
- 1技术资源:国内知名技术网站网址_农夫一夜十次
- 2spring框架概述 与 入门案例:IoC/DI_commons-loggins…jar
- 3华为od与中软外包哪个更好_华为员工感慨:天天捞人推OD,用话术忽悠,感觉良心上过不去了...
- 4基于afx透明视频的视觉增强前端方案
- 5阿里云Nodejs SDK——子设备接入物联网平台_const iot = require('./utils/aliyun-iot-sdk.js');
- 6mysql从已有表创建新表_参考原表创建一个新得表结构
- 7Python入门:三种模块实现数据写入 Excel表格_python写入excel单元格
- 8【C语言】将一个正整数分解质因数
- 9蓝桥杯青少年创意编程python初级考察内容_第十一届蓝桥杯青少年创意编程scratch初级组编程题详解...
- 10分布式搜索分析引擎ES_es分布式搜索引擎
kaldi语音识别实战网盘_第五届Kaldi技术交流会成功举办!
赞
踩

一年一度的语音技术交流盛宴——第五届Kaldi技术交流会在北京成功举办。

于北京时间2020年11月15日,北京希尔贝壳科技有限公司联合中国计算机学会语音对话与听觉专业组、AISHELL基金会、小米科技、昆山杜克大学、西北工业大学音频语音与语言处理研究组、中国科学技术大学共同举办了“第五届Kaldi技术交流会”。会议邀请了在当下学术界的精英以及小米集团副总裁崔宝秋博士、Kaldi之父Daniel Povey,齐聚一堂共享技术,探讨学术!

为了能够让更多的人参与进来,本次会议全程选择了线上直播的方式进行,让大家足不出户就可以收获满满。会议上午通过线上的形式展开,会议开场由AISHELL CEO卜辉对整场会议进行了说明。

The NPU DCCRN Speech Enhancement System and Brief Summary on Interspeech2020 DNS Challenge
胡炎鑫

西北工业大学音频语音与语言处理研究组的胡炎鑫,分享了在微软组织的Interspeech2020 Deep Noise Suppression Challenge(深度噪声抑制挑战赛,简称DNS)上获奖的作品,分别是The NPU DCCRN Speech Enhancement System和Brief Summary on Interspeech2020 DNS Challenge。
在日常生活中所用到的蓝牙耳机或者手机助理总会遇到周围环境噪声的干扰,而且根据环境构造的不同,还会造成音量衰减及混响等问题,由此在技术上产生出了帮助用户实现语音增强的需求。在微软组织的DNS上提出的Deep Complex Convolution Recurrent Network (DCCRN),在网络结构上既满足了轻量化的需求也达到了试验的目标。
最后胡炎鑫提出:如何使得降噪模式更小、更快、更好一直是语音相关从业者追求的目标。
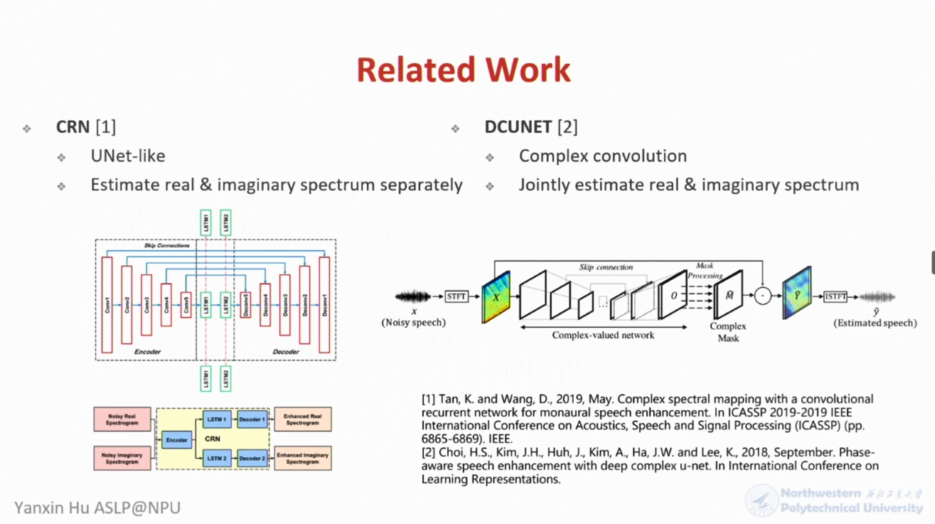

基于两阶段注意力机制和卷积神经网络的声学场景分类
王雅健

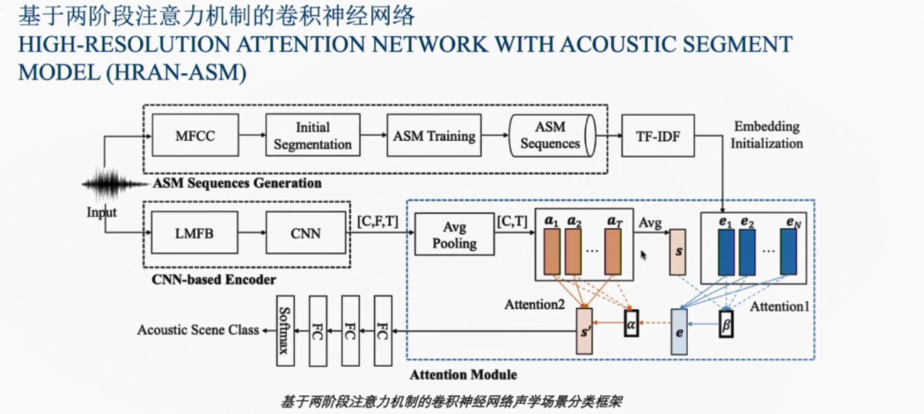
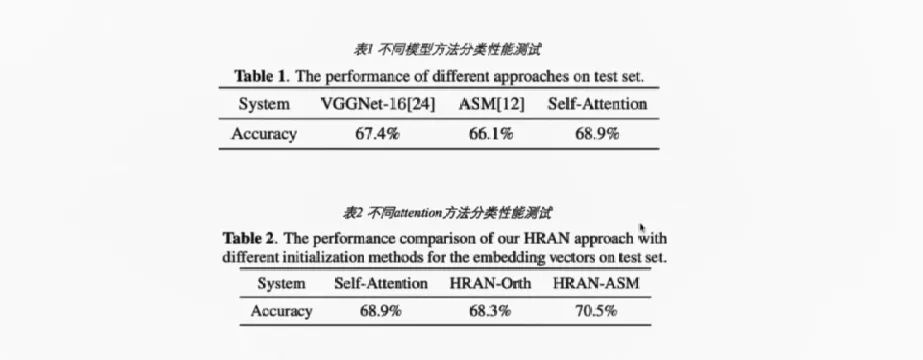
来自中国科学技术大学语音及语言信息处理国家工程实验室的王雅健,在报告中介绍到:声学场景分类系统主要是通过智能系统和算法可以自动的判别出声音所处的环境,此项技术主要应用于智能语音交互的前端,典型的应用就是蓝牙耳机的ANC主动降噪技术。目前声学场景分类存在的困难有音频场景中存在沉余信息并且有效区分性信息较为稀疏、不同场景之间存在相似声学片段,干扰分类模型判断e.g.笑声,说话声、卷积神经网络忽略了时间顺序列上的重要信息。据此希望能够提出一种自适应的网络模型能够突出有效区分性信息,从而提高分类的准确率。
此次方案中所制作的模型框架是基于两阶段注意力机制和卷积神经网络HIGH-RESOLUTION ATTENTION NETWORK WITH ACOUSTIC SEGMENT MODEL(HRAN-ASM),主要由三个模块组成
CNN提取特征的编码模块、ASM序列生成模块、注意力机制模块。采用的数据集则是DCASE task1A,其中包含了8640个音频片段,时长共计24H。
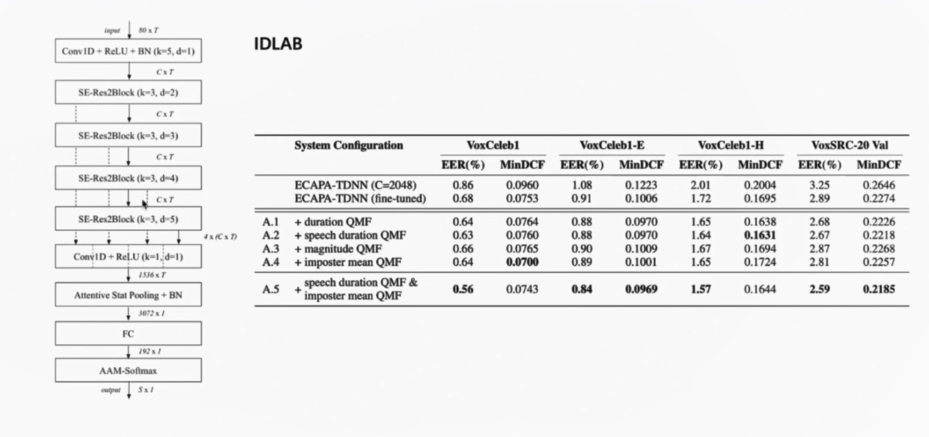
昆山杜克大学VoxSRC20 Track 1系统介绍
覃晓逸
来自昆山杜克大学大数据研究中心 SMIIP 实验室的覃晓逸为大家分享了在2020 VoxCeleb Speaker Recognition Challenge (VoxSRC)赛事上获奖 作品以及经验,报告中介绍了VoxSRC赛事的内容和4项任务。并从Data Augmentation → train Model → Fusion/Calibration详细的讲解 VoxSRC Task1。
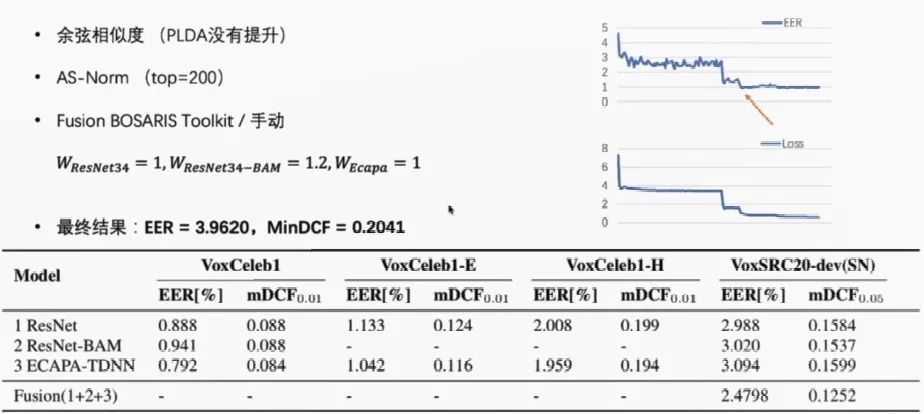
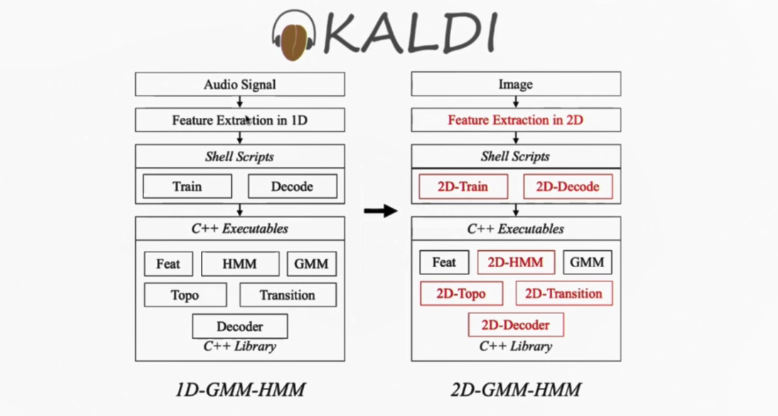
基于Kaldi工具库的二维隐马尔可夫模型实现
马洁锋

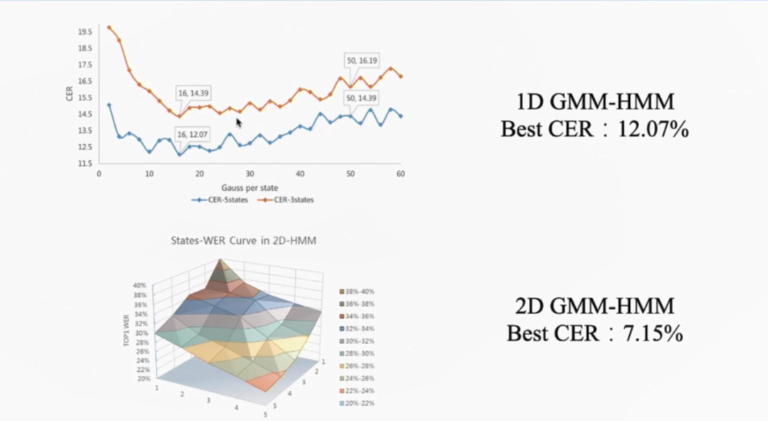
来自中国科学技术大学语音及语言信息处理国家工程实验室的马洁锋,分享了2020上半年完成的关于Kaldi工具库的二维隐马尔可夫模型实现。在报告中讲到:“试验过程中发现二维的隐马尔可夫模型相较于一维隐马尔可夫模型会有40%的性能提升,同时在部首的切分上面更加的精准。”马洁锋介绍了隐马尔可夫模型基于Kaldi工具库进行的改动,并在中科院自动化所对孤立字数据集进行了试验,同时也将试验结果分享了出来,他希望在未来将该工作扩展至连续文本行,加入对神经网络的支持,尝试实现2D DNN/DCNN-HMM。
IBG AI Speaker Recognition System for Far-Field Speaker Verification Challenge 2020
周飞飞

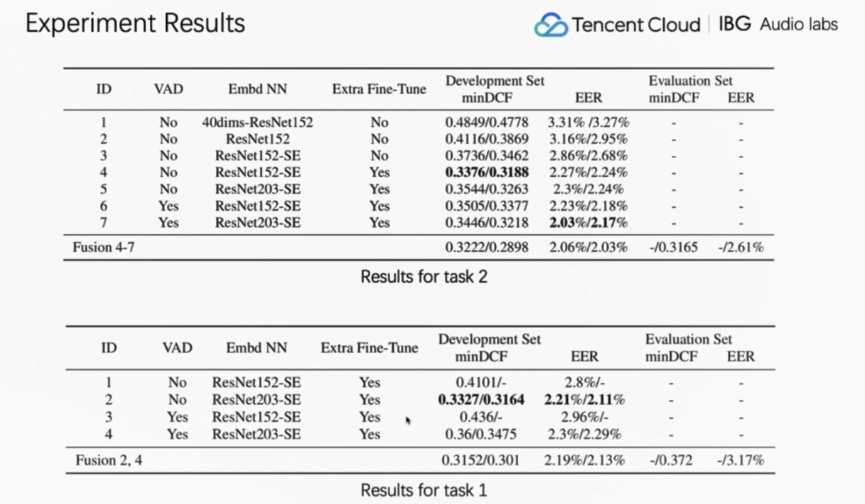
来自腾讯国际事业部的周飞飞向大家分享了IBG AI Speaker Recognition System for Far-Field Speaker Verification Challenge 2020(FFSVC2020)赛事的团队参赛作品。报告中对Training Data,Augmentations和Features and VAD两个数据集进行了简短的介绍,并分享了model structure—ResNet152,以及训练过程的细节,当然训练的步骤还是通过AAM loss进行的,但在此之上进行了一些细节的上的调整。会议上周飞飞为大家展示了试验模型的对比效果。并讲到:“通过比较发现,higher dimensional input features,90-dims > 40-dims,SE-BLOCKS & Extra Fine-tune对普通的说话人识别都是有效的,而Score normalization针对此场比赛更有效果”

CN-Celeb: multi-genre speaker recognition
李蓝天

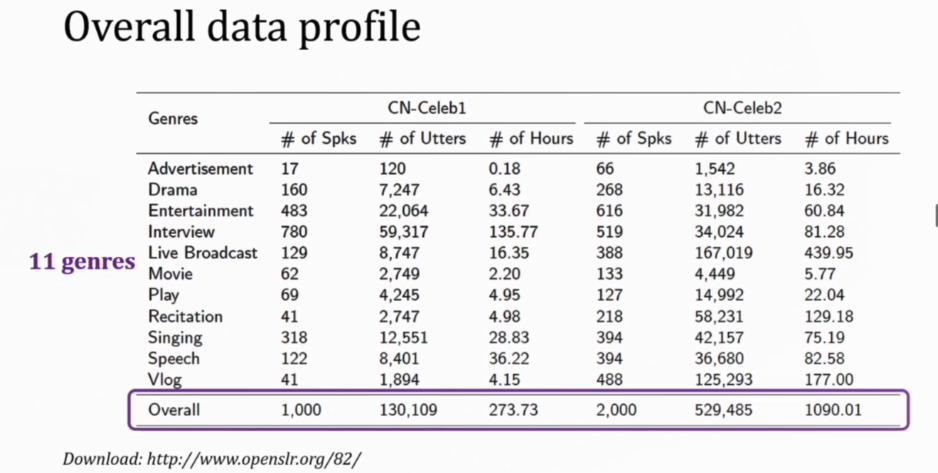
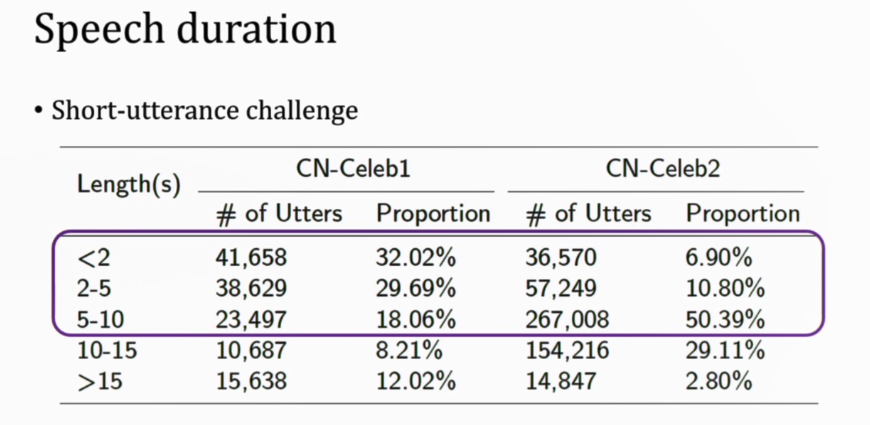
得意音通研究院执行副院长、清华信息国家研究中心助理研究员李蓝天,在报告中以从Collection pipeline、Data profile、Multi-genre challenge、Multi-genre training四个点介绍了《CN-Celeb: multi-genre speaker recognition》,并与大家探讨了不同阶段说话人识别的研究方向,分享了一些独到看法,以及解决的方案方法。
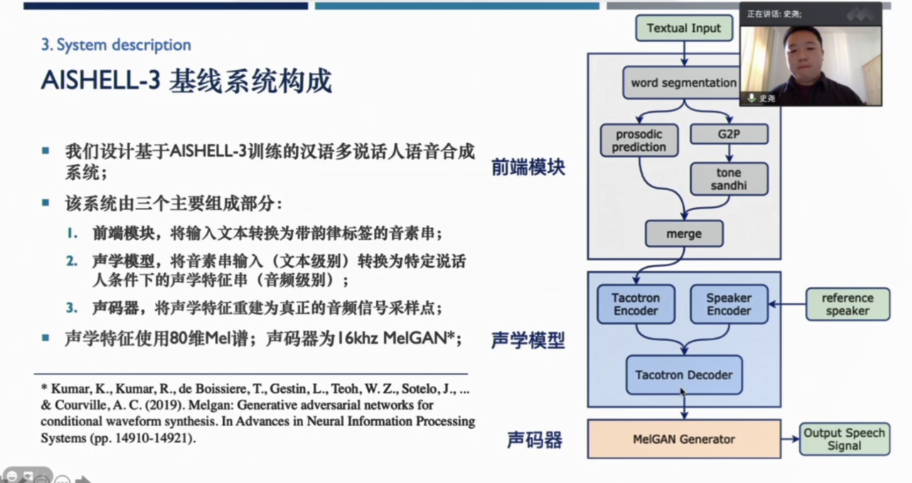
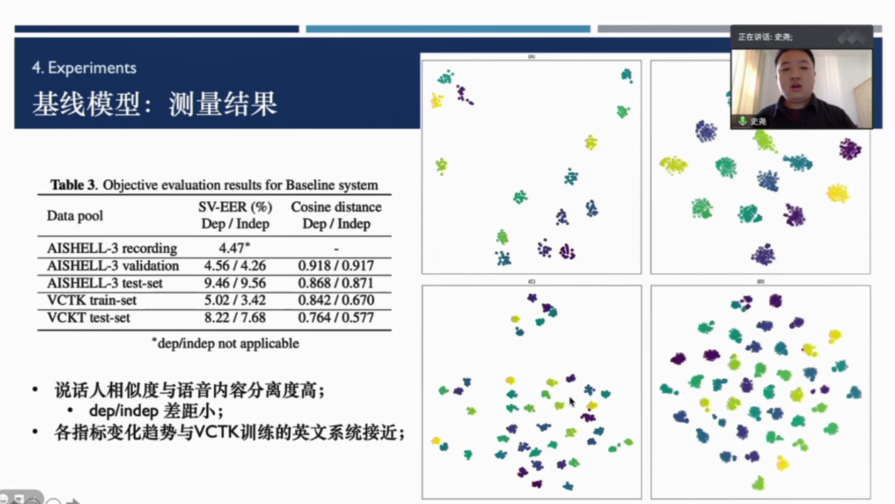
AISHELL-3多说话人语音合成数据集基线系统描述
史尧
来自武汉大学计算机学院的史尧分享的报告是《AISHELL-3多说话人语音合成数据集基线系统描述》,史尧介绍到:“语音合成(TTS)是文字信息到语音信息的转换,随着深度神经网络在该领域的应用,TTS系统实现了极高的音色自然度。AISHELL-3的语音时长为85小时88035句,可做为多说话人合成系统。录制过程在安静室内环境中, 使用高保真麦克风(44.1kHz,16bit)。由218名来自中国不同口音区域的发言人参与录制。数据库音字确率在98%以上。”而后根据AISHELL-3基线系统的构成,分别对前端模块、声学模式及声码器这三部分进行了详细的讲解。并分享了合成样本以及测量结果。
下午的线下交流会在北京小米科技园举行,有些铁杆粉丝为了不错过一分一毫,比原定签到时间还要提前半小时抵达了现场。
会议如期而至,首先由小米集团副总裁崔宝秋博士发表致辞。他讲到:拥抱开源是小米的工程文化和重要组成部分,不仅要站着巨人的肩膀上,更要为巨人指路,而kaldi正是这样的“巨人”,开源是当今时代人类进步的最佳平台与模式。同时他也希望kaldi技术交流会越做越大,希望中国能够在更多的领域崛起,成为人才向往的高地,让中国走在科技的前沿!

来自北京邮电大学的陈堃分享了在Detection and Classification of Acoustic Scenes and Events赛事上的方案《Audio Captioning based on Transformer and pre-trained CNN》,在报告中他讲解了自动音频描述(Automated audio captioning)的构成,以及使用Future works 后可以有效的提升音频特征的提取能力使其能够获得更全面的音频信息以及提升生成的多样性。

AISEHLL& AISHELLFoundation创始人卜辉,在AISHELL数据+技术的开源工作上做了报告,报告中讲到:“今年开源的AISHELL3与AISHELL1和AISHELL2不同的地方在于采用44.1KHz的采样率。在去年kaldi交流会发布的HI-MIA,,如今也已经开源到Openslr,没有开源的数据总时长为1561小时,虽然内容只有“你好,米雅”和“HI,MIA”,其关键在于尝试用阵列的方式在真实的室内收集大量的人声,并以此让开发者和研发人员能够实现解决远场声纹方案。”他表示“当下AISHELL所开源的项目里包含了ASR、VPR、TTS三种方案,在语音交互的三驾马车面前已经完成矩阵式的开源。至此,我们仍未结束开源之路,还在尝试更多的努力,做更多的开源项目。”

会议上Kaldi之父Daniel Povey首次亲临Kaldi技术交流会现场,与大家深入交流了下一代kaldi及K2的目前开发情况和未来的规划。



互动提问环节热火朝天
Daniel Povey倾囊相授,收获满满
由Daniel Povey开发和维护的Kaldi 集成了多种语音识别模型,包括隐马尔可夫和最新的深度学习神经网络,公认是业界语音识别框架的基石。在加入小米的一年里,Daniel Povey设计并开发出了新一代Kaldi。新一代Kaldi分成三个部分,包括核心算法部分,训练数据准备部分、示例脚本集合部分。
1)Lhotse
Lhotse(训练数据准备部分)将替代以前Kaldi中所有数据准备相关的工作,操作各种音频和文本的元数据。Lhotse除了Kaldi本身,也适用于其他应用。而且Lhotse纯Python代码,方便易用。

2)Icefall
Icefall(示例脚本集合部分)将代替Kaldi中的示例脚本集合,并独立成为一个单独的子项目。之所以要把示例脚本集合与核心算法分开,是考虑到示例脚本可能会非常庞大,且经常变动。

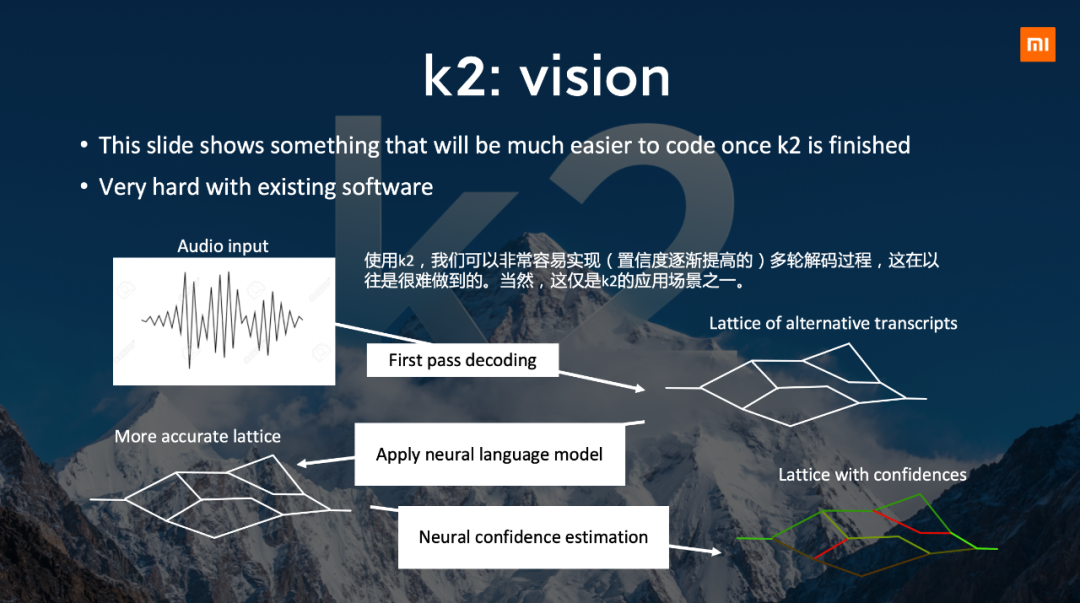
3)k2
新一代Kaldi的核心部分叫“k2”。k2可以让开发者很容易在PyTorch/TensorFlow中实现各种语音识别相关算法,比如CTC、LF—MMI、RNN—T、2nd—pass语言模型等,消除以往语音识别算法中训练跟解码不匹配的问题。

同时,通过k2可以非常容易实现(置信度逐渐提高的)多轮解码过程,这在以往是很难做到的。相较于其他一些语音识别库的优势,k2速度更快,通用性强(可以用来建模多种语音识别算法)。
大会最后,由AISHELL CEO 卜辉为Daniel Povey颁发了聘用证书,邀请Daniel Povey作为kaldi技术交流会荣誉顾问,同时也希望每一届,Daniel Povey都能够亲临kaldi技术交流会现场,在学术上与大家一起深入交流。

希望下一届kaldi交流会再会
最后干货分享给大家

- 本 期 留 言 -
“感谢分享”
即可获得本次kaldi交流会上
嘉宾演讲PPT的一手资料
- 直播回放地址 -
https://www.bilibili.com/video/BV1QD4y1Q7WF/

 扫码关注我们
扫码关注我们
了解更多语音识别
语音合成等相关领域的干货

