
2022年中青杯B题数学建模文档及程序三孩生育数学建模_2022年中青杯b题优秀论文
赞
踩
2022年中青杯B题解题文档及程序数学建模
整体做题过程
针对问题一:采用预测模型来解决这个问题,常用的预测模型有时间序列ARIMA模型、灰色预测模型,时间序列ARIMA 模型的全称叫做自回归移动平均模型,是统计模型中最常见的一种用来进行时间序列预测的模型。灰色预测是一种对含有不确定因素的系统进行预测的方法。灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
针对问题二:要求我们考虑双减政策对人口的影响,这里大家可以有不同的切入点,我们需要把双减政策转化为和我们收集数据指标相同的数据才能进行分析,这里我认为大家可以考虑家庭经济在教育上的投入,利用经济来表示双减政策,进而判断经济和人口的关系。
针对问题三:需要我们考虑医疗对人口老龄化的相关影响,这可以用因子分析或者因果分析进行。
针对问题四:多方面综合考虑,给出促进生育意愿的有效方案。
问题重述
问题1.预测开放3children后未来10年的人口状况.
问题2.分析sj落地后对新出生人口是否会有影响。
问题3.在医疗方面如何推行实施新的政策,缓解人口老化进程。
问题4.从多方面综合考虑,给出促进生育意愿的有效方案。
模型的建立与求解过程
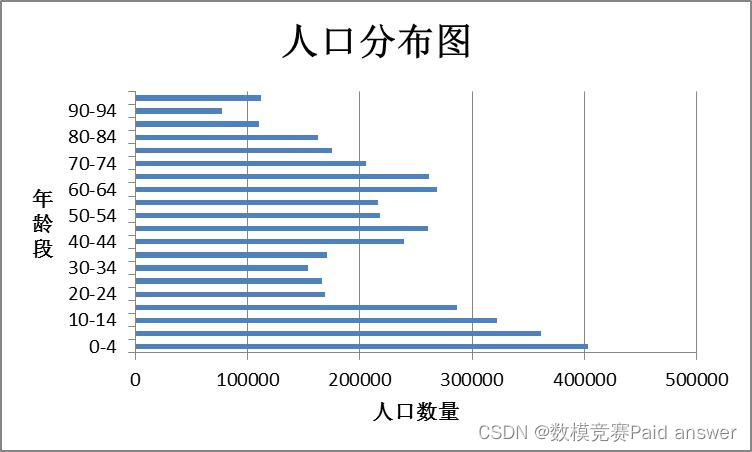
针对问题一应采用灰色预测模型或平稳时间序列模型来做,先从题目要求出发,先对不同年龄段的人口简单做个统计分析,掌握人口结构情况;(可以环形图、饼形图),然后对于整体人口的影响具体影响的是那部分人群?影响权重是多少?怎么得出的影响权重?根据是什么?紧接着主干来了,问题一是一个回归预测的问题并非是分类预测的问题,该预测是时间为十年的人口预测趋势,人口与什么相关?一、政策;二、地区经济;三、结婚率 总共大面上就这么点事
针对问题二,这就得考虑到教育了,也就是说你第一问必须得考虑一下教育因素然后为第二问做铺垫,这样评委看的满意,也符合逻辑依据。出生人口影响因素:教育、双减政策、问题一考虑的因素,就这么多。
针对问题三,相同的套路得考虑医疗因素
针对问题四,综合分析,这个地方就要用到权重占比、单因子分析及综合多因素了,并给出方案的可取性及使用依据。
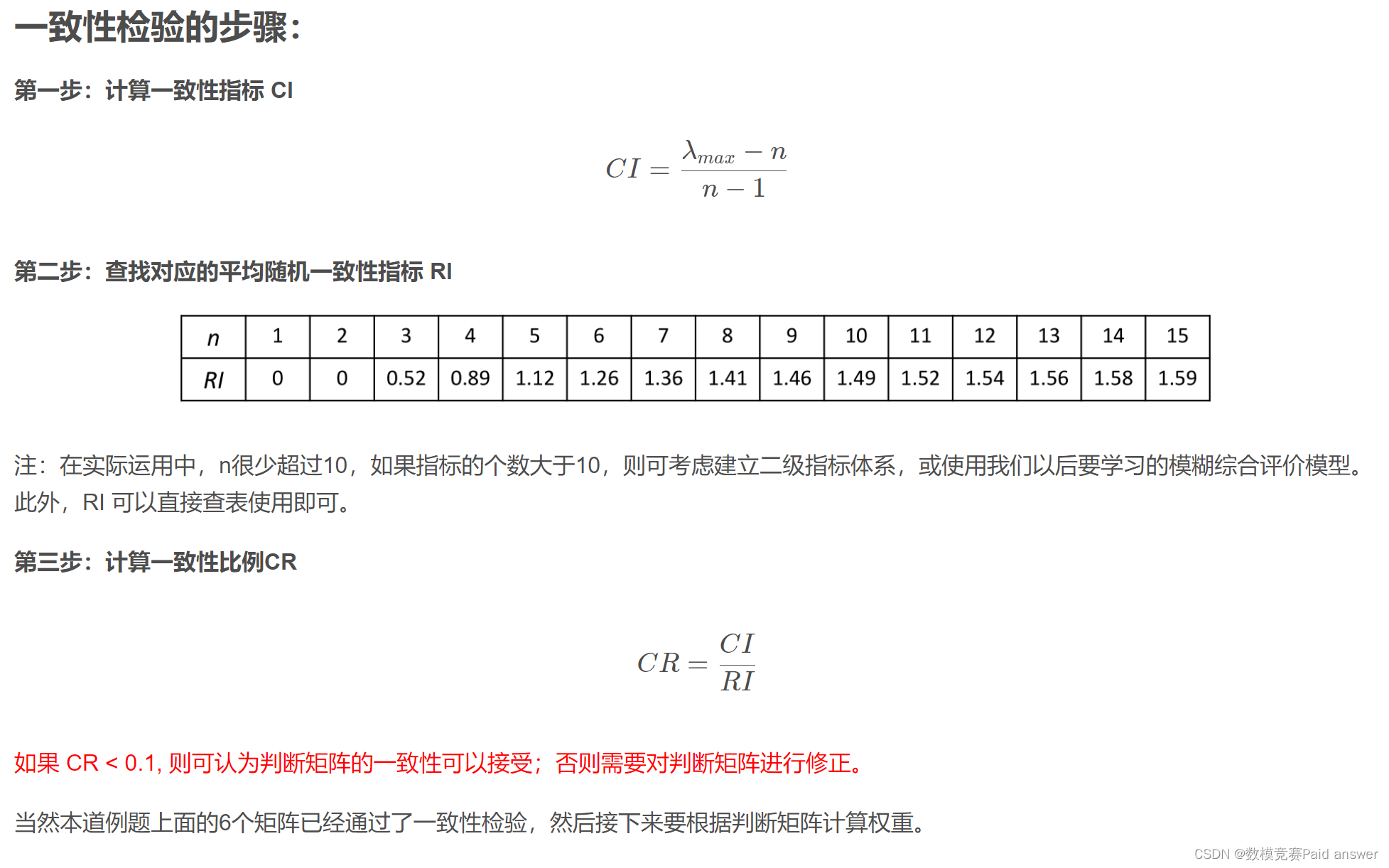
问题分析:
问题一的分析
问题一要求结合人口的年龄结构,建立数学模型,预测开放三孩后未来10年的人口状况。由于实行三胎政策会影响妇女的生育率,也即影响该地的出生率,因此本文先对生育率、出生率等参数进行预测,得到在实行政策下的参数,并建立PDE模型,通过对不同年龄阶段的人口数进行推演得到未来10年按年龄划分的人口结构。
问题二的分析
假设不实施双减政策预测,该地区未来20年的人口结构变化趋势。对比于实施双减政策系统,该地区20年来的人口结构变化趋势,得到最优出生率。从而得到这个政策落地是否对新生人口是否会有影响这一结论。在A地区不实行三孩政策,即没有政府政策影响A地区的生育率、出生率,本文通过建立灰色预测模型,通过 MATLAB、C++编写程序求解相关参数。将出生率、死亡率以及城乡人口数量根据时间的发展做出未来20年的预测,并根据预测数据得到未来20年的人口结构分布。对于第二个小问,为求得最优出生率,本文通过建立约束条件,利用人口预测公式,求出能使得X满足约束条件的解。从而得到这个政策落地是否对我国新生人口是否会有影响这一结论。
问题三的分析
问题三要求结合当下实际情况,分析在医疗方面如何推行实施新的政策,从而进一步缓解我国人口老龄化进程。人口老龄化是我国发展的必然趋势,由此要从人口老龄化产生的原因及现状来进行分析和考虑,得知当下的不足点,再从不足点提出有效的建议。
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
word or progarme not free

程序代码1
import numpy as np
import itertools
import matplotlib.pyplot as plt
#自适应层数的层次分析法
class AHP():
'''
注意:python中list与array运算不一样,严格按照格式输入!
本层次分析法每个判断矩阵不得超过9阶,各判断矩阵必须是正互反矩阵
FA_mx:下一层对上一层的判断矩阵集(包含多个三维数组,默认从目标层向方案层依次输入判断矩阵。同层的判断矩阵按顺序排列,且上层指标不共用下层指标)
string:默认为'norm'(经典的层次分析法,需输入9标度判断矩阵),若为'auto'(自调节层次分析法,需输入3标度判断矩阵)
'''
#初始化函数
def __init__(self,FA_mx,string='norm'):
self.RI=np.array([0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49]) #平均随机一致性指标
if string=='norm':
self.FA_mx=FA_mx #所有层级的判断矩阵
elif string=='auto':
self.FA_mx=[]
for i in range(len(FA_mx)):
temp=[]
for j in range(len(FA_mx[i])):
temp.append(self.preprocess(FA_mx[i][j]))
self.FA_mx.append(temp) #自调节层次分析法预处理后的所有层级的判断矩阵
self.layer_num=len(FA_mx) #层级数目
self.w=[] #所有层级的权值向量
self.CR=[] #所有层级的单排序一致性比例
self.CI=[] #所有层级下每个矩阵的一致性指标
self.RI_all=[] #所有层级下每个矩阵的平均随机一致性指标
self.CR_all=[] #所有层级的总排序一致性比例
self.w_all=[] #所有层级指标对目标的权值
#输入单个矩阵算权值并一致性检验(特征根法精确求解)
def count_w(self,mx):
n=mx.shape[0]
eig_value, eigen_vectors=np.linalg.eig(mx)
maxeig=np.max(eig_value) #最大特征值
maxindex=np.argmax(eig_value) #最大特征值对应的特征向量
eig_w=eigen_vectors[:,maxindex]/sum(eigen_vectors[:,maxindex]) #权值向量
CI=(maxeig-n)/(n-1)
RI=self.RI[n-1]
if(n<=2 and CI==0):
CR=0.0
else:
CR=CI/RI
if(CR<0.1):
return CI,RI,CR,list(eig_w.T)
else:
print('该%d阶矩阵一致性检验不通过,CR为%.3f'%(n,CR))
return -1.0,-1.0,-1.0,-1.0
#计算单层的所有权值与CR
def onelayer_up(self,onelayer_mx,index):
num=len(onelayer_mx) #该层矩阵个数
CI_temp=[]
RI_temp=[]
CR_temp=[]
w_temp=[]
for i in range(num):
CI,RI,CR,eig_w=self.count_w(onelayer_mx[i])
if(CR>0.1):
print('第%d层的第%d个矩阵未通过一致性检验'%(index,i+1))
return
CI_temp.append(CI)
RI_temp.append(RI)
CR_temp.append(CR)
w_temp.append(eig_w)
self.CI.append(CI_temp)
self.RI_all.append(RI_temp)
self.CR.append(CR_temp)
self.w.append(w_temp)
#计算单层的总排序及该层总的一致性比例
def alllayer_down(self):
self.CR_all.append(self.CR[self.layer_num-1])
self.w_all.append(self.w[self.layer_num-1])
for i in range(self.layer_num-2,-1,-1):
if(i==self.layer_num-2):
temp=sum(self.w[self.layer_num-1],[]) #列表降维,扁平化处理,取上一层的权值向量
CR_temp=[]
w_temp=[]
CR=sum(np.array(self.CI[i])*np.array(temp))/sum(np.array(self.RI_all[i])*np.array(temp))
if(CR>0.1):
print('第%d层的总排序未通过一致性检验'%(self.layer_num-i))
return
for j in range(len(self.w[i])):
shu=temp[j]
w_temp.append(list(shu*np.array(self.w[i][j])))
temp=sum(w_temp,[]) #列表降维,扁平化处理,取上一层的总排序权值向量
CR_temp.append(CR)
self.CR_all.append(CR_temp)
self.w_all.append(w_temp)
return
#计算所有层的权值与CR,层次总排序
def run(self):
for i in range(self.layer_num,0,-1):
self.onelayer_up(self.FA_mx[i-1],i)
self.alllayer_down()
return
#自调节层次分析法的矩阵预处理过程
def preprocess(self,mx):
temp=np.array(mx)
n=temp.shape[0]
for i in range(n-1):
H=[j for j,x in enumerate(temp[i]) if j>i and x==-1]
M=[j for j,x in enumerate(temp[i]) if j>i and x==0]
L=[j for j,x in enumerate(temp[i]) if j>i and x==1]
DL=sum([[i for i in itertools.product(H,M)],[i for i in itertools.product(H,L)],[i for i in itertools.product(M,L)]],[])
DM=[i for i in itertools.product(M,M)]
DH=sum([[i for i in itertools.product(L,H)],[i for i in itertools.product(M,H)],[i for i in itertools.product(L,M)]],[])
if DL:
for j in DL:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=1
if DM:
for j in DM:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=0
if DH:
for j in DH:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=-1
for i in range(n):
for j in range(i+1,n):
temp[j][i]=-temp[i][j]
A=[]
for i in range(n):
atemp=[]
for j in range(n):
a0=0
for k in range(n):
a0+=temp[i][k]+temp[k][j]
atemp.append(np.exp(a0/n))
A.append(atemp)
return np.array(A)
#%%测试函数
if __name__=='__main__' :
'''
# 层次分析法的经典9标度矩阵
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[1, 3],
[1/3 ,1]]))
criteria1 = np.array([[1, 3],
[1/3,1]])
criteria2=np.array([[1, 1,3],
[1,1,3],
[1/3,1/3,1]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[1, 1], [1, 1]])
sample2 = np.array([[1,1,1/3], [1,1,1/3],[3,3,1]])
sample3 = np.array([[1, 1/3], [3, 1]])
sample4 = np.array([[1,3,1], [1 / 3, 1, 1/3], [1,3, 1]])
sample5=np.array([[1,3],[1/3 ,1]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx) #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[]) #底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
'''
#自调节层次分析法的3标度矩阵(求在线体系的权值)
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[0, 1],
[-1,0]]))
criteria1 = np.array([[0, 1],
[-1,0]])
criteria2=np.array([[0, 0,1],
[0,0,1],
[-1,-1,0]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[0, 0], [0, 0]])
sample2 = np.array([[0,0,-1], [0,0,-1],[1,1,0]])
sample3 = np.array([[0, -1], [1, 0]])
sample4 = np.array([[0,1,0], [-1, 0,-1], [0,1,0]])
sample5=np.array([[0,1],[-1 ,0]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx,'auto') #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[])
#底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
人口老龄化的主要原因及现状:
1.人们的医疗保障意识淡薄,相比于医疗保险,人们更愿意将钱投入银行储蓄获得更安全的保障。
2.制度上的问题:社会医保覆盖面有限,保障程度低,我国仍然有很多人是无医疗保障的,这些人在步入老年后会面临大量的医疗费用,收入降低的压力。
3.缺乏针对老年人的护理保障,人口老龄化的快速发展,大量的老年人需要被照顾,需求量的增长,但是由于计划生育的实施,出生人口的降低,人口老龄化的问题日益严重。
4.“现收现付”为主的筹资模式使医疗保障面临支付压力,目前我国的医疗保险采用的社会统筹和个人账户相结合,但很多人面临着存款不足,能力有限,甚至没有存款,所以“现收现付”的必要条件就是相对好的年轻化的人口结构,而我国人口老龄化严重,每一个劳动人口对老年人口的负担加重。
5.医疗资源的不足,我国的医疗资源难以适应人口老龄化等因素带来的需求增长,以2019年的新冠肺炎为例,武汉各医院出现了“床位不足”的问题,医院床位紧张,感染者多为中老年人,因此老年化的加重,医疗保障也要扩容。
解决方案:
1.提高认识,人口老龄化是社会经济发展的必然结果,我们要充分认识人口老龄化带来的影响,及时采取有效的措施,加大各阶层人们对人口老龄化对社会的影响的认识。
2.完善老年人的医疗保障制度,老年人的医疗费用和需求相对于年轻人来说都比较大,将老年人独立出来,有利于提高其他人群的医疗福利水平,减少医疗费用危机,老年人作为弱势群体,建立老年人的医疗保障制度能够给予老年人更多的照顾。
3.适当降低医药品的价格,在我国医疗水平的发展过程中存在着盲目提高医疗保障水平的倾向。比如一些药价虚高的心脑血管药,抗生素等都进入了医疗保险用药。所以应结合人口实际的医疗需求,实际的经济能力,老龄化发展等各方面因素,制定适宜的保障水平,保障水平必须保障在未来人口老龄化发展下的可行性。
4.补充医疗保险,大力发展商业医疗保险已经成为世界各国的主要发展政策,但是我国商业医疗保险的发展并没有得到重视,市场发展不完善,很多居民没有能力购买商业保险,因此,政府要进一步采取措施,发展商业医疗保险。
5.老年人护理保障制度,老年人的护理需求包括服务和费用两个方面,在我国服务和费用都是家庭独自承担,我们应该将对老年人的护理作为应对人口老龄化的重要问题,借鉴发达国家的经验,建立我国社会和经济相适应的老年人护理保障制度。
程序代码2
from decimal import *
class GM11():
def __init__(self):
self.f = None
def isUsable(self, X0):
'''判断是否通过光滑检验'''
X1 = X0.cumsum()
rho = [X0[i] / X1[i - 1] for i in range(1, len(X0))]
rho_ratio = [rho[i + 1] / rho[i] for i in range(len(rho) - 1)]
print("rho:", rho)
print("rho_ratio:", rho_ratio)
flag = True
for i in range(2, len(rho) - 1):
if rho[i] > 0.5 or rho[i + 1] / rho[i] >= 1:
flag = False
if rho[-1] > 0.5:
flag = False
if flag:
print("数据通过光滑校验")
else:
print("该数据未通过光滑校验")
'''判断是否通过级比检验'''
lambds = [X0[i - 1] / X0[i] for i in range(1, len(X0))]
X_min = np.e ** (-2 / (len(X0) + 1))
X_max = np.e ** (2 / (len(X0) + 1))
for lambd in lambds:
if lambd < X_min or lambd > X_max:
print('该数据未通过级比检验')
return
print('该数据通过级比检验')
def train(self, X0):
X1 = X0.cumsum()
Z = (np.array([-0.5 * (X1[k - 1] + X1[k]) for k in range(1, len(X1))])).reshape(len(X1) - 1, 1)
# 数据矩阵A、B
A = (X0[1:]).reshape(len(Z), 1)
B = np.hstack((Z, np.ones(len(Z)).reshape(len(Z), 1)))
# 求灰参数
a, u = np.linalg.inv(np.matmul(B.T, B)).dot(B.T).dot(A)
u = Decimal(u[0])
a = Decimal(a[0])
print("灰参数a:", a, ",灰参数u:", u)
self.f = lambda k: (Decimal(X0[0]) - u / a) * np.exp(-a * k) + u / a
def predict(self, k):
X1_hat = [float(self.f(k)) for k in range(k)]
X0_hat = np.diff(X1_hat)
X0_hat = np.hstack((X1_hat[0], X0_hat))
return X0_hat
def evaluate(self, X0_hat, X0):
'''
根据后验差比及小误差概率判断预测结果
:param X0_hat: 预测结果
:return:
'''
S1 = np.std(X0, ddof=1) # 原始数据样本标准差
S2 = np.std(X0 - X0_hat, ddof=1) # 残差数据样本标准差
C = S2 / S1 # 后验差比
Pe = np.mean(X0 - X0_hat)
temp = np.abs((X0 - X0_hat - Pe)) < 0.6745 * S1
p = np.count_nonzero(temp) / len(X0) # 计算小误差概率
print("原数据样本标准差:", S1)
print("残差样本标准差:", S2)
print("后验差比:", C)
print("小误差概率p:", p)
if __name__ == '__main__':
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# 原始数据X
X = np.array(
[21.2, 22.7, 24.36, 26.22, 28.18, 30.16, 32.34, 34.72, 37.3, 40.34, 44.08, 47.92, 51.96, 56.02, 60.14,
64.58,
68.92, 73.36, 78.98, 86.6])
# 训练集
X_train = X[:int(len(X) * 0.7)]
# 测试集
X_test = X[int(len(X) * 0.7):]
model = GM11()
model.isUsable(X_train) # 判断模型可行性
model.train(X_train) # 训练
Y_pred = model.predict(len(X)) # 预测
Y_train_pred = Y_pred[:len(X_train)]
Y_test_pred = Y_pred[len(X_train):]
score_test = model.evaluate(Y_test_pred, X_test) # 评估
# 可视化
plt.grid()
plt.plot(np.arange(len(X_train)), X_train, '->')
plt.plot(np.arange(len(X_train)), Y_train_pred, '-o')
plt.legend(['负荷实际值', '灰色预测模型预测值'])
plt.title('训练集')
plt.show()
plt.grid()
plt.plot(np.arange(len(X_test)), X_test, '->')
plt.plot(np.arange(len(X_test)), Y_test_pred, '-o')
plt.legend(['负荷实际值', '灰色预测模型预测值'])
plt.title('测试集')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111

