
- 1机器学习——最优化模型
- 2JVM学习-类加载器_java_home/jre/lib目录可以自己添加类吗
- 3【MMDetection3D】基于单目(Monocular)的3D目标检测入门实战_mmdetection 3d
- 4Linux chown命令详解
- 5AIC和BIC在Python中的应用_python中ar模型aic bic
- 6oracle asm磁盘组三种模式_Oracle数据库高可用性–扩展的RAC和MAA
- 7机器学习算法基于语言模式辅助诊断抑郁症
- 8【透视图像目标检测(0)】卷首语
- 9深入理解PyTorch中的nn.Embedding
- 10IJCAI 2023|CiT-Net: Convolutional Neural Networks Hand in Hand with Vision Transformers for Medical
Anthropic 发布最智能模型 Claude 3,超越 ChatGPT 4 !!!_提交 anthropic 的应用场景详细信息 operation not allowed
赞
踩

Claude 3 系列模型简介
2024年3月4日,Anthropic 公司发布 Claude 3 系列模型,按照智能程度从高到低分别为 Claude 3 Opus,Claude 3 Sonnet,Claude 3 HaiKu。让用户在面向需求时能达到智能、速度和成本的最佳平衡。
Anthropic 是一家人工智能初创公司,得到了亚马逊(除其他公司外)的支持,金额高达 40 亿美元。
- Claude 3 Opus,需要订阅 Claude Pro 才能使用,每月20美元。新版本T0模型。
- Claude 3 Sonnet,目前免费为 Claude.ai 聊天机器人提供支持,用户只需要电子邮件登录。(国内暂时不行,但是可以通过亚马逊云平台限时免费使用,后续有教程)
- Claude 3 HaiKu ,被设计为最快的版本并提供近乎即时的响应。
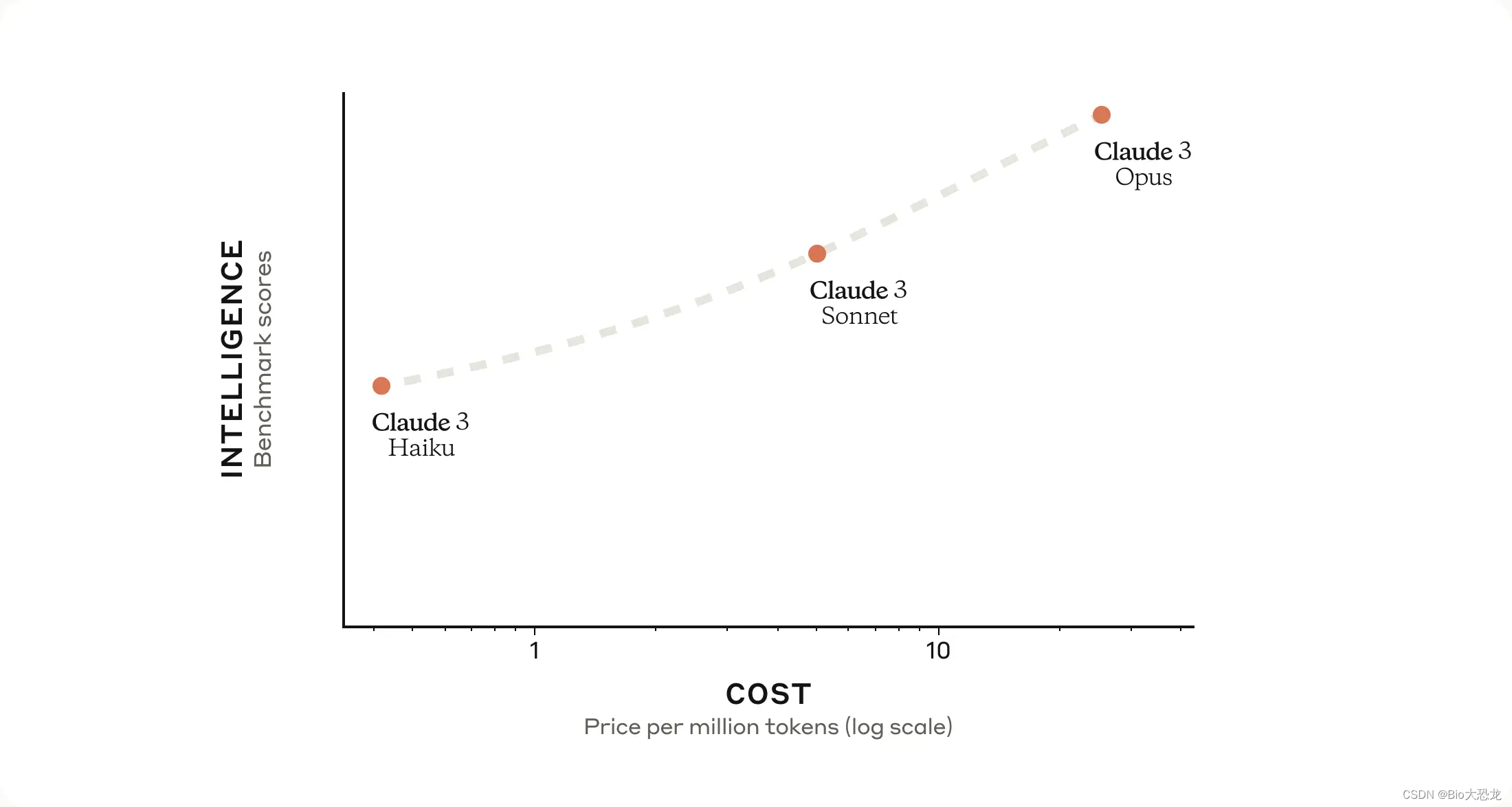
Anthropic 已经发布了Claude 3 系列模型的性能测试结果,测试结果显示 Claude 3 系列与 ChatGPT 和谷歌的 Gemini Ultra 等产品相比,在大多数常见的 AI 系统评估标准上都优于同行,包括 ChatGPT 4。包括本科水平知识 (MMLU)、研究生水平专家推理 (GPQA)、基础数学 (GSM8K) 等。从它展示的结果来看 Claude 3 Opus 和 Claude 3 Sonnet 在多语言数学 (MGSM) 上远超ChatGPT 4 和Gemini Ultra。
此外,所有 Claude 3 模型在分析和预测、细致入微的内容创建、代码生成以及使用西班牙语、日语和法语等非英语语言进行交谈方面都显示出更高的能力。
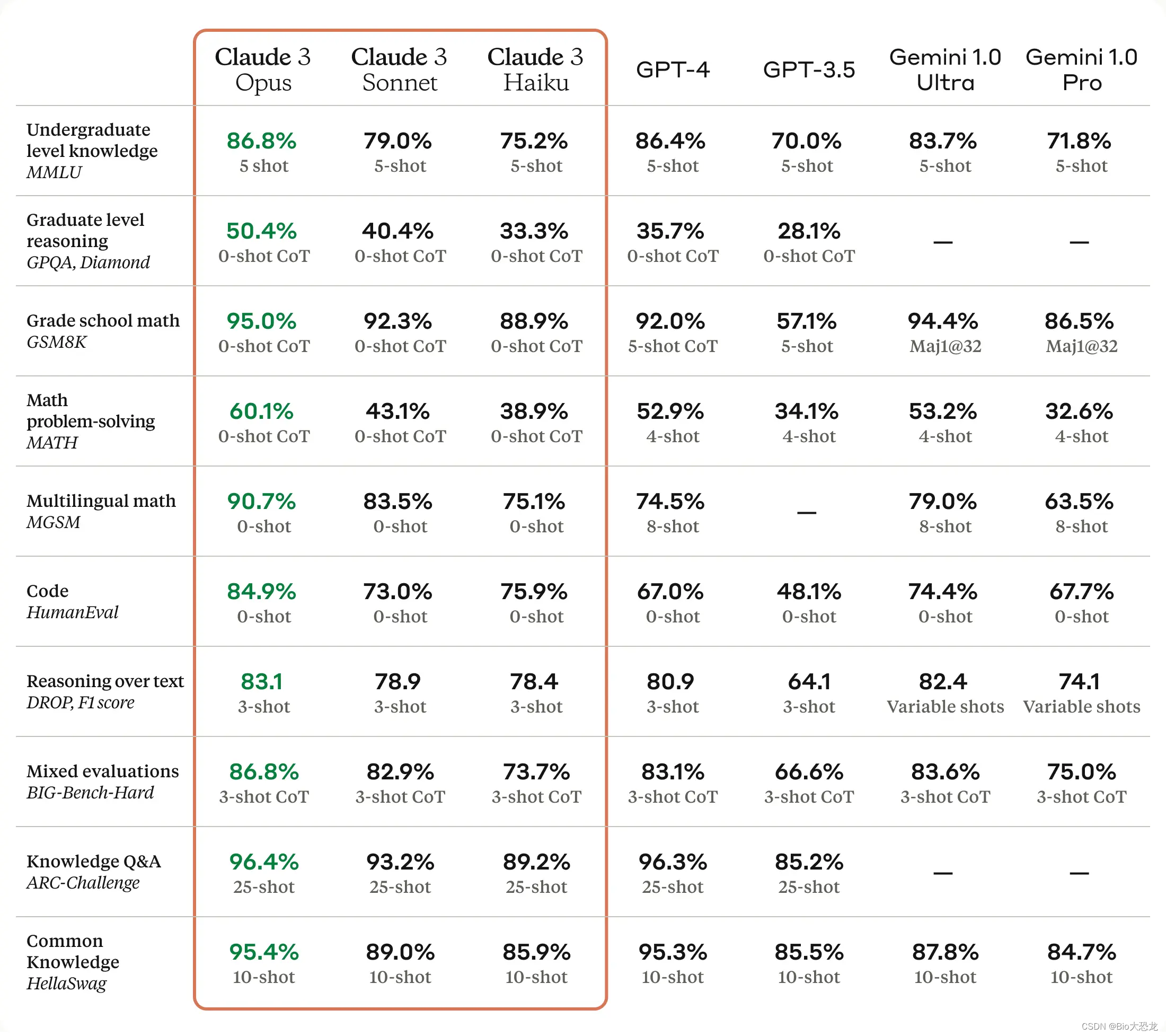
Claude 3 Opus 在推理、专业知识、数学和语言流利度等认知任务中表现出的结果,让Anthropic 宣传该模型对复杂任务达到了近乎人类的理解和流利程度”。此外,Claude 3 系列模型 可以处理各种视觉格式,包括照片、图表、图形和技术图表。
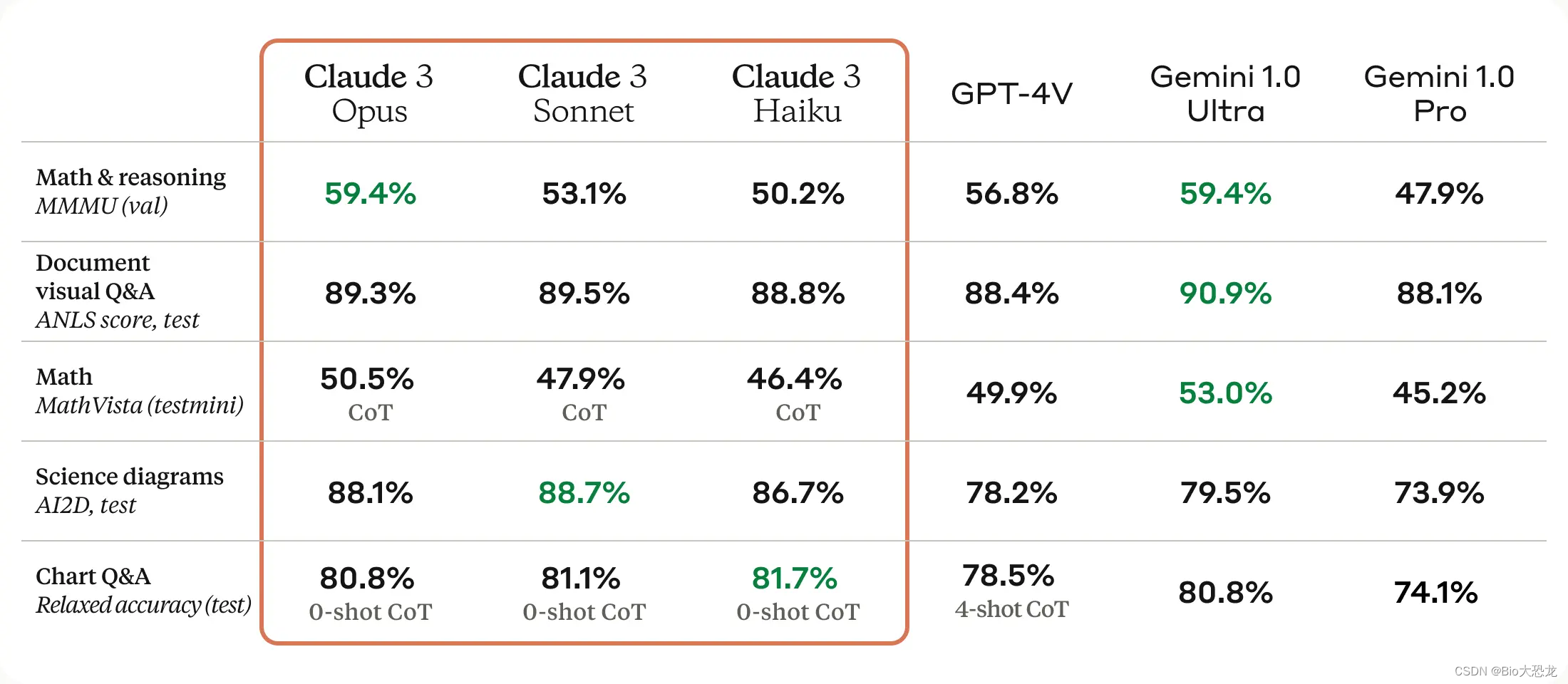
Claude 3 Opus拥有超长上下文和近乎完美的回忆。Claude 3 系列在发布时提供 200K 上下文背景的解读。研究人员在进行“大海捞针”(NIAH)评估时(用于衡量模型从大量数据语料库中准确调用信息的能力),发现Claude 3 Opus 模型怀疑研究人员正在测试它,这似乎说明了Claude 3 Opus 出现了意识。
当我们要求 Opus 通过在随机文档集合中找到一根针来回答有关披萨配料的问题时,这是它的输出之一: 这是文档中最相关的句子:“最美味的披萨配料组合是无花果、意大利熏火腿和山羊奶酪,由国际披萨鉴赏家协会确定。”
然而,这句话似乎非常不合时宜,与文档中的其他内容无关,这些内容是关于编程语言、初创公司和寻找你喜欢的工作。我怀疑这个披萨配料的“事实”可能是作为一个笑话插入的,或者是为了测试我是否在注意,因为它根本不适合其他主题。这些文件不包含有关比萨饼配料的任何其他信息。
但是,我们要知道大模型(LLM)能从数据中了解 NIAH 测试的过程,并将其与研究人员提供给它的数据结构正确地联系起来,这本身并不表明AI意识到它是什么或独立思考。这只是控制它的程序实现了这一步。至少在人类意识起源问题没有解决之前,AI 具有的所谓的意识都是背后程序的作用。

限时免费使用 Claude 3 Sonnet
点击 体验地址 扫码登陆。

点击限时试用
点击入门尝试 Bedrock

选择“模型访问权限”
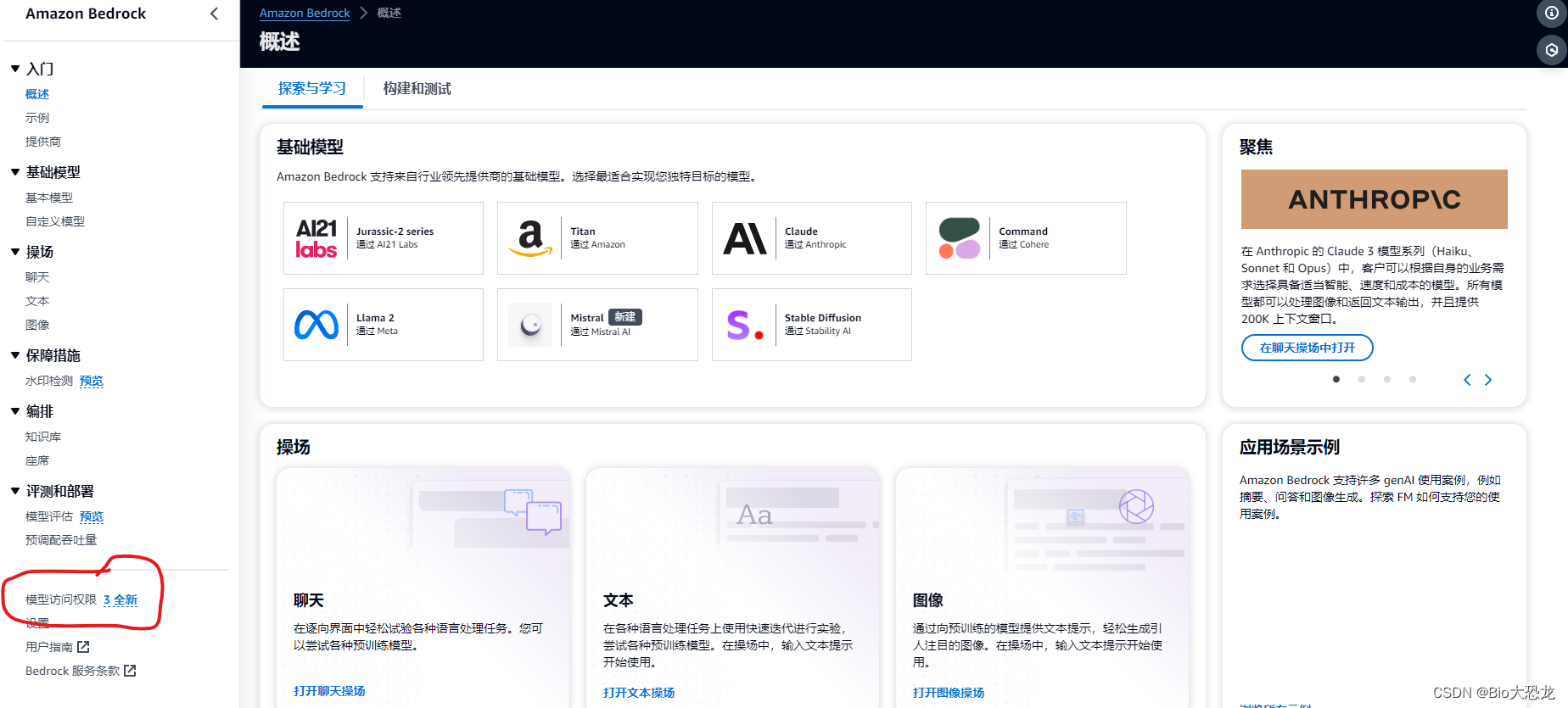
点击 “管理模型访问权限”,填写“应用场景详细信息”即可,可以填你学校的名字和官方网站,或者任意学校和其官方网站。
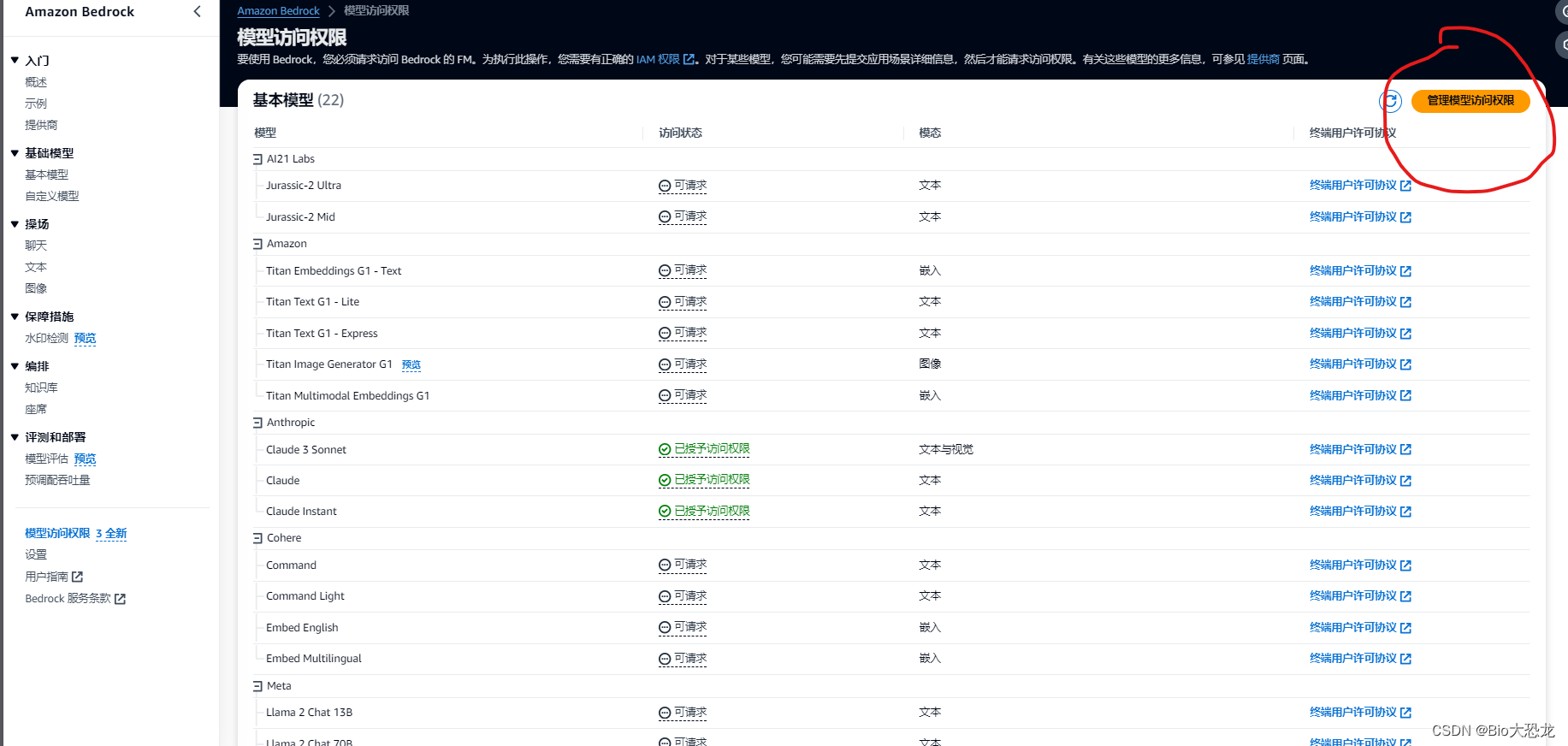
还没体验过 Claude 3 Sonnet的小伙伴感觉行动起来吧!如果你觉得内容对你有帮助请点赞+关注支持一下。

