
- 1收藏!这 50 道操作系统面试题,真牛!
- 2SeekBar去除左右内边距_android seekbar去除默认 padding
- 3深度学习框架
- 4Hive保姆级教程(万字长文,建议收藏)_hive搭建保姆
- 5平均每月2万起,俗套的BEC攻击成为企业的“噩梦”?
- 6【MATLAB源码-第183期】基于matlab的图像处理GUI很全面包括滤波,灰度,边缘提取,RGB亮度调节,二值化等。
- 7RabbitMQ压测简介_rabbitmq 压测工具
- 8学习索引结构的一些案例——Jeff Dean在SystemML会议上发布的论文(上)_有索引论文的例子
- 9python游戏案例分析_鑫软Python100天系列(Python经典案例分析笔记)循环结构与判断结构例题分析...
- 10云原生架构《一》———全景概述_云原生架构图
一文掌握RabbitMQ核心概念和原理
赞
踩
本文主要通过图文的方式介绍了RabbitMQ核心概念和原理,包括工作模型、交换机类型、交换机和队列的详细属性、过期消息、死信队列、延迟队列、消息可靠性和幂等性、集群分类等方面。
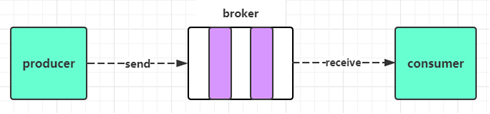
消息中间件
概念
消息中间件就是指保存数据的一个容器(服务器),可以用于两个系统之间的数据传递。消息中间件一般有三个主要角色:生产者、消费者、消息代理(消息队列、消息服务器);生产者发送消息到消息服务器,然后消费者从消息代理(消息队列)中获取数据并进行处理;
应用场景
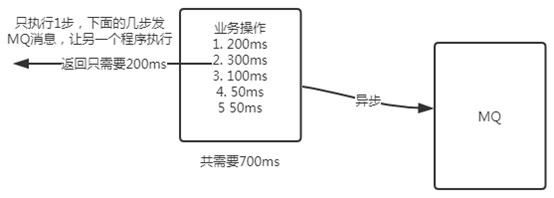
1.异步处理
一个主流程含有多个子流程的情况下,各个子流程可以借用消息中间件实现异步处理,从而加快处理速率。例如业务有5个子流程,但其余4个子流程无需返回给用户的情况:
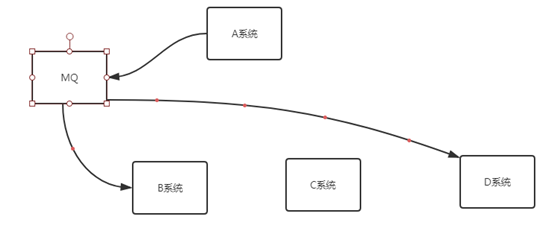
2.系统解耦
多个系统之间,不需要直接交互,通过消息进行业务流转
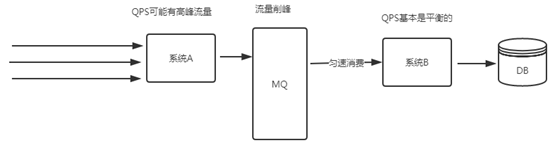
3.流量削峰
高负载请求/任务的缓冲处理
4.日志处理
解决大量日志传输问题,一般使用kafka
RabbitMQ工作模型和基本概念
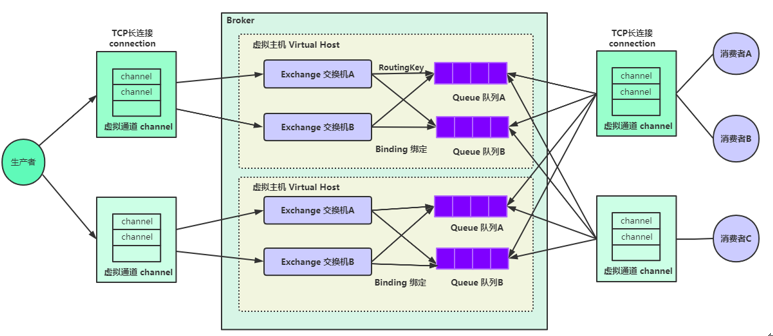
对于以上模型的关键要素解释,可用同比mysql为例进行解释:
broker 相当于mysql服务器
virtual host 相当于数据库(可以有多个数据库)
queue 相当于表
queue 中的消息相当于表中的记录。
核心概念汇总
| 概念 | 说明 |
|---|---|
| 生产者 Producer | 发送消息的应用;(java程序,也可能是别的语言写的程序) |
| 消费者 Consumer | 接收消息的应用;(java程序,也可能是别的语言写的程序) |
| 代理 Broker | 就是消息服务器,RabbitMQ Server就是Message Broker |
| 连接 Connection | 连接RabbitMQ服务器的TCP长连接 |
| 信道 Channel | 连接中的一个虚拟通道,消息队列发送或者接收消息时,都是通过信道进行的 |
| 虚拟主机 Virtual host | 一个虚拟分组,可以划分出多个Virtual host,每个Virtual host创建exchange/queue等(分类比较清晰、相互隔离) |
| 交换机 Exchange | 交换机负责从生产者接收消息,并根据交换机类型分发到对应的消息队列中,起到一个路由的作用 |
| 路由键 Routing Key | 交换机根据路由键来决定消息分发到哪个队列,路由键是消息的目的地址 |
| 绑定 Binding | 绑定是队列和交换机的一个关联连接(关联关系) |
| 队列 Queue | 存储消息的缓存 |
| 消息 Message | 由生产者通过RabbitMQ发送给消费者的信息;(消息可以任何数据,字符串、user对象,json串等等) |
RabbitMQ交换机类型
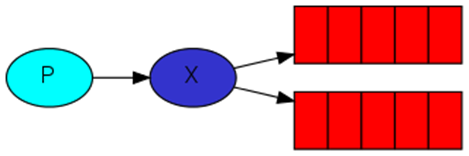
1.Fanout Exchange(扇形)
投递到所有绑定的队列,不需要路由键,不需要进行路由键的匹配,相当于广播、群发
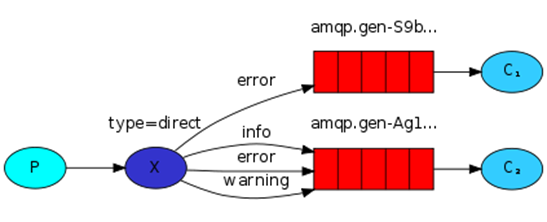
2.Direct Exchange(直连)
根据路由键精确匹配(一模一样)进行路由消息队列
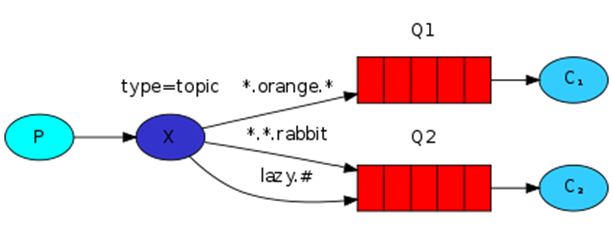
3.Topic Exchange(主题)
通配符匹配,相当于模糊匹配;
#号,匹配多个单词,用来表示任意数量(零个或多个)单词
*号,匹配一个单词(必须有一个,而且只有一个),用.隔开的为一个单词:
示例:
beijing.# == beijing.queue.abc, beijing.queue.xyz.xxx
beijing.* == beijing.queue, beijing.xyz
- 1
- 2
4.Headers Exchange(头部)
基于消息内容中的headers属性进行匹配;
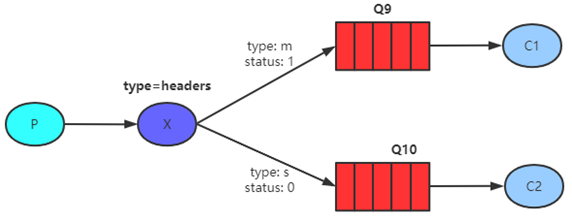
示例:
MessageProperties messageProperties = new MessageProperties();
messageProperties.setHeader("type", "m");
messageProperties.setHeader("status", 1);
- 1
- 2
- 3
经过以上配置后,消息发送时会路由到对应队列中,例如图中的Q9队列
交换机详细属性
| 属性 | 解释 |
|---|---|
| Name | 交换机名称;就是一个字符串 |
| Type | 交换机类型,direct, topic, fanout, headers四种 |
| Durability | 持久化,声明交换机是否持久化,代表交换机在服务器重启后是否还存在 |
| Auto delete | 是否自动删除,曾经有队列绑定到该交换机,后来解绑了,那就会自动删除该交换机 |
| Internal | 内部使用的,如果是yes,客户端无法直接发消息到此交换机,它只能用于交换机与交换机的绑定 |
| Arguments | 只有一个取值alternate-exchange,表示备用交换机 |
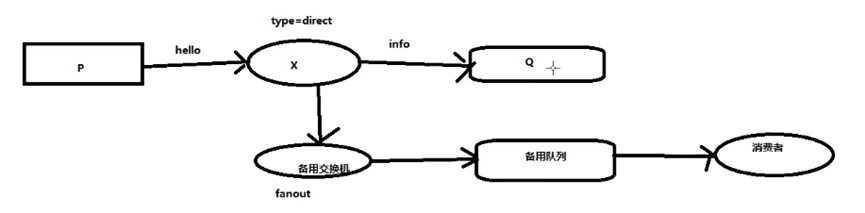
备用交换机
当消息经过交换器准备路由给队列的时候,发现没有对应的队列可以投递信息,在rabbitmq中会默认丢弃消息,如果我们想要监测哪些消息被投递到没有对应的队列,我们可以用备用交换机来实现,可以接收备用交换机的消息,然后记录日志或发送报警信息。概念示意图如下,x表示正常交换机
队列详细属性
| 属性 | 解释 |
|---|---|
| Name | 交换机名称;就是一个字符串 |
| Type | 交换机类型,direct, topic, fanout, headers四种 |
| Durability | 持久化,声明交换机是否持久化,代表交换机在服务器重启后是否还存在 |
| Auto delete | 是否自动删除,曾经有队列绑定到该交换机,后来解绑了,那就会自动删除该交换机 |
| Internal | 内部使用的,如果是yes,客户端无法直接发消息到此交换机,它只能用于交换机与交换机的绑定 |
Arguments | 只有一个取值alternate-exchange,表示备用交换机 |
Arguments 详细参数
| 参数 | 含义 |
|---|---|
| x-expires | 当Queue(队列)在指定的时间未被访问,则队列将被自动删除 |
| x-message-ttl | 发布的消息在队列中存在多长时间后被取消(单位毫秒) |
| x-overflow | 设置队列溢出行为,当达到队列的最大长度时,消息会发生什么,有效值为Drop Head或Reject Publish |
| x-max-length | 队列所能容下消息的最大长度,当超出长度后,新消息将会覆盖最前面的消息,类似于Redis的LRU算法 |
| x-single-active-consumer | 激活单一的消费者,也就是该队列只能有一个消息者消费消息,默认为false |
| x-max-length-bytes | 限定队列的最大占用空间,当超出后也使用类似于Redis的LRU算法 |
| x-dead-letter-exchange | 指定队列关联的死信交换机,有时候我们希望当队列的消息达到上限后溢出的消息不会被删除掉,而是走到另一个队列中保存起来 |
| x-dead-letter-routing-key | 指定死信交换机的路由键,一般和6一起定义 |
| .x-max-priority | 如果将一个队列加上优先级参数,那么该队列为优先级队列 |
过期消息
过期消息也叫TTL消息,TTL:Time To Live。有以下两种方式来设置过期消息
1.设置单条消息的过期时间
MessageProperties messageProperties = new MessageProperties();
messageProperties.setExpiration("15000"); // 设置过期时间,单位:毫秒
- 1
- 2
2.通过队列属性设置消息过期时间:
@Bean
public Queue directQueue() {
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-message-ttl", 10000);
return new Queue(DIRECT_QUEUE, true, false, false, arguments);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
死信队列
DLX: Dead-Letter-Exchange 死信交换器
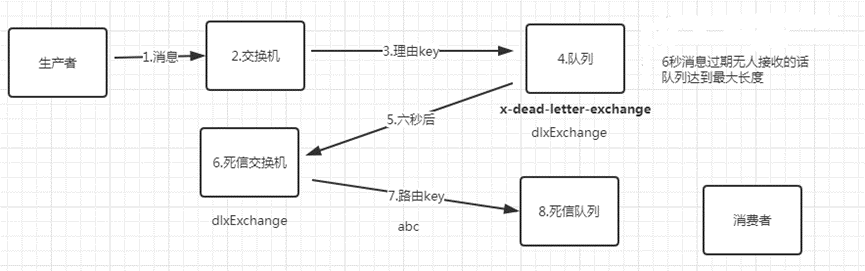
如下情况下一个消息会进入DLX(Dead Letter Exchange)死信交换机
1.消息过期
2.队列过期
3.队列达到最大长度(先入队的消息会被发送到DLX)
4.消费者对消息不进行确认,并且不对消息进行重新投递
5.消费者拒绝消息
延迟队列
RabbitMQ本身不支持延迟队列,可以使用TTL结合DLX的方式来实现消息的延迟投递,即把DLX跟某个队列绑定,到了指定时间,消息过期后,就会从DLX路由到这个队列,消费者可以从这个队列取走消息。
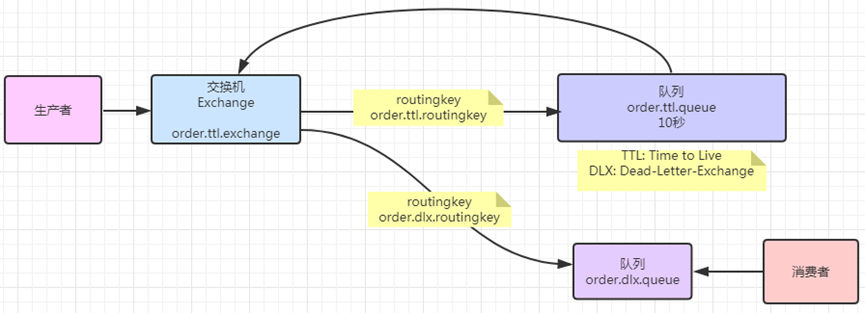
问题: 如果先发送的消息,消息延迟时间长,会影响后面的延迟时间段的消息的消费;
解决:不同延迟时间的消息要发到不同的队列上,同一个队列的消息,它的延迟时间应该一样
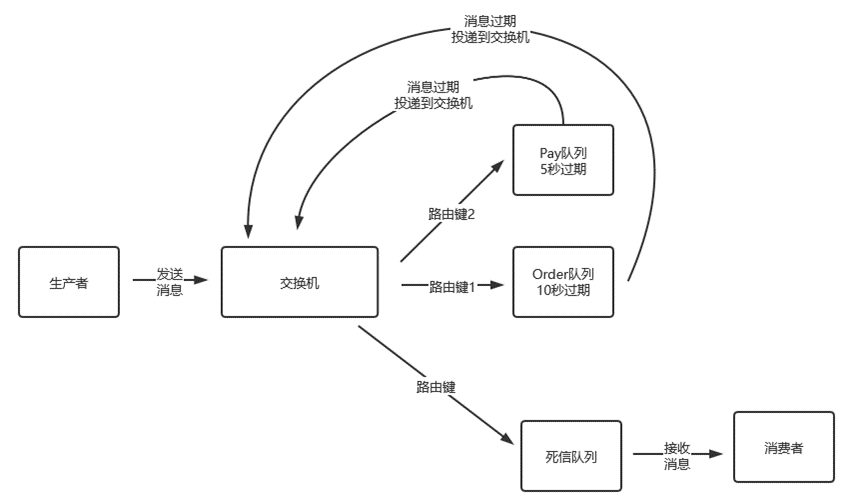
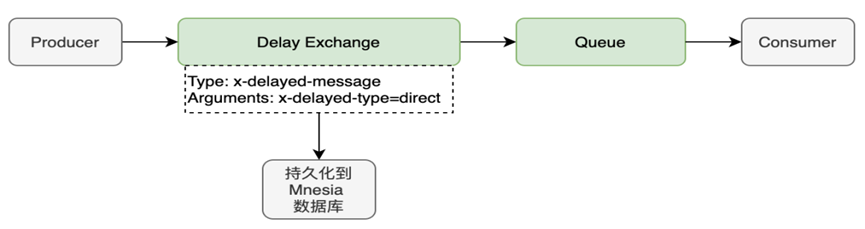
rabbitmq提供插件,可以实现延迟队列功能。
rabbitmq-delayed-message-exchange 延迟插件原理:
消息发送后不会直接投递到队列,而是存储到 Mnesia(嵌入式数据库)
消息可靠性
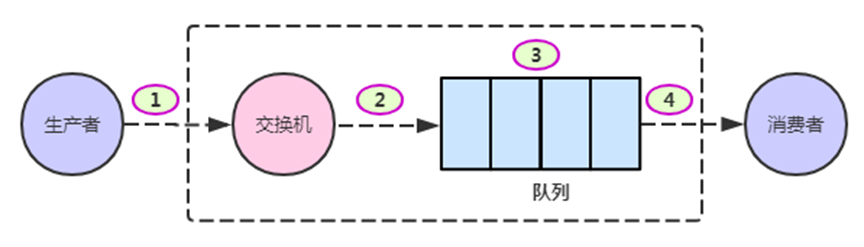
可通过以下方式保证上图每个环节的可靠性
1.确保消息发送到RabbitMQ服务器的交换机上
Confirm(确认)模式
2.确保消息路由到正确的队列
return模式,可以实现消息无法路由的时候返回给生产者;
另一种方式就是使用备份交换机
3.确保消息在队列正确地存储
队列、交换机、消息持久化
4.消费者监听Queue并消费消息
采用消息消费时的手动ack确认机制来保证,配置开启手动消息消费确认
spring.rabbitmq.listener.simple.acknowledge-mode=manual
消息Confirm确认模式
消息的confirm确认机制,是指生产者投递消息后,到达了消息服务器Broker里面的exchange交换机,则会给生产者一个应答,生产者接收到应答,用来确定这条消息是否正常的发送到Broker的exchange中,这也是消息可靠性投递的重要保障;
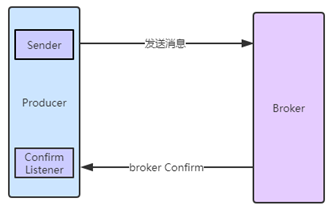
配置文件application.yml 开启确认模式:设置关联模式
spring.rabbitmq.publisher-confirm-type=correlated
- 1
代码:写一个类实现implements RabbitTemplate.ConfirmCallback
消息Return返回模式
rabbitmq 整个消息投递的路径为:
producer —> exchange —> queue —> consumer
【Confirm确认模式】消息从 producer –> exchange 则会返回一个 confirmCallback;
【Return返回模式】消息从 exchange –> queue 投递失败则会返回一个 returnCallback;
配置中开启return模式
spring.rabbitmq.publisher-returns: true
- 1
代码:写一个类实现implements RabbitTemplate.ReturnsCallback
消息的幂等性
消息消费时的幂等性是指消息不被重复消费。同一个消息,第一次接收,正常处理业务,如果该消息第二次再接收,那就不能再处理业务,否则就处理重复了;一般来说,增删改都是非幂等的。
如何避免消息的重复消费问题:全局唯一ID + Redis
生产者在发送消息时,为每条消息设置一个全局唯一的messageId,消费者拿到消息后,使用setnx命令,将messageId作为key放到redis中:setnx(messageId, 1),若返回1,说明之前没有消费过,正常消费;若返回0,说明这条消息之前已消费过,抛弃;
集群与高可用
分布式系统一定是集群的,首先解决单点故障问题(SPOF)。RabbitMQ 的集群分两种模式,一种是默认集群模式,一种是镜像集群模式;
在RabbitMQ集群中所有的节点(一个节点就是一个RabbitMQ的broker服务器) 被归为两类:一类是磁盘节点【至少要有1个】,一类是内存节点;至少要有一个磁盘节点是为了避免关机后数据消失。
默认集群模式
RabbitMQ默认集群模式,只会把交换机、队列、虚拟主机等元数据信息在各个节点同步,而具体队列中的消息内容不会在各个节点中同步;
元数据:数据的数据。队列名称和属性;交换器名称、类型和属性
消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中获取消息进行消费【生产也是类似】
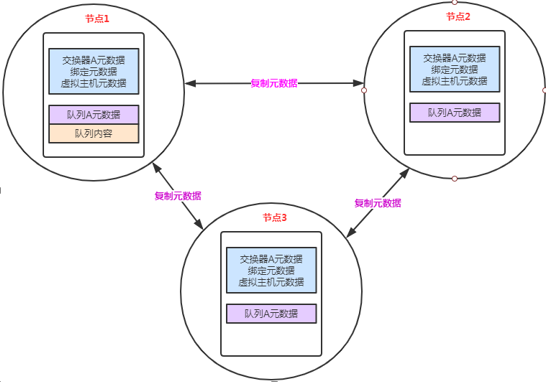
镜像集群模式
把所有的队列数据完全同步,包括元数据信息和消息数据信息
参考来源
动力节点RabbitMQ教程
觉得文章有帮助可以点个赞或关注支持一下哟~

