
- 1windows安装cuda_cuda版本选择
- 2Hadoop的安装与伪分布式学习_安装与配置hadoop分布式环境。可以选择本机安装虚拟机,或者完成头歌在线实训
- 3iphone手机 ios系统 无法更新app 跳转到AppStore 显示 打开_苹果手机软件提示升级但点开是打开
- 4MSTP笔记_对于mstp设备来说,服务层路径是存在于网管侧的路径,而客户层路径是存在于网元侧的
- 5nvidia-smi 无进程占用GPU,但GPU显存却被占用_gpu用户只占用4g,但是nvidia-smi显示占用显存用了6g
- 6「雕爷学编程」Arduino动手做(32)——雨滴传感器模块_雨滴传感器代码
- 7Docker中安装Gitlab详细全教程_docker安装gitlab
- 8区块链安全初探(二):区块链的层次
- 9【LeetCode】单链表——刷题
- 102022年最新版Android安卓面试题+答案精选(每日20题,持续更新中)【三】_安卓数据库交互面试
GroupByKey和ReduceByKey对比_reducebykey和groupby的区别
赞
踩
GroupByKey和ReduceByKey两者都是spark中的Transformation算子,尽管二者通过操作可以实现相同的效果,但是二者有着很大的区别。
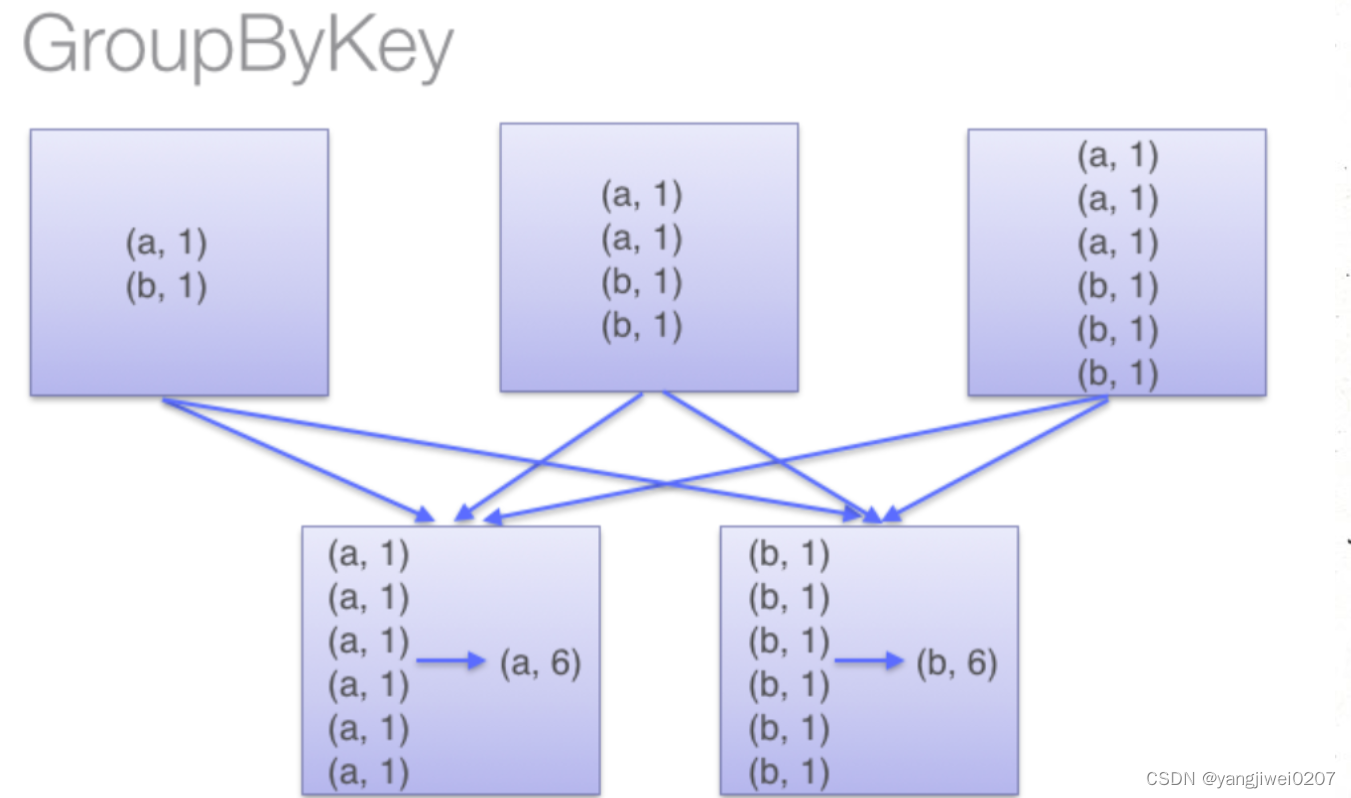
在shuffle操作上,ReduceByKey会在shuffle之前发生提前聚合,这样会大量的减少落盘的数据量,提高性能与效率,在开发中也是更偏向于使用ReduceByKey.然而GroupByKey不会在分区内提前聚合,只会在发生shuffle的时候进行分组聚合,并且还要搭配mapValues()使用,将需要的操作转到mapValues()里。
例:
Examples:使用reduceByKey统计数值
reduceByKey: 将数据按照value值累加(不是计数)
key2 = rdd3.reduceByKey(lambda x,y:x+y)
print(key2.collect())
[('b', 6), ('c', 3), ('a', 1)]
Examples:使用groupByKey+mapValues()统计词频个数
groupByKey: groupByKey搭配mapValues()使用:
>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
>>> sorted(rdd.groupByKey().mapValues(len).collect())
[('a', 2), ('b', 1)]
>>> sorted(rdd.groupByKey().mapValues(list).collect())
[('a', [1, 1]), ('b', [1])]
GroupBy:
ReduceBy:
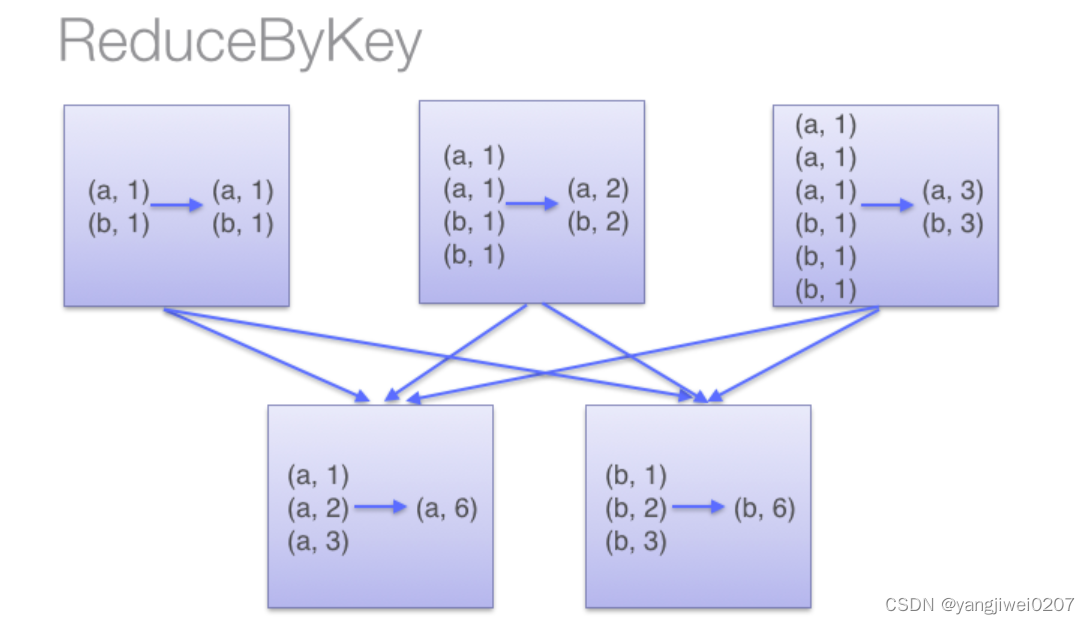
通过两张图片可知,两者的最主要的区别是否提前聚合,因为reduceByKey会提前聚合减少落盘的数据量,因此可以减少数据压力,可以使性能调优。

