
热门标签
热门文章
- 1基于node的毕业设计学生宿舍寝室管理系统
- 2创建Git本地仓库并同步远程Github_github本地项目同步
- 3使用Python解决汉诺塔问题_python汉诺塔
- 4搭建测试环境遇到的问题_net-tools is needed by mysql-community-server-8.0.
- 5GitHub 干货 | 各大数据竞赛 Top 解决方案开源汇总_百度 光伏 数据 竞赛 github, bing
- 6bert模型简介、transformers中bert模型源码阅读、分类任务实战和难点总结_bert模型难点
- 7Android中的设计模式之代理模式_android代理模式的应用场景
- 8Java类加载_-xx:reservedcodecachesize
- 9spring的refresh
- 10python每日一题——8无重复字符的最长子串_无重复字符的最长子串 python
当前位置: article > 正文
ClickHouse--17--聚合函数总结
作者:知新_RL | 2024-04-18 10:08:38
赞
踩
ClickHouse--17--聚合函数总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 环境
- 函数
- (1)count:计算行数
- (2)min:计算最小值
- (3)max:计算最大值
- (4)sum:计算总和,只能计算数字之和
- (5)avg:算数平均值,仅支持数字
- (6)any: 选择第一个遇到的值
- (7)anyHeavy:列出频繁出现的值,一般情况,结果是不确定的
- (8)anylast:选出最后一个出现的值
- (9)argMin
- (10)argMax:类比argMin
- (11)avgWeighted(x, weight):加权算数平均值,x为值,weight为值的加权
- (12)topK(num)(col):
- (13)topKWeighted(num)(col,weight):
- (14)groupArray:生成数组
- (15)groupUniqArray:类似于groupArray,不过会将生成的数组去重
- (16)groupArrayInsertAt:参数指定位置插入数组
- (17)groupArraySample(max_size)(arg)
- (18)uniq:计算字段去重后的近似数量
- (19)uniqExact:计算不同参数值的准确数量
- (20)uniqCombined:
- (21)quantile(level)(arg):
- (22)quantiles(level1,level2...)(arg):可以同时计算多个分位数,返回结果为数组
环境
1.创建clickhouse表
CREATE TABLE ck_test
(
`id` String COMMENT 'id',
`int_1` UInt32 COMMENT '整型列1',
`int_2` UInt32 COMMENT '整型列2',
`str_1` String COMMENT '字符串列1',
`str_2` String COMMENT '字符串列2'
)
ENGINE = MergeTree
ORDER BY id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.插入数据
insert into ck_test values (1,1,10,'a','A'),(2,2,12,'b','B'),(3,3,13,'c','C'),
(4,4,14,'d','D'),(5,5,15,'e','E'),(6,6,15,'f','F')
(7,6,15,'f','F');
- 1
- 2
- 3
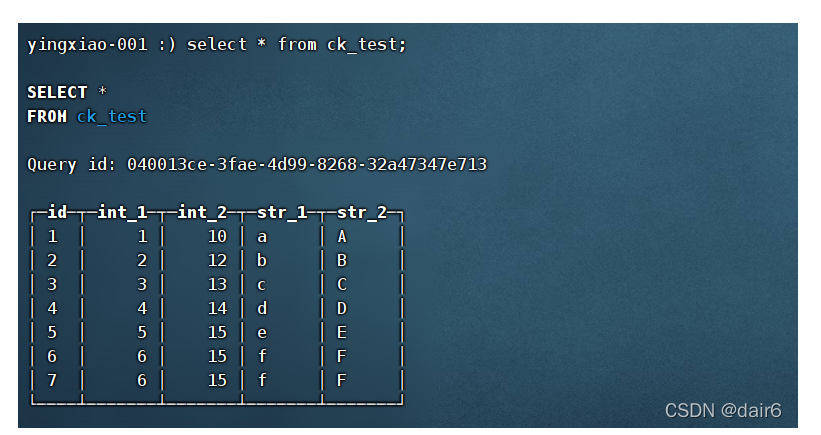
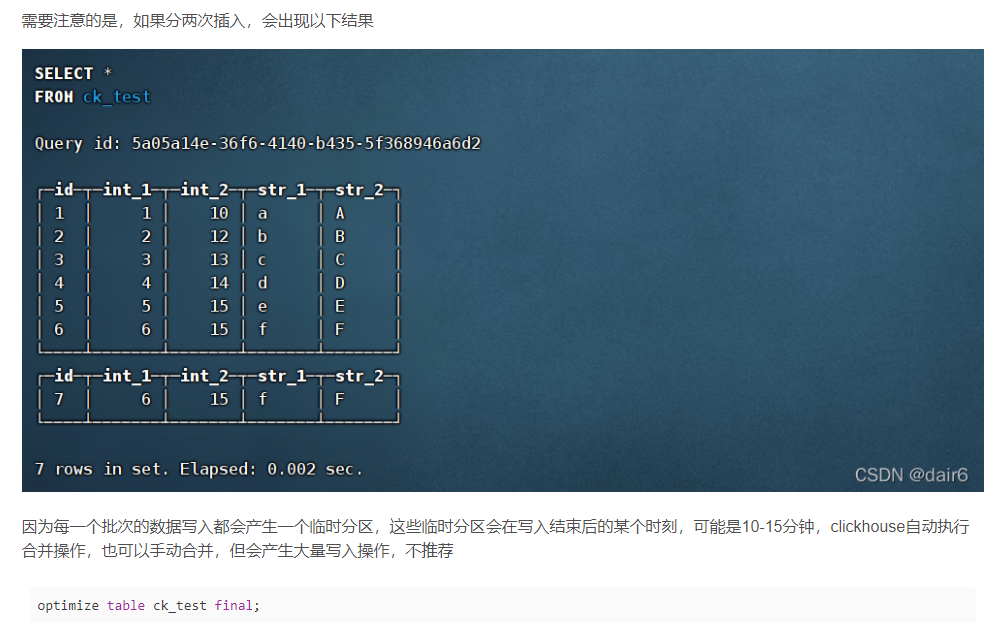
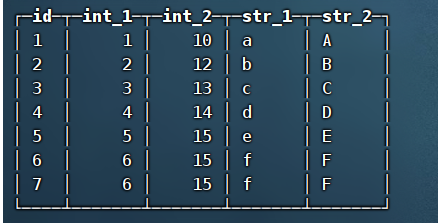
此外,如果出现了临时分区还没有合并的情况,any方法查询的结果,在合并前和合并后的结果是不一样的
函数
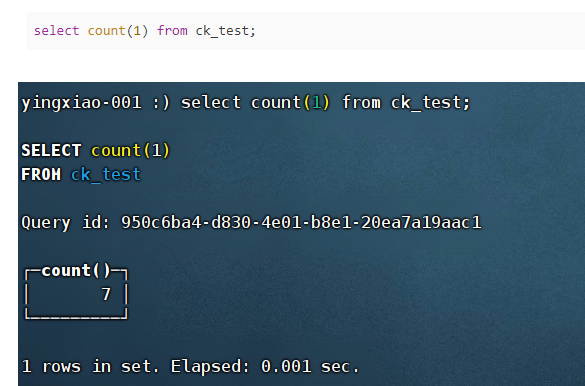
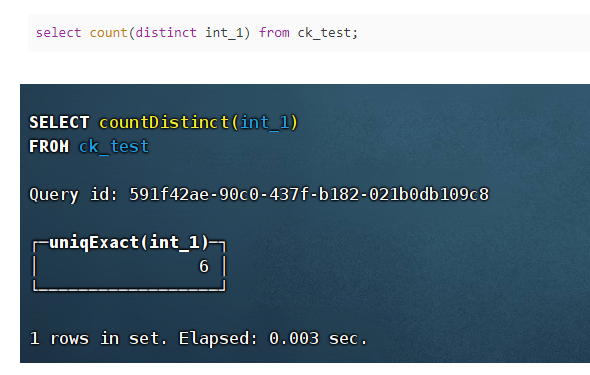
(1)count:计算行数
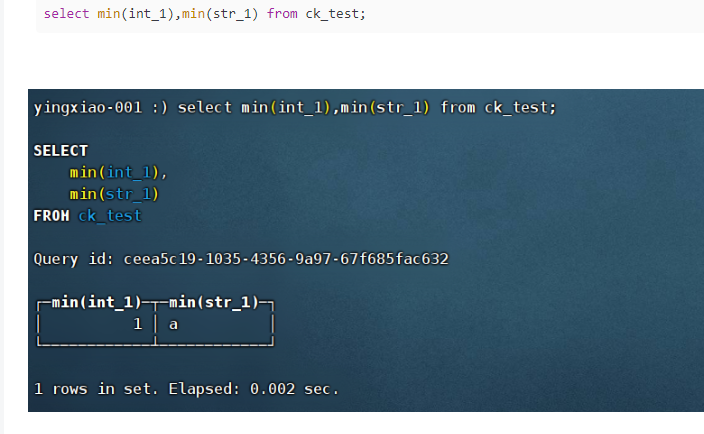
(2)min:计算最小值
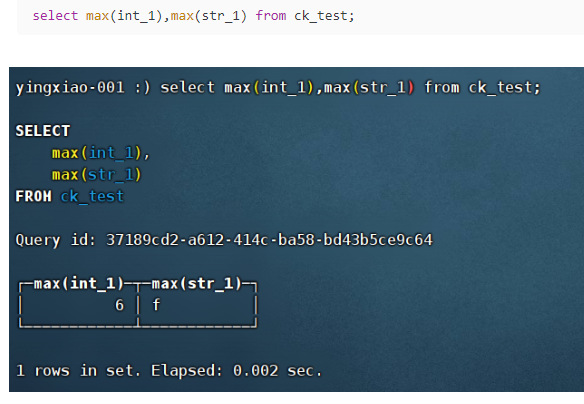
(3)max:计算最大值
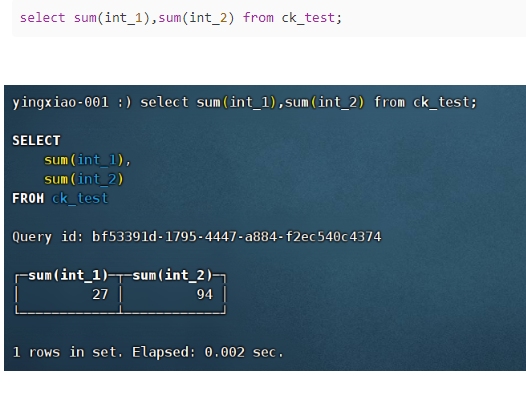
(4)sum:计算总和,只能计算数字之和
(5)avg:算数平均值,仅支持数字
select avg(int_1),avg(int_2) from ck_test;
- 1
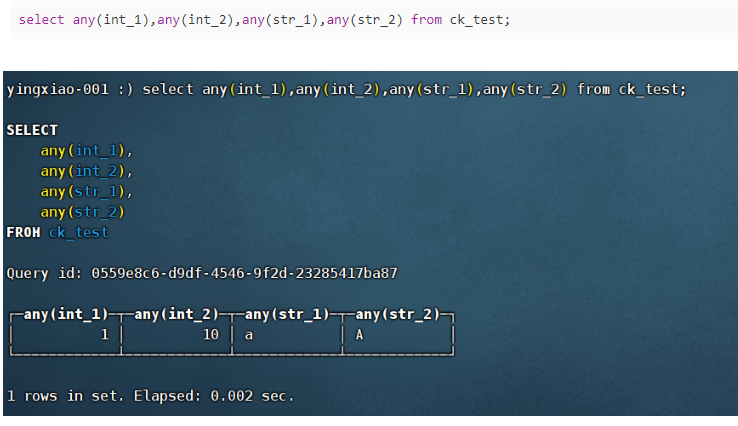
(6)any: 选择第一个遇到的值
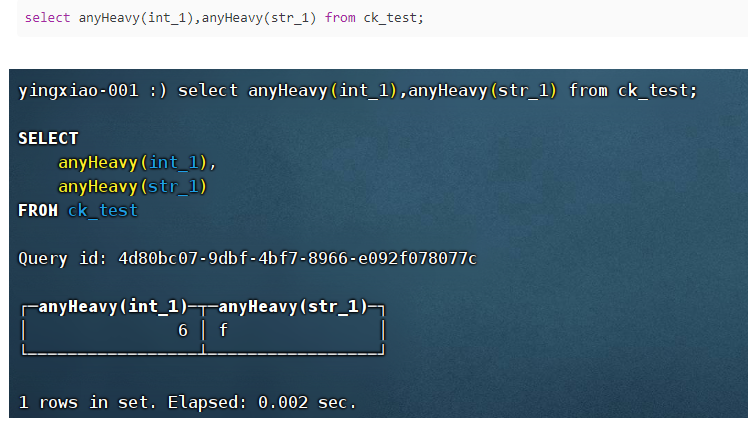
(7)anyHeavy:列出频繁出现的值,一般情况,结果是不确定的
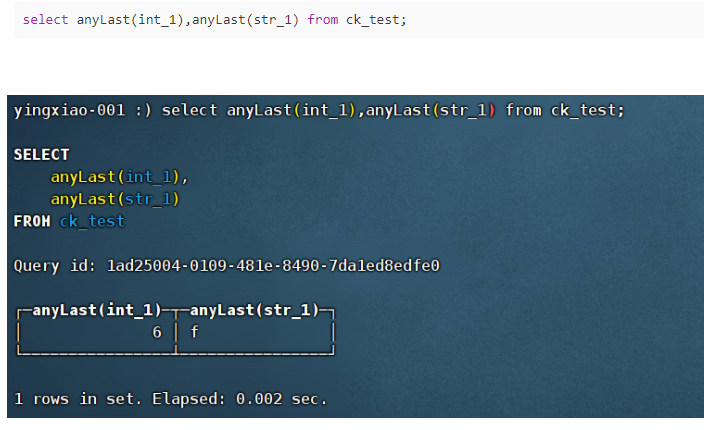
(8)anylast:选出最后一个出现的值
AggregateFunction(anyLast, String) 不支持分布式表
SimpleAggregateFunction(anyLast, String) 不支持分布式表
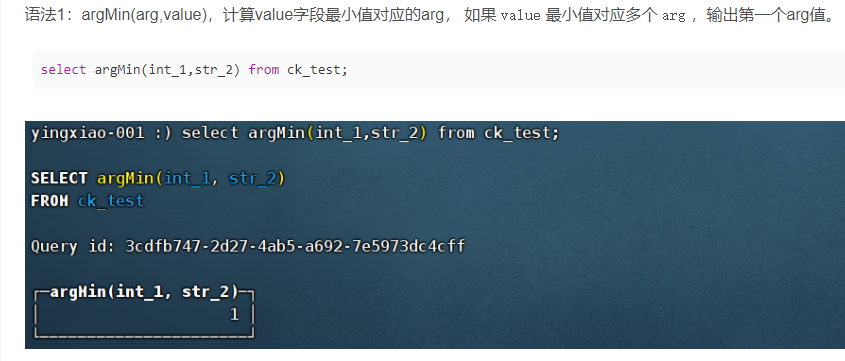
(9)argMin
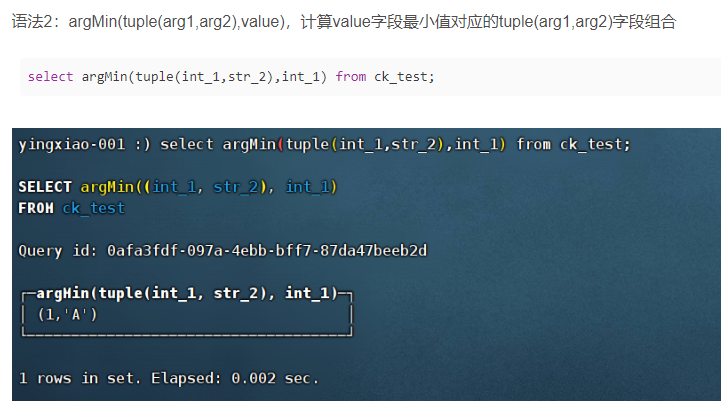
(10)argMax:类比argMin
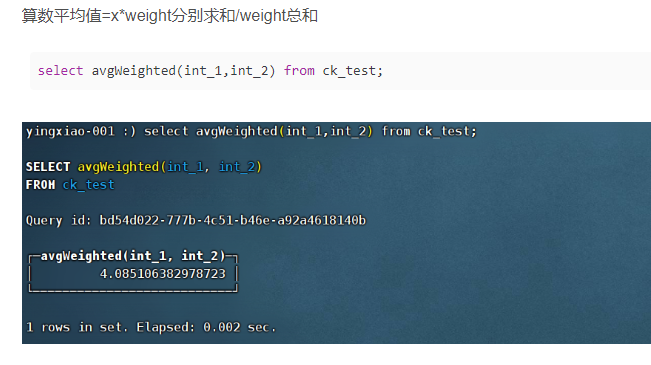
(11)avgWeighted(x, weight):加权算数平均值,x为值,weight为值的加权
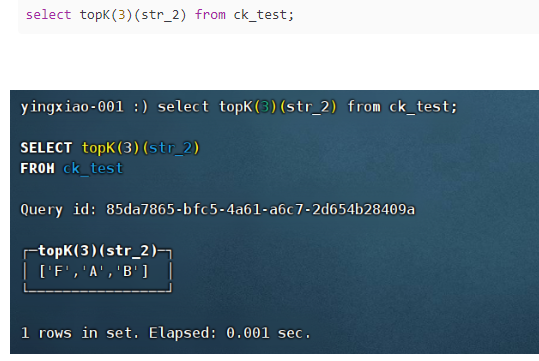
(12)topK(num)(col):
返回指定列中出现频率最多的值的数组,数组按照出现频率降序排序,num指定返回数组元素的个数,col为指定的字段
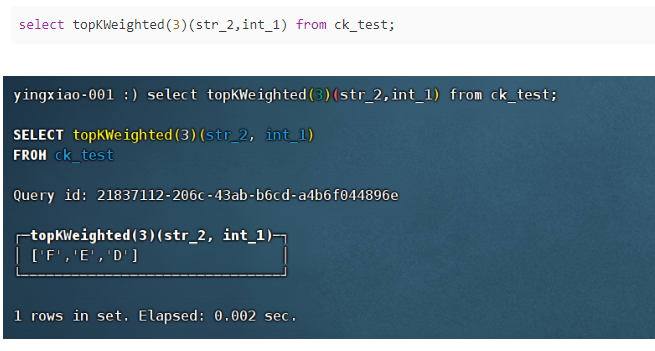
(13)topKWeighted(num)(col,weight):
类似于topK,col列每一个输入出现的次数,都会乘上weight权重,这个weight可以是类似于col的一个字段
(14)groupArray:生成数组
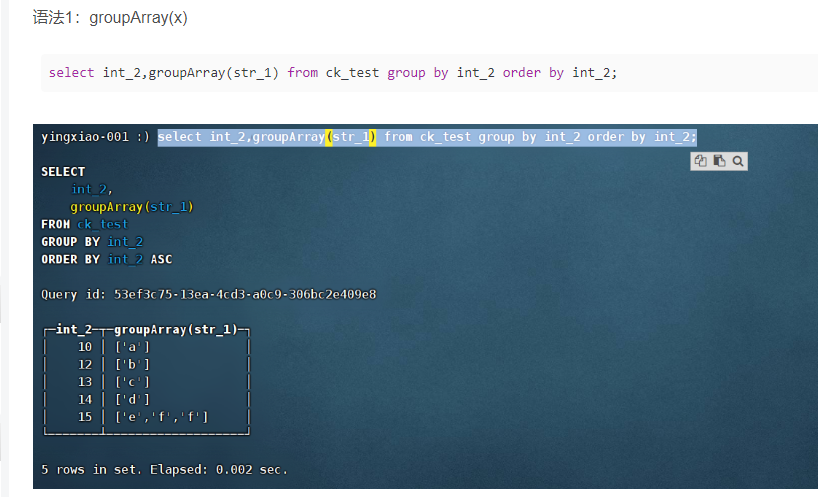
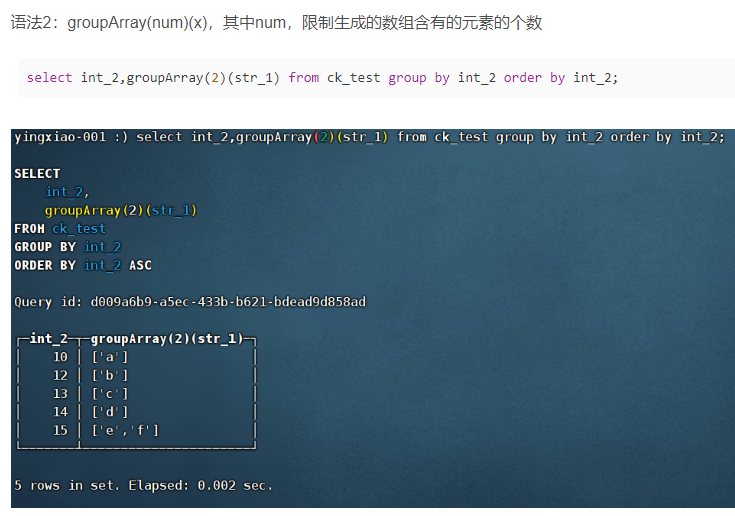
(15)groupUniqArray:类似于groupArray,不过会将生成的数组去重
(16)groupArrayInsertAt:参数指定位置插入数组
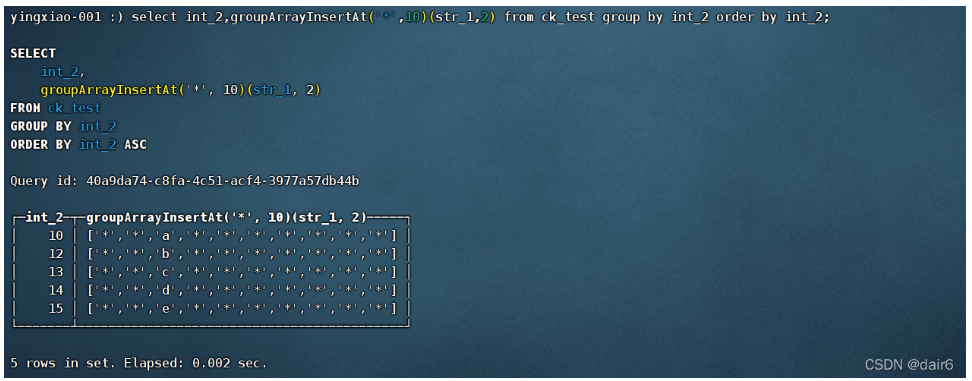
语法:groupArrayInsertAt(default_x, size)(x, pos)
其中,default_x为默认的在空位上替换的值,size为最终的数组长度,因为数组可能很长,会有空位,所以要用default_x填充
x为要被插入的值组成的数组,从0到pos这个位置都用default_x填充
按我的理解,int_2为15的那一行,应该有e,f,f三个值,不知道为啥只出现了e
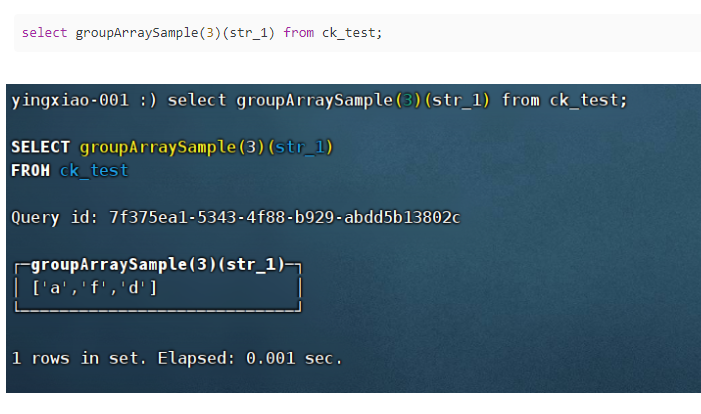
(17)groupArraySample(max_size)(arg)
生成采样数组,max_size为数组最大长度,arg可以是字段,也可以是字段拼接的表达式,如concat(‘字符:’,arg1)
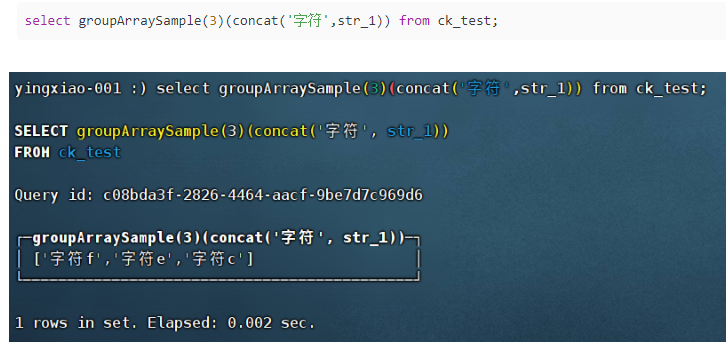
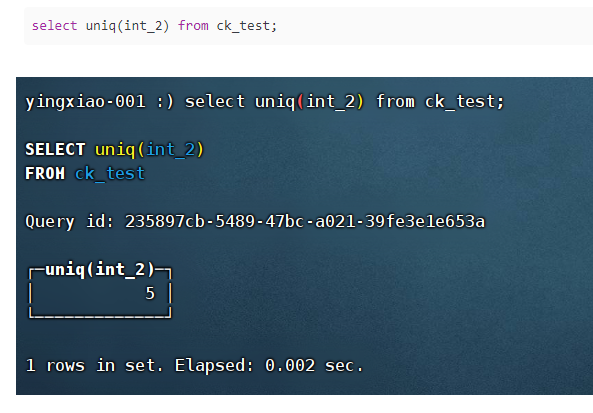
(18)uniq:计算字段去重后的近似数量
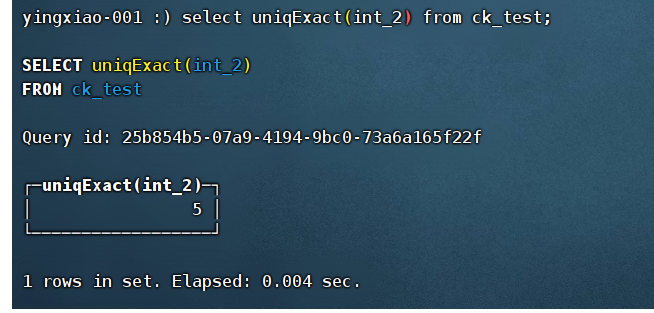
(19)uniqExact:计算不同参数值的准确数量
(20)uniqCombined:
计算不同参数值的近似数量,uniq虽然也是近似数量,但uniqCombined消耗内存多,精度也比uniq高
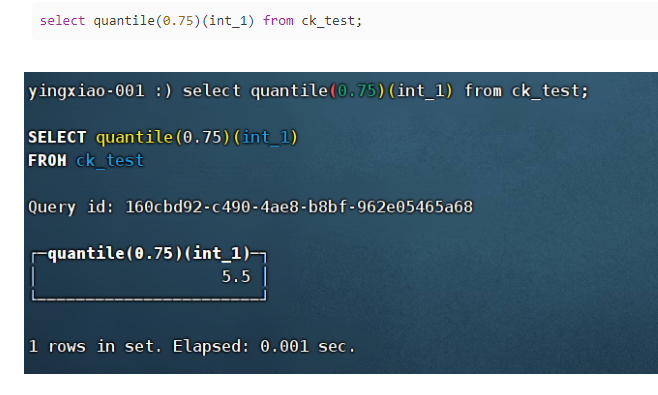
(21)quantile(level)(arg):
计算近似分位数,level是分位数常量,取值范围0-1,arg可以是数字类型,也可以是date,datetime类型
(22)quantiles(level1,level2…)(arg):可以同时计算多个分位数,返回结果为数组

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/445385
推荐阅读
相关标签

