
- 1重启iis,提示帐户名与安全标示间无任何映射_iis 帐户名与安全标识间无任何映射完成
- 2hive中case when的两种使用方法_hive case when
- 3基础数据结构11:哈希_hash.h
- 4Mac OS X、Linux和Windows设备连接至SFTP服务器的方法
- 5毕业一年后,他转行软件测试成功拿到9.5K薪资,直言互联网行业真香_男程序员转行做测试怎么样?
- 6kafka3.X集群安装(不使用zookeeper)_高版本的kafka可以不使用zookeeper
- 7【数据结构】堆的创建_堆构建
- 8读书笔记:人性的弱点读后感
- 9Hadoop3.1.3 伪分布式安装_opt/module/hadoop-3.1.3/libexec/hadoop-functions.s
- 10算法设计与分析(第二版)上机实验题——C语言实现_算法设计 c语言 csdn
教你用python爬取『京东』商品数据,原来这么简单!_python爬取京东商品
赞
踩
1
前言
本文将从小白的角度入手,一步一步教大家如何爬取『京东API』商品数据,文中以【笔记本】电脑为例!
干货内容包括:
如何爬取商品信息?
如何爬取下一页?
如何将爬取出来的内容保存到excel?
2
分析网页结构
1.查看网页
在『京东商城』搜索框输入:笔记本
链接如下:
https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1在浏览器里面按F12,分析网页标签(这里我们需要爬取1.商品名称、2.商品价格、3.商品评论数)
2.分析网页标签
获取当前网页所有商品
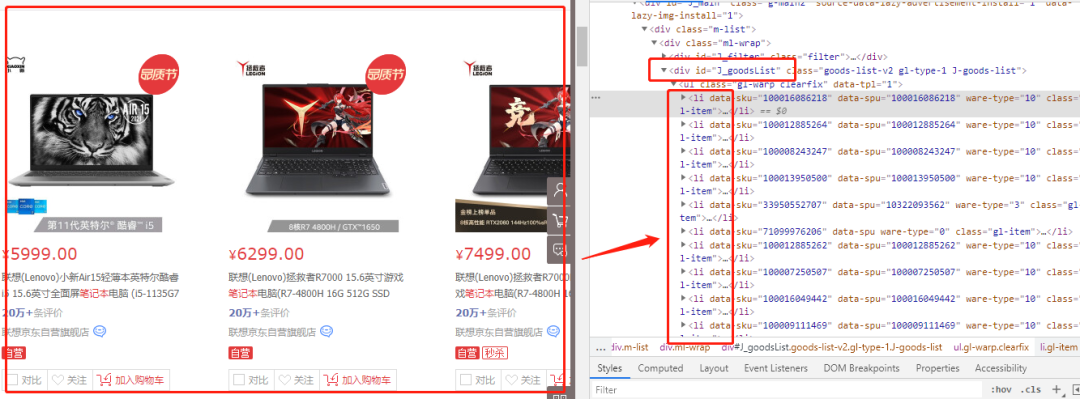
可以看到在class标签id=J_goodsList里ul->li,对应着所有商品列表
获取商品具体属性
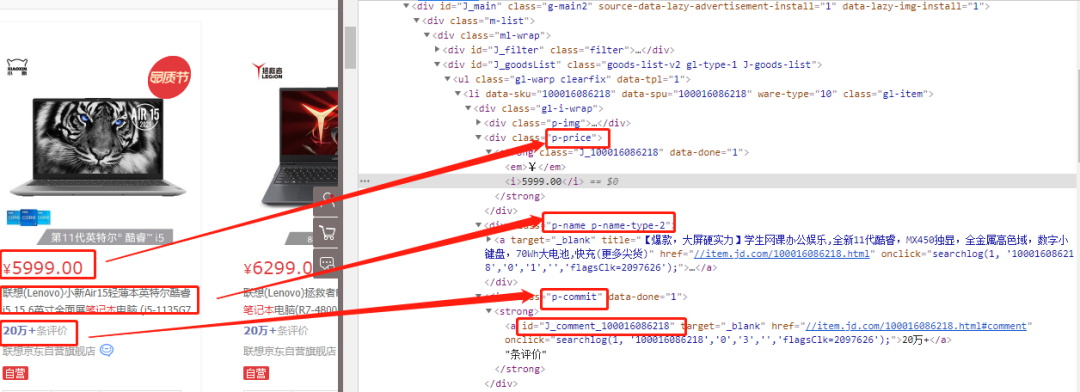
每一个li(商品)标签中,class=p-name p-name-type-2对应商品标题,class=p-price对应商品价格,class=p-commit对应商品ID(方便后面获取评论数)
避坑:
这里商品评论数不能直接在网页上获取!!!,需要根据商品ID去获取。
3
爬取数据
1.编程实现
url="https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1"res = requests.get(url,headers=headers)res.encoding = 'utf-8'text = res.text
selector = etree.HTML(text)list = selector.xpath('//*[@id="J_goodsList"]/ul/li')
for i in list: title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0] price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0] product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","") print("title"+str(title)) print("price="+str(price)) print("product_id="+str(product_id)) print("-----") 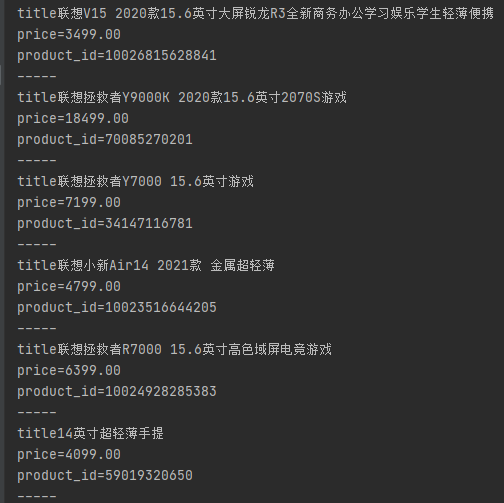
下面教大家如何获取商品评论数!
2.获取商品评论数
查看network,找到如下数据包
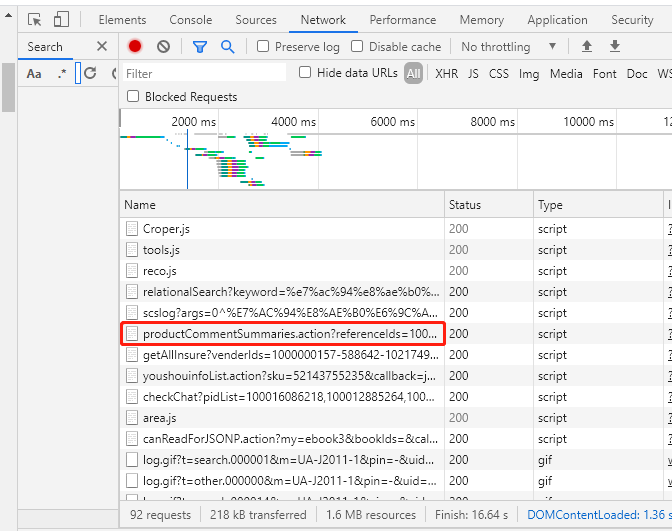

将该url链接放到浏览器里面可以获取到商品评论数

分析url

根据商品ID(可以同时多个ID一起获取)获取商品评论数

最后我们可以将获取商品评论数的方法封装成一个函数
###根据商品id获取评论数def commentcount(product_id): url = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds="+str(product_id)+"&callback=jQuery8827474&_=1615298058081" res = requests.get(url, headers=headers) res.encoding = 'gbk' text = (res.text).replace("jQuery8827474(","").replace(");","") text = json.loads(text) comment_count = text['CommentsCount'][0]['CommentCountStr']
comment_count = comment_count.replace("+", "") ###对“万”进行操作 if "万" in comment_count: comment_count = comment_count.replace("万","") comment_count = str(int(comment_count)*10000)
return comment_count此外,我们可以发现在获取到的评论数包含“万”“+”等符号,需要进行相应处理!
for i in list: title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0] price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0] product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","") ###获取商品评论数 comment_count = commentcount(product_id) print("title"+str(title)) print("price="+str(price)) print("product_id="+str(comment_count))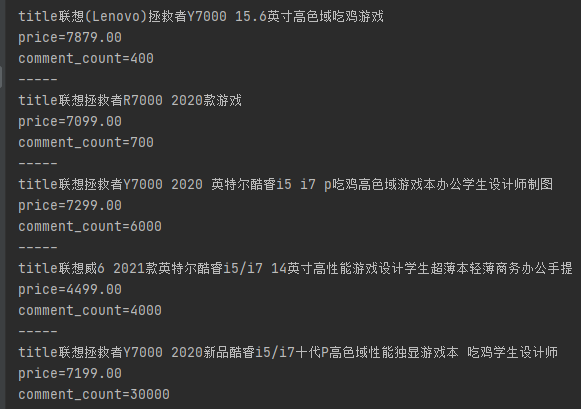
4
保存到excel
1.定义表头
import openpyxloutwb = openpyxl.Workbook()outws = outwb.create_sheet(index=0)
outws.cell(row=1,column=1,value="index")outws.cell(row=1,column=2,value="title")outws.cell(row=1,column=3,value="price")outws.cell(row=1,column=4,value="CommentCount")引入openpyxl库将数据保存到excel,表头内容包含(1.序号index、2.商品名称title、3.商品价格price、4.评论数CommentCount)
2.开始写入
for i in list: title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0] price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0] product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")
###获取商品评论数 comment_count = commentcount(product_id) print("title"+str(title)) print("price="+str(price)) print("comment_count="+str(comment_count))
outws.cell(row=count, column=1, value=str(count-1)) outws.cell(row=count, column=2, value=str(title)) outws.cell(row=count, column=3, value=str(price)) outws.cell(row=count, column=4, value=str(comment_count)) outwb.save("京东商品-李运辰.xls")#保存最后保存成京东商品-李运辰.xls

5
下一页分析
很重要!很重要!很重要!
1.分析下一页
这里的下一页与平常看到的不一样,有点特殊!



可以发现page和s有一下规律

page以2递增,s以60递增。
2.构造下一页链接
遍历每一页def getpage(): page=1 s = 1 for i in range(1,6): print("page="+str(page)+",s="+str(s)) url = "https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page="+str(page)+"&s="+str(s)+"&click=1" getlist(url) page = page+2 s = s+60这样就可以爬取下一页。
6
总结
1.入门爬虫(京东商品数据为例)。
2.如何获取网页标签。
3.获取『京东』商品评论数
4.如何通过python将数据保存到excel
5.分析构造『京东』商品网页下一页链接

