
热门标签
热门文章
- 1sqlalchemy Annotated自定义Mapped类型_sqlalchemy mapped[datetime]
- 2VIM去掉utf-8 bom头_vim bom
- 3【设计模式系列8】深入分析代理模式(JDK动态代理和CGLIB动态代理)_jdk动态代理模式与cglib代理模式
- 4Windows系统支持Verilog自动实例化等功能的Vim插件的安装及使用教程_automatic.vim
- 5顶象滑块逆向分析——背景图还原分析_顶像滑块
- 6【AI实战】llama.cpp 量化部署 llama-33B_llama。cpp
- 7github镜像站_github镜像网站
- 8要想工作流程更简便,试试开源web表单设计器_web流程设计器
- 9多任务多目标CTR预估技术_目标预估算法
- 10ubuntu 换国内apt源_apt镜像源
当前位置: article > 正文
小白学大模型——Qwen2理论篇
作者:知新_RL | 2024-05-17 06:52:40
赞
踩
小白学大模型——Qwen2理论篇
一、Qwen2架构图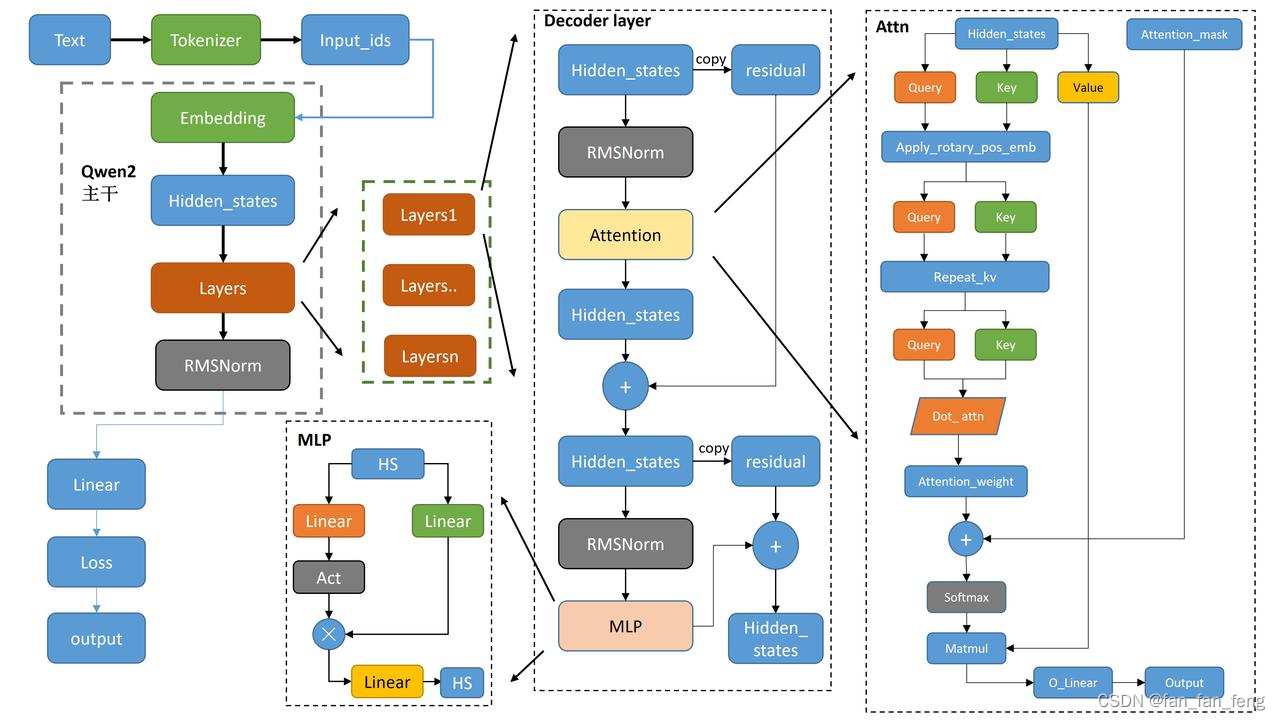
二、Qwen2 技术修改点
-
Transformer Architecture with SwiGLU activation: 不多说,最主流的transformer架构,不变。但是,SwiGLU激活函数是GLU变体,可以让模型学习表达更加复杂的模式。
-
QKV bias:在Transformer模型中,Q、K、V分别代表查询(Query)、键(Key)和值(Value)。这些向量是通过输入向量与对应的权重矩阵相乘得到的。QKV bias表示在计算Q、K、V时添加可学习的偏置项。
-
GQA:Grouped-query attention,它是一种插值方法,介于多查询和多头注意力之间,可以在保持接近多头注意力的质量的同时,达到与多查询注意力相当的速度。
-
Mixture of SWA and Full Attention: SWA指的是Sliding Window Attention,是一种注意力模式,用于处理长序列输入的问题。而full attention则是传统的注意力机制,考虑序列中所有元素的交互。这里的mixture可能指的是这两种注意力机制的结合使用。
-
Improved Tokenizer Adaptive to Multiple Natural Languages and Code: 这说明模型使用了一种改进的分词器,它不仅适用于多种自然语言,还能处理代码。在自然语言处理和编程语言处理中,分词器用于将文本分解成更小的单位(如词、字符或其他符号),这是理解和处理文本的基础步骤。
三、Qwen2核心类
- Qwen2RMSNorm: RMS归一化层
- Qwen2RotaryEmbedding: 旋转位置编码,和Qwen1不同.Qwen1可以对部分位置做旋转位置编码
- Qwen2MLP: 全连接层,lora和MOE主要在这个层上做事情
- Attention
- Qwen2Attention: 注意力层
- Qwen2FlashAttention2: 使用Flash Attention 2.0版本加速的注意力层
- Qwen2SdpaAttention: 使用Sdpa(pytorch自带的加速, Scaled Dot-Product Attention)加速的注意力层
- Qwen2DecoderLayer: 编码层,核心结构,之后就是堆叠 - Qwen2PreTrainedModel: 预训练类
- Qwen2Model: 不带head的Qwen2模型
- Qwen2ForCausalLM: 带Causal LM head的Qwen2模型 - Qwen2ForSequenceClassification: 带序列分类头的Qwen2模型
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/582433
推荐阅读

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

