
- 1面向 AI 的编程 -- 爬虫实战:爬取某乎粉丝_ai爬虫
- 2ASM Disk Group Will not Mount In Presence Of Duplicate Disks / Devices: ORA-15032, ORA-15017, ORA-15...
- 3AI助力90.4%双11前端模块自动生成_基于ai javascript可视化编辑器
- 4【Bert】(六)句子关系判断--源码解析(bert基础模型)_max_position_embeddings
- 5浅谈sysfs系统--文件和目录的创建_zsfs文件为此系统的信息文件,在exit或quit的时候会自动创建在sfs_cache文件夹下。
- 6gateway集成sentinel配置nacos持久化GatewayFlowRule规则后--GatewayFlowRule规则失效(规则的时间单位和时间粒度失效)_在nacos中持久化的规则 加载了 但是不展示
- 7算法·动态规划Dynamic Programming
- 8Pytorch的安装教程从0开始_pytorch 安装
- 9DevOps 发展史_devops发展史
- 10WOT全球技术创新大会2022即将召开,亮点抢先看
LM Studio-简化安装和使用开源大模型 | OpenAI API 文字转语音本地运行程序分享_lm studio ai
赞
踩
原文:LM Studio-简化安装和使用开源大模型 | OpenAI API 文字转语音本地运行程序分享 - 知乎
实测在Mac上使用Ollama与AI对话的过程 - 模型选择、安装、集成使用记,从Mixtral8x7b到Yi-34B-Chat
最近用上了LM Studio,对比Ollama,LM Studio还支持Win端,支持的模型更多,客户端本身就可以多轮对话,而且还支持启动类似OpenAI的API的本地HTTP服务器。
https://lmstudio.ai/
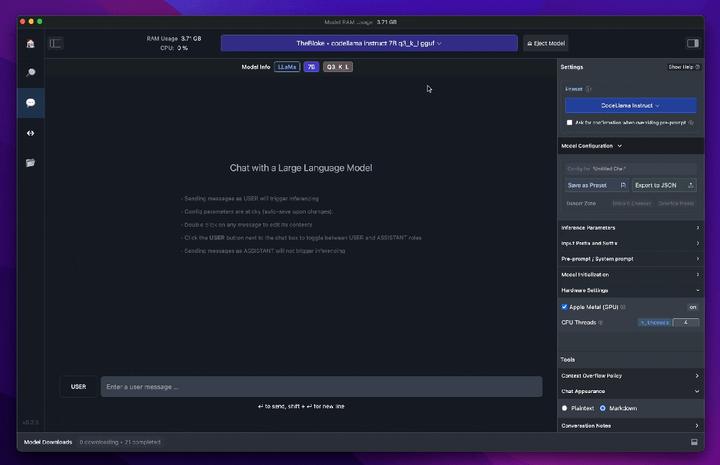
我推荐dolphin-2.6-mistral 7B和dolphin-2.7-mixtral-8x7b模型。


下载后选择模型,设置参数,再重新加载模型。

实测,dolphin-2.6-mistral 7B模型在我Mac M1 Max 32G的电脑上运行速度很快,生成质量不错,而且dolphin是可以生成NSFW内容的。

LM Studio的特色功能
我最喜欢LM Studio的功能是支持启动类似OpenAI API的本地HTTP服务器。

也就是说,如果你之前做过一些应用,用的是OpenAI API的模型,那现在可以非常方便转成本地模型。


从OpenAI API到本地模型:平滑过渡
这里的示例代码非常好用,稍微修改下,既可做本地模型使用,而且也可以写OpenAI的套壳应用。
本地模型chat-python
- # Example: reuse your existing OpenAI setup
- from openai import OpenAI
-
- # Point to the local server
- client = OpenAI(base_url="http://localhost:1234/v1", api_key="not-needed")
-
- completion = client.chat.completions.create(
- model="local-model", # this field is currently unused
- messages=[
- {"role": "system", "content": "Always answer in rhymes."},
- {"role": "user", "content": "how to be happy."}
- ],
- temperature=0.7,
- )
-
- print(completion.choices[0].message.content)

OpenAI-chat-python
- from openai import OpenAI
- import os
-
- client = OpenAI(base_url="https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY/openai/", api_key=os.getenv('OPENAI_API_KEY'))
-
- completion = client.chat.completions.create(
- model="gpt-3.5-turbo-1106",
- messages=[
- {"role": "system", "content": "Always answer in rhymes."},
- {"role": "user", "content": "write a song."}
- ],
- temperature=0.7,
- )
-
- print(completion.choices[0].message.content)
-
Tips:
1. 将你的 OPENAI API 密钥导出为环境变量。
export OPENAI_API_KEY=YOUR_OPENAI_API_KEY2. 这里用到Cloudflare的AI Gateway,方便链接到OpenAI API。
新建网关(下图我已创建了一个),点击openapi-proxy API Endpoints,可以看到ACCOUNT_TAG。

更多OpenAI · Cloudflare AI Gateway docs请看这里:
https://developers.cloudflare.com/ai-gateway/providers/openai
当通过Cloudflare AI Gateway运行后,可以在实时日志里查看每一次调用状态。

利用OpenAI API进行文字转语音
我是在使用LM Studio之前找OpenAI API官方文档,编写了几个本地运行的Python代码,最终做了一个本地的程序。

它帮我解决了一个问题:使用OpenAI API的文字转语音服务,生成视频配音。
这里需要注意下,GPT4里关于OpenAI API的知识不是最新的,需要在OpenAI官方文档里检索。
- https://platform.openai.com/docs/api-reference
-
- https://github.com/openai
下图的信息是过时的。


声音类型

我编写的程序支持选声音、是否合并段落来生成语音。

界面设计:Tldraw与Gradio的应用
我是用Tldraw帮我做的界面,教程请见tldraw make real:利用AI一键从原型图到生成真实可用的代码。


生成的UI代码最后又让GPT4修改了一下。
我还试了不用html,而用Gradio来做UI。
Gradio是一个开源的Python库,它允许用户为机器学习模型构建用户界面,并将其部署在几行代码中。Gradio的主要优势在于其易用性,只需简单定义输入和输出接口,就可以快速构建简单的交互页面,并轻松部署模型。

这个界面大家应该很熟悉,很多大模型的demo用的是这种界面。
由于刚接触Gradio不久,为避免GPT4出现上文OpenAI文档过时的情况,我做了个“Gradio文档助手”GPT来帮我写Gradio代码。
https://www.gradio.app/docs/

我是通过gpt-crawler来获取Gradio文档的。
https://github.com/BuilderIO/gpt-crawler
如它的官网展示,修改的参数很少,很方便就能将文档下载下来。


文本转语音实践:Python代码分享
这里分享直接可以运行的text to speech python代码:
- from openai import OpenAI
- import os
- import datetime
-
- client = OpenAI(base_url="https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY/openai/", api_key=os.getenv('OPENAI_API_KEY'))
-
- # 指定的文本文件路径和语音文件保存路径
- input_file_path = 'text2speech-input.txt'
- current_time = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
-
- # 读取输入文件并生成语音
- with open(input_file_path, 'r') as file:
- lines = file.readlines()
- for i, line in enumerate(lines):
- input_text = line.strip()
- speech_file_path = f'/Users/yourmac/Downloads/{current_time}_{i+1}.mp3'
-
- response = client.audio.speech.create(
- model="tts-1",
- voice="onyx",
- input=input_text
- )
-
- # 保存语音文件
- response.stream_to_file(speech_file_path)
- print(f"Speech {i+1} saved to {speech_file_path}")
-
同目录下新建文件text2speech-input.txt,将要转录的文字放在文档里。
我还编写了根据AI绘图提示词批量生成图片的程序,只是DALLE3的API费用太贵,小试一下。
本地模型与OpenAI模型的结合
回到开头介绍的LM Studio,本地大模型可以完成许多有趣的任务,而不需要调用开销更高的API。例如,本地模型可以生成创意的绘画提示词和主题,以帮助艺术家获得灵感。它们也可以用来写出引人入胜的故事大纲。
除了独立完成这些创作任务外,本地模型还可以与OPENAI等API结合,发挥各自的优势。比如,本地模型可以先生成初始素材,再由OPENAI模型进行细化和提升。这样既节省了调用API的成本,又能发挥大模型的强大能力。探索本地模型和API的最佳组合,能帮助我们在成本和效果之间找到最好的平衡点。
推荐阅读:与AI相关的创新体验
Ollama上线 Nous Hermes 2 与 Dolphin Phi 2.6 模型及 Ollama Web UI 体验分享

