
- 1Topaz Photo AI 人工智能图像降噪锐化放大
- 2(详细版)java实现小程序获取微信登录,用户信息,手机号,头像_java获取微信小程序用户信息
- 3【Git GitHub 入门 命令】Git入门 2019_9_19_github 忽略追踪
- 4PostgreSQL - 如何杀死被锁死的进程_pg怎么杀进程
- 5【我的C/C++语言学习进阶之旅】NDK开发之解决错误:signal 5 (SIGTRAP), code 1 (TRAP_BRKPT), fault addr 0xXXX
- 6HarmonyOS NEXT 开发者预览版Beta招募应知测试——答案
- 7iOS中代码支持多国语言切换的实现(Xcode5+iOS7)_iphone x keyboard 多种语言切换
- 8一次地狱级面试
- 9R语言:ts() 时间序列的建立_r语言ts
- 10bp神经网络预测模型原理,神经网络模型怎么预测
AI-无损检测方向速读:基于深度学习的表面缺陷检测方法综述_表面缺陷滤波
赞
踩
1 表面缺陷检测的概念
表面缺陷检测是机器视觉领域中非常重要的一项研究内容, 也称为 AOI (Automated optical inspection) 或 ASI (Automated surface inspection),它是利用机器视觉设备获取图像来判断采集图像中是否存在缺陷的技术。
1.1 传统检测的缺陷(非CNN)
在很多开放式的工业环境下,期待设计的成像系统完全消除场景或者被检材料等变化对检测系统的影响,往往不太现实。也增加了检测系统的应用成本
在真实复杂的工业环境下,表面缺陷检测往往面临诸多挑战,例如存在缺陷成像与背景差异小、对比度低、缺陷尺度变化大且类型多样,缺陷图像中存在大量噪声,甚至缺陷在自然环境下成像存在大量干扰等情形,如图1所示,此时经典方法往往显得束手无策,难以取得较好的效果。

1.2 定义
1.2.1 缺陷的定义
-
有监督的方法,体现在利用标记了标签(包括类别、矩形框或逐像素等)的缺陷图像输入到网络中进行训练. 此时 “缺陷”意味着标记过的区域或者图像. 因此, 该方法更关注缺陷特征, 例如在训练阶段将包含大片黑色范围的区域或者图像标记为 “异色”缺陷用于网络训练. 在测试阶段, 当布匹图像中检测到大片黑色的特征时, 即认为出现了“异色”缺陷.
-
无监督的缺陷检测方法, 通常只需要正常无缺陷样本进行网络训练, 也称为one-class learning. 该方法更关注无缺陷 (即正常样本)特征, 当缺陷检测过程中发现未见过的特征(异常特征) 时, 即认为检测出缺陷. 此时 “缺陷”意味着异常, 因此该方法也称作异常检测 (Anomaly de-tection).
1.2.2 缺陷检测的定义
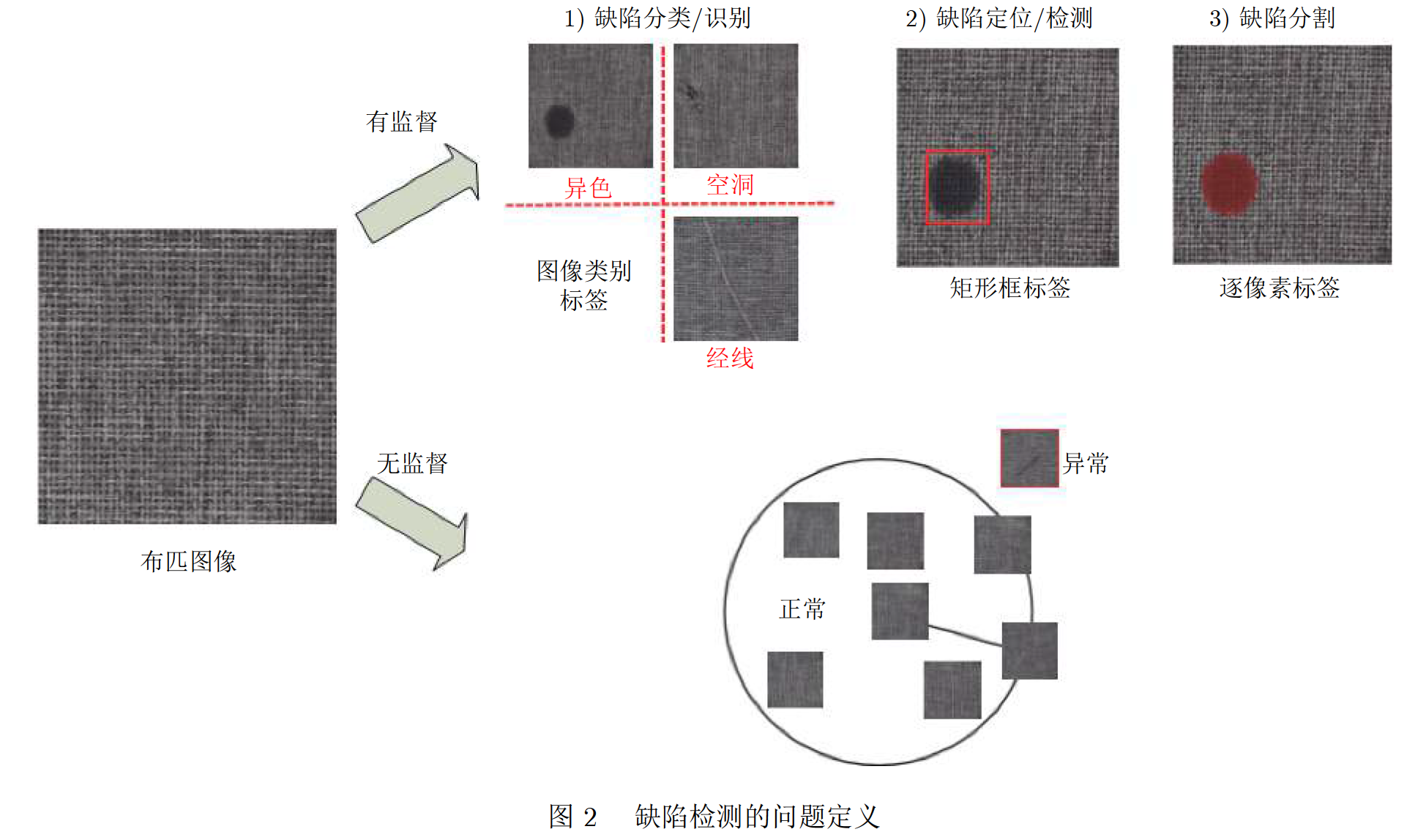
第1阶段: “缺陷是什么”对应计算机视觉中的分类任务, 如图2中分类三种缺陷类别: 异色、空洞和经线, 这一阶段的任务可以称为 “缺陷分类”, 仅仅给出图像的类别信息。
第2阶段: “缺陷在哪里”对应计算机视觉中的定位任务, 这一阶段的缺陷定位才是严格意义上的检测。 不仅获取图像中存在哪些类型的缺陷, 而且也给出缺陷的具体位置,如图2中将异色缺陷用矩形框标记出来。
第3阶段: “缺陷是多少”对应计算机视觉中的分割任务,如图2中缺陷分割的区域所示,将缺陷逐像素从背景中分割出来,并能进一步得到缺陷的长度、面积、位置等等一系列信息, 这些信息能辅助产品高一级的质量评估,例如优劣等级的判断。
2 表面缺陷检测深度学习方法
2.1 缺陷检测框架图
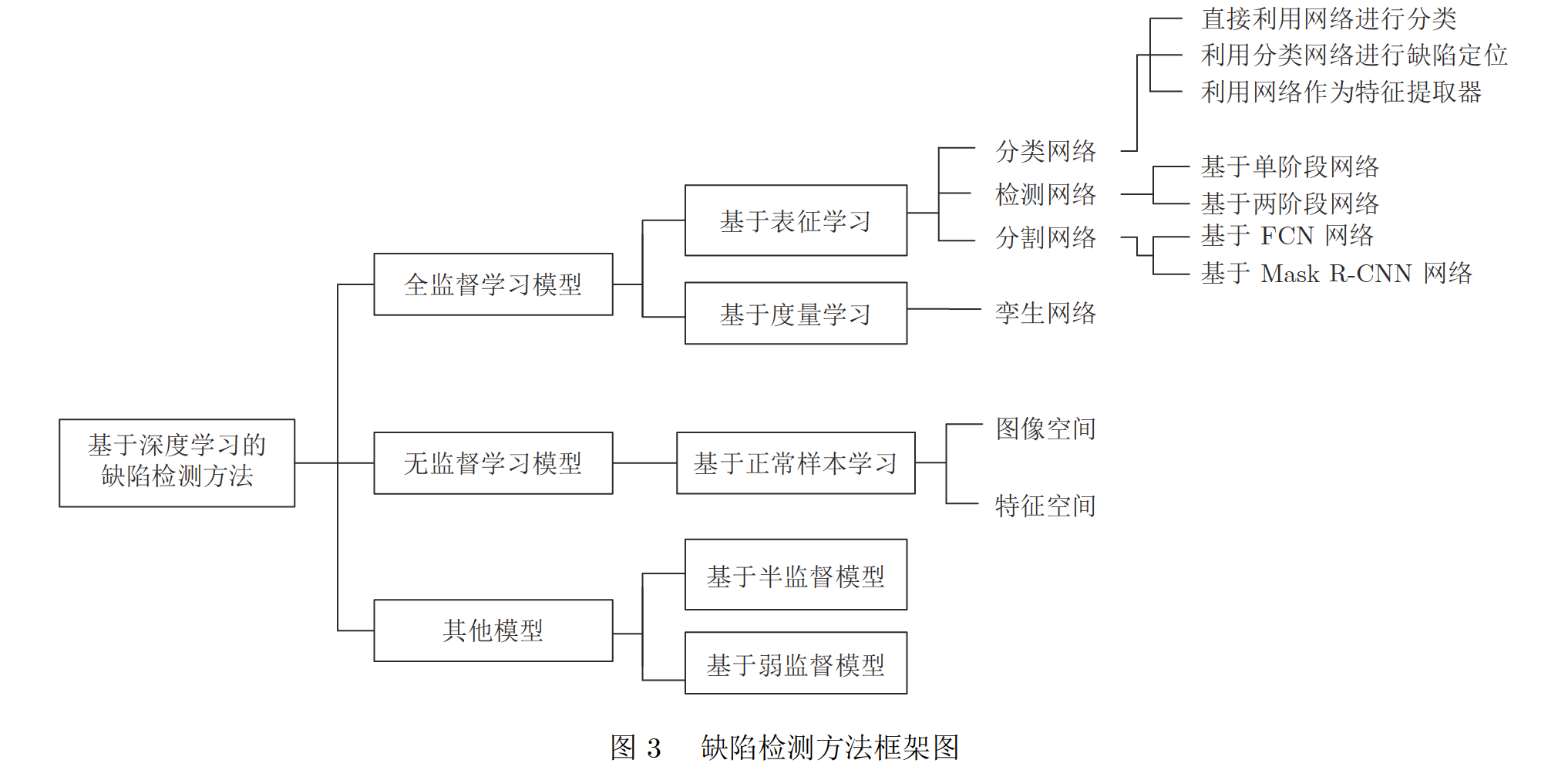
2.2 表征学习
根据网络结构的不同分为分类网络、检测网络、分割网络。将缺陷检测问题看作CV中的分类任务,粗粒度的图像标签分类或区域分类,像素分类。
2.2.1 分类网络
基于CNN的分类网络:特征提取部分由级联的卷积层+pooling层组成,后面接全连接层(或average pooling层)+softmax结构用于分类。
1)直接利用网络进行分类:根据工作特点,细分为原图分类、定位感兴趣区域(Region of interest,ROI)后分类和多类别分类
-
原图分类:缺陷数据集放入网络进行学习训练
-
定位ROI后分类:预先获取到感兴趣的区域(ROI),将ROI输入网络进行缺陷类别的判断。
-
多类别分类:分类缺陷类型超过两类,采用基础网络进行缺陷和正常样本二分类,在同一个网络上共享特征提取部分,修改或者增加缺陷类别的分类分支。给后续的多目标缺陷分类网络准备一个预训练权重参数,权重参数通过正常样本与缺陷样本之间二分类训练得到。
2)利用网络进行缺陷定位分类网络:可以实现缺陷定位和逐像素分类
-
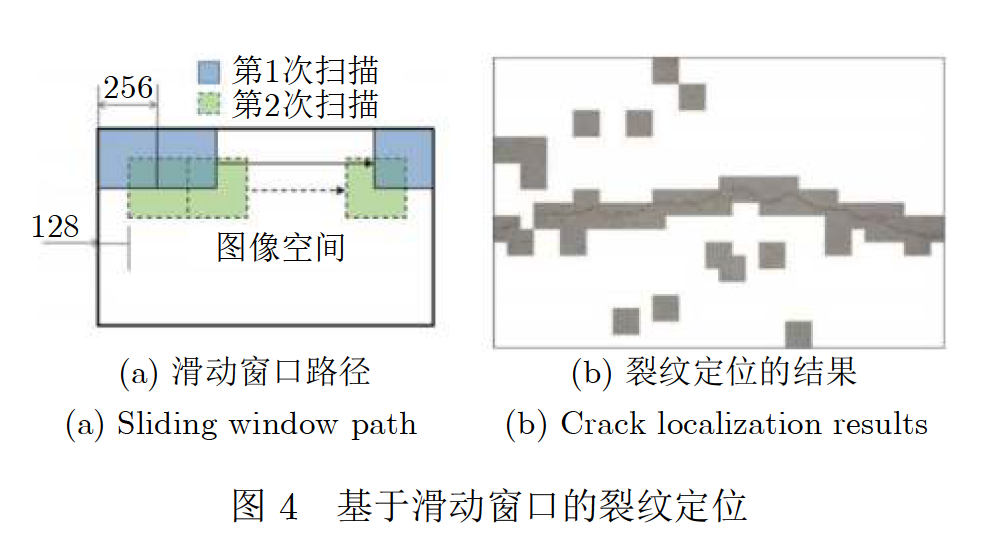
滑动窗口:粗定位,通过较小尺寸的窗口在原始图像上进行冗余滑动,将滑动窗口中的图像输入到分类网络中进行缺陷识别,最后将所有的滑动窗口进行链接,即可获得缺陷粗定位的结果。
-
热力图:反应图像中各区域重要性程度的图像,颜色越深的区域代表其属于缺陷的概率越大。在热力图的基础上运用Otsu法和图割算法进一步得到准确的缺陷轮廓区域。CAM(Class activation mapping)和Grad-CAM方法获得热力图,本质上是通过加权特征图,确定网络模型是通过哪些像素作为依据来判断输入图片所属的类别。
-
多任务学习:单纯的分类网络若不加入其他技巧,一般只能实现图像级别的分类. 因此,为了精细定位缺陷位置, 往往设计的网络会加上额外的分割分支,两个分支共享特征提取的骨架 (backbone) 结果,这样网络一般有分类和分割两个输出,构成多任务学习网络。对于分割网络分支,图像中每个像素都能被当作训练样本来训练网络。因此,多任务学习网络不仅利用分割分支输出缺陷具体的分割结果,而且可以大大减少分类网络对样本的需求。
3)利用网络做特征提取器
利于CNN特征提取功能,先将图像输入到预训练网络中获取图像表征特征,在将获取的特征输入到常规的机器学习分类器(SVM)中进行分类。
2.2.2 检测网络
目标定位是获得目标精准的位置和类别信息
基于深度学习的缺陷检测网络从结构上可以划分为:以FasterR-CNN为代表的两阶段(Twostage)网络和以SSD或YOLO为代表的一阶段(Onestage)网络。两者的主要差异在于两阶段网络需要首先生成可能包含缺陷的候选框,然后再进一步进行目标检测。一阶段网络则直接利用网络中提取的特征来预测缺陷的位置和类别。
1)基于两阶段的缺陷检测网络(强调检测精度的缺陷检测领域)
首先通过Backbone网络获取图像的特征图,利用区域生成网络(Region proposal network,RPN)计算锚框(anchor box)置信度,获取Proposal区域,然后对Proposal区域的的特征图进行ROIpooling后输入网络,通过对初步检测结果进行精细调整,最终得到缺陷的定位和类别结果。
常用方法往往针对 Back- bone 结构或其特征图、锚框比例、ROIpooling 和损失函数等方面进行改进。
2)基于单阶段的缺陷检测网络(追求检测速度的缺陷检测领域)
单阶段检测网络分为SSD和YOLO两种,利用整幅图作为网络的输入,直接在输出层回归边界框(Bounding box)的位置及其所属的类别。
SSD:特点在于引入了特征金字塔检测方式,从不同尺度的特征图中预测目标位置与类别。使用6个不同特征图检测不同尺度的目标,一般底层特征图用于预测小目标,高层特征图预测大目标。
2.2.3 分割网络
将表面缺陷检测任务转化为缺陷与正常区域的语义分割甚至实例分割任务,不但能精细分割出缺陷区域,还可以获取缺陷的位置、类别以及相应的几何属性(包括长度、宽度、面积、轮廓、中心等)。
按照分割功能的区别分为:全卷积神经网络(Fully Convolutional networks,FCN)、Mask R-CNN。
1)FCN方法(图像语义分割的基础)
利用卷积操作对输入图像进行特征提取和编码,再通过反卷积操作或上采样将特征图逐渐恢复到输入图像尺寸大小。根据FCN网络结构差异,可分为常规FCN、Unet和SegNet
a)常规FCN方法:通过融合多尺度采样层的特征图来细化分割轮胎图像中的缺陷.
b)Unet方法:经典的FCN结构,同时由编码器—解码器(Encoder-decoder)结构。特点在于引入跳层连接,将编码阶段的特征图与解码阶段的特征图进行融合,有利于分割细节的恢复。
c) SegNet方法:经典编码器-解码器结构,特点在于解码器中的上采样操作利用了编码器中最大池化操作的索引。
基于深度学习的分割网络还在不断提出,例如:LinkNet、DeepLabv3、PSPNet等。在最新模型中的模块,空洞卷积和金字塔Pooling也被添加了FCN框架中。生成对抗网络(Generative adversarial network,GAN)在CV中广泛应用,常用来生成图像,GAN由生成器和判别器模型构成。在结合GAN的缺陷检测方法中,生成器往往直接采用FCN网络,判别器通过分类模型来区分生成器的结果和Groundtruth,通过生成器和判断器的不断博弈,让生成器的输出结果逐渐接近Groundtruth。
2)Mask R-CNN方法(最常用的图像实力分割方法)
基于检测和分割网络相结合的多任务学习方法。当多个同类型缺陷存在粘连或重叠时,实例分割能将单个缺陷进行分离并进一步统计缺陷数目,语义分割往往将多个同类型缺陷当做整体进行处理。
目前大部分文献都是直接将Mask R-CNN框架应用于缺陷分割,路面缺陷分割、工业制造缺陷、螺栓紧固件缺陷和皮革表面缺陷。
分割方法在缺陷信息获取上有优势,但与检测网络一样,需要大量的标注数据,标注信息是逐像素,需要花费大量的标注经历和成本。
2.3 度量学习(使用深度学习直接学习输入的相似性度量)
缺陷分类任务中,往往采用孪生网络(Siamese networks)进行度量学习。不同于表征学习,输入单幅图像转化为分类任务,孪生网络的输入通常为两幅或多幅成对图像,通过网络学习出输入图片的相似度,判断其是否属于同一类。
孪生网络损失函数的核心思想是让相似的输入距离尽可能小,不同类别的输入距离尽可能大。
度量学习可以近似看作为学习样本在特征空间进行聚类,表征学习可以近似看作为学习样本在特征空间的分界面。相比于表征学习,度量学习的方法应用在表面缺陷定位中不太多,大部分都是应用在缺陷分类任务重。缺陷定位方面,输入孪生网络的图像对需要具有统一的内容形式,要求比较严格,无法适应复杂的工业环境。
2.4 正常样本学习
常用表面缺陷检测的无监督学习模型是基于正常样本学习的方法。只需要正常无缺陷样本进行网络训练,One-class learning方法。
正常样本学习的网络只接受正常(无缺陷)样本训练,使其具备强大的正常样本分布的重建和判别能力。当网络输入的样本存在缺陷时,往往会产生与正常样本不同的结果。
与有监督学习模型相比,检测到偏离预期的模式或者没有见过的模式,就是缺陷和异常。
依据处理空间的不同,本文将该缺陷检测方法分为基于图像空间和特征空间两种。通常该方法采用的网络模型为自编码器(Autoencoder,AE)和GAN。
2.4.1基于图像空间的方法
在图像空间对缺陷进行检测,不仅能实现图像级别的分类和识别, 也可以获取到缺陷的具体位置.
1)利用网络实现样本重建与补全(原理类似去噪编码器)
当输入任意样本图像到网络中,可以得到重建后对应的正常样本。网络可以具备自动修复或者补全缺陷区域的能力。输入图像分别减去这些重建或修复图像可以获得残差图像/重建误差,能够作为判断待检测样本是否异常的指标。
原则:重建误差过大时,可以认为输入图像存在缺陷,差异过大的区域即为缺陷区域。重建误差很小时,即认为输入图像是正常样本。
2)利用网络实现异常区域分类
通常采用GAN的判别器。
原理:训练生成对抗网络GAN以生成类似于正常表面图像的伪图像。训练好的GAN可以在潜在特征空间中很好地学习正常样本图像。GAN的判别器可以用作分类器,用于分类缺陷和正常样本。
基于深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN)的自动检测织物缺陷的新型无监督方法。该模型包括两个部分:第一部分部分利用模型中GAN的判别器生成了一个缺陷分布似然图,其中每个像素值都表示该位置出现缺陷的管理;第二部分通过引入编码器到标准DCGAN,实现重检测图像的重建。当从原始图像中减去重建图像时,可以创建残差图以突出显示潜在的缺陷区域。联合残差图和似然图以形成增强的融合图。在融合图上采用阈值分割算法进一步获取准确的缺陷位置,该方法在各种真实纺织物样品上进行评估和验证。
2.4.2基于特征空间的方法
在特征空间中,通过正常样本与缺陷样本特征分布之间的差异来进行缺陷检测。特征之间的差异也称为异常分数,当异常分数高于某个值时,即可认为出现缺陷。
基于空间的特征空间的方法往往只能实现图像级别的分类或识别,无法获取像素级别的缺陷位置,实际上,通过AE和GAN模块也能实现与图像空间检测方法类似的缺陷精确定位。
基于正常样本学习方法常用于简单统一的纹理表面缺陷检测,在复杂的工业检测环境,相比于监督学习的方法,其检测效果还不太理想。
2.5 弱监督与半监督学习(较少应用于表面缺陷检测中)
弱监督方法采用图像级别类别标注(弱标签)来获取分割/定位级别的检测效果。
半监督学习通常会使用大量的未标记数据和少部分有标签的数据用于表面缺陷检测模型的训练。大部分用于解决缺陷分类或识别任务,还没有广泛应用到定位于分割任务中。
3、关键问题/痛点
3.1 小样本/数据集过小
表面缺陷检测作为工业领域的具体应用。工业缺陷样本太少,相比于ImageNet数据集1400万样本数据,表面缺陷检测中的面临的最关键的问题是小样本问题,很多真实的工业场景下甚至有几张或几十张缺陷图片。
解决方案:
1)数据扩增、合成与生成。
对原始缺陷样本采用镜像、旋转、评议、扭曲、滤波、对比度调整等多种图像处理操作来获取更多的样本。
数据合成,将单独缺陷融合叠加到正常样本上构成缺陷样本,不少GAN的工作也应用于表面缺陷样本生成上。
2)网络预训练或迁移学习
深度学习网络参数较多,直接采用小样本训练网络很容易导致过拟合,但在预训练模型中存在一些比较共性的特征数据与权重信息。预训练网络或迁移学习是目前针对样本少最常用的方法之一
3)合理的网络结构设计
设计合理的网络结构可以大大减少样本的需求,基于孪生网络的表面缺陷检测方法也可以看作是一种特殊的网络设计,能够大幅减少样本需求。
4)采用无监督与半监督模型方法
主要方案是减少样本需求。无监督模型中,只利用正常样本进行训练,因此不需要缺陷样本,解决小样本情况下的网络训练难题。
3.2 实时性
缺陷检测方法在工业应用中的三个环节:数据标注、模型训练与模型推断。实际应用更关注模型推断。
以前大多数缺陷检测方法都集中在分类或识别的准确性上,而很少关注模型推断的效率。有不少方法用于加速模型, 例如模型权重量化和模型剪枝等。
3.3 传统图像处理与基于深度学习的缺陷检测方法的比较

4 缺陷数据集

5总结与展望
缺陷检测包括缺陷分类、缺陷定位和缺陷分割。基于深度学习方法是端到端的特征提取和分类。虽然表面缺陷检测技术已经不断地从学术研究走向成熟的工业应用,但是依然有一些需要解决的问题。
1)网络结构设计
大部分网络都是由人工设计,从模型到包含多少层到每一层的详细结构都是漫长的设计和调参过程。网络很难说最优,只是手工设计的网络在当前缺陷检测数据集上大致满足需求。机器搜寻和自动生成的网络逐步替代人工设计的网络,大幅减少手工设计网络参数,检测的正确率也会上升。
2)网络训练学习
难以收集到所有类型的缺陷。倘若只有良品数据集的情况下,如何利用类脑(受脑启发的)计算与仿人视觉认知模型,在有先验知识的前提下,来知道缺陷检测网络的训练和学习。
3)异域数据联邦学习or迁移学习
单个表面缺陷检测数据集往往都很少, 虽然小样本问题可以通过数据增广缓解相关问题。实际上不同工业行业和领域中, 真实工业表面缺陷数据是非常多的, 一些缺陷种类也是共同的, 例如划痕广泛存在于金属、液晶屏幕、太阳能电池板、玻璃等等一系列材质表面。
由于涉及隐私敏感, 不同检测领域之间数据并没有有效结合和利用。如何利用不同工业领域的缺陷数据集来进行网络学习。也是表面缺陷检测的一种重要研究方向。
因此, 基于异域数据的联邦学习将会成为一个趋势, 它能够打破不同应用场景之间的壁垒, 充分学习不同领域之间数据来提升网络性能。

