
- 1网易面试软件测试面试题_网易软件测试面试题
- 2带你快速使用PaddleNLP构建基于Prompt实体情感分类_prompt_model情感分类数据
- 3UBUNTU14.04 下 安装Intel GPU OpenCL runtime_apt install intel runtime
- 4Linux11个主要发行版本_linux发行版
- 5GitHub 上找到的学习AI的路线图 珍藏
- 6墨天轮访谈 | SelectDB 衣国垒:Apache Doris(incubating)1.0版本特性解析与未来规划_selectdb是国产化数据库吗
- 7分类预测 | Matlab实现CNN-GRU-Mutilhead-Attention卷积神经网络-门控循环单元融合多头注意力机制多特征分类预测_matlab mutilhead-attention
- 8openssl+SM2开发实例一(含源码)_openssl sm2
- 9移动互联网产品设计小结_总结移动互联网时代在产品/服务设计时应该注意的事项
- 10WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform...的解决方案_warn [main] util.nativecodeloader: unable to load
ICLR 2024 时间序列相关最新论文汇总,涉及transformer、GNN、大模型等热门领域_iclr2024
赞
踩
ICLR(International Conference on Learning Representations),国际公认的深度学习顶会之一,与AAAI、CVPR、ACL和NIPS等老牌学术会议齐名,由图灵奖巨头Yoshua Bengio和Yann LeCun牵头举办,在人工智能、统计和数据科学以及计算机视觉、语音识别、文本理解等多个重要应用领域中都发表了众多极其有影响力的论文。
本届ICLR 2024会议共收到了7262篇论文,整体接收率约为31%,与去年(31.8%)基本持平。其中Spotlight论文比例为5%,Oral论文比例为1.2%。会议将于2024年5月7日至11日在奥地利维也纳举行,为来自世界各地最杰出的人工智能专家和研究者提供交流平台,共同探讨前沿的深度学习和强化学习领域的最新进展。
本文盘点了 ICLR 2024 有关时间序列领域的最新研究成果,为大家的论文添砖加瓦:
-
transformer:4篇
-
多层感知机:1篇
-
图神经网络:1篇
-
生成模型:4篇
-
即插即用(与模型无关):1篇
-
LLM大模型:2篇
-
预训练与表示:3篇
transformer
TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series
更好、更快、更简单的多元时间序列注意力耦合器
「简述:」论文介绍了一种新的多变量概率时间序列预测模型,旨在灵活地解决一系列任务,包括预测、插值及其组合。基于 copula 理论,作者提出了最近引入的基于 transformer 的注意力 copula(TACTiS)的简化目标,其中分布参数的数量现在与变量的数量成线性关系,而不是成指数关系。新的目标需要引入一个训练课程,这与原始架构的必要更改密切相关。

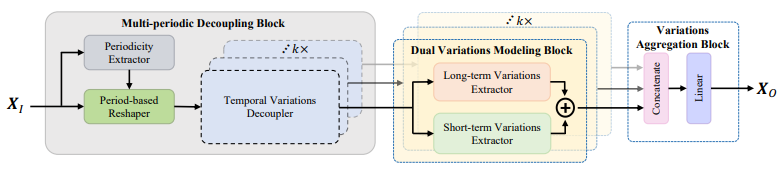
Periodicity Decoupling Framework for Long-term Series Forecasting
长期序列预测的周期性解耦框架
「简述:」论文提出了一种新的周期性解耦框架(PDF),用于捕捉解耦系列的二维时间变化,进行长期系列预测。该框架由三个组件组成:多周期解耦块、双变量建模块和变量聚合块。与之前的方法不同,该方法主要对二维时间变化进行建模,通过解耦一维时间序列来捕捉。实验结果显示,该方法在预测性能和计算效率方面优于其他最先进的方法。
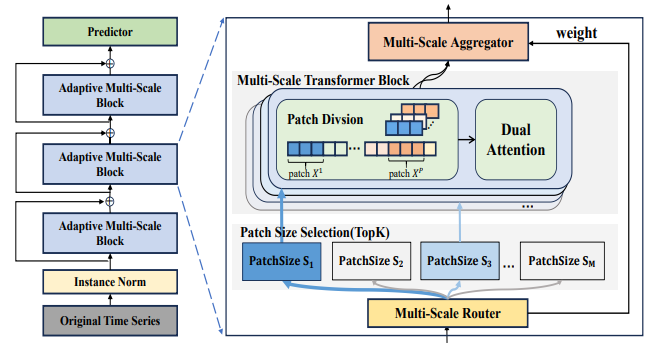
Multi-scale Transformers with Adaptive Pathways for Time Series Forecasting
用于时间序列预测的具有自适应路径的多尺度transformer
「简述:」Transformer模型在时间序列预测中取得了显著成功。但现有方法主要从固定尺度建模,难以捕捉不同尺度的特征。作者提出了一种新的多尺度变压器模型(Pathformer),它结合了时间分辨率和时间距离进行多尺度建模。该模型通过自适应调整多尺度建模过程,提高了预测准确性和泛化能力。在多个真实数据集上的实验表明,Pathformer不仅超越了其他模型,而且具有较强的泛化能力。
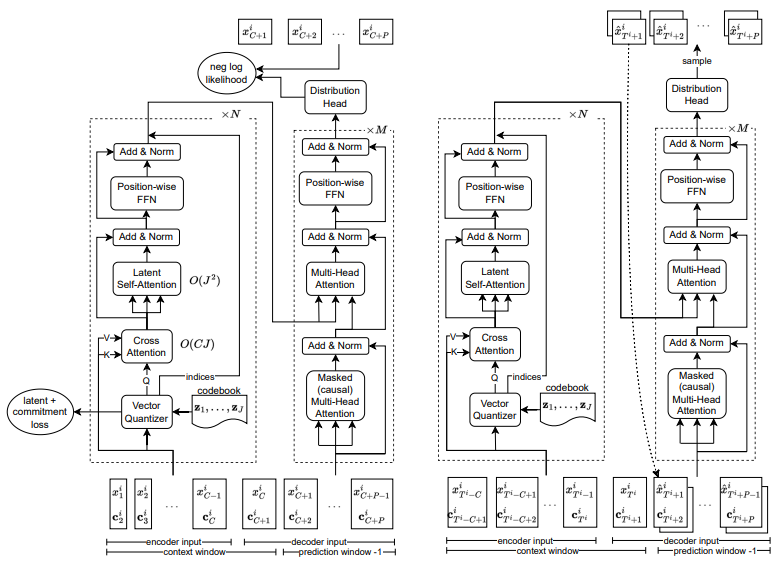
VQ-TR: Vector Quantized Attention for Time Series Forecasting
用于时间序列预测的向量量化注意力
「简述:」作者提出了一种名为VQ-TR的方法,用于时间序列预测。该方法将大型序列映射到离散的表示形式,并将其作为Attention模块的一部分。这使得我们可以在与序列长度成线性关系的较大上下文窗口上进行注意力计算。作者将此方法与其他竞争性的深度学习和经典的单变量概率模型进行比较,并使用各种不同领域的开放数据集的预测指标突出其性能。
多层感知机
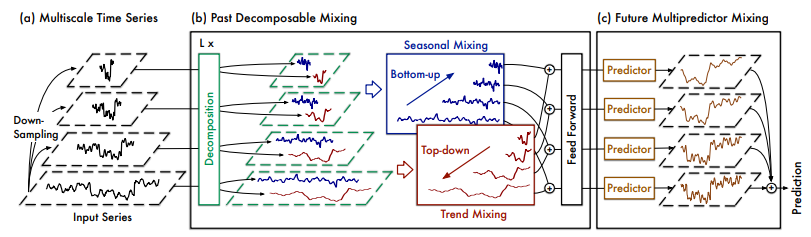
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting
用于时间序列预测的可分解多尺度混合模型
「简述:」论文提出了一种名为TimeMixer的新方法,用于时间序列预测。该方法利用多尺度混合来分析时间序列中的时序变化,并使用基于多层感知机(MLP)的架构来充分利用解耦的多尺度序列。具体而言,该方法包括过去可分解混合和未来多重预测器混合块,以实现良好的预测性能和运行效率。
图神经网络
Biased Temporal Convolution Graph Network for Time Series Forecasting with Missing Values
具有偏置时间卷积图网络的缺失值时间序列预测
「简述:」论文提出了偏置时序卷积图网络(Biased Temporal Convolution Graph Network)新方法,用于处理缺失值的时间序列预测。该方法能够同时捕捉时间依赖性和空间结构,并在两个精心设计的模块中注入偏差以考虑缺失模式。实验结果表明,该方法在五个真实世界的基准数据集上比现有方法提高了9.93%。

生成模型
Generative Learning for Financial Time Series with Irregular and Scale-Invariant Patterns
用于具有不规则和尺度不变模式的金融时间序列的生成式学习
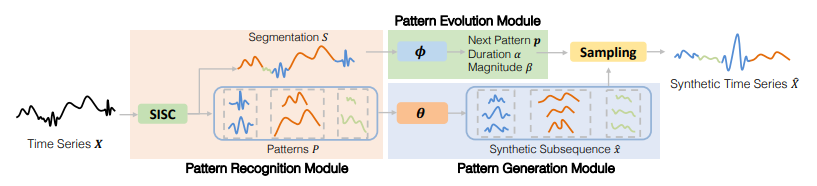
「简述:」对于金融应用中的深度学习模型,训练数据有限是一个大问题。因为金融时间序列有不规则和尺度不变的特点,很难合成真实数据。作者开发了一个新的生成框架,名为FTS-Diffusion,可以模拟这些特点。这个框架有三个模块:模式识别、基于扩散的生成网络和时序转换模型。实验表明,它生成的金融时间序列与真实数据非常相似,优于其他方法。此外,使用它增强的真实数据,股票市场预测的误差减少了多达17.9%。
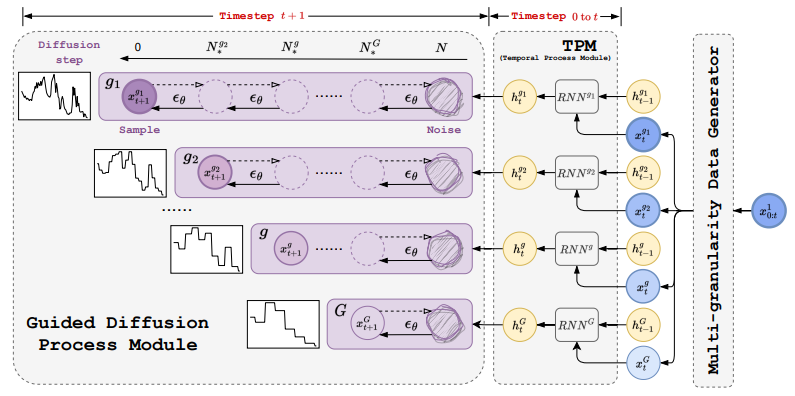
MG-TSD: Multi-Granularity Time Series Diffusion Models with Guided Learning Process
具有引导学习过程的多粒度时间序列扩散模型
「简述:」扩散概率模型能够生成高保真样本,因此受到关注。但其在时间序列预测中的稳定性和利用度有待提升。为解决此问题,作者提出了多粒度时间序列扩散(MG-TSD)模型。该模型利用数据中的固有粒度级别作为目标,指导扩散模型的学过程,实现了先进预测性能。此方法不依赖外部数据,适用于多个领域。实验证明,MG-TSD模型优于现有预测方法。
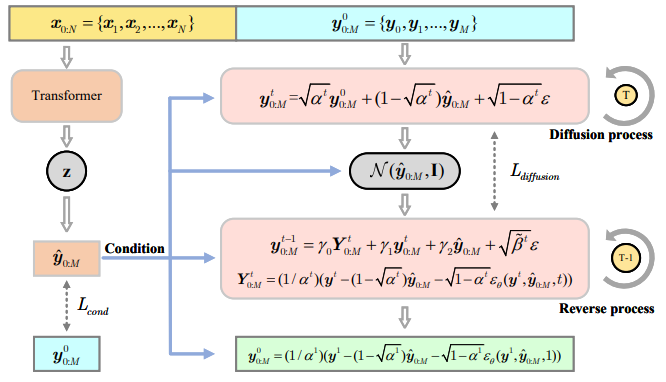
Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting
用于概率多元时间序列预测的Transformer调制扩散模型
「简述:」Transformer在多元时间序列预测中很常用,但现有方法忽视了预测中的不确定性。作者提出了一种Transformer-Modulated Diffusion Model (TMDM),结合条件扩散生成过程和Transformer,以更精确地预测MTS的分布。TMDM利用Transformer提取历史数据的见解,并捕获扩散过程中的协变量依赖性。作者还引入了新指标来评估不确定性估计。实验证明,TMDM在概率MTS预测中很有效。
Multi-Resolution Diffusion Models for Time Series Forecasting
用于时间序列预测的多分辨率扩散模型
「简述:」论文提出了一种名为多分辨率扩散模型(mr-Diff)的新方法,用于利用时间序列数据的多尺度特性进行预测。该方法通过季节性趋势分解,从时间序列中依次提取细到粗的趋势来进行正向扩散。去噪过程以易到难的非自回归方式进行,首先生成最粗糙的趋势,然后逐步添加更精细的细节,并使用预测到的较粗的趋势作为条件变量。在九个真实世界的时间序列数据集上的实验结果表明,mr-Diff优于最先进的时间序列扩散模型,并且在各种先进的时间序列预测模型之间表现良好或相当。

即插即用(与模型无关)
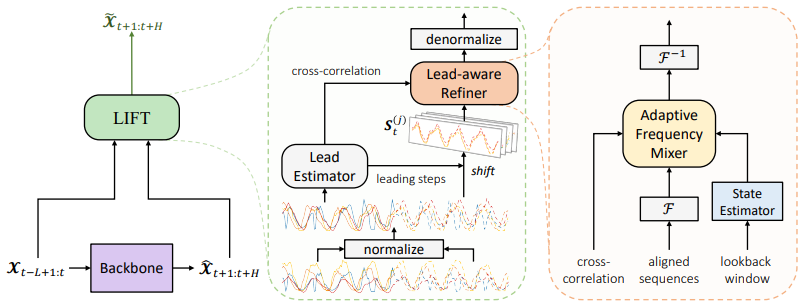
Rethinking Channel Dependence for Multivariate Time Series Forecasting: Learning from Leading Indicators
重新思考多元时间序列预测中的通道依赖性
「简述:」最近,通道独立方法在多元时间序列预测中表现很好。但是这些方法忽略了利用通道依赖性进行准确预测的机会。本文提出了一种名为LIFT的新方法,该方法利用领先指标提供提前信息,帮助滞后变量进行更准确的预测。实验表明,LIFT可以显著提高预测性能。
LLM大模型
TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
文本原型对齐嵌入以激活LLM的时间序列能力
「简述:」论文介绍了两种使用语言模型处理时间序列任务的策略,其中重点介绍了TS-for-LLM方法。该方法通过设计适用于LLM的TS嵌入方法来激活LLM处理TS数据的能力。作者提出了一种名为TEST的方法,它首先将TS进行标记化,然后构建一个编码器,通过实例、特征和文本原型对齐对比来嵌入它们,接着创建提示以使LLM更加开放地接受嵌入,并最终实现TS任务。

Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
通过重新编程大型语言模型进行时间序列预测
「简述:」论文介绍了一种名为Time-LLM的框架,用于重新编程大型语言模型(LLM)以进行一般的时间序列预测。作者提出了一种方法,通过使用文本原型重新编写输入的时间序列来对齐两种模式,并使用Prompt-as-Prefix(PaP)来增强LLM推理时间序列数据的能力。实验结果表明,Time-LLM可以超越最先进的专用预测模型,并在少样本和零样本学习场景中表现出色。

预训练与表示
Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
增强时间序列对比学习
「简述:」本文研究了时间序列对比学习中存在的两种不良正样本对——噪声正样本对和错误正样本对,它们会影响通过对比学习获得的时间序列表示的质量。作者提出了一种名为动态坏对挖掘(DBPM)的算法,该算法可以识别并减少这些不良正样本对的影响,从而提高模型的性能。该方法不需要可学习的参数,易于使用,已在多个真实世界数据集上进行了实验验证。

Soft Contrastive Learning for Time Series
时间序列的软对比学习
「简述:」论文提出了一种名为SoftCLT的时间序列软对比学习策略,通过引入实例和时间上的对比损失,并使用0到1之间的软分配来对它们进行加权,解决了传统对比学习方法忽略时间序列相关性的问题。该方法简单易用,不需要增加复杂度,实验结果表明在各种下游任务中都表现出色,具有最先进的性能。

Learning to Embed Time Series Patches Independently
学习独立嵌入时间序列补丁
「简述:」本文提出了一种名为“独立嵌入时间序列补丁”的方法,用于学习将时间序列数据转换为低维向量表示。该方法的核心思想是分别对每个时间序列补丁进行嵌入,而不是将整个时间序列作为单个实体进行处理。具体来说,该方法使用卷积神经网络(CNN)来提取每个时间序列补丁的特征,并使用最大池化层来减小特征的维度。然后,该方法使用一个全连接层来将这些特征映射到一个固定长度的向量中,以便于后续的任务处理。与传统的时间序列嵌入方法相比,该方法可以更好地捕捉到时间序列数据中的局部模式和相关性。
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

