
- 1php-svg-lib,SVG-edit是一个基于Web的快速,由JavaScript驱动的SVG绘图编辑器
- 2spacy包使用_spacy加载离线模型
- 3【FPGA & Verilog】手把手教你实现一个DDS信号发生器_dds的方波信号
- 4学习笔记-Frida综合案例
- 5uniapp 微信开发工具上访问正常,真机调试一直跨域报错
- 6Linux下软硬链接和动静态库制作详解
- 7磁盘调度算法剖析(FIFO、SSTF、SCAN、CSCAN、FSCAN)_scan算法会饥饿吗
- 8谷歌内核浏览器无法下载文件的解决方法_谷歌无法从网站上提取文件
- 9Stata导入数据,批量贴标签_stata excel 导入第二排标签
- 10[Django] 后台管理系统_django开发一个管理系统
应届生面试最爱问的几道java基础面试题_java面试题应届生
赞
踩
原文链接:应届生面试最爱问的几道java基础面试题
个人网站:生命不息 折腾不止
一 为什么 Java 中只有值传递?
首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。
Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
下面通过 3 个例子来给大家说明
example 1
public static void main(String[] args) { int num1 = 10; int num2 = 20; swap(num1, num2); System.out.println("num1 = " + num1); System.out.println("num2 = " + num2); } public static void swap(int a, int b) { int temp = a; a = b; b = temp; System.out.println("a = " + a); System.out.println("b = " + b); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果:
a = 20
b = 10
num1 = 10
num2 = 20
- 1
- 2
- 3
- 4
解析:
在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.
example 2
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
System.out.println(arr[0]);
change(arr);
System.out.println(arr[0]);
}
public static void change(int[] array) {
// 将数组的第一个元素变为0
array[0] = 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果:
1
0
- 1
- 2
解析:
array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。
很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。
example 3
public class Test { public static void main(String[] args) { // TODO Auto-generated method stub Student s1 = new Student("小张"); Student s2 = new Student("小李"); Test.swap(s1, s2); System.out.println("s1:" + s1.getName()); System.out.println("s2:" + s2.getName()); } public static void swap(Student x, Student y) { Student temp = x; x = y; y = temp; System.out.println("x:" + x.getName()); System.out.println("y:" + y.getName()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
结果:
x:小李
y:小张
s1:小张
s2:小李
- 1
- 2
- 3
- 4
解析:
交换之前:
交换之后:
通过上面两张图可以很清晰的看出: 方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝
总结
Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按
值传递的。
下面再总结一下 Java 中方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
- 一个方法可以改变一个对象参数的状态。
- 一个方法不能让对象参数引用一个新的对象。
参考:
《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节
二 ==与 equals(重要)
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型比较的是值,引用数据类型比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况 1:类没有覆盖 equals()方法。则通过 equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况 2:类覆盖了 equals()方法。一般,我们都覆盖 equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
举个例子:
public class test1 { public static void main(String[] args) { String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 if (aa == bb) // true System.out.println("aa==bb"); if (a == b) // false,非同一对象 System.out.println("a==b"); if (a.equals(b)) // true System.out.println("aEQb"); if (42 == 42.0) { // true System.out.println("true"); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
说明:
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
三 hashCode() 与 equals()(重要)
面试官可能会问你:“你重写过 hashcode 和 equals么,为什么重写 equals 时必须重写 hashCode 方法?”
3.1 hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
public native int hashCode();
- 1
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
3.2 为什么要有 hashCode?
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
3.3 为什么重写 equals 时必须重写 hashCode 方法?
如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
更多关于 hashcode() 和 equals() 的内容可以查看:Java hashCode() 和 equals()的若干问题解答
四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用 String
- 单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
- 多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
String 为什么是不可变的吗?
简单来说就是 String 类利用了 final 修饰的 char 类型数组存储字符,源码如下图所以:
/** The value is used for character storage. */
private final char value[];
- 1
- 2
String 真的是不可变的吗?
我觉得如果别人问这个问题的话,回答不可变就可以了。
下面只是给大家看两个有代表性的例子:
1) String 不可变但不代表引用不可以变
String str = "Hello";
str = str + " World";
System.out.println("str=" + str);
- 1
- 2
- 3
结果:
str=Hello World
- 1
解析:
实际上,原来 String 的内容是不变的,只是 str 由原来指向"Hello"的内存地址转为指向"Hello World"的内存地址而已,也就是说多开辟了一块内存区域给"Hello World"字符串。
2) 通过反射是可以修改所谓的“不可变”对象
// 创建字符串"Hello World", 并赋给引用s String s = "Hello World"; System.out.println("s = " + s); // Hello World // 获取String类中的value字段 Field valueFieldOfString = String.class.getDeclaredField("value"); // 改变value属性的访问权限 valueFieldOfString.setAccessible(true); // 获取s对象上的value属性的值 char[] value = (char[]) valueFieldOfString.get(s); // 改变value所引用的数组中的第5个字符 value[5] = '_'; System.out.println("s = " + s); // Hello_World
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果:
s = Hello World
s = Hello_World
- 1
- 2
解析:
用反射可以访问私有成员, 然后反射出 String 对象中的 value 属性, 进而改变通过获得的 value 引用改变数组的结构。但是一般我们不会这么做,这里只是简单提一下有这个东西。
五 什么是反射机制?反射机制的应用场景有哪些?
5.1 反射机制介绍
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
5.2 静态编译和动态编译
- **静态编译:**在编译时确定类型,绑定对象
- **动态编译:**运行时确定类型,绑定对象
5.3 反射机制优缺点
- 优点: 运行期类型的判断,动态加载类,提高代码灵活度。
- 缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。
5.4 反射的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:① 我们在使用 JDBC 连接数据库时使用 Class.forName()通过反射加载数据库的驱动程序;②Spring 框架也用到很多反射机制,最经典的就是 xml 的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中;
2)Java 类里面解析 xml 或 properties 里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的 Class 实例; 4)动态配置实例的属性
推荐阅读:
六 什么是 JDK?什么是 JRE?什么是 JVM?三者之间的联系与区别
6.1 JVM
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM 可以理解的代码就叫做
字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行一般有下面 3 步:
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
总结:
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
6.2 JDK 和 JRE
JDK 是 Java Development Kit,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
七 什么是字节码?采用字节码的最大好处是什么?
先看下 java 中的编译器和解释器:
Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。
Java 源代码---->编译器---->jvm 可执行的 Java 字节码(即虚拟指令)---->jvm---->jvm 中解释器----->机器可执行的二进制机器码---->程序运行。
采用字节码的好处:
Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同的计算机上运行。
八 接口和抽象类的区别是什么?
- 接口的方法默认是 public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法
- 接口中的实例变量默认是 final 类型的,而抽象类中则不一定
- 一个类可以实现多个接口,但最多只能实现一个抽象类
- 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
- 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
注意:Java8 后接口可以有默认实现( default )。
九 重载和重写的区别
重载
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
下面是《Java 核心技术》对重载这个概念的介绍:
重写
重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。也就是说方法提供的行为改变,而方法的外貌并没有改变。
十. Java 面向对象编程三大特性: 封装 继承 多态
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。(以后介绍)。
多态
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
在 Java 中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
十一. 什么是线程和进程?
11.1 何为进程?
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
11.2 何为线程?
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
// 遍历线程信息,仅打印线程 ID 和线程名称信息
for (ThreadInfo threadInfo : threadInfos) {
System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
[5] Attach Listener //添加事件
[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
[3] Finalizer //调用对象 finalize 方法的线程
[2] Reference Handler //清除 reference 线程
[1] main //main 线程,程序入口
- 1
- 2
- 3
- 4
- 5
从上面的输出内容可以看出:一个 Java 程序的运行是 main 线程和多个其他线程同时运行。
十二. 请简要描述线程与进程的关系,区别及优缺点?
从 JVM 角度说进程和线程之间的关系
12.1 图解进程和线程的关系
下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:《可能是把 Java 内存区域讲的最清楚的一篇文章》
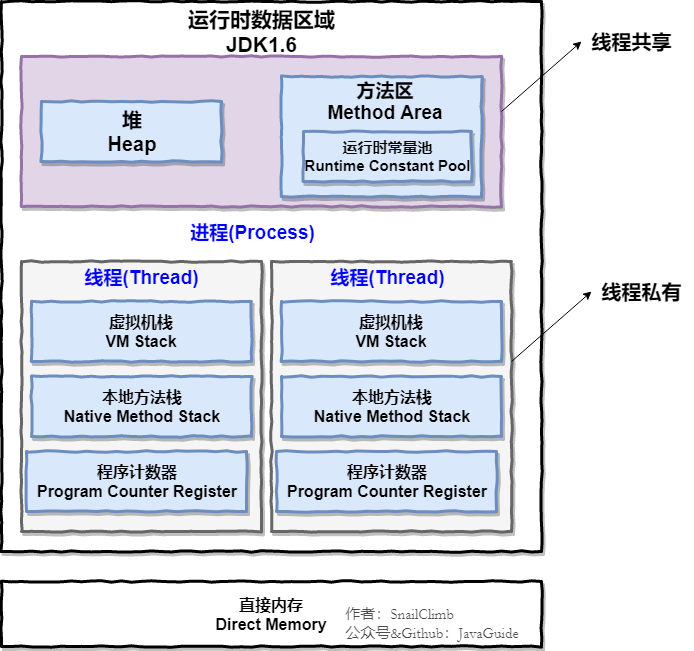
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
总结: 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
下面是该知识点的扩展内容!
下面来思考这样一个问题:为什么程序计数器、虚拟机栈和本地方法栈是线程私有的呢?为什么堆和方法区是线程共享的呢?
12.2 程序计数器为什么是私有的?
程序计数器主要有下面两个作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
所以,程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。
12.3 虚拟机栈和本地方法栈为什么是私有的?
- 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
- 本地方法栈: 和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
所以,为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
12.4 一句话简单了解堆和方法区
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
十三. 说说并发与并行的区别?
- 并发: 同一时间段,多个任务都在执行 (单位时间内不一定同时执行);
- 并行: 单位时间内,多个任务同时执行。
十四. 什么是上下文切换?
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
十五. 什么是线程死锁?如何避免死锁?
15.1. 认识线程死锁
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
public class DeadLockDemo { private static Object resource1 = new Object();//资源 1 private static Object resource2 = new Object();//资源 2 public static void main(String[] args) { new Thread(() -> { synchronized (resource1) { System.out.println(Thread.currentThread() + "get resource1"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resource2"); synchronized (resource2) { System.out.println(Thread.currentThread() + "get resource2"); } } }, "线程 1").start(); new Thread(() -> { synchronized (resource2) { System.out.println(Thread.currentThread() + "get resource2"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resource1"); synchronized (resource1) { System.out.println(Thread.currentThread() + "get resource1"); } } }, "线程 2").start(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Output
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
- 1
- 2
- 3
- 4
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
学过操作系统的朋友都知道产生死锁必须具备以下四个条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
15.2 如何避免线程死锁?
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
破坏互斥条件
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
破坏请求与保持条件
一次性申请所有的资源。
破坏不剥夺条件
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
破坏循环等待条件
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 2").start();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Output
Thread[线程 1,5,main]get resource1
Thread[线程 1,5,main]waiting get resource2
Thread[线程 1,5,main]get resource2
Thread[线程 2,5,main]get resource1
Thread[线程 2,5,main]waiting get resource2
Thread[线程 2,5,main]get resource2
Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们分析一下上面的代码为什么避免了死锁的发生?
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
十六. 说说 sleep() 方法和 wait() 方法区别和共同点?
- 两者最主要的区别在于:sleep 方法没有释放锁,而 wait 方法释放了锁 。
- 两者都可以暂停线程的执行。
- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
十七. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。

