
- 1mysql字符串位数不够前面补0_mysql位数不足补0
- 2亚马逊云科技 | Bedrock尝鲜全新Claude3(附免费体验名额)_亚马逊云claude3
- 3学习axios必知必会(2)~axios基本使用、使用axios前必知细节、axios和axios实例对象区别、axios拦截器、axios取消请求_axios response config 能做标识符
- 4毕业设计选题基于Java的考研学习交流系统的设计与实现_考研学习交流系统设计与实现
- 5探索VSCode新宠:AI小助手,让你编程如虎添翼!_vscode ai助手
- 620240401 每日AI必读资讯
- 7OSError: cannot write mode RGBA as JPEG解决办法
- 8CSS的@media与@media screen,媒体查询_css @media screen
- 9Spring项目所需的Maven依赖_org.springframework.util.base64utils 哪个maven依赖
- 10NLP机器翻译全景:从基本原理到技术实战全解析_机器翻译原理 词典
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_llam2a 参数
赞
踩
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
导读:2023年7月18日,Meta重磅发布Llama 2!这是一组预训练和微调的大型语言模型(LLM),规模从70亿到700亿个参数不等。Meta微调的LLM称为Llama 2-Chat,专为对话使用场景进行了优化。Llama 2模型在我们测试的大多数基准测试中胜过开源聊天模型,并且根据Meta的人类评估,对于可靠性和安全性,可能是闭源模型的适当替代品。Meta提供了关于如何微调和提高Llama 2-Chat安全性的详细说明,以便让社区在Meta的工作基础上建立并为LBM的负责任开发做出贡献。
Llama 2 = Llama 1【RoPE+RMSNorm+SwiGLU+AdamW】+数据量新增40%+2T的tokens+4096+高质量SFT+RLHF对齐【PPO+Rejection 采样微调】:Llama 2模型是在2万亿个标记上进行训练的,Llama-2-chat模型还额外训练了超过100万个新的人类注释。Llama 2的数据比Llama 1多了40%,上下文长度增加了一倍。并且,Llama-2-chat使用从人类反馈中进行的强化学习来确保安全和有用。Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入。 采用AdamW 优化器进行训练,其中 β_1 = 0.9,β_2 = 0.95,eps = 10^−5。同时使用余弦学习率计划(预热 2000 步),并将最终学习率衰减到了峰值学习率的 10%。Meta 在其研究超级集群(Research Super Cluster, RSC)以及内部生产集群上对模型进行了预训练。
三个常用基准评估了 Llama 2 的安全性:采用 TruthfulQA 基准评估真实性+采用 ToxiGen 基准评估毒性+采用 BOLD 基准评估偏见。Meta 在安全微调中使用监督安全微调、安全 RLHF、安全上下文蒸馏。首先通过收集人类对安全性的偏好数据来进行 RLHF,其中注释者编写他们认为会引发不安全行为的 prompt,然后将多个模型响应与 prompt 进行比较,并根据一系列指南选择最安全的响应。接着使用人类偏好数据来训练安全奖励模型,并在 RLHF 阶段重用对抗性 prompt 以从模型中进行采样。Meta 通过上下文蒸馏完善了 RLHF 流程。
模型性能开源即秀+高昂承本【A100】+依旧走Open路线:Meta两个集群均使用了 NVIDIA A100。HuggingFace 机器学习科学家内森·兰伯特估算 Llama 2 的训练成本可能超过 2500 万美元。Meta公布了Llama 2 模型训练数据、训练方法、数据标注、微调等大量细节,对比发现,同等参数规模, Llama 2 能力超过所有的开源大模型;公布的测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
Llama 2的诞生,以及它开源的脾性,直接硬刚哪些说要Open却一点都不Open、一直在构建“技术围墙”的GPT-4,还有谷歌的PaLM 2。Llama 2将会是LLMs在开源领域的一个重要里程碑,未来将大概率加速改变大语言模型市场的格局和生态。
那么,今天,你的LLMs底座换了吗?
目录
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读
LLMs之LLaMA2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA-2:基于LocalGPT利用LLaMA-2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
T1.2、基于原始LLaMA+国外微调或精调的版本:比如Alpaca、Vicuna
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
☆T1.3、LLaMA的汉化版本——即Chinese-LLaMA-Alpaca+词表扩充的预训练2阶段+指令微调
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
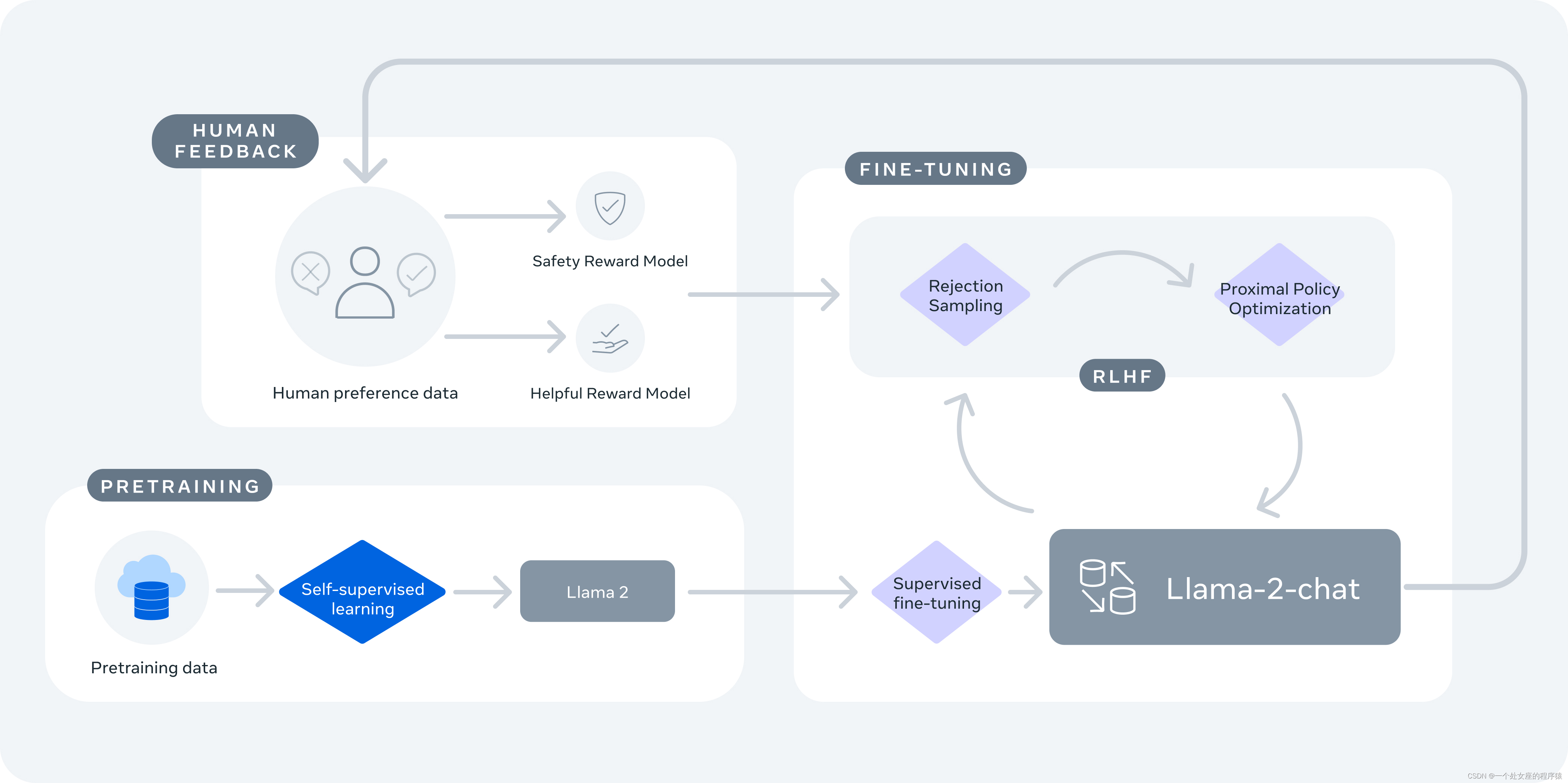
2、Llama-2-chat使用从人类反馈中进行的强化学习来确保安全和有用
相关文章
理论论文相关
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/131318974
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_一个处女座的程序猿的博客-CSDN博客
实战应用相关
T1.1、基于原始LLaMA
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读_ai自然语言处理_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA:在单机CPU+Windows系统上对LLaMA模型(基于facebookresearch的GitHub)进行模型部署且实现模型推理全流程步骤【部署conda环境+安装依赖库+下载模型权重(国内外各种链接)→模型推理】的图文教程(非常详细)
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
https://yunyaniu.blog.csdn.net/article/details/131526139
LLMs之LLaMA2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA-2:源码解读之所有py文件(包括example_text_completion.py/example_chat_completion.py+model.py/generation.py/tokenizer.py)
LLMs之LLaMA-2:基于LocalGPT利用LLaMA-2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
LLMs之LLaMA-2:基于云端进行一键部署对LLaMA-2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数据集【datasets】→加载模型【transformers】→分词→模型训练【peft+SFTTrainer+wandb】→基于HuggingFace实现云端分享)之图文教程详细攻略
LLMs之LLaMA-2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时微调LLaMA2模型(采用Conda环境安装tg webui+PyTorch→CLI/GUI下载模型→启动WebUI服务→GUI式+LoRA微调→加载推理)之图文教程详细攻略
T1.2、基于原始LLaMA+国外微调或精调的版本:比如Alpaca、Vicuna
2023年3月14日——Alpaca(Stanford):使用小成本训练大模型(只需廉价600美元)、利用GPT3.5模型生成高质量的指令数据【175 个prompts+52K指令遵循样本数据】去SFT的LLaMA-7B、 基于LLaMA-7B+微调【HuggingFace框架训练】+Self-Instruct指令跟随语言模型、全分片数据并行+混合精度训练+8个A100-80G三个小时、后期的微调优化Alpace-LoRA
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读_一个处女座的程序猿的博客-CSDN博客
2023年3月30日——Vicuna(Berkeley+CMU+Stanford):训练Vicuna13B仅300美元=8张A100耗费1天+PyTorch FSDP、ShareGPT收集7万段对话、基于Alpaca构建+内存优化(梯度检查点gradient checkpointing+闪光注意力flash attention,最大上下文长度扩展到2048)+多轮对话+管理Spot实例(降低成本)+GPT4模型评估
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
LLMs:在Linux服务器系统上实Vicuna-7B本地化部署(基于facebookresearch的GitHub)进行模型权重合并(llama-7b模型与delta模型权重)、模型部署且实现模型推理全流程步骤的图文教程(非常详细)
https://yunyaniu.blog.csdn.net/article/details/131016620
☆T1.3、LLaMA的汉化版本——即Chinese-LLaMA-Alpaca+词表扩充的预训练2阶段+指令微调
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/131318974
LLMs之Chinese-LLaMA-Alpaca:基于中文汉化版LLaMA(Meta)/Alpaca(斯坦福)开源代码(详细解读多个py文件)基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
https://yunyaniu.blog.csdn.net/article/details/131319010
LLMs之Chinese-LLaMA-Alpaca:源代码解读run_clm_pt_with_peft.py文件实现模型增量预训练(CLI准备【命令行解析/设置日志】→文件设置准备【递增训练/种子/配置字典/分词字典】→数据预处理【文本标记/文本序列长度/token化/分组/切分数据集】→模型训练与评估【判断执行模式/预训练文件/调整词嵌入的大小/LoRA模型/输出可被训练的参数/替换state_dict/初始化Trainer/训练【续载训练/保存结果/度量指标/保存状态】→保存【LoRA模型/预训练配置信息/tokenizer】→验证【计算困惑度/记录评估指标】
https://yunyaniu.blog.csdn.net/article/details/122274996
LLMs之Chinese-LLaMA-Alpaca:源代码解读inference_hf.py文件基于验证数据集(拼接输入数据和模板指令+去空格+分词)利用合并模型(LLaMA+LoRA)实现模型推理(交互方式【实时输出】/非交互方式【导出生成结果和模型配置文件到本地】)
https://yunyaniu.blog.csdn.net/article/details/113482076
LLMs之Chinese-LLaMA-Alpaca:基于单机CPU+Windows系统实现中文LLaMA算法进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版LLaMA转HF格式+合并llama_hf和chinese-alpaca-lora-7b→下载llama.cpp进行模型的量化(CMake编译+生成量化版本模型)→部署f16/q4_0+测试效果】的图文教程(非常详细)
https://yunyaniu.blog.csdn.net/article/details/131016046
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
LLMs:Chinese-LLaMA-Alpaca-2的简介、安装、案例实战应用之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLaMA2的简介
LLaMA2的简介
2023年7月18日,Meta重磅发布Llama 2,就像官网阐述的那样,Meta正在释放这些大型语言模型的力量。Llama 2现在可供个人、创作者、研究人员和企业使用,以便他们能够负责任地实验、创新和扩展他们的想法。此版本包括预训练和微调Llama语言模型的模型权重和起始代码,范围从7B到70B个参数不等。
Llama 2是在公开可用的在线数据源上进行预训练的。经过微调的模型Llama-2-chat利用了公开可用的指令数据集和超过100万个人类注释。在模型内部,Llama 2模型是在2万亿个标记上进行训练的,具有Llama 1的2倍的上下文长度。Llama-2-chat模型还额外训练了超过100万个新的人类注释。Llama 2的数据比Llama 1多了40%,上下文长度增加了一倍。并且,Llama-2-chat使用从人类反馈中进行的强化学习来确保安全和有用。
Llama-2-chat是使用公开可用的在线数据对Llama 2进行预训练。然后使用监督式微调创建Llama-2-chat的初始版本。接下来,使用从人类反馈中进行的强化学习(RLHF)进行Llama-2-chat的迭代优化,其中包括拒绝抽样和近端策略优化(PPO)。
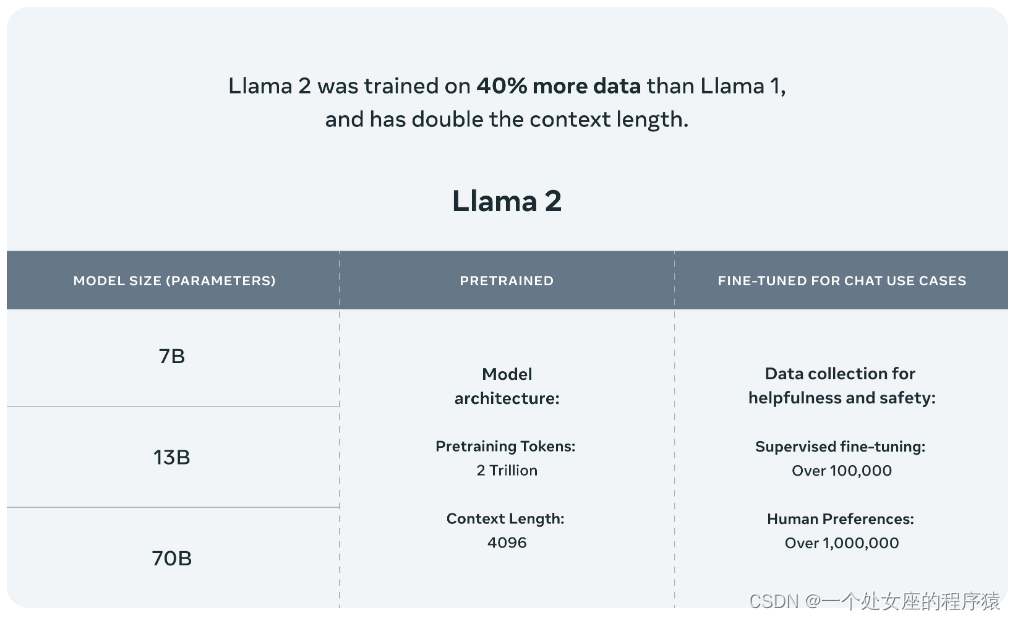
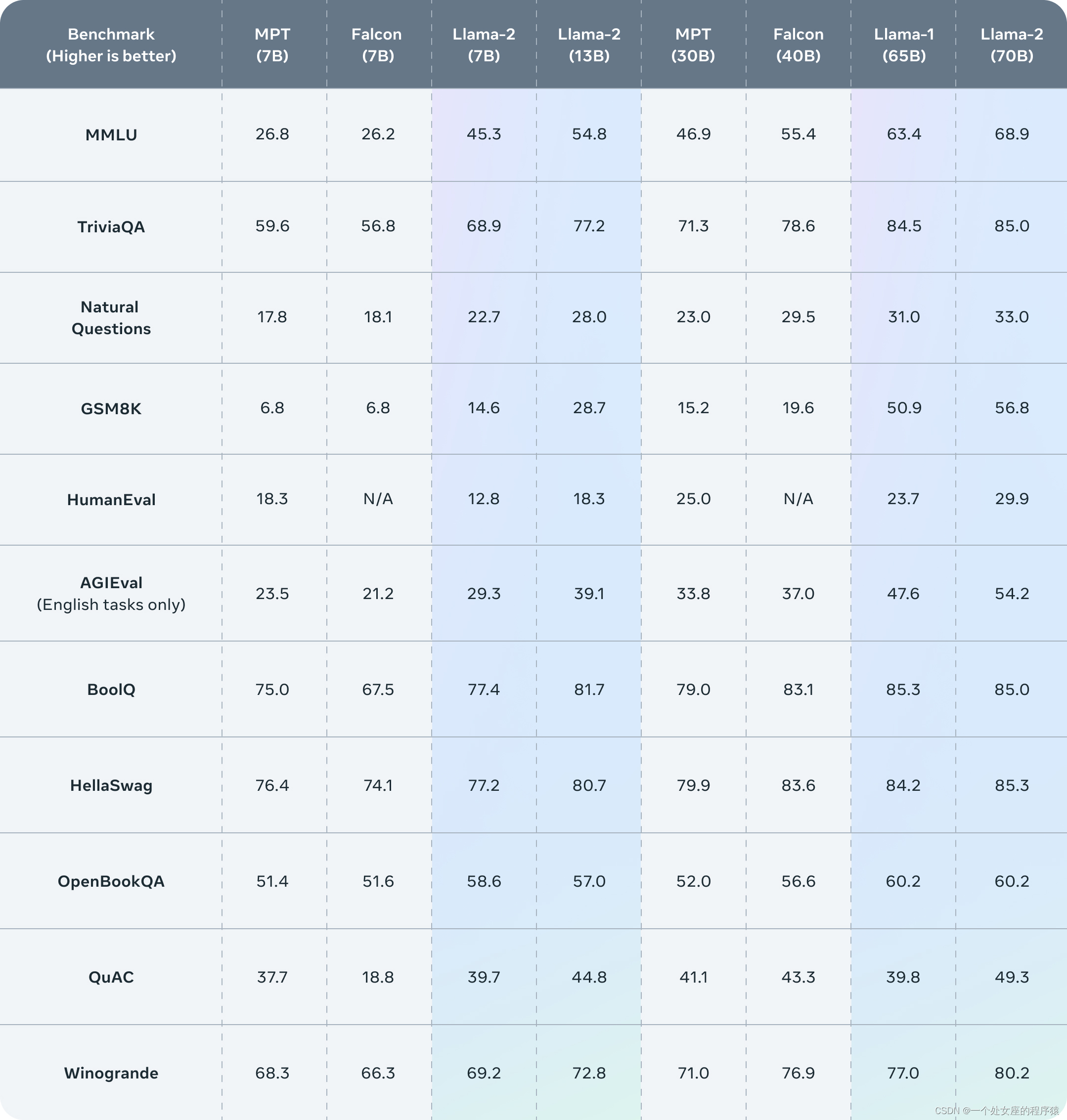
1、基准测试
Llama 2在许多外部基准测试中优于其他开源语言模型,包括推理、编码、熟练度和知识测试。
2、Llama-2-chat使用从人类反馈中进行的强化学习来确保安全和有用
LLaMA2的安装
1、下载下载模型权重和分词器
T1、从官网下载
如果下载模型权重和分词器,需要访问Meta AI网站并接受Meta 的许可。一旦您的请求获得批准,您将通过电子邮件收到签名的URL。然后运行download.sh脚本,在提示开始下载时传递提供的URL。请确保只复制URL文本本身,不要使用右键单击URL时的“复制链接地址”选项。如果复制的URL文本以https://download.llamameta.net开头 ↗,那么您已正确复制它。如果复制的URL文本以https://l.facebook.com开头 ↗,则您复制错误了。
确保已安装wget和md5sum。然后运行脚本:
./download.sh
- 1
T2、基于Hugging Face下载
我们还提供了在Hugging Face上的下载。您必须首先使用与您的Hugging Face帐户相同的电子邮件地址从Meta AI网站请求下载。这样做后,您可以请求访问Hugging Face上的任何模型,在1-2天内,您的帐户将获得访问所有版本的权限。
2、安装
在具有PyTorch/CUDA的conda环境中,克隆存储库并在顶级目录中运行
pip install -e
- 1
LLaMA2的使用方法
1、基础用法
(1)、模型推理
不同的模型需要不同的模型并行(MP)值
| Model | MP |
|---|---|
| 7B | 1 |
| 13B | 2 |
| 70B | 8 |
所有模型都支持最多4096个标记的序列长度,但我们根据max_seq_len和max_batch_size值预分配缓存。因此,请根据您的硬件设置这些值。
(2)、预训练模型
这些模型没有微调为聊天或问答。它们应该被提示,以便预期的答案是提示的自然延续。
有关一些示例,请参见example_text_completion.py。为了说明这一点,请查看下面的命令,以使用llama-2-7b模型运行它(nproc_per_node需要设置为MP值):
-
torchrun --nproc_per_node
1 example_text_completion.py \
-
--ckpt_dir llama-
2-
7b
/ \
-
--tokenizer_path tokenizer.model \
-
--max_seq_len
128 --max_batch_
size
4
- 1
(3)、微调聊天模型
这些经过微调的模型是为对话应用程序而训练的。为了获得预期的特征和性能,需要遵循在chat_completion中定义的特定格式,包括INST和<<SYS>>标签、BOS和EOS标记,以及它们之间的空格和换行符(我们建议对输入调用strip()以避免双空格)。
您还可以部署其他分类器,以过滤出被认为不安全的输入和输出。请参见llama-recipes存储库,了解如何将安全检查器添加到您的推断代码的输入和输出中的示例。
使用llama-2-7b-chat的示例:
-
torchrun --nproc_per_node
1 example_chat_completion.py
-
--ckpt_dir llama-
2-
7b-chat
/
-
--tokenizer_path tokenizer.model
-
--max_seq_len
512 --max_batch_
size
4
- 1
Llama 2是一项新技术,其使用存在潜在风险。到目前为止进行的测试并不能涵盖所有情况。为了帮助开发人员应对这些风险,我们创建了负责任的使用指南。更多详细信息可以在我们的研究论文中找到。

