
热门标签
热门文章
- 1大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)_hadoop mysql
- 2【修改huggingface transformers默认缓存文件夹】_transformers_cache
- 3大数据在推荐系统中的作用_推荐系统与大数据安全
- 4android 检测无用资源,一个自动清理Android项目无用资源的工具类及源码
- 5【深度学习】-Imdb数据集情感分析之模型对比(4)- CNN-LSTM 集成模型_cnn-lstm做情感分析的时候需要保证cnn的输出和bilstm的输出维度一致吗
- 6Wireshark 抓包工具与长ping工具pinginfoview使用,安装包_wireshark端口抓包命令
- 7Neo4基础语法学习_neo4j语法教程
- 8注意力机制(Attention)原理详解_attention层
- 9毕业设计 基于单片机的智能盲人头盔系统 - 导盲杖 stm32
- 10基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
当前位置: article > 正文
数据特征分析:相关性分析(Pandas中的corr方法)_pandas corr
作者:知新_RL | 2024-03-31 02:44:31
赞
踩
pandas corr
分析连续变量之间的线性相关程度的强弱
介绍如下几种方法:
- 图示初判
- Pearson相关系数(皮尔逊相关系数)
- Sperman秩相关系数(斯皮尔曼相关系数)
1.图示初判
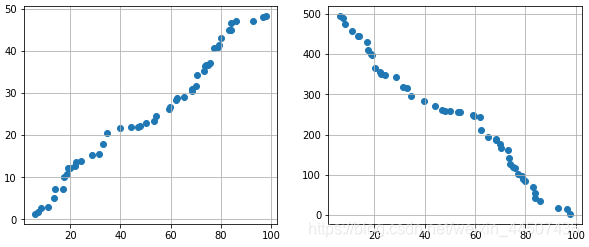
拿到一组数据,可以先绘制散点图查看各数据之间的相关性:
两个变量之间的相关性(散点图)
import numpy as np import pandas as pd import matplotlib.pyplot as plt from scipy import stats %matplotlib inline # 图示初判 # (1)变量之间的线性相关性 data1 = pd.Series(np.random.rand(50)*100).sort_values() data2 = pd.Series(np.random.rand(50)*50).sort_values() data3 = pd.Series(np.random.rand(50)*500).sort_values(ascending = False) # 创建三个数据:data1为0-100的随机数并从小到大排列,data2为0-50的随机数并从小到大排列,data3为0-500的随机数并从大到小排列, fig = plt.figure(figsize = (10,4)) ax1 = fig.add_subplot(1,2,1) ax1.scatter(data1, data2) plt.grid() # 正线性相关 ax2 = fig.add_subplot(1,2,2) ax2.scatter(data1, data3) plt.grid() # 负线性相关

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
多变量之间的相关性(散点图矩阵)
# 图示初判
# (2)散点图矩阵初判多变量间关系
data = pd.DataFrame(np.random.randn(200,4)*100, columns = ['A','B','C','D'])
pd.plotting.scatter_matrix(data,figsize=(8,8),#注意Pandas中的用法与之前不同
c = 'k',
marker = '+',
diagonal='hist',
alpha = 0.8,
range_padding=0.1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

2.Pearson相关系数
当两个变量都是正态连续变量,而且两者之间呈线性关系时,表现这两个变量之间相关程度用积差相关系数,主要有Pearson简单相关系数。

相关系数的绝对值越大,相关性越强:相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数绝对值 :
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
采用Pearson相关系数检验相关性时,应先检验数据是否服从正态分布:
# pearson data1 = pd.Series(np.random.rand(100)*100).sort_values() data2 = pd.Series(np.random.rand(100)*50).sort_values() data = pd.DataFrame({'value1':data1.values, 'value2':data2.values}) print(data.head()) print('------') # 创建样本数据 u1,u2 = data['value1'].mean(),data['value2'].mean() # 计算均值 std1,std2 = data['value1'].std(),data['value2'].std() # 计算标准差 print('value1正态性检验:\n',stats.kstest(data['value1'], 'norm', (u1, std1))) print('value2正态性检验:\n',stats.kstest(data['value2'], 'norm', (u2, std2))) print('------') # 正态性检验 → pvalue >0.05 data.corr()#pearson相关系数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
value1 value2
0 2.335472 0.214691
1 4.180496 0.325134
2 4.767242 0.946280
3 6.094463 2.159698
4 6.470296 2.838669
------
value1正态性检验:
KstestResult(statistic=0.07415975648701445, pvalue=0.6343538050483026)
value2正态性检验:
KstestResult(statistic=0.08744635124554456, pvalue=0.4091022731946044)
------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

3.Spearman相关系数
Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。斯皮尔曼等级相关是根据等级资料研究两个变量间相关关系的方法。它是依据两列成对等级的各对等级数之差来进行计算的,所以又称为“等级差数法”
斯皮尔曼等级相关对数据条件的要求没有积差相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关来进行研究
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。Pearson相关系数的计算公式可以完全套用 Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
在实际操作中,检验非正态分布变量的相关性可直接调用spearman方法。
data = pd.DataFrame({'智商':[106,86,100,101,99,103,97,113,112,110],
'每周看电视小时数':[7,0,27,50,28,29,20,12,6,17]})
print(data)
print('------')
# 创建样本数据
data.corr(method='spearman')
# pandas相关性方法:data.corr(method='pearson', min_periods=1) → 直接给出数据字段的相关系数矩阵
# method默认pearson
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
智商 每周看电视小时数
0 106 7
1 86 0
2 100 27
3 101 50
4 99 28
5 103 29
6 97 20
7 113 12
8 112 6
9 110 17
------
智商
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

https://blog.csdn.net/ruthywei/article/details/82527400
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/342861
推荐阅读
相关标签

