解释在运行时部署的其他模型。
而随着LLMs显示出可以真正“理解世界”的潜力,Prannay Khosla认为这种新的理解水平可以扩展到驾驶任务,使模型无需显式训练(Explicit Training),就能安全自然地驾驭复杂场景,这为解决“长尾问题”提供了新的路径。LLMs还显示出在决策中使用大量上下文信息的能力。
最后,Prannay Khosla也提到了基于action的生成式视觉模型,例如GANs和Diffusion models,可以在线创建逼真的驾驶场景,可以用于有效的仿真。
但同样,Prannay Khosla也提到尚不完全清楚大型视觉模型是否能生成有意思的Corner Case场景。像素级仿真渲染对于构建规划器和测试道路预测模型非常有用,但对于测试和制造自动驾驶汽车所需的规模来说,计算效率可能不高。
3
—
自动驾驶终局在哪?
目前,视频生成方法主要分为两类:基于Transformer和基于扩散模型。
前者源于大型语言模型方案,通常是采用对下一个Token的自回归预测或对masked Token的并行解码来生成视频。
利用Transformer进行Token预测可以高效学习到视频信号的动态信息,并可以复用大语言模型领域的经验,因此,基于Transformer的方案是学习通用世界模型的一种有效途径。
扩散模型是近两年来视频生成领域的研究热点,是“文生图”的代表,相关研究成果也有不少。比如在2D扩散模型潜在空间的基础上引入时间维度,并使用视频数据进行微调,有效地将图像生成器转变为视频生成器,实现高分辨率视频合成;有基于预训练的2D扩散模型构建了级联视频扩散模型;也有基于Transformer的扩散模型改进了视频生成。
不过,基于扩散模型的方法难以在单一模型内整合多种模态。此外,基于扩散模型的方案难以拓展到更大参数,因此很难学习到通用世界的变化和运动规律。
Sora则是结合了Transformer 和 Diffusion 两个模型,在过去DALL.E和GPT的研究基础上,采用了DALL.E 3中的重述技术。因此能更好遵循用户的文本描述,并且有极强的扩展性。
再简单些,OpenAI用GPT的能力做视频文本对齐,通过将多个高分辨率视频素材进行降维处理,然后密集训练,最后就是我们熟悉的大力出奇迹。
阳光底下无新鲜事,虽然没有网络大小、用了哪些数据、具体怎么训练等细节,但从OpenAI公布的报告中,并没有“武功秘籍”般的存在,思路和方法都是大家熟悉的东西。
但AI热与明星公司OpenAI的结合,再加上关于技术本身之外的讨论,让Sora的热度来到了极高的位置,也引出了大家对自动驾驶终局的讨论。
2月18日,马斯克在科技主播 @Dr.KnowItAll 一条主题为“OpenAI 的重磅炸弹证实了特斯拉的理论”的视频下留言,表示“特斯拉已经能够用精确物理原理制作真实世界视频大约一年了”。
随后马斯克在 X 上转发了一条 2023 年的视频,内容是特斯拉自动驾驶总监 Ashok Elluswamy 向外界介绍特斯拉如何用 AI 模拟真实世界驾驶。
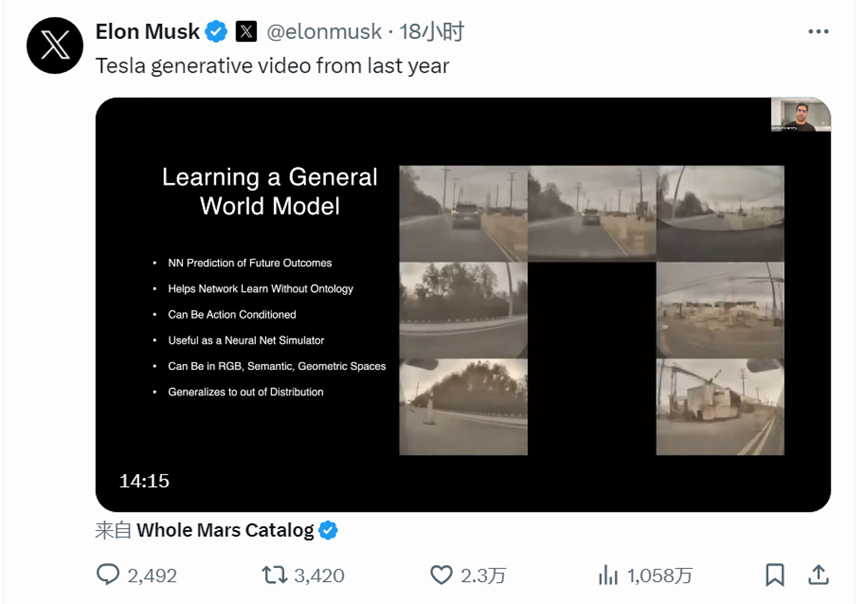
训练 AI 理解和生成一个真实的场景或世界,是特斯拉与Sora一致的训练思路。
过去十几年,虽然技术在不断迭代,但自动驾驶的本质依然是通过海量数据教会系统开车,即便目前在不少环节已经有大模型加入,也只是加速了过程,并没有解决自动驾驶研发过程中遇见的问题。
“但是自动驾驶从世界感知进入到通用认知以后,自动驾驶的本质很可能就会发生变化,那就是Al Agent——LLM+Memory+Tool+Planning。自动驾驶就变成了怎么教一个通用智慧体开车的问题,通过大模型的预训练去学会推理、记忆等能力和道路驾驶等通用知识,通过SFT去强化场景驾驶行为,通过RL把数据闭环变成奖励模型。这跟当前依赖海量数据和Corner Case的思路完全不同。” 杨继峰说道。
“(自动驾驶)最终可能就是一个语言模型加世界模型。”黄冠也提出了类似观点。
可以说,对于自动驾驶,Sora这次的小试牛刀,不仅展示出了相关技术在自动驾驶仿真领域的应用潜力,更是让行业看到大模型对真实世界有了理解和模拟之后,引发了对于自动驾驶发展方向的思考。
这场AI热给自动驾驶带来的新课题,已然摆在眼前。

