
- 1Java——IO流
- 2Leaflet中多边形Polygon事件监听失效的可能原因_leaflet 多边形点击事件
- 3Angular 监听服务(Service)中的数据变化_angular监听数据变化
- 4IOS github客户端操作流程 超详细_ios git 客户端
- 5GPUImage 原理_didoutputsamplebuffer gpuimage
- 6超网、IP 聚合、IP 汇总分别是什么?三者有啥区别和联系?
- 7【重难点】【MySQL 09】面试场景题_mysql场景题
- 8【NLP笔记】文本分词、清洗和标准化
- 9Android Intent action有什么用???
- 10基于VSCode的Linux内核调试环境搭建以及start_kernel跟踪分析_vscode linux内核开发
基于PyTorch的图像识别_pytorch图像识别
赞
踩
前言
图像识别是计算机视觉领域的一个重要方向,具有广泛的应用场景,如医学影像诊断、智能驾驶、安防监控等。在本项目中,我们将使用PyTorch来开发一个基于卷积神经网络的图像识别模型,用来识别图像中的物体。下面是要识别的四种物体。

一、项目内容
图像识别的过程一般可以分成以下几个步骤:建立一个包含图像和对应标签的数据集,将这些图像输入神经网络,对它们进行训练,得到模型文件,当输入不在训练集中的图像(新图像数据),对图像进行处理(包括图像灰度化、图像滤波去噪声、图像腐蚀、轮廓提取等操作),然后与模型文件进行匹配,最后得到预测结果。基本流程如图所示。
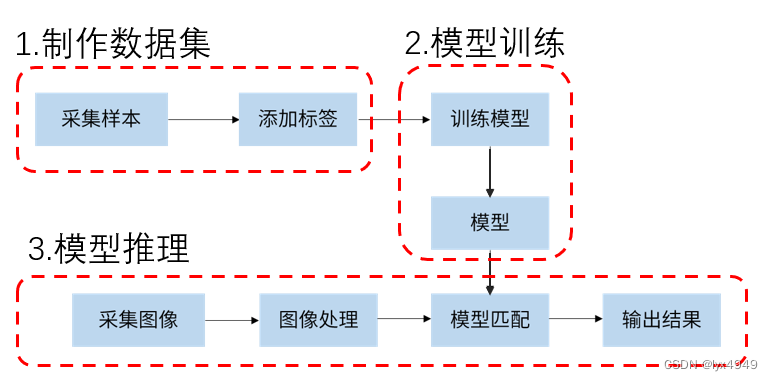
本项目分为三个主要部分:制作数据集(采集与预处理)、模型构建和训练、模型推理。
首先,我们将对数据进行预处理,包括图像数据集采集、图像增强、数据划分等操作。然后,我们将使用PyTorch中的卷积神经网络构建一个有效的图像识别模型,并使用训练数据对模型进行训练。最后,我们将使用训练好的模型对新的图像进行分类预测。
二、知识链接
(此部分是关于Pytorch如何实现图像识别的流程介绍,可以直接跳到下一步)
在 PyTorch 中,图像识别通常使用卷积神经网络(Convolutional Neural Network,简称 CNN)模型进行训练和推理。CNN 是一种专门用于处理图像数据的神经网络模型,它可以自动从原始图像中提取特征信息,并完成分类、检测、分割等任务。
在使用 PyTorch 进行图像识别时,通常需要进行以下步骤:
- 图像采集及数据预处理
收集到图像数据后,要将原始图像数据进行预处理,包括图像大小调整、灰度化、归一化等操作,以便于输入到神经网络中进行训练或推理。
- 定义模型(训练模型过程)
使用 PyTorch 提供的高级接口,定义一个卷积神经网络模型。模型通常由若干个卷积层、池化层、全连接层等组成,每个层都有多个参数需要进行训练。
- 定义损失函数(训练模型过程)
使用 PyTorch 提供的损失函数,定义一个用于衡量模型预测结果与真实标签之间差距的函数。常见的损失函数包括交叉熵损失、均方误差损失等。
- 定义优化器(训练模型过程)
使用 PyTorch 提供的优化器,定义一个用于更新模型参数的优化算法。常见的优化器包括随机梯度下降(SGD)、Adam 等。
- 训练模型(训练模型过程)
将预处理后的图像数据输入到模型中进行训练,使用定义的损失函数和优化器对模型参数进行优化,直到模型收敛或达到一定的训练轮数。
上述模型训练过程
- 模型推理
将预处理后的图像数据输入到已经训练好的模型中进行推理,得到模型对输入图像的预测结果。通常使用 softmax 函数将预测结果转换为概率分布,以便于进行分类。
本项目中将使用深度学习中的卷积神经网络模型 ResNet18 进行模型推理。大致的推理过程:在推理前,将输入的图像进行预处理,包括将图像变换为指定大小、转换为张量数据并进行归一化等操作。然后将预处理后的图像数据输入到 ResNet18 模型中进行推理。推理结果是一个概率向量,表示输入图像属于每个分类的概率,通过计算概率向量中的最大值,可以得到模型预测出的最佳分类标签。
三、项目准备
1.摄像头:能够拍摄到图像的工具,建议外界摄像头能够拍摄到物体的图片。
2.如果没有外接摄像头,可以自己手动采集相关的物体图片(例如鸟、鸭、猪、猫)
3.可以看最后我上传的附件程序
四、项目实施
任务一:数据集准备
收集数据集是实现图像分类的第一步,可从公共数据集或互联网上收集相关的图像数据,也可以自己拍摄或录制图像数据。其次,要对采集到的图像进行一系列的预处理,如缩放、旋转、裁剪等,以便后续模型训练的需要。
1.本程序分为2部分:①采集数据集 ②拍摄一张图像(等到训练好后使用)
① 采集数据集:使用外接摄像头拍摄物体的图片并生成4张曝光度不同的灰度图片存放到raw文件夹,然后把这4张图片分别旋转20次,每次18°
②拍摄一张图像此部分用于训练好模型之后使用
#collect_image.py程序 import cv2 import os import numpy as np #采集物体4张曝光度不同的图像,然后旋20次,每次18° def Collect_Datasets(): # 创建文件夹 if not os.path.exists('raw'): #原始4张曝光度图片存放路径 os.makedirs('raw') if not os.path.exists('out'): #旋转后生成图片的路径 os.makedirs('out') image_name = input("请输入物体名称:") #给拍摄物体命名 if not os.path.exists(image_name): os.makedirs(f'data/train/{image_name}') #把物体数据集存放到data/tarin文件夹 #采集物体4张曝光度不同的图像 # 调用摄像头拍摄1张图片 cap = cv2.VideoCapture(1) ret, frame = cap.read() cap.release() # 灰度化 gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 获取图像宽度和高度 height, width = gray_frame.shape # 保存第一张灰度图片到raw文件夹 cv2.imwrite('raw/exposure_1.jpg', gray_frame) # 生成其他3张曝光度不同的图片 for i in range(3): exposure_adjusted = cv2.convertScaleAbs(gray_frame, alpha=(i+1)*0.65, beta=0) cv2.imwrite(f'raw/exposure_{i+2}.jpg', exposure_adjusted) #其他3张不同曝光度的图片也存放到raw文件夹 #旋转图片 for i in range(20): angle = i * 18 # 每次旋转18° for j in range(4): image_path = f'raw/exposure_{j+1}.jpg' #给旋转的图片命名 img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) #读取raw文件夹内图片 #cv2.getRotationMatrix2D()函数用于获取图像旋转的变换矩阵 #获取一个变换矩阵 M,该矩阵可以将图像围绕 (width/2, height/2) 旋转 angle 度 M = cv2.getRotationMatrix2D((width/2, height/2), angle, 1) rotated = cv2.warpAffine(img, M, (width, height)) #对图像进行旋转操作 out_path = f'data/train/{image_name}/{image_name}_{i*4+j+1}.jpg' #图片存放路径,存放到以你为物体命的名的文件夹 cv2.imwrite(out_path, rotated) #拍摄一张需要验证的物体图像,用于训练完验证时候使用 def Verify_Image(): print("拍摄一张图片验证数据集!") cap = cv2.VideoCapture(1) ret, frame = cap.read() cv2.imshow("image", frame) print("关闭窗口即拍摄结束!") cv2.waitKey()# 等待按键触发 cap.release() # 灰度化 gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 保存灰度图片 cv2.imwrite('image/image.jpg', gray_frame) if __name__ == "__main__": collect_picture = input("请输入数字:1.采集数据集 2.采集一张验证:") if collect_picture == "1": Collect_Datasets() #制作数据集 elif collect_picture == "2": Verify_Image() #验证时采集一张图片的时候调用

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
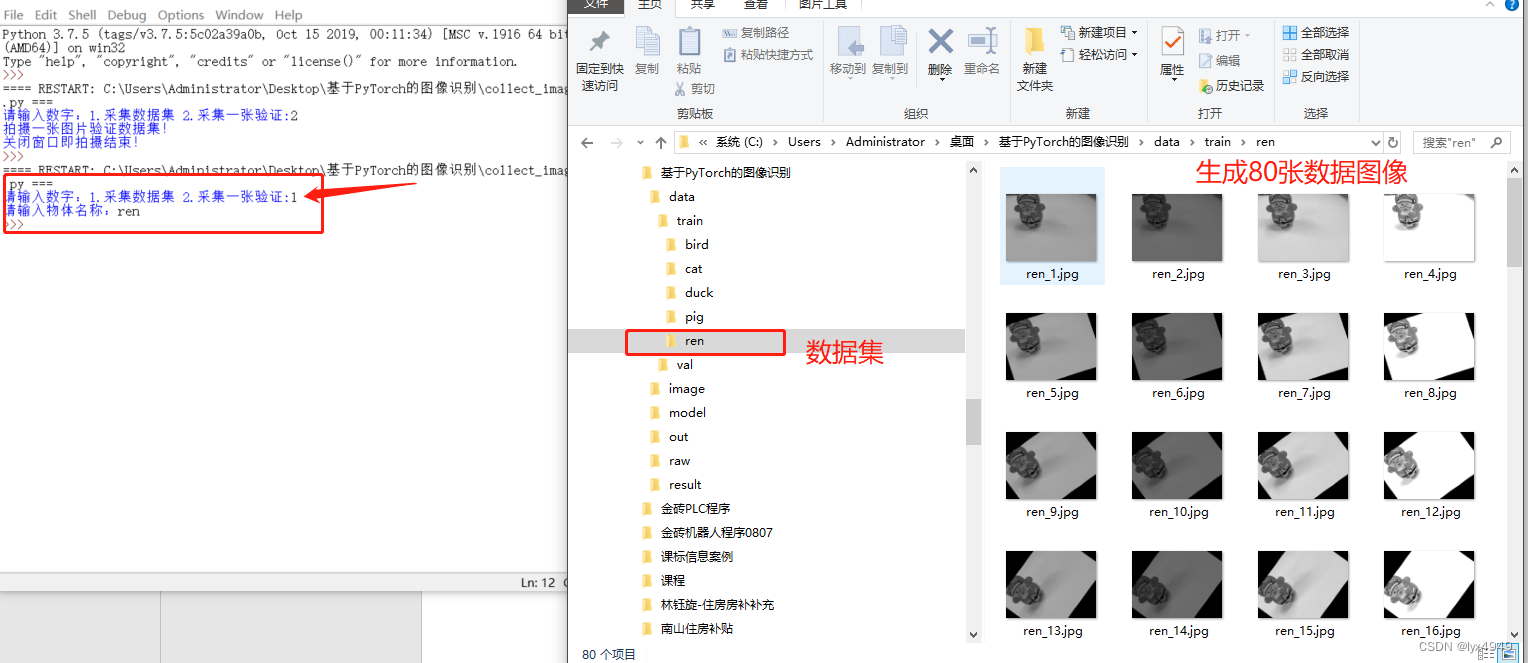
运行效果:假设我这里需要增加一个物体的数据集,执行程序后,输入“1”,执行过程有提示,执行完成后,会生成对应物体的文件夹,里面会有生成的80张数据集,是4张不同曝光度图片,分别旋转20次后得到的。
任务二:模型训练
在制作好数据集后,需要使用深度学习算法进行模型训练,本项目使用PyTorch框架来训练图像分类模型,包括数据预处理、模型定义、模型训练、模型保存等过程。
为了能够更快的得到模型,我们使用一个预训练好的ResNet-18网络模型来进行图像分类、目标检测等任务,而不需要从头开始训练模型,从而节省训练时间和计算资源。resnet18.pth已放置在model文件夹中。
关于程序的解释,看代码注释。其中通用训练模型函数train_model(),用于训练和验证一个给定的深度学习模型。该函数接受一个模型(model)、一个损失函数(criterion)、一个优化器(optimizer)和一个学习率调度器(scheduler),以及一个可选的训练的轮数(num_epochs,默认参数25),在给定的训练数据集和验证数据集上训练模型,并返回训练好的模型
#train.py程序 import os import time import torch import torchvision from torchvision import datasets, models, transforms import matplotlib.pyplot as plt import numpy as np import copy import glob import shutil import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler # 数据集存放路径 path = './data/' # 遍历数据集 #将训练集数据中的数据随机抽取作为验证集数据,并将验证集数据复制到新建的文件夹中,以便于后续的模型训练和评估 for folder in os.listdir('./data/train'): # 图片格式为.jpg或.png jpg_files = glob.glob(os.path.join(path,"train", folder, "*.jpg")) png_files = glob.glob(os.path.join(path,"train", folder, "*.png")) files = jpg_files + png_files # 统计训练集数据 num_of_img = len(files) print("Total number of {} image is {}".format(folder, num_of_img)) # 从训练集里面抽取100%作为验证集,将训练集中的所有数据进行随机打乱,并计算出需要抽取的数据数量 shuffle = np.random.permutation(num_of_img) percent = int(num_of_img * 1) print("Select {} img as valid image".format(percent) ) # 新建val文件夹存放验证集数据 path_val = os.path.join(path,"val",folder) if not os.path.exists(path_val): os.makedirs(path_val) # 把训练集里面抽取100%的数据复制到val文件夹 # shuffle()方法将序列的所有元素随机排序 for i in shuffle[:percent]: print("copy file {} ing".format(files[i].split('\\')[-1])) shutil.copy(files[i], path_val) # 数据增强与变换 ''' 定义一个数据增强与变换的函数data_transforms,包括训练集和验证集两部分。 使用transforms.Compose()方法将多个图像变换组合起来,以增强训练集的多样性和鲁棒性。 在训练深度神经网络时,数据增强是提高模型性能和泛化能力的重要手段之一。 通过多个随机变换组合起来,可以使训练集数据更加丰富多样,从而降低模型的过拟合风险 ''' data_transforms = { # 训练集 'train':transforms.Compose([ transforms.Resize((224,224)), #调整输入图像的大小,以适应模型的输入尺寸 transforms.Grayscale(3), #将输入图像转换为三通道的灰度图像,以便于在RGB模型上进行训练 transforms.RandomRotation(5), #对输入图像随机进行旋转 transforms.RandomVerticalFlip(0.5), #对输入图像进行垂直翻转,增加模型对镜像变换的鲁棒性 transforms.RandomHorizontalFlip(0.5), #对输入图像进行水平翻转,增加模型对镜像变换的鲁棒性 transforms.ToTensor(), #将输入图像转换为PyTorch张量 transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) #对输入图像进行标准化处理 ]), # 测试集,同上 'val':transforms.Compose([ transforms.Resize((224,224)), transforms.Grayscale(3), transforms.RandomRotation(5), transforms.RandomVerticalFlip(0.5), transforms.RandomHorizontalFlip(0.5), transforms.ToTensor(), transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ]) } # 加载数据 data_dir = './data/' # 使用datasets.ImageFolder()方法加载数据集,并对训练集和验证集分别进行数据增强和变换操作 image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train','val'] } print(image_datasets) # 使用torch.utils.data.DataLoader()方法构建训练集和验证集的数据迭代器 dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=len(os.listdir('./data/train')), #batch_size参数表示每个批次的样本数量 shuffle=True, #shuffle参数表示是否对数据进行打乱 num_workers=0) for x in ['train', 'val'] } #num_workers参数表示数据加载的并行数 print(dataloaders) # 统计训练集和验证集的数据集大小 dataset_sizes = {x:len(image_datasets[x]) for x in ['train', 'val']} print(dataset_sizes) # 获取数据集的类别信息 class_names = image_datasets['train'].classes print(class_names) # 判断GPU是否可用,如果当前计算机支持GPU,则使用GPU作为计算设备;否则使用CPU作为计算设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) # 通用训练模型函数,参数说明:模型、损失函数、优化器、学习率调度器、可选的训练轮数 ''' 该函数首先对模型进行深拷贝,以备后续使用。然后,对于给定的训练轮数,它循环进行训练和验证阶段。在每个阶段中, 该函数设置模型的工作模式(训练模式或评估模式)并迭代输入数据进行训练或验证。在训练阶段, 该函数使用给定的优化器和损失函数计算模型参数的梯度,并更新模型的参数。在验证阶段, 该函数仅计算模型的输出和指标,不进行参数更新。在每个阶段结束时, 该函数打印阶段的损失和准确率,并记录最佳模型的权重和准确率。最后返回训练好的模型,并加载最佳模型的权重 ''' def train_model(model, criterion, optimizer, scheduler, num_epochs=25): since = time.time() # 返回当前时间的时间戳 # deepcopy为深拷贝,即创建一个新的对象,完全复制原始对象及其所有子对象。 # model.state_dict是PyTorch中的一个方法,返回一个字典对象,将模型的所有参数映射到它们的张量值 best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 # 显示当前的训练进度 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) # 输出训练进度 print('-' * 10) # 每个epoch都有一个训练和验证阶段 for phase in ['train', 'val']: if phase == 'train': # PyTorch中用于更新优化器的学习率 scheduler.step() model.train() # 设置模型的工作模式:训练模式,模型会更新参数 else: model.eval() # 设置模型的工作模式:评估模式,模型不会更新参数 running_loss = 0.0 # 用于记录当前epoch的累计损失 running_corrects = 0 # 用于记录当前正确分类的数量 # 迭代数据 for inputs, labels in dataloaders[phase]: # GPU加速,inputs、labels用于将输入数据和标签数据移动到指定的设备上,例如CPU或GPU inputs = inputs.to(device) labels = labels.to(device) # 清空梯度,在每次优化前都需要进行此操作 optimizer.zero_grad() # torch.set_grad_enabled在训练模式下启用梯度计算,而在评估模式下禁用梯度计算 with torch.set_grad_enabled(phase == 'train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) # 返回输入张量在指定维度上的最大值及其对应的索引 loss = criterion(outputs, labels) # 后向 + 仅在训练阶段进行优化 if phase == 'train': # 反向传播:根据模型的参数计算loss的梯度 loss.backward() # 调用Optimizer的step函数使它所有参数更新 optimizer.step() running_loss += loss.item() * inputs.size(0) # 获取损失值和输入数据的数量 running_corrects += torch.sum(preds == labels.data) # 记录当前epoch中正确分类的数量 # dataset_sizes[phase]:该变量用于获取数据集在当前阶段中的大小 epoch_loss = running_loss / dataset_sizes[phase] #当前epoch的平均损失 epoch_acc = running_corrects.double() / dataset_sizes[phase] # 当前epoch的准确率 # 打印当前epoch的损失和准确率,以实时监控模型的训练状态 print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # 前阶段的名称、当前epoch的平均损失、当前epoch的准确率 if phase == 'val' and epoch_acc > best_acc: #更新最佳模型参数 best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since # 输出整个训练过程的时间 print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) # 用于输出最佳验证准确率,best_acc是训练过程中被更新为模型在验证集上的最佳准确率 print('Best val Acc: {:4f}'.format(best_acc)) # 用于加载模型的状态字典,即将最佳模型的参数设置为给定的参数字典 model.load_state_dict(best_model_wts) return model # 主程序入口使用ResNet-18模型对图像进行分类,并训练模型并保存模型参数。 if __name__ == "__main__": # 用于初始化ResNet-18 模型 model_ft = torchvision.models.resnet18(pretrained=False) # 加载resnet18网络参数 model_ft.load_state_dict(torch.load('./model/resnet18.pth')) # 提取fc层中固定的参数 num_ftrs = model_ft.fc.in_features # 重写全连接层的分类 model_ft.fc = nn.Linear(num_ftrs, len(os.listdir('./data/train'))) model_ft = model_ft.to(device) # 这里使用分类交叉熵Cross-Entropy作为损失函数,动量SGD作为优化器 criterion = nn.CrossEntropyLoss() # 初始化优化器 optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # 每7个epochs衰减LR通过设置gamma = 0.1 exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) #调用通用训练模型的函数,返回训练得到的最佳模型 ''' 下面调用了定义好的模型的训练函数。最后一个参数num_epochs用于指定训练模型的轮数,训练模型的轮数是一个重要的参数, 它决定了模型训练的时间和精度。训练轮数太短可能会导致模型欠拟合,训练轮数太长则可能会导致模型过拟合。 因此,在选择训练轮数时需要进行适当的调整和优化,以得到最佳的模型性能。 在这个例子中,由于数据集较小,所以训练轮数设置为 2 轮,在实际应用中, 需要根据数据集的大小、复杂度和模型的性能等因素进行调整,以便得到更为准确和实用的模型。 ''' model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=2) # 保存模型 torch.save(model_ft.state_dict(), './model/dobot20230810.pkl')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
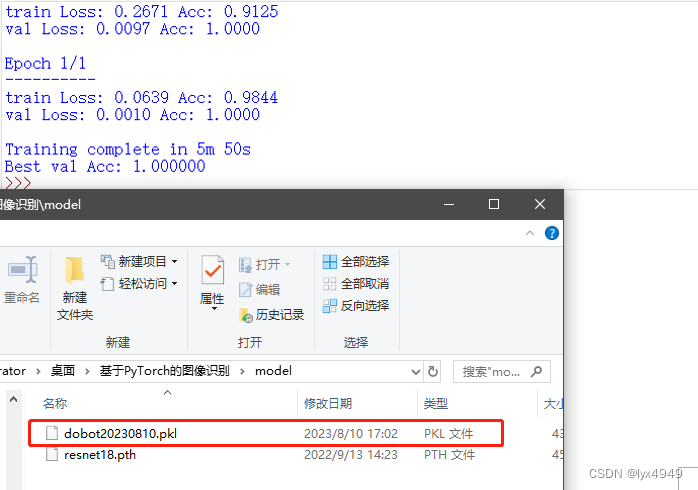
运行结果:
程序运行后,输出了模型的详细信息,如图所示。其中 train Loss 表示训练集上的损失函数值,train Acc 表示训练集上的准确率,val Loss 表示验证集上的损失函数值,val Acc 表示验证集上的准确率。可以在运行窗口看到训练集上的准确率和验证集上的准确率都接近甚至达到了 100%,这表明模型在训练集和验证集上都表现非常好,没有出现过拟合的情况,可以用于实际的图像分类任务中。最后,该模型的训练时间为 5 分 50 秒
任务三:模型推理
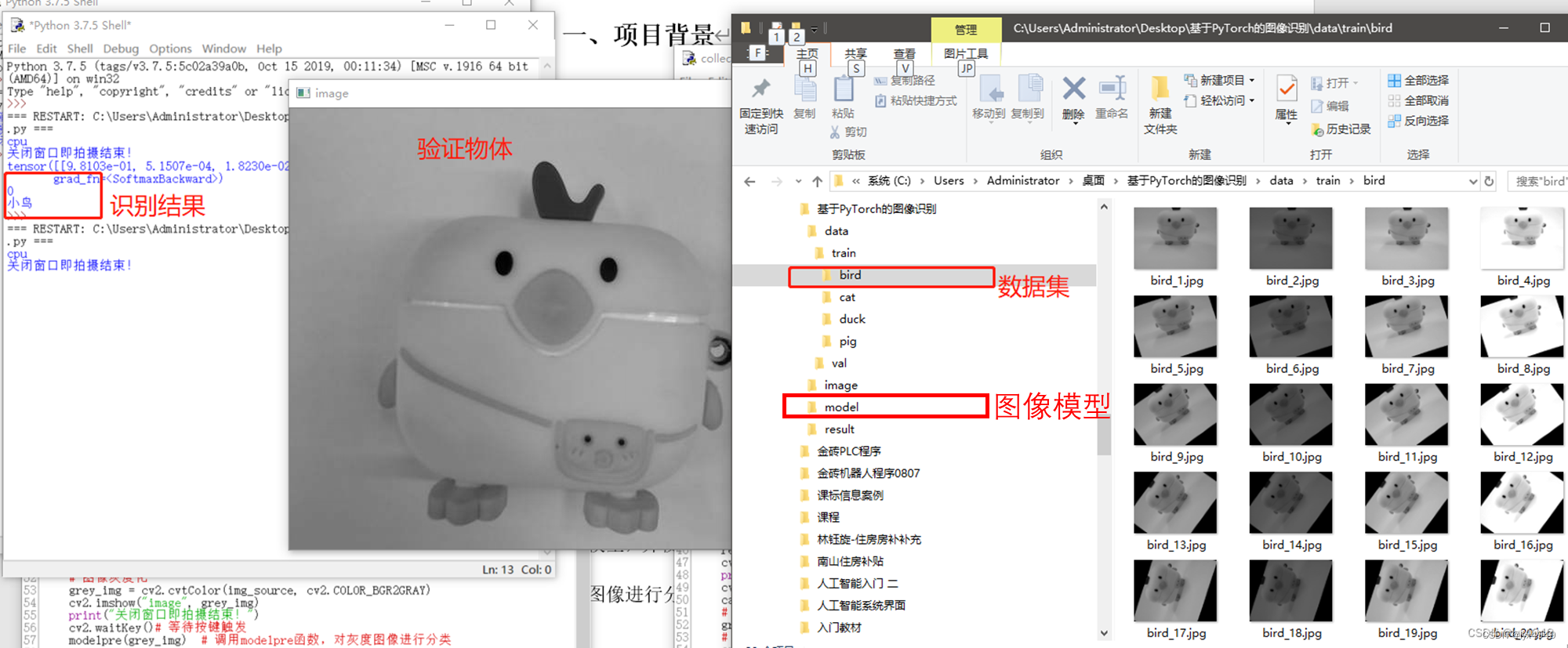
模型训练完成后,需要对新的图像进行分类。使用PyTorch框架,加载训练好的图像分类模型dobot20230810.pkl,可以对输入的灰度图像进行分类,判断其属于四个类别(‘小鸟’,‘小猫’,‘小鸭’,‘小猪’)中的哪一个。在推理之前,先通过原来的图像采集程序采集一张图片放到image文件夹内,并对图像灰度化,然后进行图像识别并输出识别结果,验证模型的准确性。
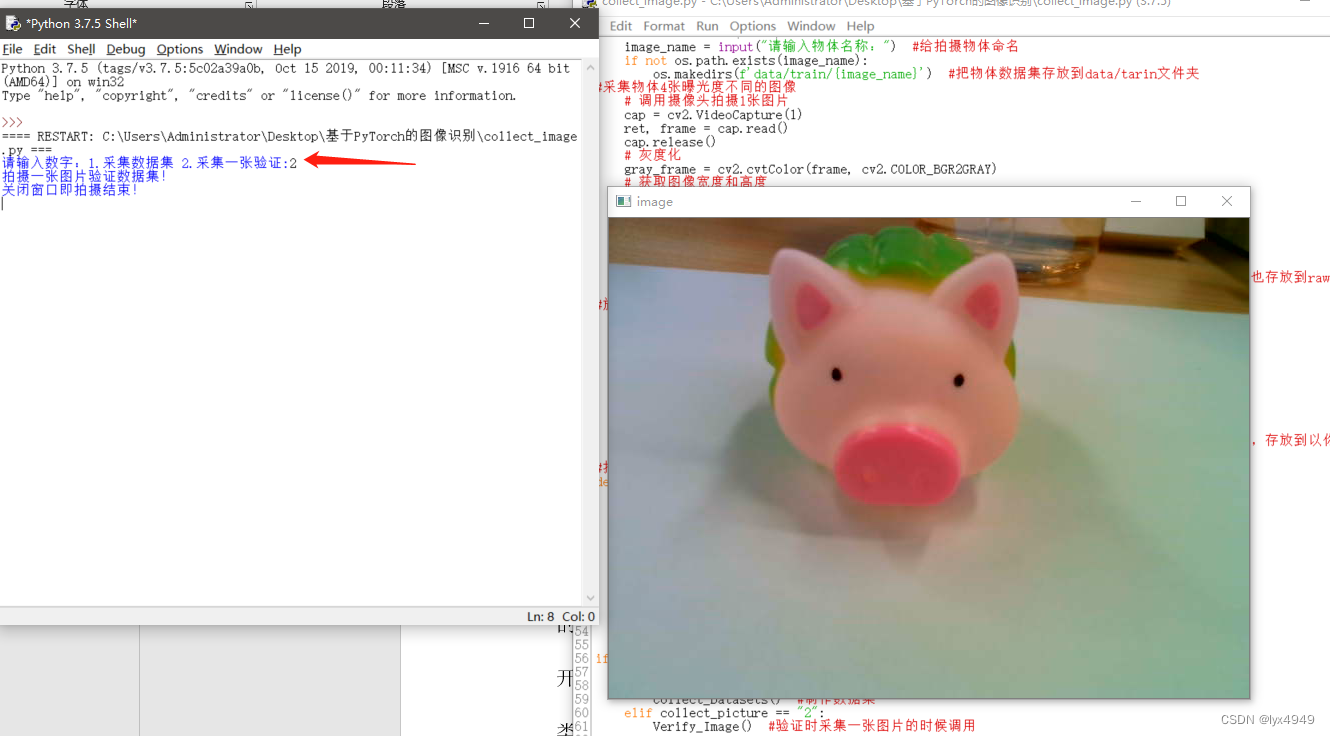
执行这个程序之前,需要先利用图像采集程序采集一张物体的图像存放在image文件夹内,使用任务一的代码,执行效果如下图。
模型推理程序
#inference_test.py程序 import cv2 from PIL import Image import torch import torchvision from torchvision import datasets, models, transforms import torch.nn.functional as F import torch.nn as nn tsfrm = transforms.Compose([ transforms.Grayscale(3), # 将图像转换为灰度图像,通道数为3 transforms.Resize((224, 224)), # 将图像变换为指定大小 transforms.ToTensor(), # 将PIL图像转换为tensor数据 transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 将PIL图像转换为tensor数据 ]) # 0.水果 1.蔬菜 2.服装 3.零食 (顺序需要按照训练集中的顺序) classes = ('小鸟','小猫','小鸭','小猪') # 判断GPU是否可用,有cpu和cuda两种,这里的cuda就是gpu device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) # 模型推理 def modelpre(grey_img): model_eval = models.resnet18(pretrained=False) # 加载ResNet18模型 num_ftrs = model_eval.fc.in_features # 获取默认的全连接层的输入维度 model_eval.fc = nn.Linear(num_ftrs, 4) # 替换模型的全连接层,使其输出4个分类 # 加载已经训练好的模型权重 model_eval.load_state_dict(torch.load('./model/dobot20230810.pkl', map_location=device)) # 在推理前,务必调用model.eval()去设置dropout和batch normalization层为评估模式 model_eval.eval() # 将OpenCV图像转换为PIL图像,并进行预处理 image = Image.fromarray(cv2.cvtColor(grey_img, cv2.COLOR_GRAY2RGB)) # PIL图像数据转换为tensor数据,并归一化 img = tsfrm(image) # 图像增加1维[batch_size,通道,高,宽] img = img.unsqueeze(0) # 进行模型推理,得到分类结果 output = model_eval(img) # 计算每个分类的概率 prob是4个分类的概率 prob = F.softmax(output, dim=1) print(prob) # tensor([[0.0360, 0.0061, 0.9529, 0.0050]], grad_fn=<SoftmaxBackward>) # 找出最大概率的分类.torch.max() 函数会返回输入张量中最大值和最大值的索引 value, predicted = torch.max(output.data, 1) # value模型预测出来的最大概率值 label = predicted.numpy()[0] # 将Tensor转换为numpy数组 print(label) # 打印出标签的索引 pred_class = classes[predicted.item()] # 提取最佳分类的标签 print(pred_class) if __name__ == "__main__": img_source = cv2.imread('image/image.jpg') # 图像灰度化 grey_img = cv2.cvtColor(img_source, cv2.COLOR_BGR2GRAY) cv2.imshow("image", grey_img) print("关闭窗口即拍摄结束!") cv2.waitKey()# 等待按键触发 modelpre(grey_img) # 调用modelpre函数,对灰度图像进行分类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
运行效果:
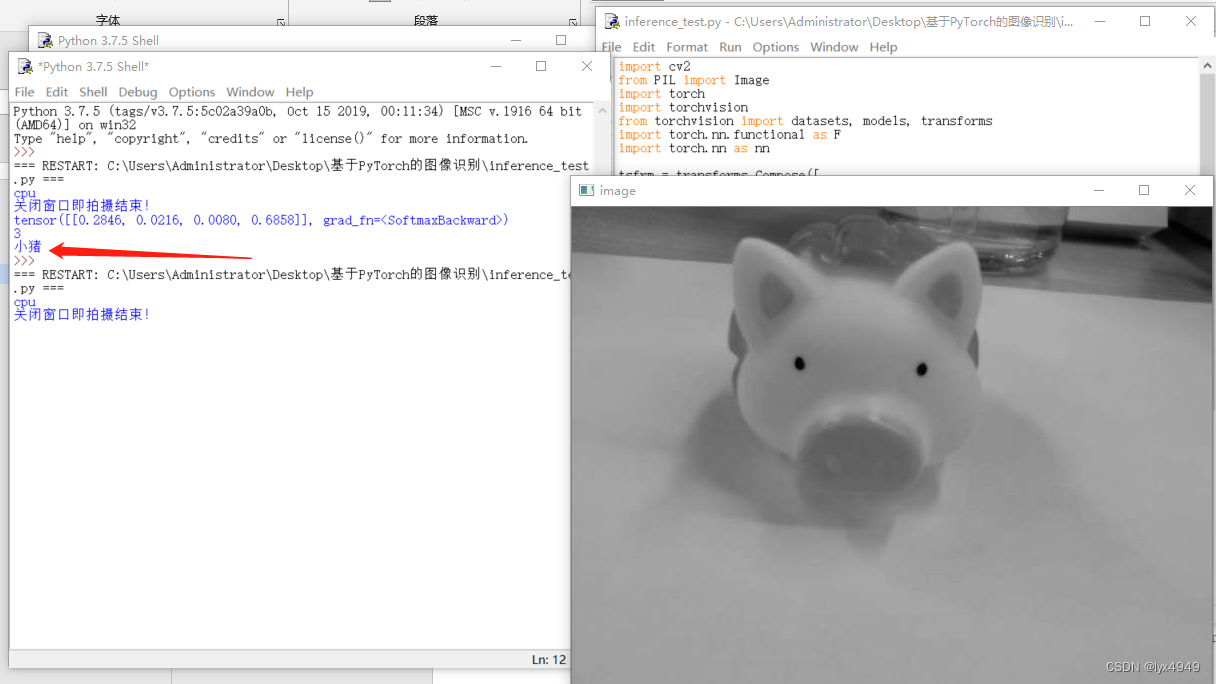
程序会去image文件夹内调用刚刚拍摄的验证图片去跟模型比对,最终输出4个概率。这4个概率就是我们拍摄的验证集与模型种4种类别的对比概率,最终程序会从中找到最大概率的那个类别输出对应的标签。
代码运行后,输出结果如图所示。print(device) 输出了 cpu,说明在这段代码中使用的是 CPU 来运行模型。输出结果3 是通过 torch.max() 函数得到的,它表示模型预测出来的最有可能的分类的索引。由于在 Python 中索引从0开始,因此3 表示模型预测出来的是第4个类别(索引为3),即 “猪” 这个类别
总结
程序附件链接:https://pan.baidu.com/s/1NYQ9E_WT0HVW0C32kelGyQ?pwd=lyx4
提取码:lyx4

