
- 1【MATLAB第51期】基于MATLAB的WOA-ORELM-LSTM多输入单输出回归预测模型,鲸鱼算法WOA优化异常鲁棒极限学习机ORELM超参数,修正LSTM残差_建立多输入单输出的修正方程的步骤
- 2【随笔】Git 高级篇 -- 远程与本地不一致导致提交冲突 git push --rebase(三十一)_git push 如何避免没有同步远程最新文件
- 3brew mysql 失败_Mac 用 brew 安装 MySQL 总是出错, 求解
- 4从C语言到C++过渡篇(快速入门C++)
- 512个C语言必背实例_c语言案例
- 62023-02-23 leetcode-数据结构_匈 利算法bfs
- 7北大发现了一种特殊类型的注意力头!
- 8关于时间复杂度和空间复杂度_论文的复杂度
- 9最优二叉搜索树问题(Java)_最优二叉搜索树java
- 10人工智能畅想——《人工智能简史》读后感_人工智能简史读后感
大数据学习之分布式数据库HBase_2. 关系数据库可以存储和处理多种类型的结构化和非结构化数据。hbase只能存储
赞
踩
HBase简介
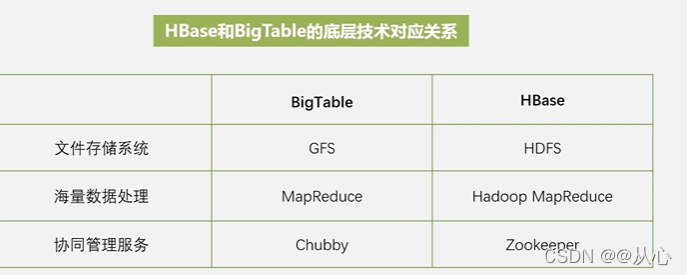
HBase就是BigTable的开源实现,是一个稀疏的多维度的排序的映射表,可以用来存储非结构化和半结构化的松散数据,通过水平扩展的方式,允许几千台服务器去存储海量文件
HBase的特点
- 高可靠
- 高性能
- 面向列
- 可伸缩
HBase与传统的关系型数据库的联系与区别
- 数据类型方面,传统的关系数据库用的是经典的关系数据模型,有非常多的数据类型和存储方式;而HBase的数据模型就很简单,把存储的数据存储为未经解释的字符串,靠开发人员读取数据来解释数据类型。
- 数据操作方面,在关系数据库当中定义了非常多的数据操作(增、删、改、查、连接);而HBase会将很多数据都完整的存储在一张表中,只有简单的插入、查询、删除、清空等,避免了复杂的表和表之间的关系。
- 存储模式方面,关系数据库是基于行模式存储;而HBase是基于列存储。
- 数据索引方面,关系数据库可以直接针对各个不同的列,构建复杂的索引,提高数据访问效率;而HBase只有一个索引—行
键,通过行键访问或扫描,从而使得整个系统不会慢下来 - 数据维护方面,在关系型数据库中做数据更新操作时,会覆盖掉旧的值;而HBase不会覆盖旧版本的数据,而是生成一个新版本的数据,旧版本仍然会保留,直到超过设置参数的期限之后,才会清理掉旧的版本。与HDFS只允许追加不允许修改的特性相关
- 可伸缩性方面,关系数据库很难实现水平扩展,最多可以实现纵向扩展(增加CPU、增加内存、增加磁盘);而HBase能
够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
HBase访问接口
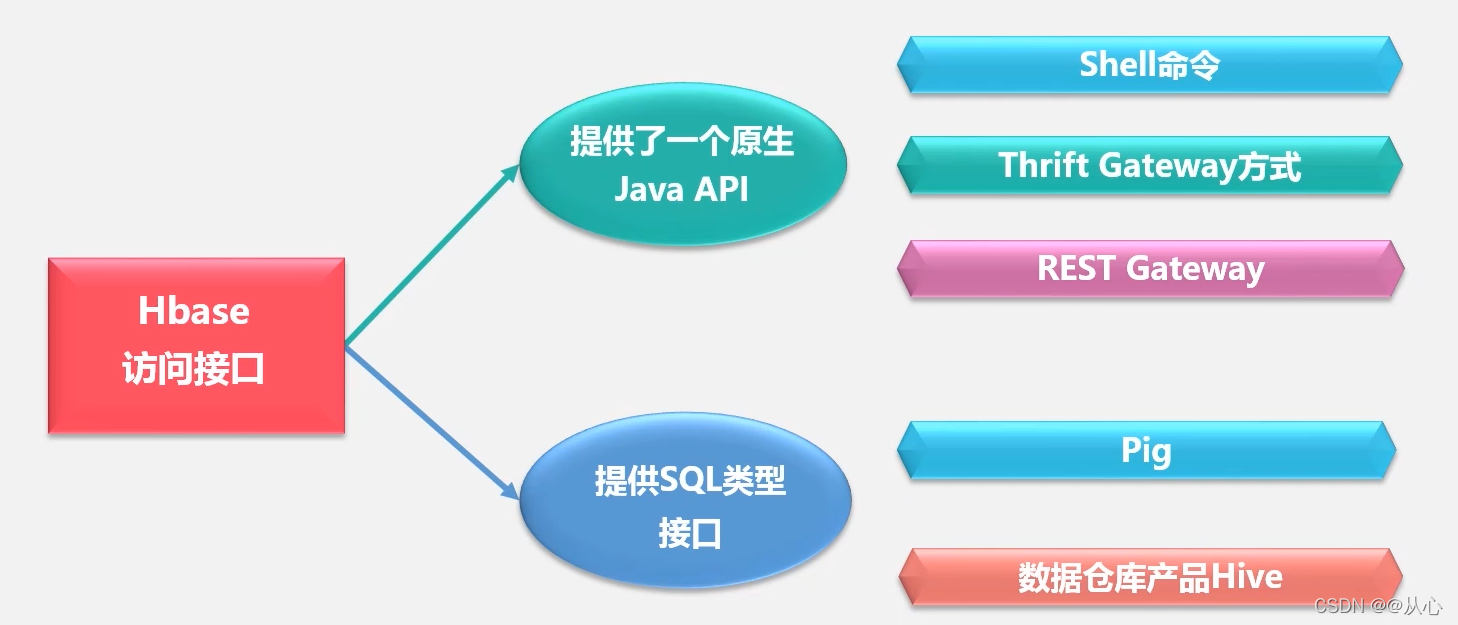
- Java API 最常规和高效的访问方式,适合Hadoop Map Reduce作业并行批处理HBase表数据
- Shell命令 Hbase的命令行工具,最简单的接口,适合HBase管理使用
- Thrift Gateway 利用Thrift序列化技术,支持C++、PHP、Python等多种语言,适合其他异构系统在线访问HBase表数据
- REST Gateway 解除语言限制,支持REST风格的Http API访问HBase
- Pig 使用Pig Latin流式编程语言来处理HBase中的数据,适合做数据统计
- 数据仓库有Hive 适合应用于需要以类似SQL语言方式来访问HBase的时候
Hbase数据模型
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。
每个值是一个未经解释的字符串,没有数据类型,也就是Bytes数组。
用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。
列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换
HBase对数据的定位
HBase通过四维坐标(行键、列族、列限定符、时间戳)来定位,类似键值数据库
Hbase的实现原理
HBase的功能组件
- 库函数 一般用于连接每个客户端
- 一个Master服务器 充当管家的作用,负责区分信息进行维护和管理、维护Region服务器列表、整个集群当中有哪些Region服务器在工作、负责对Region进行分配、负载均衡
- 若干个Region服务器 负责存储不同的Region,客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
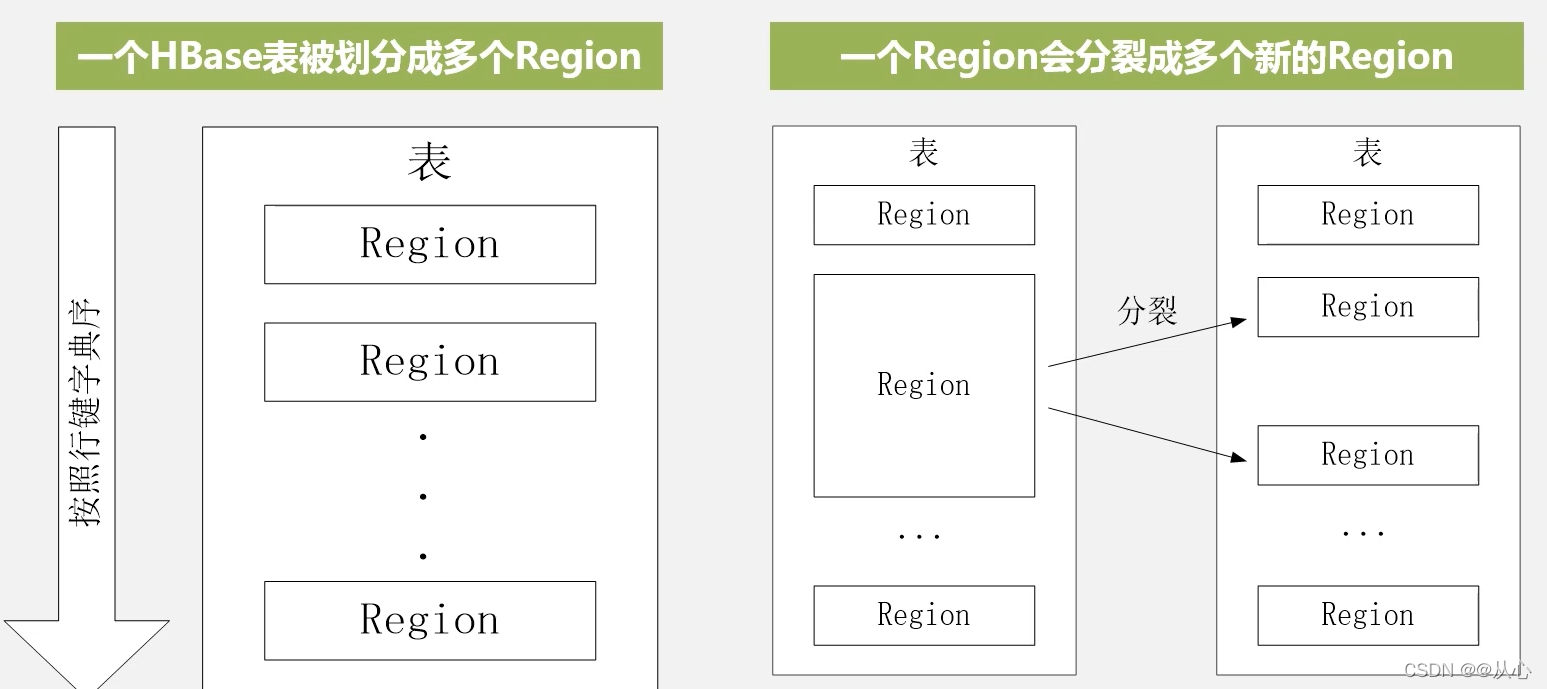
一个Region的大小最佳配置为1GB到2GB。Region的实际大小,取决于单台服务器的有效处理能力
对于同一个Region它是绝对不会被拆分到不同的Region服务器上的。每一个Region服务器,大概可以存储10到1000个Region
Region的定位
HBase设计了三层结构实现Region的寻址和定位
- 首先构建一个元数据表,假设这个元数据表中只有两列,第一列是Region的id,第二列是所在Region服务器的id。也就是HBase最开始构建的时候会有一个存储Region和Region服务器的关系映射表,即.META表
- 根数据表,-ROOT-表,记录所有元数据的具体位置。-ROOT-表只有唯一一个Region,名字是在程序中被写死的
- Zookeeper文件记录了-ROOT-表的位置


为了加快访问速度,.META.表的全部Region都会被保存在内存中
现假设.META.表的每行映射记录在内存中的大小大约为1KB,并且每个Region限制为128MB,那么,三层结构可以保存的用户数据表的Region数目的计算方法是:
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的Region可以寻址的用户数据表的Region个数)
而一个-ROOT-表最多只能有一个Region,也就是说最多只能有128MB,按照上述假设计算,128MB空间可以容纳128MB/1KB=217行,也就是说,一个-ROOT-表可以寻址217个.META.表的Region。同理,每个.META.表的Region可以寻址的用户数据表的Region个数是128MB/1KB=217,即每个.META表的Region可以定位217个用户表的Region。最终,三层结构可以保存的Region数目是(128MB/1KB)×(128MB/1KB)=234个Region
HBase的允许机制
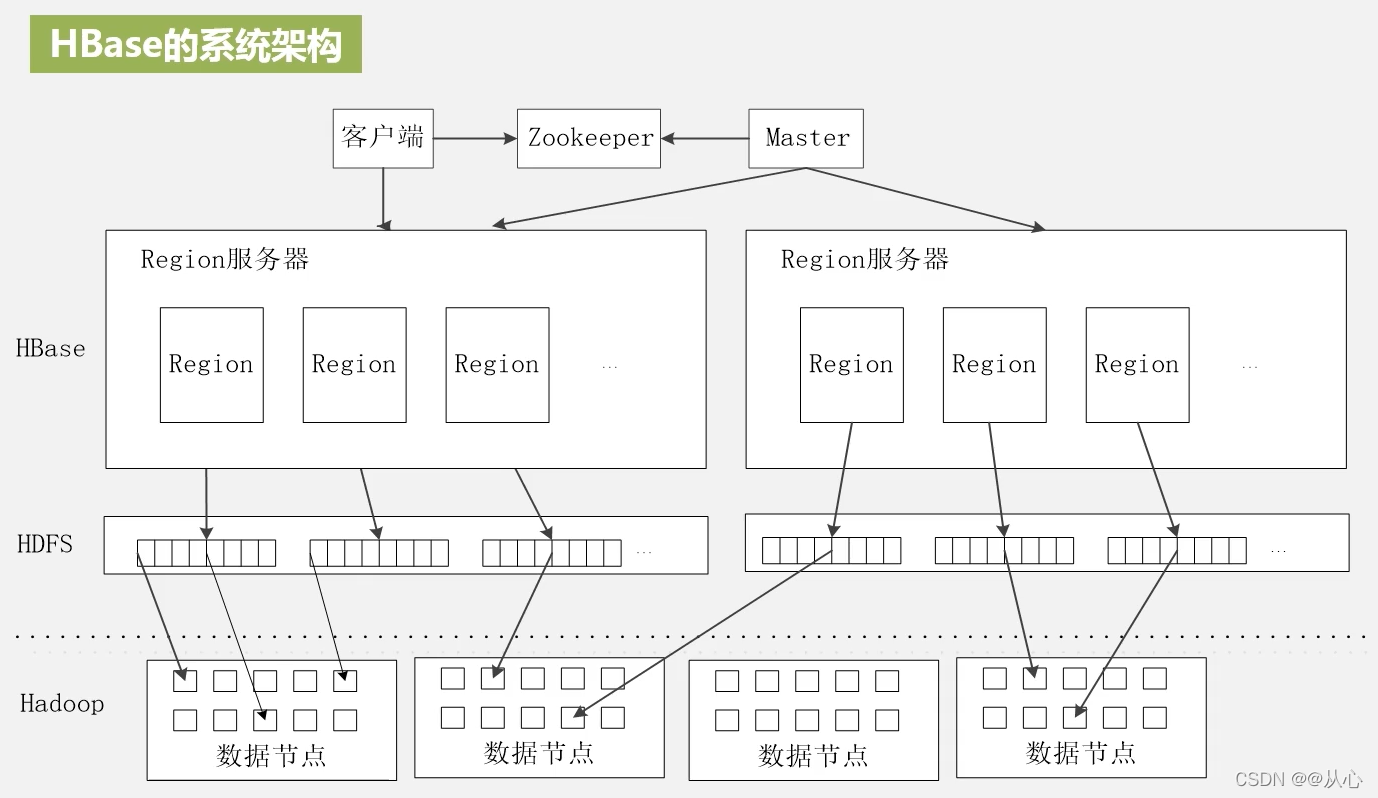
客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
Zookeeper
Zookeeper实现协同管理服务,可以帮助选举出一个Master作为集群的总管,维护和管理整个HBase集群,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题。Zookeeper是一个很好的集群管理工具,被大量用于分布式计算,提供配置维护、域名服务、分布式同步、组服务等。
主服务器Master
主要负责表和Region的管理工作:
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障或失效的Region服务器,进行Region的迁移
Region服务器
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,进行存储和管理,并响应用户的读写请求。
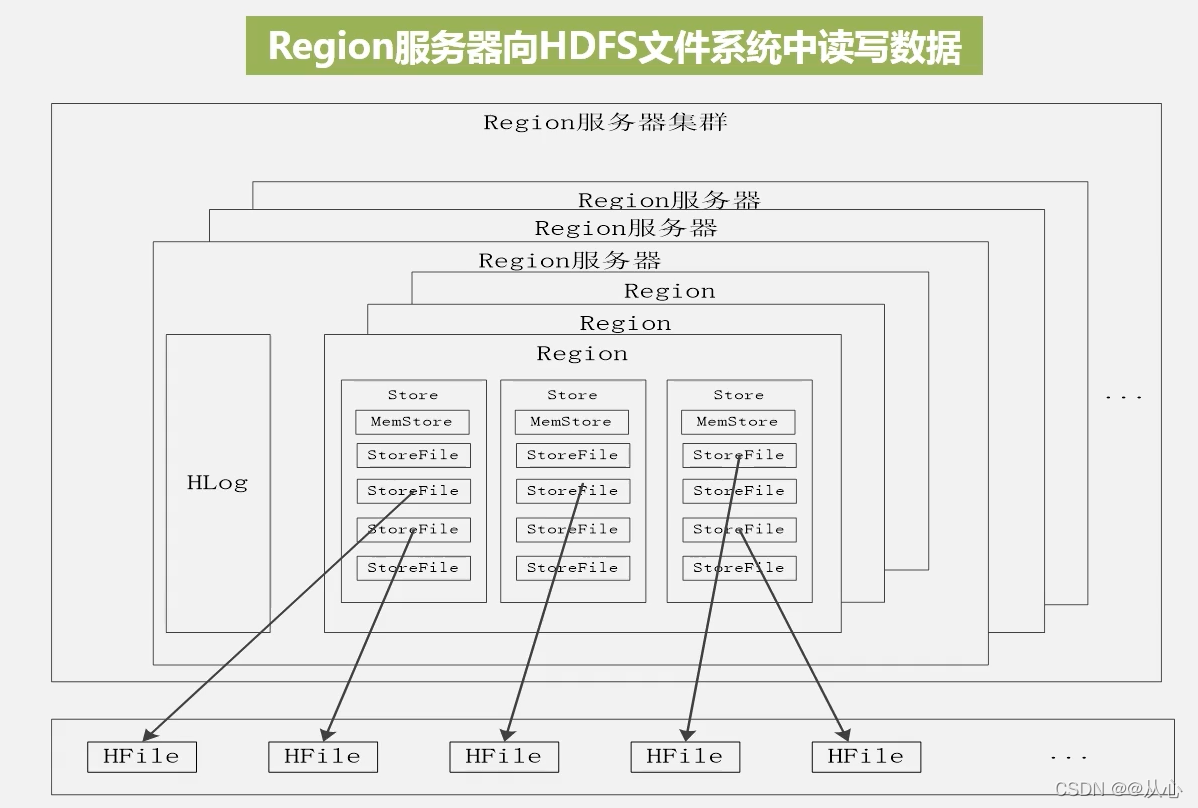
Region集群由若干Region服务器构成,每个Region服务器可以存储10到1000个Region,这些Region共用HLog日志文件,在写入数据时,每个Region会按照列切分,每个列族会构成一个Store,数据会先写入日志文件HLog,再到MemStore的缓存文件中,缓存满了之后,再刷新写入到StoreFile的磁盘文件中,StoreFile的底层是借助HDFS进行存储的,所以每一个StoreFile都是通过HFile进行存储。
用户读写数据过程
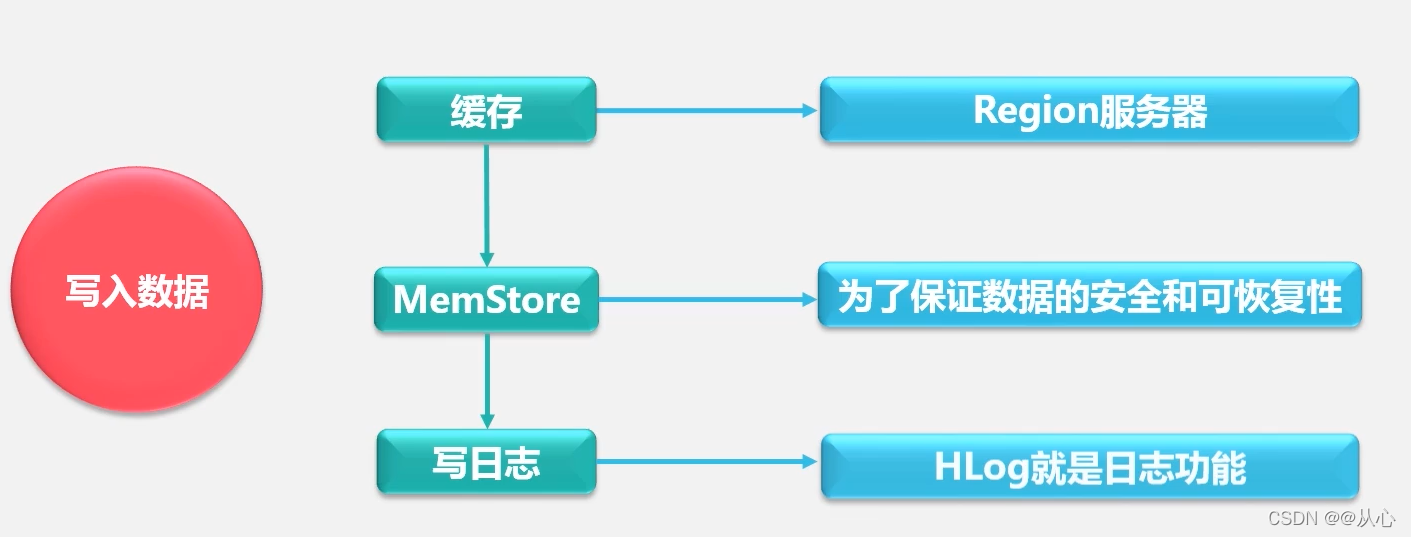
用户写入数据时,被分配到相应Region服务器去执行。用户数据首先被写入到MemStore和Hlog中。只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
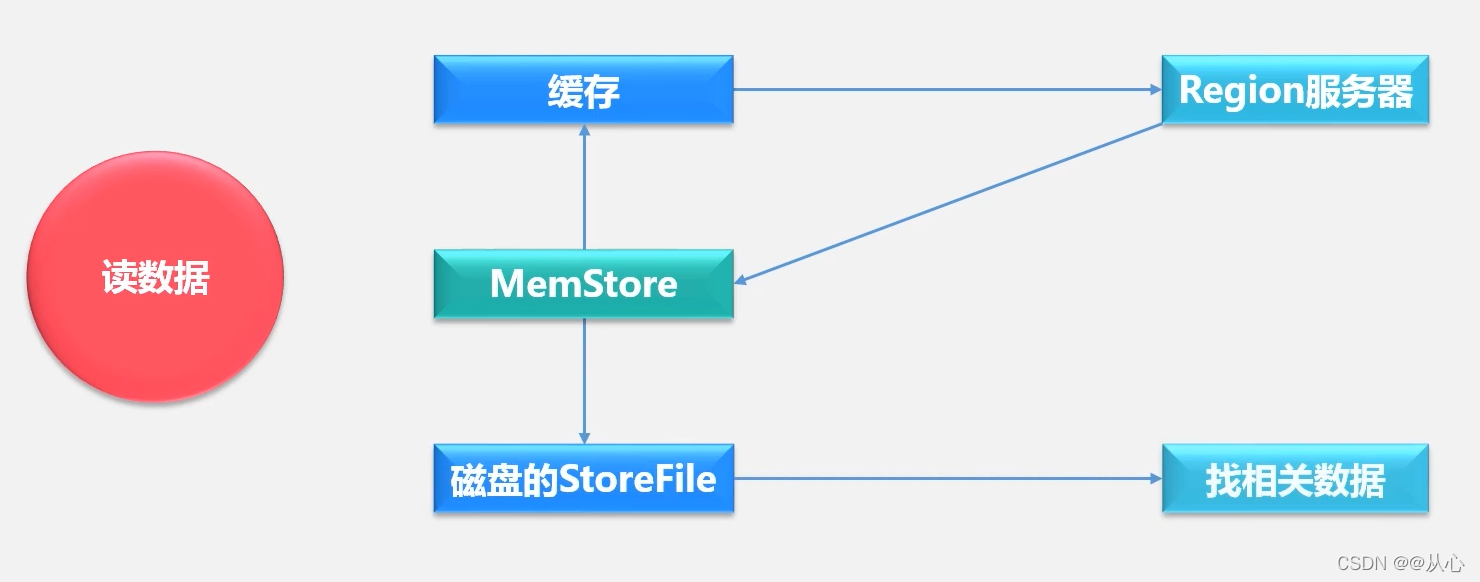
当用户读取数据时,Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
缓存刷新
系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记。每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件。
每个Region服务器都有一个自己的HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务。
StoreFile的合并
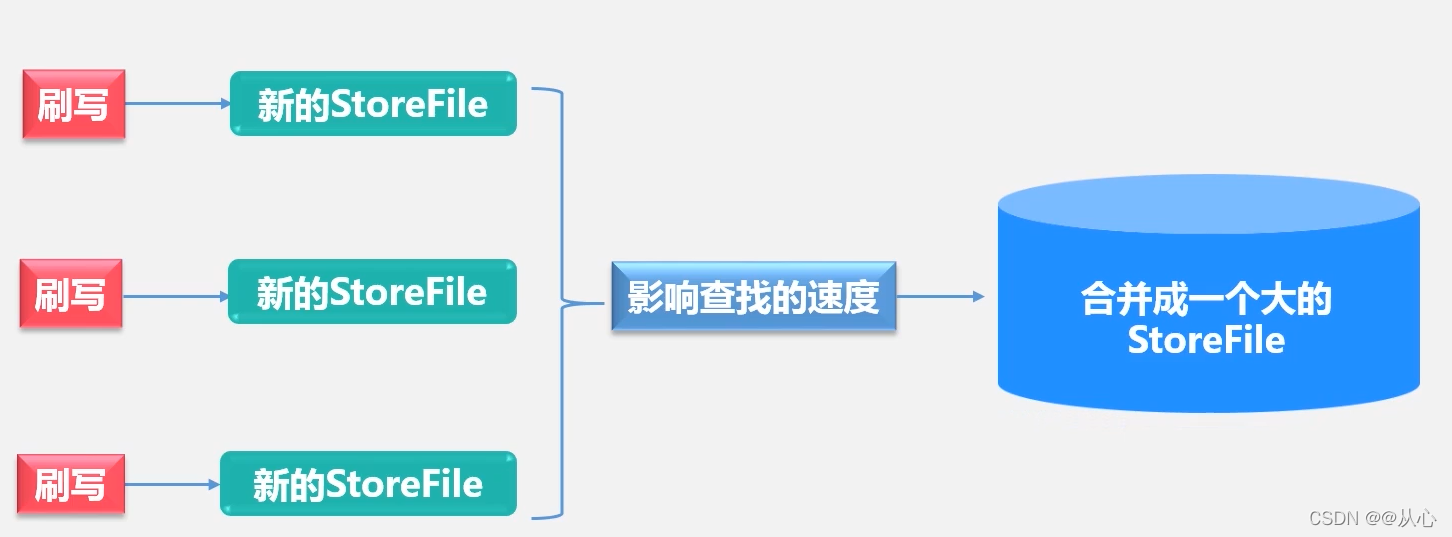
每次刷写都生成一个新的StoreFile,数量太多,会影响查找速度。调用Store.compact()把多个合并成一个。但是合并操作比较耗费资源,只有数量达到一个阈值才启动合并
StoreFile合并之后越来越大,达到阈值之后,引发分裂操作,一个大的Region就会分裂成两个Region
HLog的工作原理
HBase是一个经典的分布式环境,底层的机器会经常故障,所以一般通过日志恢复相关数据
Zookeeper会实时监控整个集群,发现某个服务器出现问题后,通知给相关的Master。Maseter来通过故障服务器上的HLog文件,将其进行拆解,拆分出每个Region的日志记录,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器。Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复。
共用日志优点:提高对表的写操作性能
缺点:恢复时需要分拆日志
HBase应用
性能优化方案
-
读取最新被写入的数据
行键是按照字典序存储,可以充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块
若想要时间比较靠近的数据存放在一起,可以将时间戳作为行键的一部分,由于是字典按升序排序,想要逆序排序,可以用系统最大的整型值减去时间戳,即Log.MAX_VALUE - timestamp作为行键,保证最新写入的数据在读写时可以快速被命中。 -
提升读写性能
可以设置HColumnDescriptor.setInMemory(true),把相关的表放在Region服务器的缓存中,根据需要来决定是否放入缓存 -
最大版本数
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最
新版本的数据,那么可以设置setMaxVersions(1) -
自动清除数据
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeTo Live)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(22460*60)。
HBase怎么检测性能?
- Master-status(自带)
- Ganglia
- OpenTSDB
- Ambari
构建HBase二级索引
二级索引,又叫辅助索引
HBase只有一个针对行健(row key)的索引,若要访问HBase表中的行,只有三种方式:
- 通过单个行健访问
- 通过一个行健的区间来访问
- 全表扫描
想要为HBase表构建二级索引,需要使用其他产品为HBase行健提供索引功能:
- Hindex二级索引
- HBase + Redis
- HBase + solr
原理:采用HBase0.92版本之后引入的Coprocessor特性
Coprocessor提供了两个实现:endpoint和observer,endpoint相当于关系型数据库的存储过程,而observer则相当于触
发器。observer允许我们在记录put前后做一些处理,因此,而我们可以在插入数据时同步写入索引表。
优点:非侵入性,引擎构建在HBase之上,既没有对HBase进行任何改动,也不需要上层应用做任何妥协。
缺点:每插入一条数据需要向索引表插入数据,即耗时是双倍的,对HBase的集群的压力也是双倍的。
1. Hindex二级索引
Hindex是华为公司开发的纯Java编写的HBase二级索引,专门针对于HBase数据库的。支持多个列索引,也支持基于部分列
值的索引。缺点是频繁的更新存储在底层磁盘的索引表,代价很高。
2.HBase+Redis
Redis是一种键值数据库产品,能高效地管理键值对,由Redis数据库在缓存中管理索引,在定期把索引更新到HBase底层数据中。
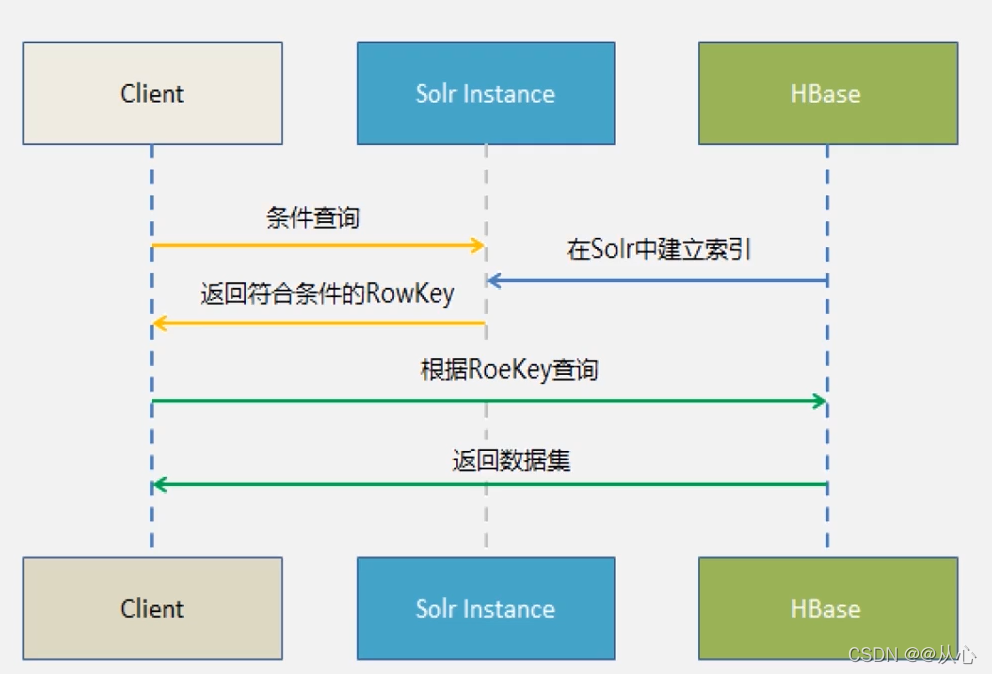
3.HBase+solr
Solr是一个高性能,基于Lucene的全文搜索服务器。Solr构建起的是其他列和行键之间的对应关系。
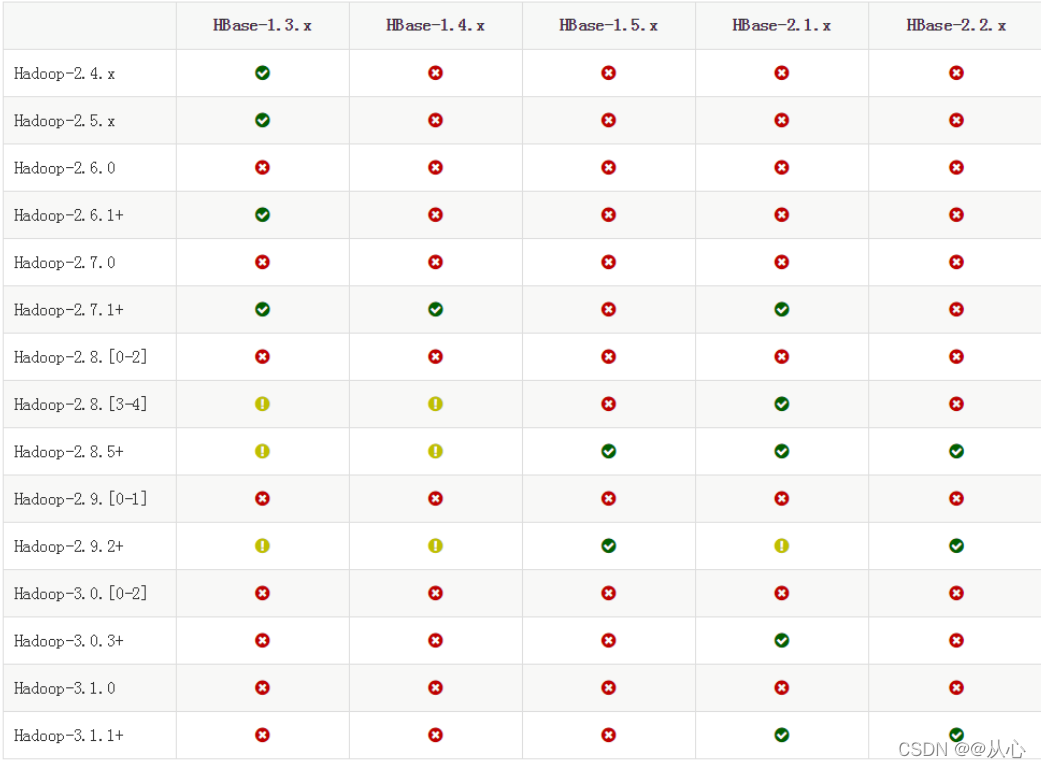
HBase的安装
HBase的版本一定要和Hadoop的版本保持兼容,不能随意选择
确认好HBase的安装版本之后,进行安装
- 解压HBase压缩包,
sudo tar -zxvf ./hbase-2.2.2-bin.tar.gz -C /usr/local - 重命名,
sudo mv ./hbase-2.2.2 ./hbase - 配置环境变量
vim ~/.bashrc在文件中 PATH中加入:/usr/local/hbase/bin,文件生效source ~/.bashrc - HBase伪分布式配置,确保JDK、Hadoop、SSH已经安装,
进入hbase的conf目录下,修改 hbase-env.sh 文件和hbase-site.xml 文件
hbase-env.sh 中加入以下内容export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HBASE_CLASSPATH=/usr/local/hadoop/conf export HBASE_MANAGES_ZK=true- 1
- 2
- 3
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 先启动Hadoop,再切到对应安装目录下,使用
./bin/start-hbase.sh启动hbase,jsp检查是否有HRegionServer、HMaster、HQuorumPeer进程。 - 使用
./bin/hbase shell,进入shell交互环境
HBase常用Shell命令
- 创建student表
create 'student', 'Sname', 'Ssex', 'Sage', 'Sdept' - 查看表信息
describe ‘student’ - 添加数据,一次只能添加一个单元格的数据
put 'student', '95001', 'Sname', 'zhangsan'跟上表名,行键,列名,value - 删除数据
delete 'student', '95001', 'Ssex'删除Ssex这一列数据 - 删除所有数据
deleteall 'student', '95001' - 查看数据
get 'student', '95001' - 查看表里的所有数据
scan 'student' - 删除表,先禁表
disable 'student',再删除表drop 'student'


