
- 1Python编程入门学什么?_python程序设计学什么
- 2数组在Java中的运用_java 数组使用
- 3【问题记录】02 Linux服务器安装MySql数据库报错:Failing package is: mysql-community-server GPG Keys are configured as_linux mysql8 yum安装 gpg keys are configured
- 4软考证到底有多大个鸟用?_软考有什么用
- 5央视的AI动画《AI我中华》宣传视频,原来用AI工具Stable Diffusion制作,竟然这么简单?
- 6给大家推荐一个用Java开发的开源的AI模型_java 开源的ai
- 7虚拟机red hat linux下oracle9.2i的安装配置_oraclelinux9.2 安装oracle
- 8<网络安全>《83 微课堂<国家数据要素总体框架>》
- 9鸿蒙开发 - 常用UI组件介绍_鸿蒙开发中其他组件知识点
- 10抖音短视频数据抓取实战系列(十一)——Appium与Mitmproxy联合-自动取存抖音用户信息_appnium抓取数据
飞桨框架架构演进与核心技术
赞
踩

本系列根据Create 2024 百度AI开发者大会「大模型与深度学习技术论坛」嘉宾分享整理。本文整理自百度杰出架构师胡晓光的主题分享——「飞桨框架架构演进与核心技术」。

深度学习框架发展历程
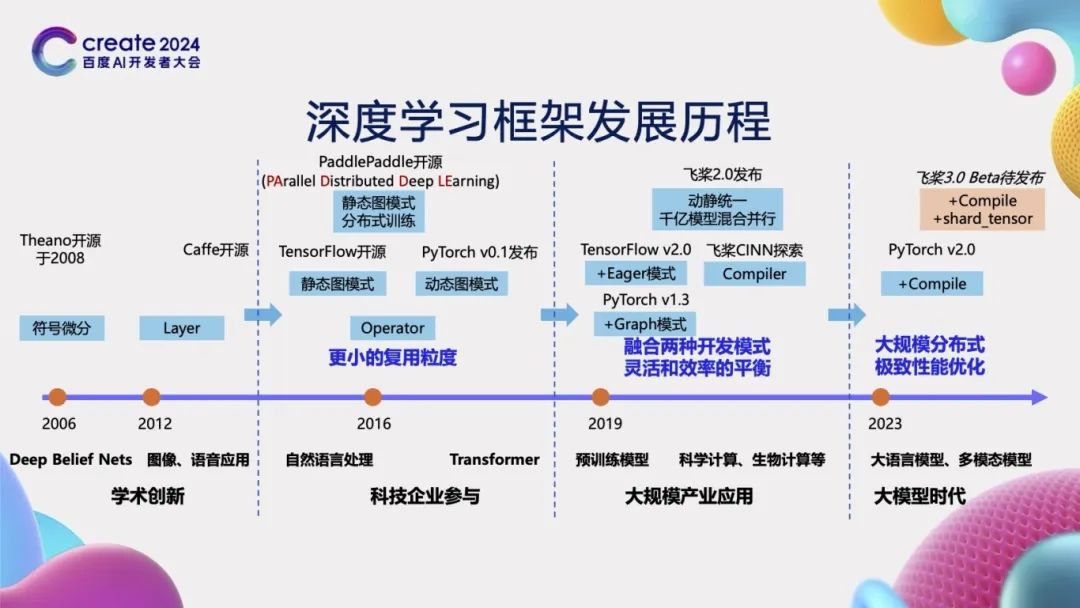
在人工智能发展的初级阶段,模型结构相对简单,无需深度学习框架,可直接通过手写编码实现。然而,随着模型复杂性的逐步提升,深度学习框架变得至关重要。例如,2008年开源的Theano和2013年推出的Caffe等框架,为复杂模型的构建提供了有力支持。在框架开发的初级阶段,它们使用的基本单元粒度较大,如Caffe采用的Layer为基本单元,要求开发者手动编写Layer的前向及反向逻辑,操作难度较大。
自2015年起,越来越多的科技企业投身于深度学习框架的研发,并推出了新的框架。如2015年Google的TensorFlow、2016年百度的飞桨(PaddlePaddle)以及2017年Facebook的PyTorch等相继开源。这些框架凭借其先进的设计理念,引入了Operator以及更细粒度的可复用单元——算子,通过灵活组合这些算子,能够构建出更为复杂的神经网络结构,从而显著提高开发效率。飞桨自开源之初就致力于服务产业实践,支持大规模的分布式训练,其名称“PaddlePaddle”正是“PArallel Distributed Deep LEarning”的缩写,体现了其设计理念。
到了2019年,TensorFlow 2.0引入了Eager模式,而PyTorch 1.3则增加了Graph模式,标志着深度学习框架开始融合动态图与静态图两种不同的开发模式。到了2021年初,飞桨发布了2.0版本,进一步融合了动态图的灵活性与静态图的高效性,同时支持了千亿参数模型的混合并行训练。与此同时,飞桨还开启了神经网络编译器技术CINN(Compiler Infrastructure for Neural Networks)的探索之旅。
随着大模型时代的到来,模型参数规模不断扩大,训练成本也随之攀升,这对深度学习框架在大规模分布式训练和性能优化方面提出了更高的要求。为此,在2023年,PyTorch发布了2.0版本,其核心在于通过引入Compile机制来提升模型运行速度。飞桨也即将在6月推出3.0 Beta版本,其关键特性是增加了编译器性能优化技术和基于张量分割的分布式自动并行技术,以应对当前深度学习领域的新挑战。

大模型时代的深度学习框架
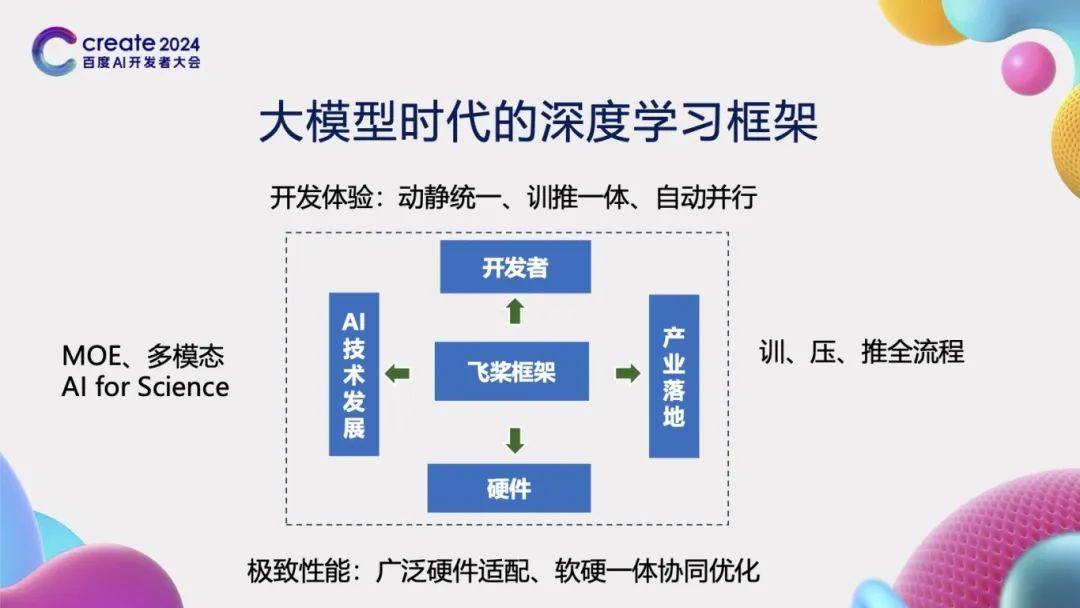
在大模型时代,深度学习框架的设计对于推动人工智能技术的发展至关重要,从以下四个方面进行考虑:
首先,框架向上对接开发者的需求。一个优秀的深度学习框架应当为开发者提供极致的开发体验。这不仅仅意味着提供一个用户友好的开发环境,更重要的是要能够大幅度减少开发者的学习成本和时间成本,同时显著提升开发的便利性。为此,飞桨框架创新性地提出了“动静统一、训推一体、自动并行”的先进概念,极大地提高了开发效率。
其次,框架向下对接硬件。现代深度学习应用往往需要在多样化的硬件平台上运行,因此,框架必须能够兼容并适配各种不同的硬件设备。这要求框架能够智能地隔离不同硬件接口之间的差异,实现广泛的硬件适配性。同时,为了充分发挥硬件的性能,框架还需要具备软硬件协同工作的能力,确保在利用硬件资源时能够达到最优的性能表现。
再者,框架需要考虑到AI技术发展的整体趋势。随着技术的不断进步,诸如MOE(Mixture of Experts)、多模态以及科学智能(AI for Science)等前沿技术逐渐成为新的研究热点。深度学习框架应当能够紧跟这些技术发展的步伐,为研究者提供必要的支持和工具,以推动相关技术的快速发展和应用。
最后,框架需要能够支持产业的实际落地应用。在产业化方面,框架需要具备支持训练、压缩、推理一体化的全流程能力。这意味着,从模型的训练到优化,再到实际部署和推理,框架应当提供一套完整、高效的解决方案,以满足产业界对于深度学习技术的实际需求。

飞桨框架架构图和核心技术
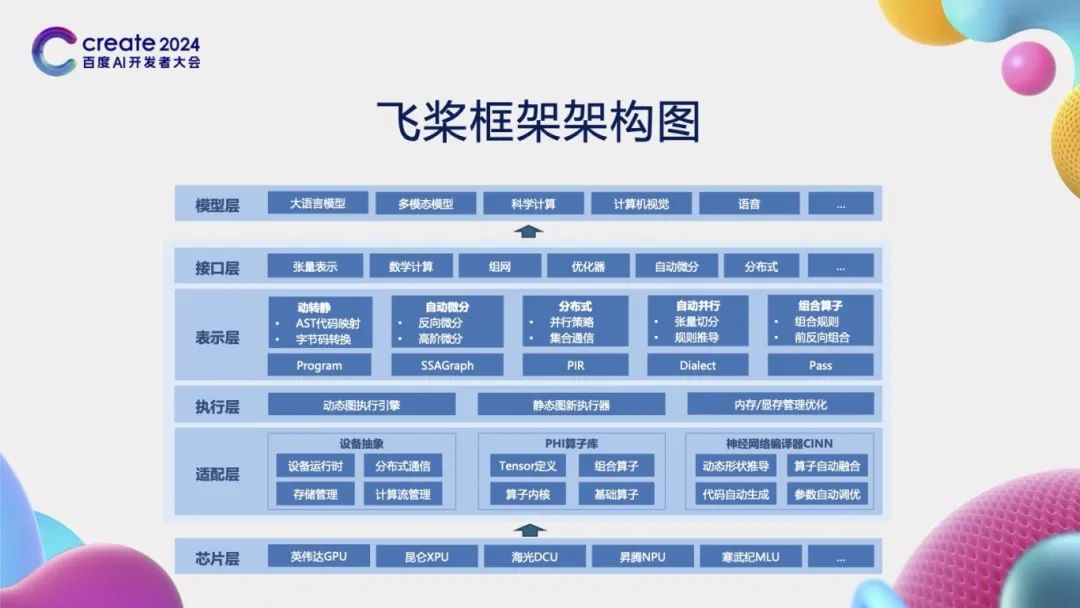
为了实现深度学习框架的上述特性,我们必须对框架的架构进行精心设计,确保其能够向上支持各种复杂的模型构建,同时向下与多样化的芯片实现无缝对接。飞桨框架在这方面采用了先进的分层架构设计,该架构分为以下四层:
首先是“接口层”,这一层主要提供了与深度学习相关的各种API接口,如张量表示、模型组网、优化策略等。通过这些接口,开发者能够便捷地构建和训练自己的深度学习模型,无需深入到底层的技术细节中去。
紧接着是“表示层”,它包含了几个核心的概念表示,如Program、SSAGraph以及飞桨中间表示PIR(Paddle Intermediate Representation)。PIR具有高度的灵活性和可扩展性,能够实现多种变化,包括动态图到静态图的转换(动转静)、自动微分、分布式训练、自动并行以及组合算子的优化等。这些功能为深度学习模型的计算优化提供了强有力的支持。
再来看“执行层”,这一层的设计旨在支持动态图和静态图的执行,并且能够根据实际需求进行显存和内存的管理优化。这意味着,无论开发者选择使用动态图还是静态图进行模型开发,飞桨框架都能提供高效的执行环境,同时确保资源利用的最优化。
最后是“适配层”,它主要负责与硬件设备的接口抽象和适配工作。包括飞桨高可复用算子库 PHI (Paddle HIgh reusability operator library),该库提供了一系列高效的运算操作,以满足不同硬件设备上的计算需求。此外,适配层还包括神经网络编译器CINN,使得深度学习模型能够在各种硬件平台上实现高效运行。

动静转换技术

我们来探讨飞桨框架所提供的静态图和动态图两种开发模式。通过示例代码可以观察到,这两种模式在模型组网阶段的代码是完全一致的,因此我们称之为动静统一的组网方式。然而,它们之间的主要差异体现在计算图的构建和执行过程中。在静态图开发模式下,一旦计算图被创建,它将保持不变。这意味着,无论输入多少批次的数据,计算图都不会发生改变。相反,在动态图开发模式下,每当输入新的数据批次时,计算图会动态地生成和执行。这种灵活性使得动态图模式在现代深度学习任务中备受欢迎。然而,尽管动态图模式具有诸多优势,但它也并非毫无缺点。
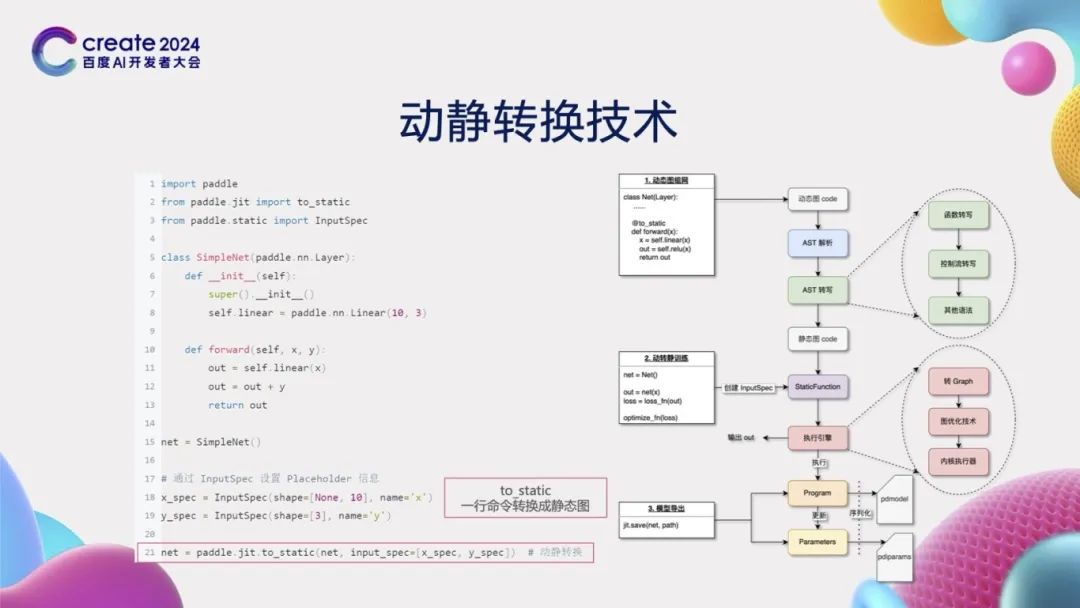
动态图模式虽然灵活,但也存在一个问题:由于计算图会频繁地创建和执行,这使得对其进行优化变得相当困难。特别是在推理部署场景下,动态图模式往往难以摆脱对Python解释器的依赖进行部署。而Python解释器的引入,在某些场景下,如资源受限的端侧环境,可能会导致效率低下或无法使用。为了克服这一难题,飞桨研发了动静转换技术,通过简单的一行命令(to_static),便能够将动态图的代码轻松转换为静态图代码。飞桨采用的技术方案是源代码到源代码的转换,即分析并转写动态图Python源代码,进而生成对应的静态图Python源代码;在获取源代码后,使用静态Python解释器来执行这段静态图代码,从而得到计算图表示。
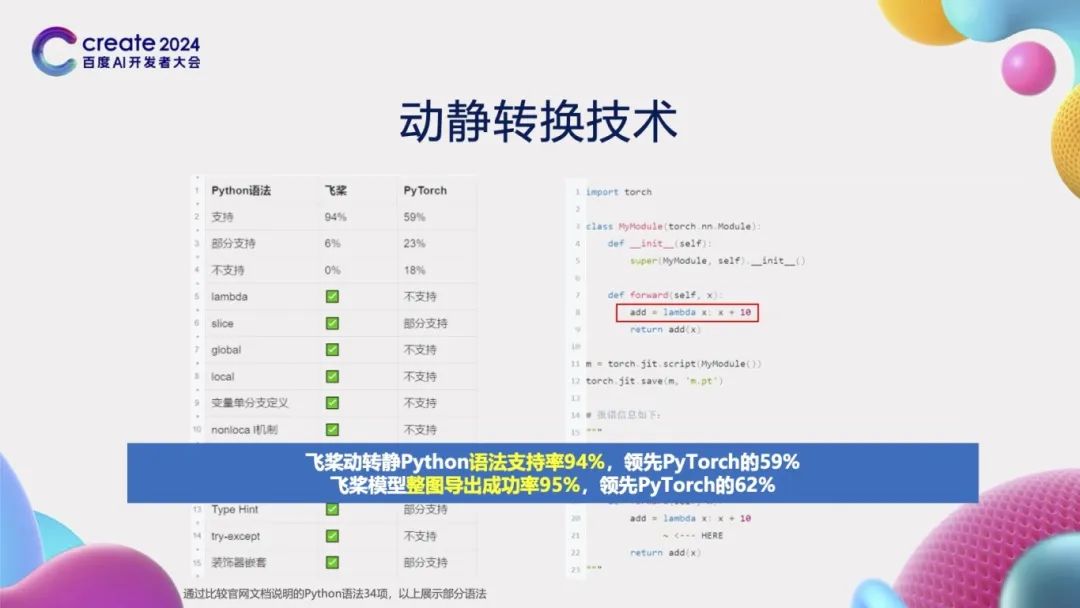
动静转换技术的核心挑战在于对Python语法的支持程度。通过详细对比官方文档并进行实际测试,我们发现飞桨对Python语法的支持率高达94%,显著超过了PyTorch的TorchScript方案,其支持率仅为59%。举例来说,TorchScript方案并不支持Python中广泛使用的lambda表达式,而这在飞桨中则得到了很好的支持。根据我们的实际测试,飞桨的动静转换功能在整图导出任务的成功率高达95%,远胜于TorchScript方案的62%。深入分析后发现,TorchScript方案是通过源代码转换技术,将动态图的Python源代码转变为自定义的TorchScript源代码。然而,这种转换后的TorchScript代码无法再被Python解释器执行。从本质上讲,从Python语言转换到其他语言的难度相当于开发一个全新的Python解释器。相比之下,飞桨框架的优势在于它同时兼容动态图和静态图两种开发模式。因此,在进行动静转换时,仅需实现从动态图Python源代码到静态图Python源代码的转换。这一转换过程可以通过Python解释器进一步增强对Python语法的支持,从而大大降低了实现的难度。正因如此,飞桨在整图导出成功率上远超PyTorch。
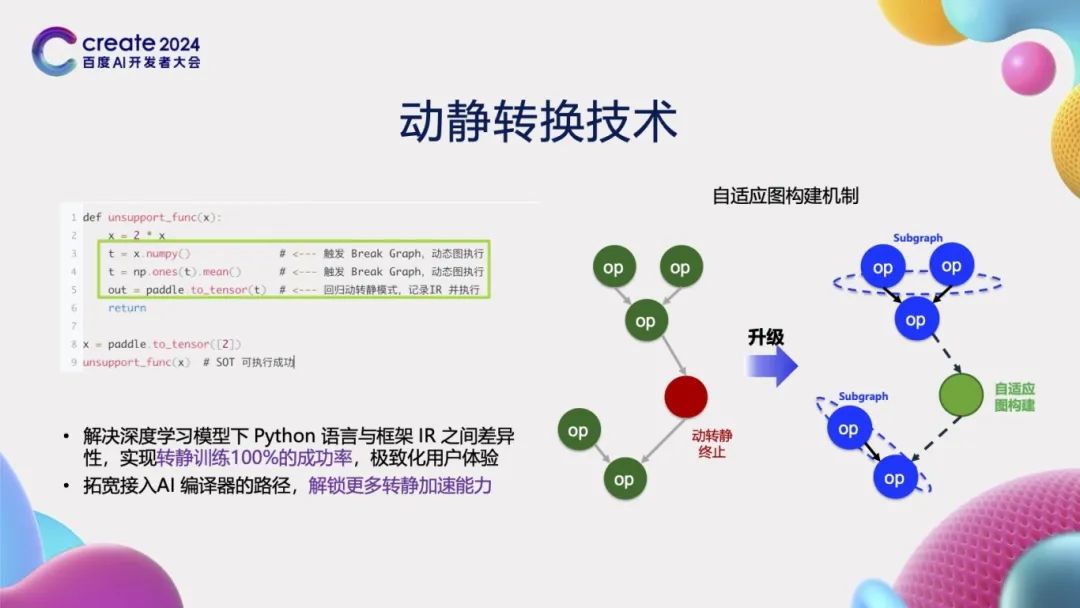
在训练场景,针对那些无法进行动静转换的情况,例如Python代码中调用numpy等第三方库时,这些库的函数调用无法直接转换为静态图表示。为了解决这一问题,飞桨创新性地研发了“自适应图构建机制”。当遇到不支持的语法时,该机制会被触发,自动断开这些部分,并利用前后相邻的图进行重新构建。通过采用这种方案,我们在训练场景中可以实现100%的动静转换成功率,从而为编译器等计算图优化技术提供了更广阔的空间。

高扩展中间表示PIR
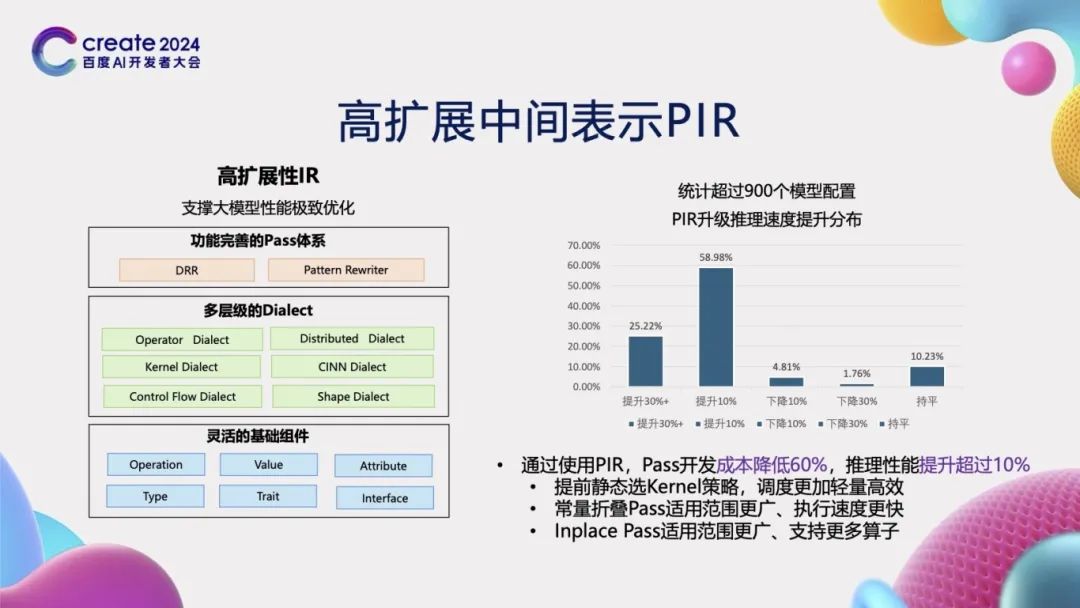
在通过动静转换技术获取计算图表示后,我们仍需对计算图进行一系列优化,如自动微分变换、分布式变换以及编译器加速等。为实现这些优化,我们需要一种“高扩展性的中间表示”——PIR(Paddle Intermediate Representation)。PIR具备灵活的基础组件,支持Operation、Value、Attribute等元素的定义,从而便于进行扩展。其中,Dialect定义是PIR的核心组成部分,它类似于形式化语言中的一种表达,能够表示一个相对完整的体系。这个体系涵盖了分布式、编译器、动态形状推理与控制流等多个方面。在表示的基础上,我们还需要利用Pass进行变换。为此,PIR提供了DRR和Pattern Rewriter两种机制,以实现IR的灵活变化。为了验证PIR的有效性,我们比较了超过900个模型配置在使用PIR后的推理速度提升情况。结果显示,25%的模型推理速度提升了超过30%,60%的模型提升了超过10%。总体而言,使用PIR后,推理整体性能提升了超过10%。这一显著提升主要归功于新PIR能够提前静态选择Kernel,从而降低了调度成本和开销。此外,常量折叠策略的应用范围更广,Inplace Pass策略机制也得到了更广泛的应用。采用新的PIR表示机制后,我们可以实现训推一体,展现出优异的性能和表现。

高阶自动微分
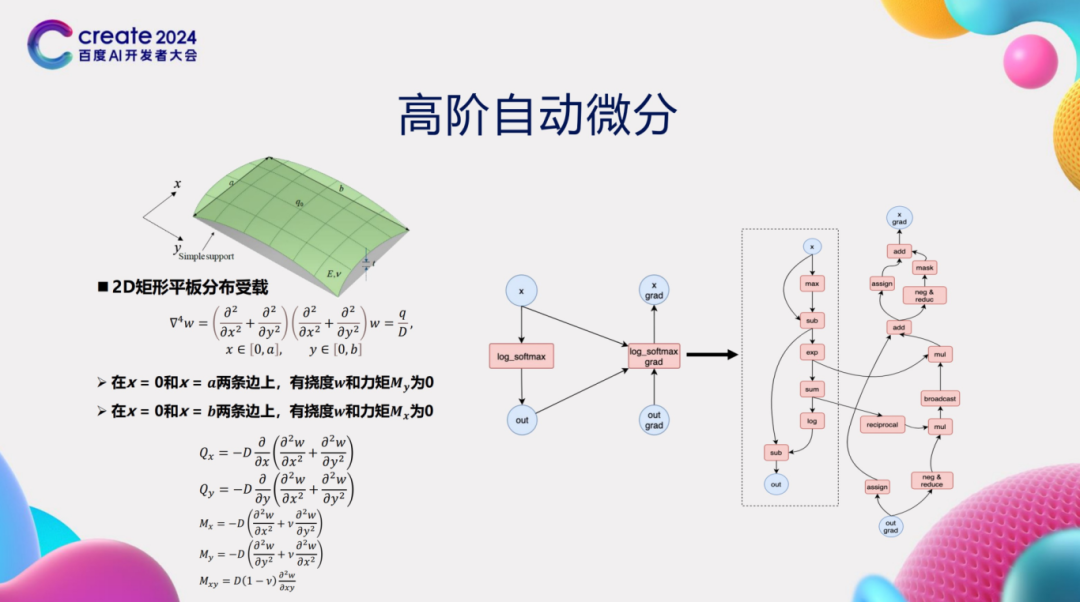
深度学习模型的训练过程涉及使用随机梯度下降(SGD)等优化算法来更新模型参数。在这一过程中,深度学习框架的自动微分功能发挥着核心作用,它利用链式法则自动计算出损失函数相对于模型参数的梯度。尽管大多数深度学习任务只需计算一阶导数,但在某些AI for Science场景中,却需要计算高阶导数,这无疑增加了自动微分的复杂性。以2D矩形平板分布受载问题为例,该问题的内在机理需要使用4阶微分方程来描述。因此,为了求解这类问题,深度学习框架必须支持高阶自动微分功能。然而,高阶自动微分的实现面临诸多挑战。具体而言,框架需要为每个算子编写高阶微分规则。随着阶数的增加,微分规则的复杂性也随之上升。当阶数达到三阶或更高时,编写这些规则变得极其困难,同时正确性难以保证。为了解决这一问题,我们提出了基于基础算子组合的高阶自动微分技术。该技术的关键在于将复杂算子(如log_softmax)拆解为多个基础算子的组合。然后,我们对这些基础算子进行一阶自动微分变换。重要的是,基础算子经过一阶自动微分变换后,其得到的计算图仍然是由基础算子所构成。通过反复应用一阶自动微分规则,我们可以轻松地获得高阶自动微分结果。
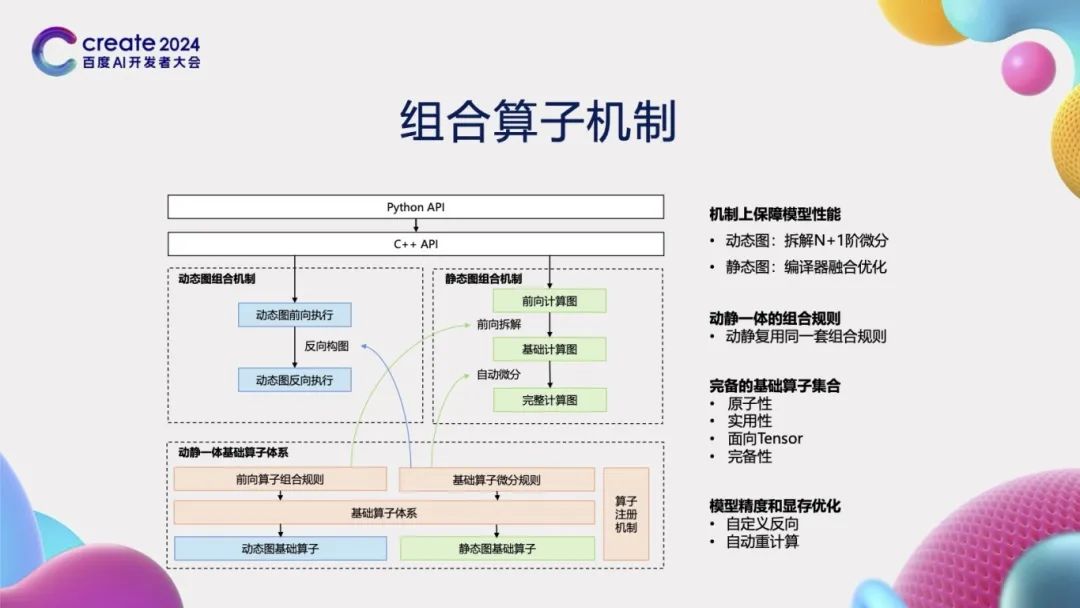
为了支持高阶自动微分,飞桨框架精心设计与实现了组合算子机制。这一机制不仅兼容动态图模式和静态图模式,而且在动态图模式下支持N+1阶微分的拆分,同时在静态图模式下能够进行编译器融合优化。我们创新性地设计并实现了动静一体的算子组合规则,这意味着同一套组合规则在动态图和静态图两种模式下均可复用,从而避免了重复开发。在构建基础算子体系时,我们以Tensor作为核心操作对象,确保了算子的原子性、实用性和完备性。此外,我们还支持自定义反向操作和自动重计算功能,这些特性不仅提升了模型的精度,还有效地减少了显存占用,为用户提供了更高效、更灵活的深度学习体验。
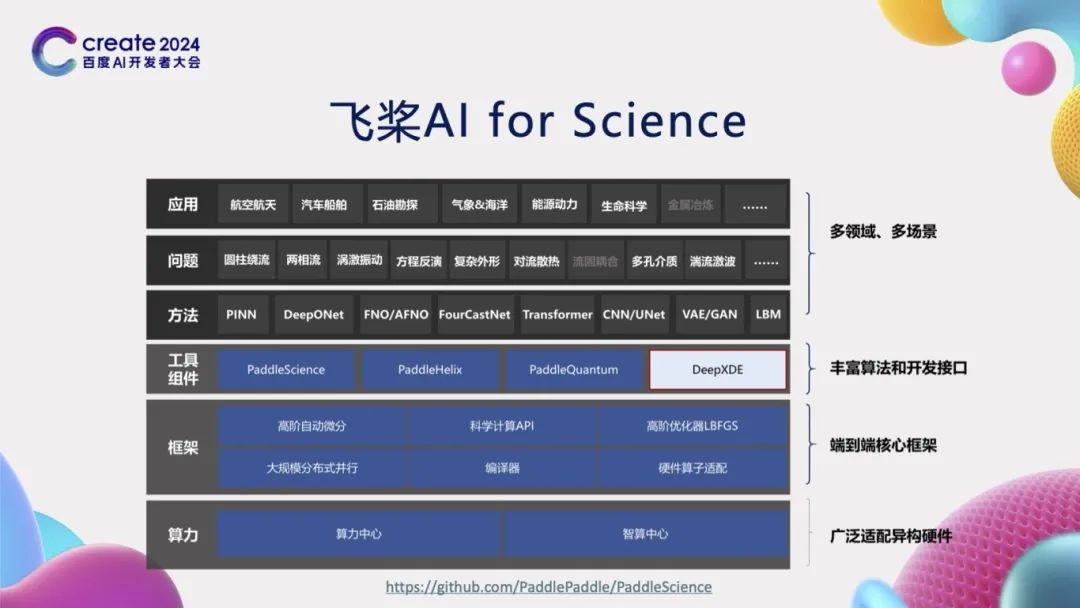
基于前期的工作积累,飞桨已经开始探索科学智能(AI for Science)领域的相关工作。为了满足AI for Science任务的各种需求,飞桨在框架层面实现了基于组合算子的高阶自动微分功能,并提供了专门针对科学计算的开发接口,此外还实现了高阶优化器,如LBFGS等。在工作组件层面,我们研发了赛桨(PaddleScience)、螺旋桨(PaddleHelix)等系列开发套件,以及支持了DeepXDE等科学计算库。我们实现了物理信息网络(PINN)、傅里叶算子学习(FNO)等数据驱动、机理驱动和数据机理融合的方法。这些方法在航空航天、汽车船舶、气象海洋、生命科学等多个领域都具有广泛的应用潜力。

动静统一自动并行
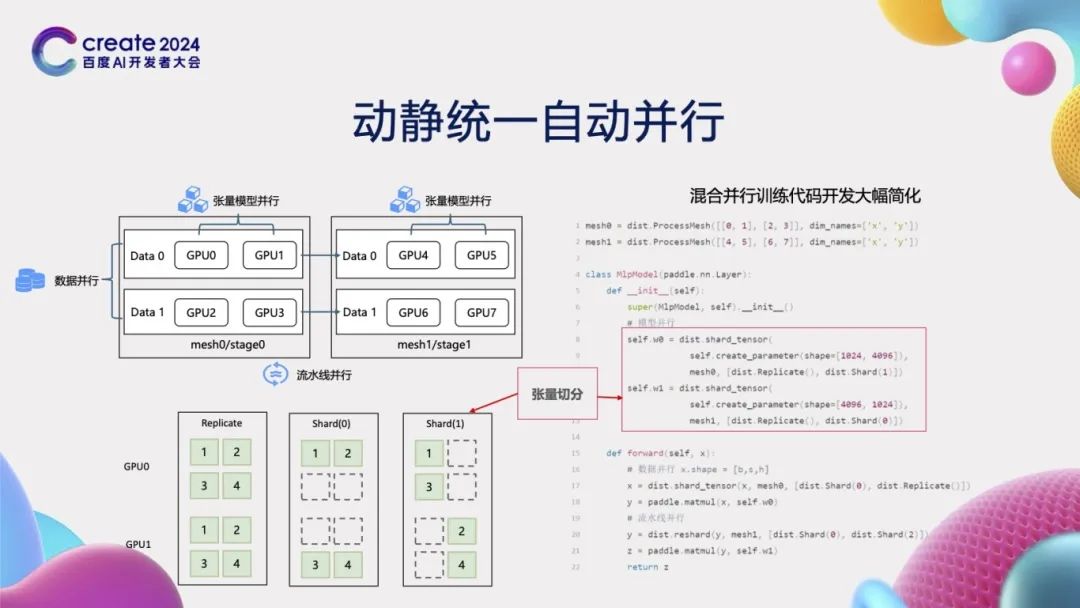
在大模型开发场景中,多维混合并行显得尤为重要。然而,多维混合并行的开发过程往往相当复杂。以数据并行、张量模型并行和流水线并行为例,开发者必须精心处理计算、通信、调度等多元逻辑,才能编写出正确的混合并行代码,这无疑提高了开发的难度。为了攻克这一难题,我们推出了动静统一的自动并行方案。我们通过“张量切分”的方式,对不同的分布式策略进行了抽象化处理。如左下角图示,GPU上标注的不同数字(1, 2, 3, 4)代表张量的各个元素。通过明确指定张量的切分方式,我们可以轻松地在GPU 0和1之间对数据进行复制或切分。如右侧代码所示,复杂的并行策略通过张量切分的方式,仅用几行代码就能实现。此外,所有与通信相关的繁琐过程都由框架自动处理,从而极大地提升了开发效率,也显著降低了开发的难度。
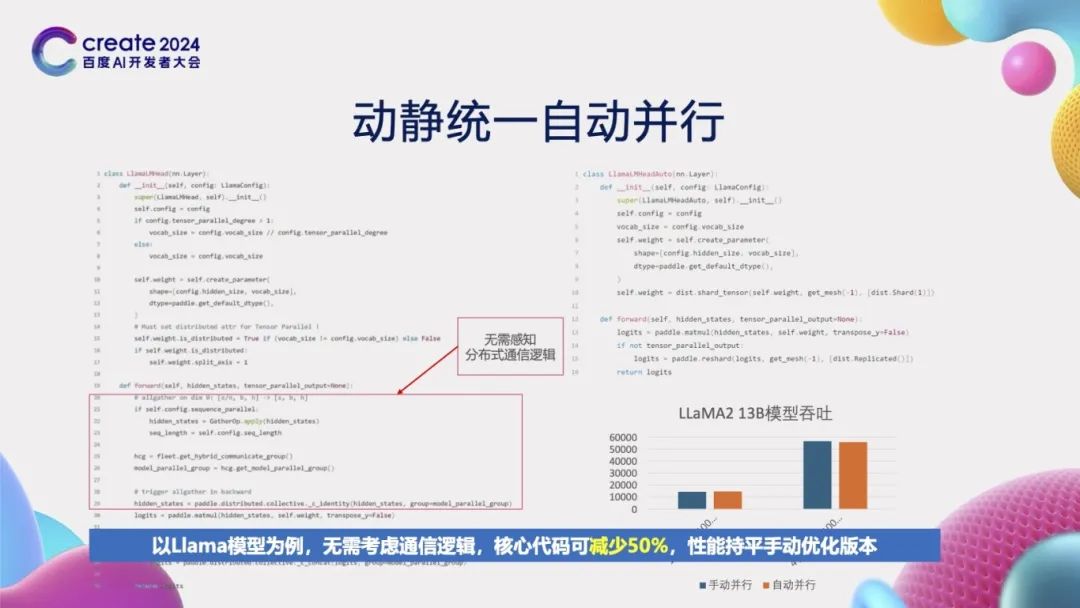
我们来观察一个具体的llama模型训练实例。在左侧,展示了动态图手动并行的开发方式,它要求开发者不仅要选择合适的并行策略,还必须精心设计通信逻辑。然而,在右侧,通过采用自动并行的开发方式,开发者无需再考虑复杂的通信逻辑。这种方法的优势显而易见:核心代码量减少了一半,从而大大降低了开发的难度;从实验结果可以看到,当前这种自动并行的性能与动态图手动并行的性能不相上下,未来还有进一步提升的空间。

深度学习编译器

飞桨框架中的一项关键技术是“深度学习编译器”。那么,为什么在深度学习框架中需要引入编译器技术呢?让我们通过一个实例来阐释这一点。以LLaMA2模型中经常使用的RMSNorm为例,其计算公式相对简单明了。从左侧的代码示例中可以看到,相应的代码也非常直观,可以通过直接调用加、减、乘、除等基础算子来组合出所需的公式。然而,这种方式在进行加法和乘法运算时,每次都是独立的算子调用。算子调用意味着数据需要从显存拷贝到寄存器中进行计算,完成后再拷贝回显存,这在访存密集型的计算中效率非常低。另一种方法是直接手写一个大算子,虽然执行速度较快,但灵活性较差,因为它变成了固定的函数调用,开发者对其内部实现并不了解,这无疑增加了开发难度。从性能角度来看,纯算子组合的方式虽然最为灵活,但速度却是最慢的。相比之下,手写大算子的速度要快上4倍多。而深度学习编译器的应用,则能在保持灵活性和易用性的前提下,实现性能的显著提升。通过使用深度学习编译器技术,我们的速度相较于手写大算子的方法能提升14%,从而在灵活性和性能之间找到了一个理想的平衡点。
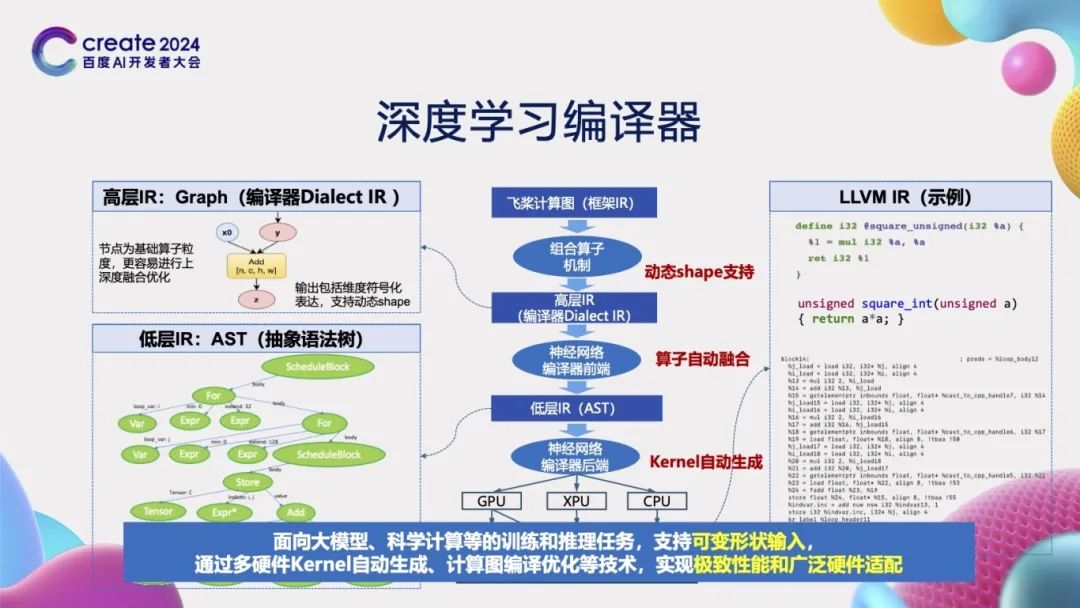
那么,如何通过编译器实现深度学习任务的加速呢?深度学习编译器的核心任务是接收一个计算图作为输入。首先,它会利用组合算子机制将这个计算图拆解为由基础算子组成的详细计算图,并在此过程中记录算子输入输出张量之间的形状关系,以适应动态形状张量的情况。接下来,通过神经网络编译器的前端部分,编译器会判断哪些基础算子可以被融合。对于可融合的基础算子,编译器会调用基础的Compute函数,将这些算子降级为由抽象语法树(AST)组成的低层中间表示(IR)。之后,通过神经网络编译器的后端部分,进一步将这些中间表示转换成具体的代码,这可能是CUDA C代码,也可能是LLVM IR代码。最后,利用NVCC编译器或LLVM编译器将这些代码转换成最终可在芯片上运行的可执行代码,从而实现深度学习任务的加速。

硬件适配方案
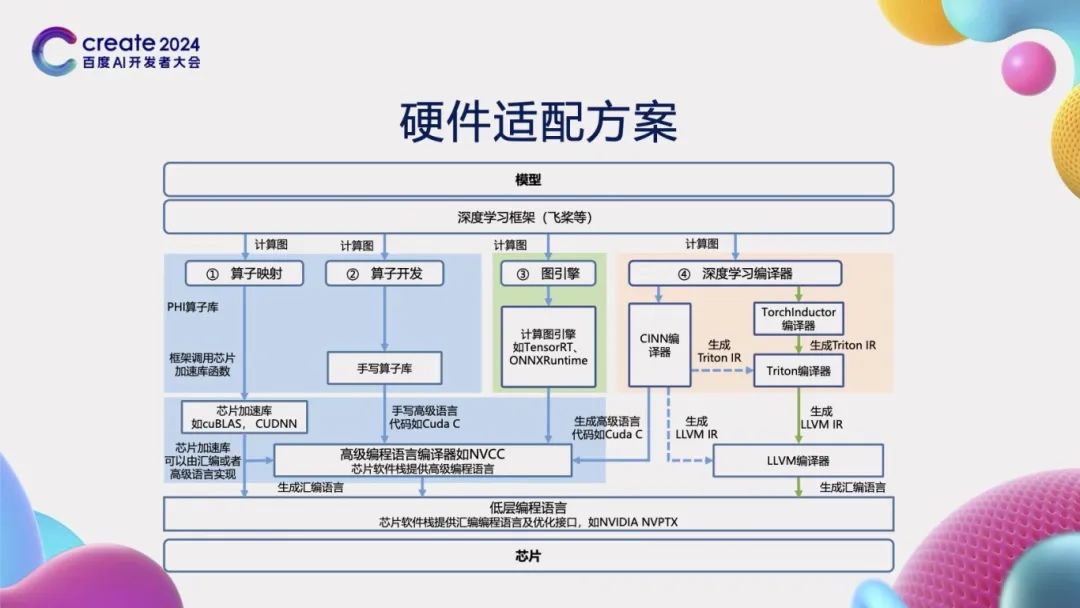
深度学习框架在实现高效能计算的过程中,还面临着一个关键性挑战,即如何实现与各类硬件的有效适配。为了应对这一挑战,飞桨框架采取了全面的策略,并成功实现了4种不同的接入方式,以确保能够灵活满足不同芯片的适配需求。这四种方式分别是:算子映射、算子开发、图引擎接入以及深度学习编译器。通过这些多样化的接入方法,飞桨框架不仅提升了深度学习应用的性能,还确保了广泛的硬件兼容性,从而为开发者提供了一个强大且灵活的工具,以适应不断变化的计算环境和需求。

基于前述的先进技术,飞桨与芯片厂商携手,共同打造一个繁荣的硬件生态。这一过程可划分为三个核心阶段。首先是“共聚”阶段,我们联合多家芯片厂商,共同发起了飞桨硬件生态圈。其次是“共研”阶段,与芯片厂商携手实现软硬一体的联合优化。最后是“共创”阶段,与芯片厂商深度合作,共创繁荣生态。至今,我们已与22家硬件厂商伙伴成功联合推出了飞桨生态发行版,标志着合作的深入与成果的显现。同时,我们的生态圈已吸引超过40家成员单位加入,覆盖了主流硬件厂商,提供了极为丰富的硬件支持框架,为用户带来更加多样化的选择。

飞桨新一代框架
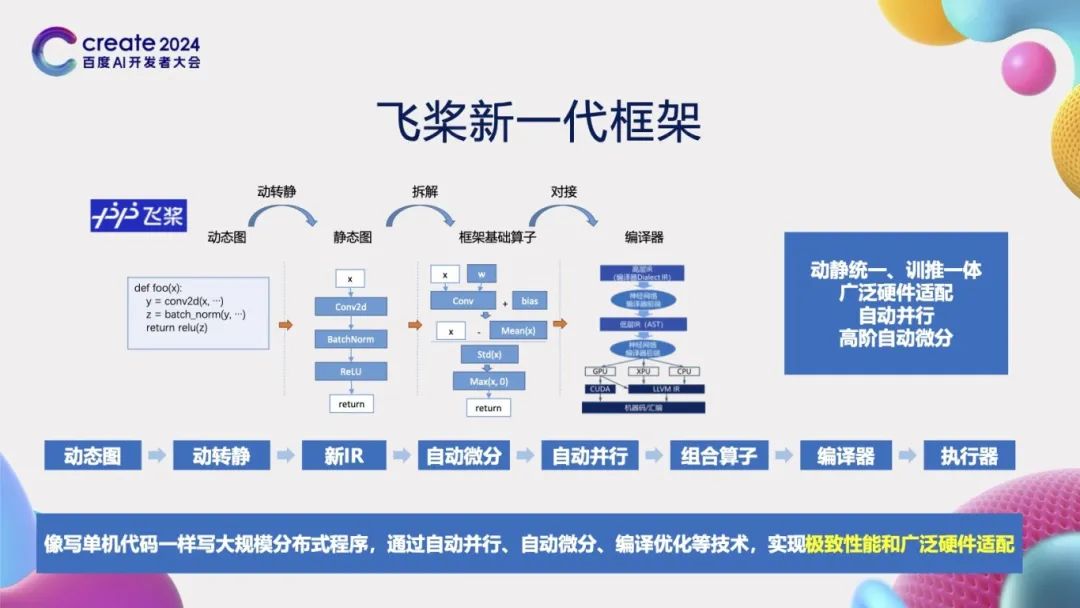
总结一下,在大模型时代和AI for Science时代背景下,飞桨框架通过一系列创新技术来更好地支持大模型和科学计算。我们设计了一个完整的流程:从接收动态图开始,通过动转静技术将其转换为新的中间表示(IR),然后进行自动微分处理。在完成自动微分后,我们应用自动并行技术来优化计算过程。接着,通过组合算子对计算进行拆解,再经由编译器进行优化,并最终执行。飞桨框架的独特之处在于实现了动静统一、训推一体、广泛的硬件适配性以及自动并行处理,同时还能支持高阶自动微分。我们希望为开发者提供灵活易用的使用体验,让编写分布式程序变得像编写单机代码一样简单,通过自动并行、自动微分、编译优化等自动化技术,实现极致性能和广泛的硬件适配。





关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

