- 1一网统管/安防监控/视频综合管理EasyCVR视频汇聚平台解决方案
- 2按月统计数据——mysql实现_mysql按月统计
- 3axios的get请求和post请求的传参方式、拦截器_axios get
- 4C语言数据结构之链表详细解析_typedef struct lnode { elemtype data; struct lnode
- 5如何在 Ubuntu 14.04 上使用 Rsyslog、Logstash 和 Elasticsearch 实现日志集中管理
- 6python毕业设计 深度学习卫星遥感图像检测与识别 opencv 目标检测_opencv和深度学习结合做遥感影像目标识别
- 7【开源硬件篇】STM32F103C8T6主控板_stm32f103c8t6原理图
- 8存储器讲述工作原理及作用
- 9Mysql sql优化
- 10【数据结构与算法】深入浅出:单链表的实现和应用_单链表应用
Mysql字符集_mysql中my.cnf的中的编码字符集如何通过navicat命令来修改
赞
踩
1、修改MySQL5.7字符集
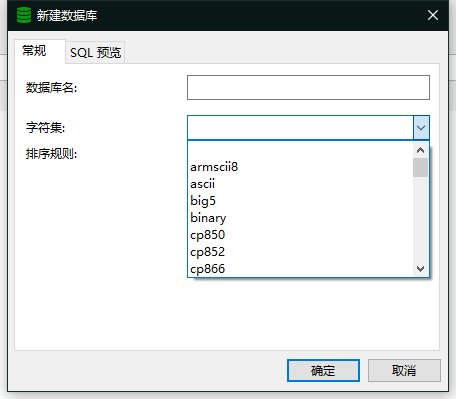
我们在新建数据库时(Navicat)界面时会遇到这两个选项,字符集和排序规则
在MySQL 8.0版本之前,MySQL 5.7 默认的客户端和服务器都用了 latin1 ,而latin1是不包含中文的,所以保存中文会报错 ,在数据库设计的时候往往会将编码修改为utf8字符集。如果遗忘修改默认的编码,就会出现乱码的问题。
从MySQL 8.0开始,数据库的默认编码将改为 utf8mb4 ,从而避免上述乱码的问题。 可以通过一下命令查看当前数据库字符集编码规则
show variables like 'character%'; # 或者 show variables like '%char%';
修改编码,在MySQL5.7或之前的版本中,/etc/my.cnf 在文件最后加上中文字符集配置
character_set_server=utf8 #再重启 systemctl restart mysqld
但是原库、原表的设定不会发生变化,参数修改只对新建的数据库生效
2、已有库&表字符集的变更
MySQL5.7版本中,以前创建的库,创建的表字符集还是latin1
修改已创建数据库的字符集 alter database dbtest1 character set 'utf8'; 修改已创建数据表的字符集 alter table t_emp convert to character set 'utf8';
注意:但是原有的数据如果是用非'utf8'编码的话,数据本身编码不会发生改变。已有数据需要导 出或删除,然后重新插入。
3、 各级别的字符集
mysql有4个级别的字符集和比较规则,分别是: 服务器级别 数据库级别 表级别 列级别
show variables like 'character%';

character_set_server:服务器级别的字符集
character_set_database:当前数据库的字符集
character_set_client:服务器解码请求时使用的字符集
character_set_connection:服务器处理请求时会把请求字符串从character_set_client转为 character_set_connection
character_set_results:服务器向客户端返回数据时使用的字符集
3.1、服务器级别的字符集
我们可以在启动服务器程序时通过启动选项或者在服务器程序运行过程中使用 SET 语句修改这两个变量 的值。比如我们可以在配置文件中这样写:
[server] character_set_server=gbk # 默认字符集 collation_server=gbk_chinese_ci #对应的默认的比较规则
当服务器启动的时候读取这个配置文件后这两个系统变量的值便修改了。
3.2、当前数据库的字符集
我们在创建和修改数据库的时候可以指定该数据库的字符集和比较规则,具体语法如下:
CREATE DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称]; ALTER DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称];
3.3、表级别字符集
我们也可以在创建和修改表的时候指定表的字符集和比较规则,语法如下:
CREATE TABLE 表名 (列的信息) [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称]] ALTER TABLE 表名 [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称]
如果创建和修改表的语句中没有指明字符集和比较规则,将使用该表所在数据库的字符集和比较规则作 为该表的字符集和比较规则。
3.4、列级别字符集
对于存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则。我们在创建和修改列 定义的时候可以指定该列的字符集和比较规则,语法如下:
CREATE TABLE 表名( 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称], 其他列... ); ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
对于某个列来说,如果在创建和修改的语句中没有指明字符集和比较规则,将使用该列所在表的字符集 和比较规则作为该列的字符集和比较规则
提示 在转换列的字符集时需要注意,如果转换前列中存储的数据不能用转换后的字符集进行表示会发生 错误。比方说原先列使用的字符集是utf8,列中存储了一些汉字,现在把列的字符集转换为ascii的 话就会出错,因为ascii字符集并不能表示汉字字符。
小结
介绍的这4个级别字符集和比较规则的联系如下
- 如果 创建或修改列 时没有显式的指定字符集和比较规则,则该列 默认用表的 字符集和比较规则
- 如果 创建表时 没有显式的指定字符集和比较规则,则该表 默认用数据库的 字符集和比较规则
- 如果 创建数据库时 没有显式的指定字符集和比较规则,则该数据库 默认用服务器的 字符集和比较规 则
知道了这些规则之后,对于给定的表,我们应该知道它的各个列的字符集和比较规则是什么,从而根据 这个列的类型来确定存储数据时每个列的实际数据占用的存储空间大小了。比方说我们向表 t 中插入一 条记录:
mysql> INSERT INTO t(col) VALUES('我们');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t;
+--------+
| s |
+--------+
| 我们 |
+--------+
1 row in set (0.00 sec)
首先列 col 使用的字符集是 gbk ,一个字符 '我' 在 gbk 中的编码为 0xCED2 ,占用两个字节,两个字 符的实际数据就占用4个字节。如果把该列的字符集修改为 utf8 的话,这两个字符就实际占用6个字节
4、 字符集与比较规则
查看所有字符集和比较规则(大小或者排序)

第一列是字符集 ,mysql一共支持41中字符集
第二列字符集描述
第三列是当前字符集默认的比较规则,
其中比较规则后缀表示该比较规则是否区分语言中的重音、大小写

第四列它代表该种字符集表示一个字符最多需要几个字节。
常见字符集和maxlen对应关系
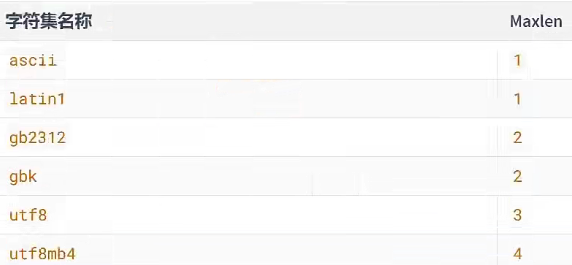
说明1、utf8 字符集,只使用1~3个字节表示字符。 utf8是utf8mb3别名, 正宗的 utf8 字符集就是 utf8mb4 ,使用1~4个字节表示字符 ,比如存储emjo表情就要用 utf8mb4
说明2、常用命令
#查看GBK字符集的比较规则 SHOW COLLATION LIKE 'gbk%'; #查看UTF-8字符集的比较规则 SHOW COLLATION LIKE 'utf8%'; #查看服务器的字符集和比较规则 SHOW VARIABLES LIKE '%_server'; #查看数据库的字符集和比较规则 SHOW VARIABLES LIKE '%_database'; #查看具体数据库的字符集 SHOW CREATE DATABASE dbtest1; #修改具体数据库的字符集 ALTER DATABASE dbtest1 DEFAULT CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; #查看表的字符集 show create table employees; #查看表的比较规则 show table status from atguigudb like 'employees'; #修改表的字符集和比较规则 ALTER TABLE emp1 DEFAULT CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
5、 请求到响应过程中字符集的变化
客户端发送一个请求,比如 SELECT * FROM t WHERE s = '我'; 在请求从发送到结果返回过程中字符集的变化
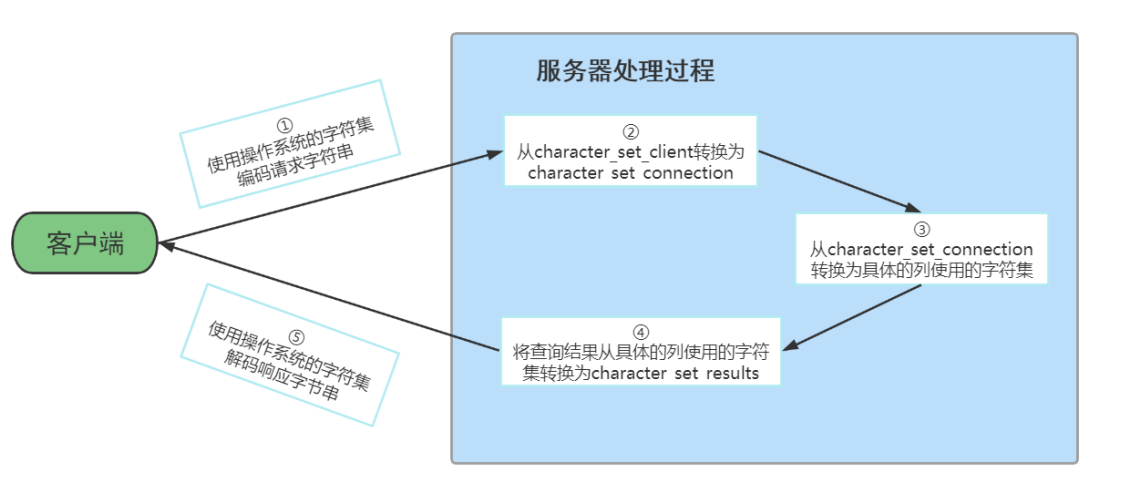
1、 客户端发送请求所使用的字符集
一般情况下客户端所使用的字符集和当前操作系统一致,不同操作系统使用的字符集可能不一 样,如下: 当客户端使用的是 utf8 字符集,字符 '我' 在发送给服务器的请求中的字节形式就是: 0xE68891 提示 如果你使用的是可视化工具,比如navicat之类的,这些工具可能会使用自定义的字符集来编 码发送到服务器的字符串,而不采用操作系统默认的字符集(所以在学习的时候还是尽量用 命令行窗口)。
2、 服务器接收到客户端发送来的请求其实是一串二进制的字节,它会认为这串字节采用的字符集是 character_set_client ,然后把这串字节转换为 character_set_connection 字符集编码的 字符。 由于我的计算机上 character_set_client 的值是 utf8 ,首先会按照 utf8 字符集对字节串 0xE68891 进行解码,得到的字符串就是 '我' ,然后按照 character_set_connection 代表的 字符集,也就是 gbk 进行编码,得到的结果就是字节串 0xCED2 。
3、 因为表 t 的列 col 采用的是 gbk 字符集,与 character_set_connection 一致,所以直接到列 中找字节值为 0xCED2 的记录,最后找到了一条记录 提示 如果某个列使用的字符集和character_set_connection代表的字符集不一致的话,还需要进行 一次字符集转换。
4. 上一步骤找到的记录中的 col 列其实是一个字节串 0xCED2 , col 列是采用 gbk 进行编码的,所 以首先会将这个字节串使用 gbk 进行解码,得到字符串 '我' ,然后再把这个字符串使用 character_set_results 代表的字符集,也就是 utf8 进行编码,得到了新的字节串: 0xE68891 ,然后发送给客户端。
5. 由于客户端是用的字符集是 utf8 ,所以可以顺利的将 0xE68891 解释成字符 我 ,从而显示到我 们的显示器上,所以我们人类也读懂了返回的结果。