
- 1一文带你了解MySQL的存储引擎
- 2(附源码)app心理健康线上咨询系统 毕业设计 031539_心理咨询 小程序 报告 源码
- 3卷王登场:yoloV5视频流处理LoadImages与box_label_yolov5 class loadwebam读rtsp
- 4数据库查询优化-添加索引_加查询索引语句
- 5计算机毕业设计题目大全(论文+源码)_kaic_鸿蒙开发 毕业设计题目
- 6一些不错的职场建议
- 7nlp入门之nltk_nltk(英文分词)
- 8Communication-efficient asynchronous federated learning inresource-constrained edge computing_communication-efficient federated learning for res
- 9嵌入式C语言基础(STM32)
- 10技术管理者应有的 4 种基本思维模式_技术管理思维
【ChatGPT】文本向量化与余弦相似度:揭开文本处理的神秘面纱(5)_chatgpt 写作 文本转化为向量
赞
踩
1、引言
在这个数字化的时代,我们每天都会面对大量的文本信息,从社交媒体到新闻报道,文本无处不在。但是,计算机要如何理解和处理这些文字呢?本文将为大家揭开其中的一些奥秘,详细解释文本向量化的概念,以及通过余弦相似度如何计算文本之间的相似度。
说白了,就是把文字、图片或其他东西变成一串数字,然后通过计算这些数字的距离来找相似的东西。这样做有啥好处呢?能够让搜索更快、更准确,而且在很多地方都能派上用场。
2、什么是向量?
先别怕,我们来聊聊向量。在这里,向量就是一种数学工具,它可以帮助我们在计算机中表示信息。你可以把向量看作是一个有序的数字列表,就像在坐标系中标出的点。在计算机科学领域,向量通常被用来表示数据的多维空间中的点。例如,一个二维向量 v 可以表示平面上的一个点,其中 v=[x, y]。
3、文本向量化方法
原理其实挺简单的。就是把东西转化成数字的形式,然后把这些数字放在一个虚拟的空间里。相似的东西在这个虚拟空间里靠得比较近,不相似的就远一点。这样,只要计算一下距离,就能找到相似的东西了。
1. 词袋模型
先别被名词吓到,词袋模型其实很简单。它把一段文字看成是一个袋子,里面装满了各种词汇。每个文档(比如一篇文章)都可以被表示为一个向量,向量的每个元素表示相应词汇在文档中出现的次数。
比如说,对于文本 “机器学习是人工智能的分支。”,我们可以得到一个向量表示: [1,1,1,1,1][1,1,1,1,1]。
2. Word Embeddings
再来看看Word Embeddings,这个名词听起来高级,但实际上很有趣。它通过将每个单词映射为一个实数向量,捕捉到了单词之间的关系。比如, “机器学习是人工智能的分支。” 可以被表示为向量: [0.23,0.45,−0.12,0.67,0.89][0.23,0.45,−0.12,0.67,0.89]。
4、余弦相似度计算
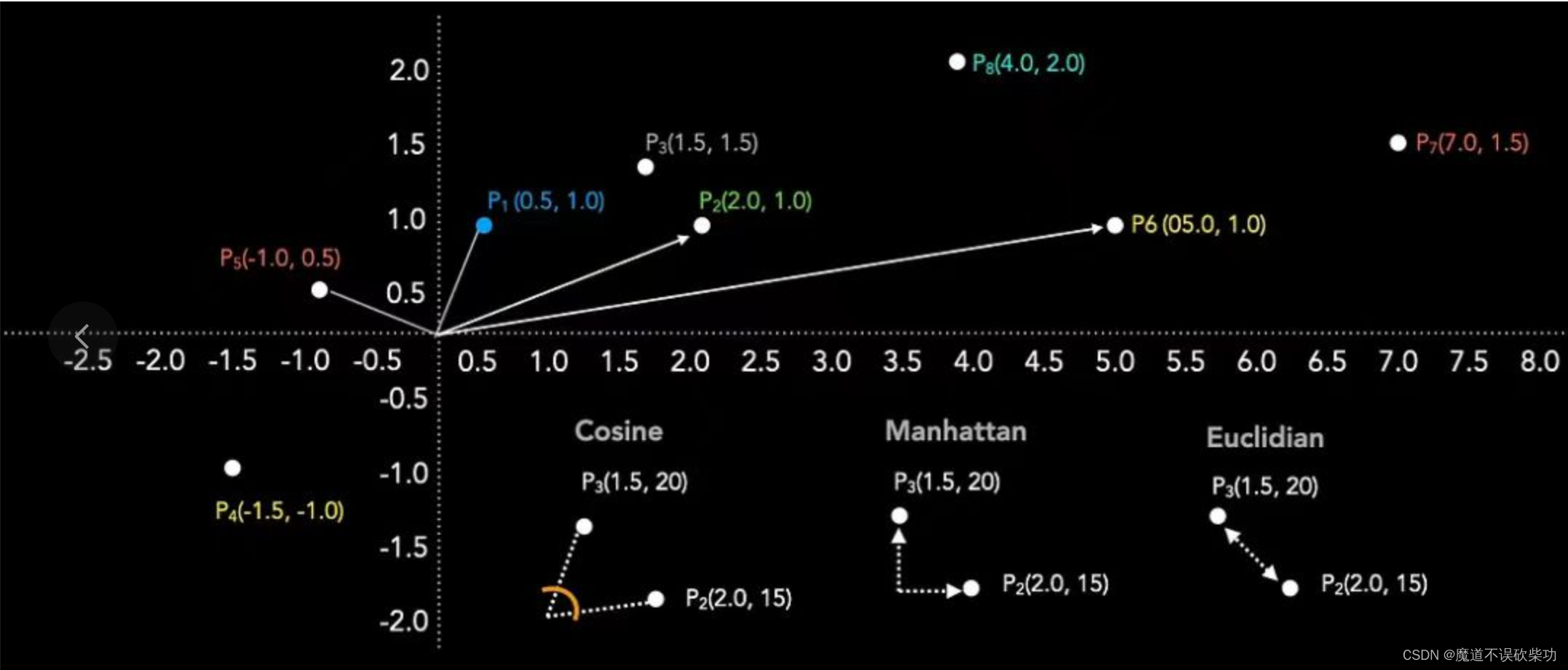
好了,现在我们有了文本的向量表示,接下来就是如何计算它们的相似度。这时候登场的就是余弦相似度了。这是一种衡量两个向量相似性的方法,通过计算夹角的余弦值来得出相似度。假设下面三个文本词向量分别是(为了演示简单,使用的是二维向量):
机器学习是人工智能的分支(用A表示)。对应的向量为 [1.5,1.5],
人工智能的重要分支是机器学习(用B表示)。对应的向量为 [2.0,1.0],
天气预报说明天可能会下雨(用C表示)。对应的向量为 [-1.0,-0.5]
计算这三个文本之间的相似度,如下图示:
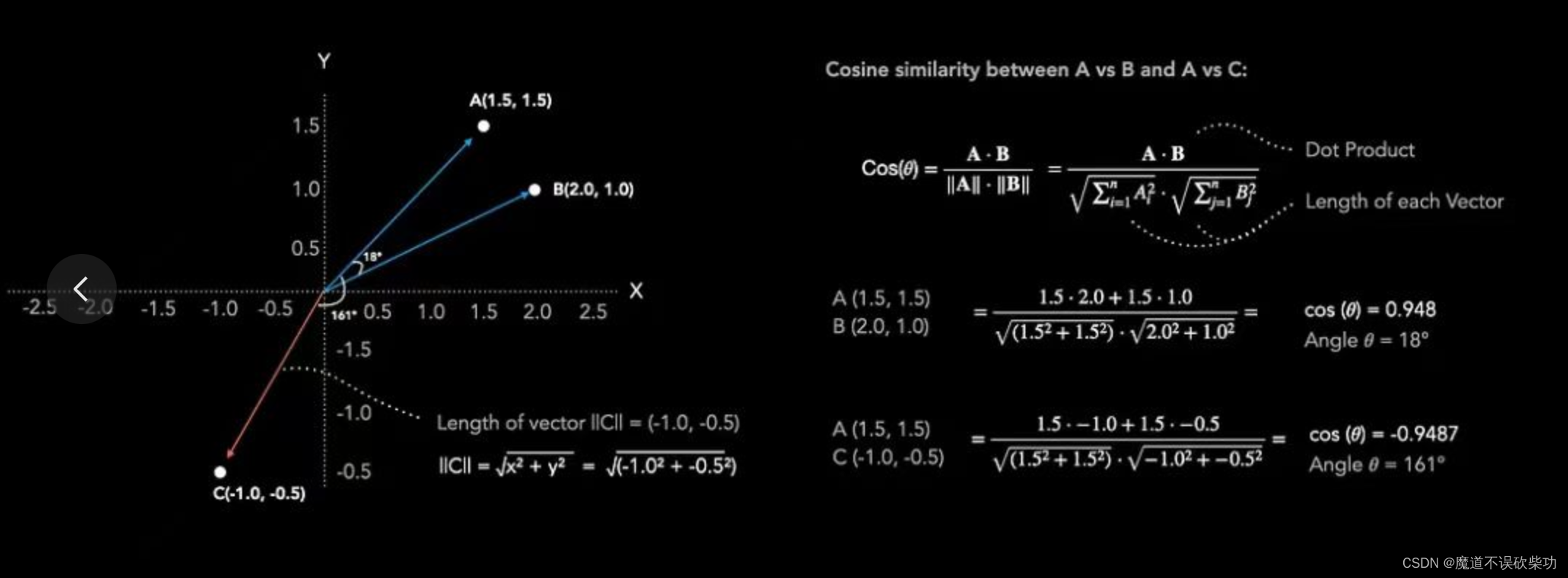
我们可以计算余弦相似度,得到A与B的余弦约为0.948,A与C的余弦约为-0.9487.。因为余弦0.948越靠近1,说明A与B文本越相似。从中文意思理解也是符合常理语义的。
5、文本向量化的应用场景
现在你可能会想,这些向量有什么用呢?原来,它们可以用于各种各样的应用:
- 推荐系统: 帮助计算机理解用户兴趣,实现个性化推荐。
- 情感分析: 通过分析文本的向量,计算机能够判断情感是正面还是负面。
- 文本相似度计算: 通过比较文本向量,找到相似的文本,用于搜索或者分类。
- 图像处理: 将图像特征表示为向量,实现图像检索等功能。
6、总结
文本向量化和余弦相似度为我们打开了处理文本数据的大门。通过这些方法,计算机能够更好地理解和利用文字信息。无论是在推荐系统、情感分析,还是在搜索引擎中,文本向量化都扮演着重要的角色。希望通过这篇博客,你对这些概念有了更清晰的认识。让我们一起迈向文本处理的新世界吧!

