
- 1python除法向下取整函数_除法:经典除法,向下取整除法和真除法
- 2FPGA 乒乓操作_fpga乒乓操作
- 3十、训练自己的TTS模型_tts 训练
- 4【程序人生】全球首位AI程序员诞生,将会对程序员的影响有多大
- 5Spring Boot面试题 35 问_springboot面试题
- 6完整时间线!李开复Yi大模型套壳争议;第二届AI故事大赛;AI算命GPTs;LLM应用全栈开发笔记;GPT-5提上日程 | ShowMeAI日报_yi和llama的代码对比
- 7RT-DERT改进最新Generalized ELAN核心结构 GELAN【一】 广义的高效层聚合网络GELAN
- 8vue el-tabs 鼠标滚轮滚动切换_vue tabs鼠标移上滑动
- 9java中文分词的简单实现
- 10Git面试题汇总
tensorflow学习笔记(1):tensorflow基础与介绍
赞
踩
引言
作为深度学习方面比较全面的几个框架之一,相比于Keras、pytorch、caffe等库,TensorFlow的优势在于它有一个良好的生态,并且具有一个强大的背景,虽然难度也更高,Keras算是最简单的一个搭建模型的方式,因为它省略了很多中间过程,是Deep learning犹如搭积木,但也因此具有一定局限性,而TensorFlow到目前使用人数还是最多,解决效率高,是Google第二代大规模分布式深度学习框架,具有如下四个特点:
-
灵活通用的深度学习库
-
端云结合的人工智能引擎
-
高性能的基础平台软件
-
跨平台的机器学习系统
tensorflow介绍
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。使用图来表示计算任务. 图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个 Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组. 例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels]。例如下图中的cde皆为op,意思是(3+5)+ 3*5 = 23,但在TensorFlow中需要注意的是 计算定义 != 执行计算,也就是说cde节点并不能打印出计算结果。
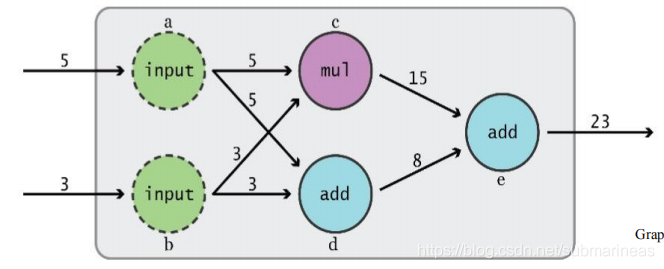
tensor张量
张量(tensor)是TensorFlow管理数据的形式,在TensorFlow所有程序中,所有的数据都是通过张量的形式来表示。从功能的角度上来看,张量可以被简单理解为多维数组。其中零阶张量表示标量,也就是一个数;一阶张量表示一个向量,也就是一个一维数组;n阶张量可以理解为一个n维数组。但张量在TensorFlow中的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
张量主要有三个属性:名字(name)、维度(shape)和类型(type)。如:Tensor(“add:0”, shape=(2,), dtype=float32)就是一个二维矩阵,这个就是一个张量,相同的,下表可以知道张量的具体形式:
| 阶 | 数学实例 | Python 例子 |
|---|---|---|
| 0 | 纯量 (只有大小) | s = 483 |
| 1 | 向量(大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵(数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n | n阶 | 依照前面的例子想象 |
再可以看一个实例说明:
node1 = tf.constant(3.0, dtype=tf.float32)
node2 = tf.constant(4.0)# also tf.float32 implicitly
print(node1, node2)
"""
Tensor("Const_6:0", shape=(), dtype=float32) Tensor("Const_7:0", shape=(), dtype=float32)
"""
node3 = node1 + node2
print(node3)
"""
Tensor("add:0", shape=(), dtype=float32)
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上述正常应该是Const_0:0和Const_1:0,因为我之前定义过常量,所以现在才会往后推。而我们可以看到第二个例子中node3的tensor的表示,它相加的结果并没有显示出来,那么就要引入会话的概念了。
session会话
Session会话是tensorflow里面的重要机制,tensorflow构建的计算图必须通过Session会话才能执行,如果只是在计算图中定义了图的节点但没有使用Session会话的话,就不能运行该节点。比如在tensorflow中定义了两个矩阵a和b,和一个计算a和b相加的c节点,如果想要得到a和b的相加结果(也就是c节点的运算结果)的话,必须要建立Session会话,并调用Session中的run方法运行c节点才行。
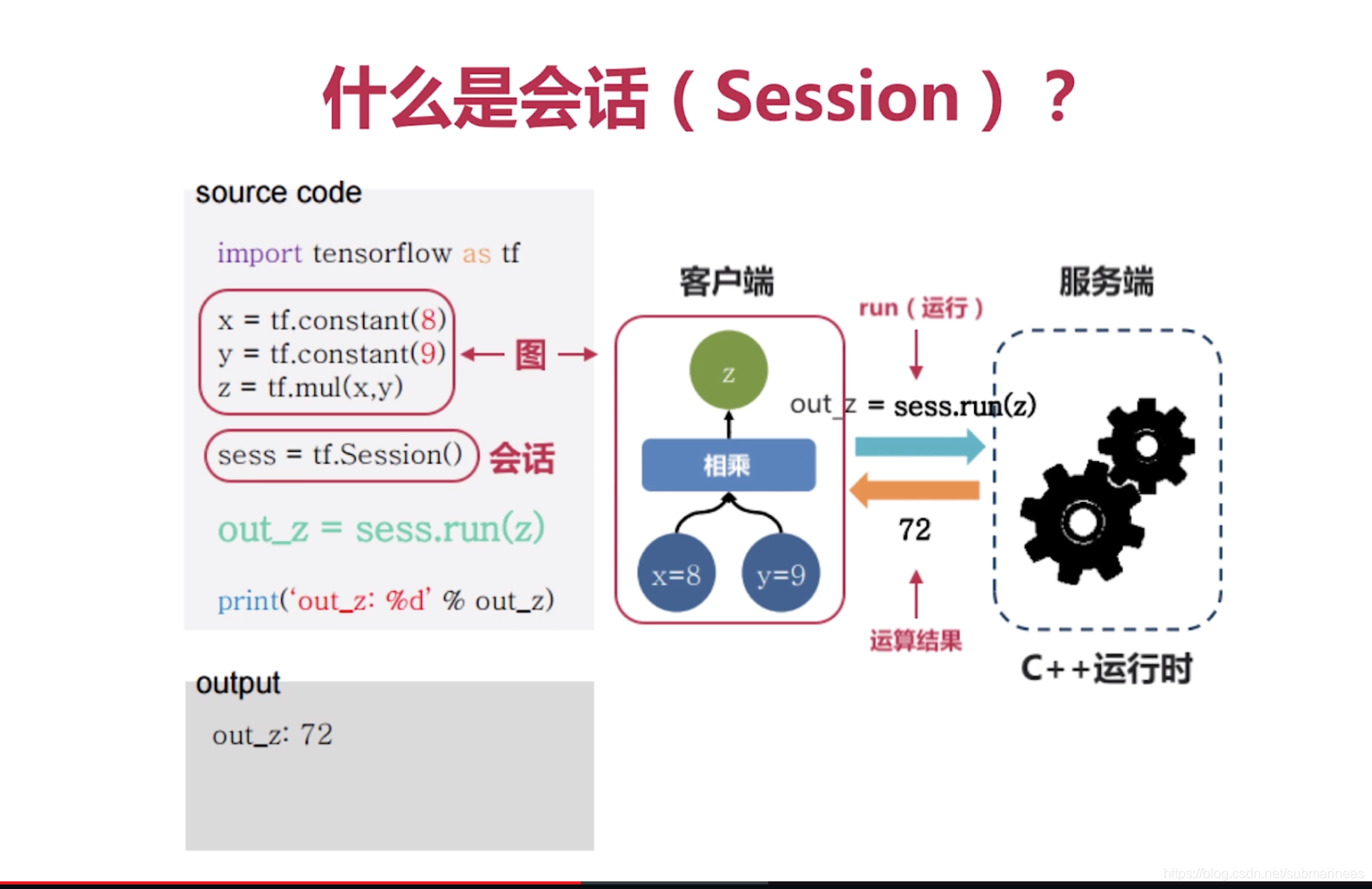
那么我们还是可以拿上面这个例子来运算:
sess=tf.Session()
result=sess.run(node3)
print(result)
sess.close() #关闭session,可有可无,规范是加上了,但不加的话内部会自动加,另外还有第二种写法更标准
"""
7.0
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
第二种就可以不需要写close:
with tf.Session() as sess:
result=sess.run(node3)
print(result) #当代码跳出代码块后自动关闭session
"""
7.0
"""
- 1
- 2
- 3
- 4
- 5
- 6
variable变量
训练模型时,需要使用变量(Variables)保存和更新参数。Variables是包含张量(tensor)的内存缓冲。变量必须要先被初始化(initialize),而且可以在训练时和训练后保存(save)到磁盘中。之后可以再恢复(restore)保存的变量值来训练和测试模型。
变量的使用是有Variable和get_variable两种,下面就介绍一下它内部的异同:
tf.get_variable()和tf.Variable()用法
关于get_variable(),获取已存在的变量(要求不仅名字,而且初始化方法等各个参数都一样),如果不存在,就新建一个。
W = tf.get_variable("W", shape=[784, 256],initializer=tf.contrib.layers.xavier_initializer())
"""
<tf.Variable 'W:0' shape=(784, 256) dtype=float32_ref>
"""
- 1
- 2
- 3
- 4
而tf.Variable()为用于生成一个初始值为initial-value的变量。必须指定初始化值,用法为:
w = tf.Variable(tf.truncated_normal([3,4],mean=0,stddev=.5),name='weight')
"""
<tf.Variable 'weight:0' shape=(3, 4) dtype=float32_ref>
"""
- 1
- 2
- 3
- 4
tf.get_variable()和tf.Variable()的区别
使用tf.Variable时,如果检测到命名冲突,系统会自己处理。使用tf.get_variable()时,系统不会处理冲突,而会报错
import tensorflow as tf
w_1 = tf.Variable(3,name="w_1")
w_2 = tf.Variable(1,name="w_1")
print w_1.name
print w_2.name
#输出
#w_1:0
#w_1_1:0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
import tensorflow as tf
w_1 = tf.get_variable(name="w_1",initializer=1)
w_2 = tf.get_variable(name="w_1",initializer=2)
#错误信息
#ValueError: Variable w_1 already exists, disallowed. Did
#you mean to set reuse=True in VarScope?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
基于这两个函数的特性,当我们需要共享变量的时候,需要使用tf.get_variable()。在其他情况下,这两个的用法是一样的。
更详细的对于两个函数使用以及参数可以看我下面的链接:
tensorflow tf.Variable()和tf.get_variable()详解
tensorflow和numpy的异同
| 说明 | numpy | tensorflow |
|---|---|---|
| 构造数组 | a = np.zeros((2,2)); b = np.ones((2,2)) | a = tf.zeros((2,2)),b = tf.onse((2,2)) |
| 矩阵相加 | np.sum(b,axis=1) | tf.reduce_sum(a,reduction_indices=[1]) |
| 查看维数 | a.shape | a.get_shape() |
| 调整维数 | np.reshape(a,(1,4)) | tf.reshape(a,(1,4)) |
| 数值计算 | b*5+1 | b*5+1 |
| 矩阵乘 | np.dot(a,b) | tf.multiply(a,b) |
| 数组切片 | a[0,0],a[:,0],a[0,:] | a[0,0],a[:,0],a[0,:] |
上表只是说明了其中一部分,其实还是有很多的,我之前写过一篇numpy的总结,等之后TensorFlow熟悉了也进行汇总回顾下:
tensorflow代码示例
import tensorflow as tf import numpy as np # 使用 NumPy 生成假数据(phony data), 总共 100 个点. x_data = np.float32(np.random.rand(2, 100)) # 随机输入 y_data = np.dot([0.100, 0.200], x_data) + 0.300 # 构造一个线性模型 b = tf.Variable(tf.zeros([1])) W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0)) y = tf.multiply(W, x_data) + b # 最小化方差 loss = tf.reduce_mean(tf.square(y - y_data)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # 初始化变量 init = tf.initialize_all_variables() # 启动图 (graph) sess = tf.Session() sess.run(init) # 拟合平面 for step in range(0, 201): sess.run(train) if step % 20 == 0: print(step, sess.run(W), sess.run(b)) """ 0 [[0.20863649 0.17040384]] [0.6597076] 20 [[0.07992584 0.15665914]] [0.335356] 40 [[0.09189988 0.18794507]] [0.31127203] 60 [[0.09710585 0.19647598]] [0.3035966] 80 [[0.0990198 0.19893399]] [0.30114797] 100 [[0.09967679 0.19967039]] [0.3003665] 120 [[0.09989496 0.19989674]] [0.300117] 140 [[0.09996611 0.19996738]] [0.30003735] 160 [[0.09998913 0.19998965]] [0.30001193] 180 [[0.09999651 0.1999967 ]] [0.30000383] 200 [[0.09999888 0.19999894]] [0.3000012] """

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
上面的代码来自TensorFlow中文教程(https://www.tensorflow.org/) ,毫无疑问,最后你和出来的最终结果,应该是[0.1,0.2] [0,3],只不过因为选用参数没达到相应的值而朝该方向过拟合,那么以上就是基础的关于tensorflow的介绍。
参考与推荐:

