
- 1如何禁用@ typescript-eslint / no-non-null-assertion规则
- 2Light-YOLOv5 | 一种基于SepViT + BiFPN + SIoU YOLOv5 的轻量级复杂火灾场景检测算法_bifpn缺点
- 3C++练习题(1):开始C++、处理数据、符合类型、循环和关系表达式
- 4并发操作之——CAS_cas指令性能影响
- 52024年了,你还不会小程序反编译吗?
- 6鸿蒙应用开发-学习-第一章-CSS基础(三)_鸿蒙 background-image
- 7Git常用命令merge_gitmerge命令
- 8红米k30pro刷机鸿蒙,红米k30pro最严重缺点_红米k30pro建不建议买
- 9ubuntu22.04 安装wordpress搭建网站
- 10OpenHarmony媒体子系统音频组件
关于数据cutoff值确定多种方法(自备)
赞
踩
目录
方法①survminer 包
使用从“maxstat”R软件包中最大限度选择的等级统计数据,一次确定一个或多个连续变量的最佳分界点。这是一种以结果为导向的方法,提供了与结果(此处为存活率)关系最密切的分界点值。 surv_cutpoint():使用“maxstat”确定每个变量的最佳切割点。
surv _ categorize():根据surv_cutpoint()返回的切割点划分每个变量值。
示例数据分析
- ##采用包自带的示例数据##
- rm(list = ls())
- library(survival)
- library(survminer)
- data(myeloma)
- head(myeloma)
-
- ?surv_cutpoint#查看函数
- res.cut <- surv_cutpoint(myeloma,
- time = "time", #生存时间
- event = "event", #生存结局
- variables = c("DEPDC1", "WHSC1", "CRIM1"))
- summary(res.cut) #查看数据最佳截断点及统计量
- #cutpoint statistic
- #DEPDC1 279.8 4.275452
- #WHSC1 3205.6 3.361330
- #CRIM1 82.3 1.968317
-
- #数据分布
- plot(res.cut, "DEPDC1", palette = "npg")

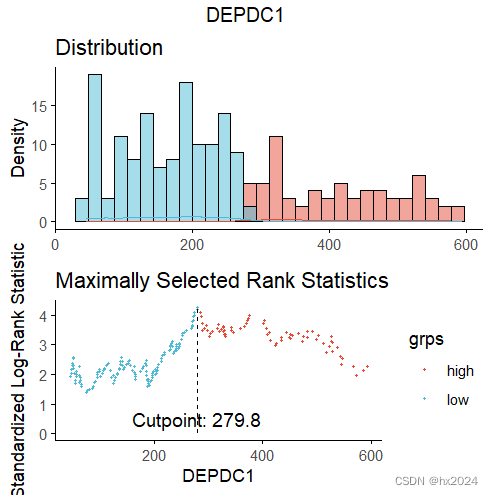
- # 3. Categorize variables:这里根据cutoff值分为高低分组
- res.cat <- surv_categorize(res.cut)
- #head(res.cat)
- #生存曲线绘制#
- fit <- survfit(Surv(time, event) ~DEPDC1, data = res.cat)#拟合生存分析

- #绘制生存曲线并显示P值
- ggsurvplot(fit,
- data = res.cat,
- risk.table = TRUE,
- pval = T)
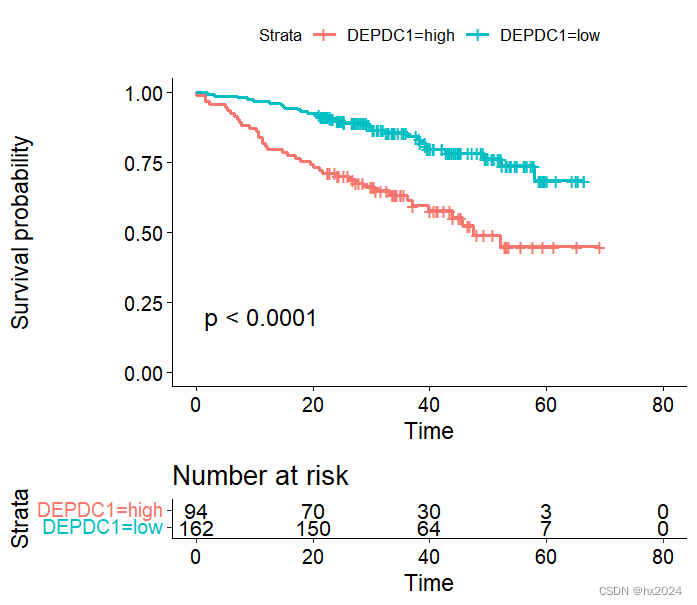
感谢木舟笔记:Q&A | R做生存分析如何取最佳cutoff(截断) - 知乎 (zhihu.com)
方法②ROC曲线绘制的最佳cutoff
根据某个数据的检验效能最佳截断值进行分组。
其可以在没有生存数据的时候进行使用,然后分析组间差异
连续性变量的组间差异分析_连续变量和连续变量差异性分析-CSDN博客
- rm(list = ls())
- library(pROC)
- library(survival)
- library(survminer)
- #roc截断值确定属于是检验诊断效能
- data(myeloma)##这里为了方便展示也是用这个数据进行测试
-
- dat <- myeloma[,c(4,8)]#[1] "event" "DEPDC1"
- roc1 <- roc(event ~ DEPDC1, data = dat)
- #Setting levels: control = 0, case = 1
- #Setting direction: controls < cases
-
- attributes(roc1)#查看结果包含内容
- roc1$auc#
- #Area under the curve: 0.6272
- ci.auc(roc1)
- #95% CI: 0.5491-0.7053 (DeLong)
-
- #求约登指数
- roc.result <- data.frame(threshold = roc1$thresholds,
- sensitivity = roc1$sensitivities,
- specificity = roc1$specificities)
- View(roc.result)
- roc.result$youden <- roc.result$sensitivity + roc.result$specificity - 1
- head(roc.result)
- which.max(roc.result$youden)#找出约登指数最大的一行
- roc.result[160,]##查看cutoff值
- #threshold sensitivity specificity youden
- #160 281.9 0.5714286 0.7096774 0.281106
- ##计算出CI值和cutoff点,然后进行标注
- table(dat$DEPDC1 > 281.9)
-
- #根据截断值划分分组#
- myeloma$DEPDC11 <- ifelse(myeloma$DEPDC1 > 281.9,"high", "low")
- ##绘制生存曲线
- fit <- survfit(Surv(time, event) ~DEPDC11, data = myeloma)#拟合生存分析
- #绘制生存曲线并显示P值
- ggsurvplot(fit,
- data = myeloma,
- risk.table = TRUE,
- pval = T)

结果是一致的。
surv_cutpoint()和ROC曲线都是用于确定最佳截断值的方法,它们之间存在一致性的原因如下:
-
目标相同:surv_cutpoint()和ROC曲线都旨在找到一个截断值,使得在该值之上或之下的预测结果能够最好地与实际观测结果相匹配。
-
基于模型性能:两种方法都是基于模型的性能来确定最佳截断值。surv_cutpoint()通过评估生存曲线的差异来选择最佳截断值,而ROC曲线通过计算真阳性率和假阳性率来评估分类模型的性能。
-
最大化敏感性和特异性:无论是surv_cutpoint()还是ROC曲线,都追求在预测中最大化敏感性和特异性。敏感性指的是正确识别阳性样本的能力,特异性指的是正确识别阴性样本的能力。
-
统计学原理:surv_cutpoint()和ROC曲线都基于统计学原理进行计算。surv_cutpoint()使用Kaplan-Meier估计和log-rank检验来评估生存曲线的差异,而ROC曲线使用真阳性率和假阳性率的比值来评估分类模型的性能。
综上所述,surv_cutpoint()确定的最佳截断值与ROC确定的最佳截断值是一致的,因为它们都追求在预测中最大化敏感性和特异性,并基于统计学原理来评估模型的性能。
其他
使用OptimalCutpoints包,cutpointr包

