
热门标签
热门文章
- 1标准DH建模与改进DH建模(三)—— 怎么用改进DH法_工业机器人dh和改进dh
- 2带T带Z的时间字符串使用LocalDateTime类转换成时间/时间戳类型_时间戳 t z
- 3命令行实现FFMpeg拉流推流方法思路_ffmpeg 推流 命令行
- 4数据安全被篡改的风险分析解决方案_信息安全 数据窜改风险监测
- 5解决 macOS 系统向日葵远程控制鼠标、键盘无法点击的问题_macos远程windows桌面键盘锁了
- 6完美收官!字节4面斩下2-2Offer,入职就是30K16薪,全凭这套“面试+架构进阶知识点
- 7python lxml用法
- 8[Linux防火墙]一文学会防火墙概念及常用命令_linux防火墙怎么设置默认区域
- 9Linux环境(Ubuntu)上搭建MQTT服务器(EMQX )_ubuntu怎么开放emqx相关端口
- 10【MATLAB源码-第139期】基于matlab的OFDM信号识别与相关参数的估计,高阶累量/小波算法调制识别,循环谱估计,带宽估计,载波数目估计等等。_ofdm循环谱
当前位置: article > 正文
Flink 流处理_flink流处理
作者:知新_RL | 2024-05-19 22:11:21
赞
踩
flink流处理
一、Flink 流处理简介
Apache Flink 是一个框架和分布式的的处理引擎 ,用于对无界和有界数据流进行计算状态计算。
二、为什么选择Flink?
数据流可更加真实反映我们的生活方式;
传统的数据架构是基于有限的数据集;
目标:低延迟,高吞吐,结果的 准确性和良好的容错性;
三、传统的数据处理架构
- 事务处理
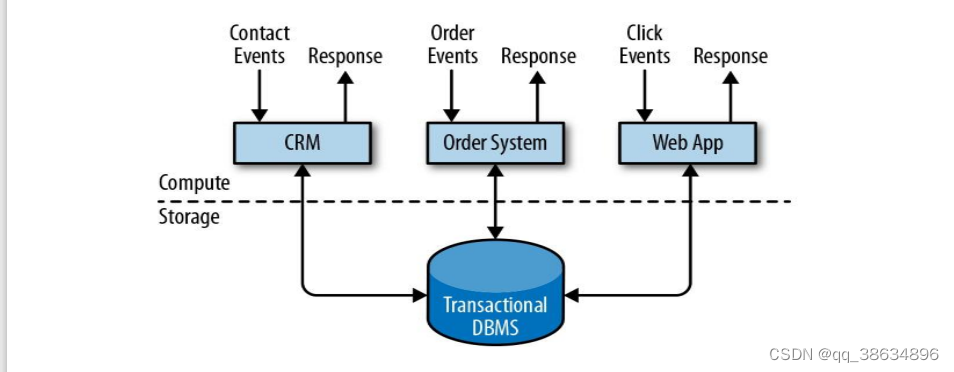
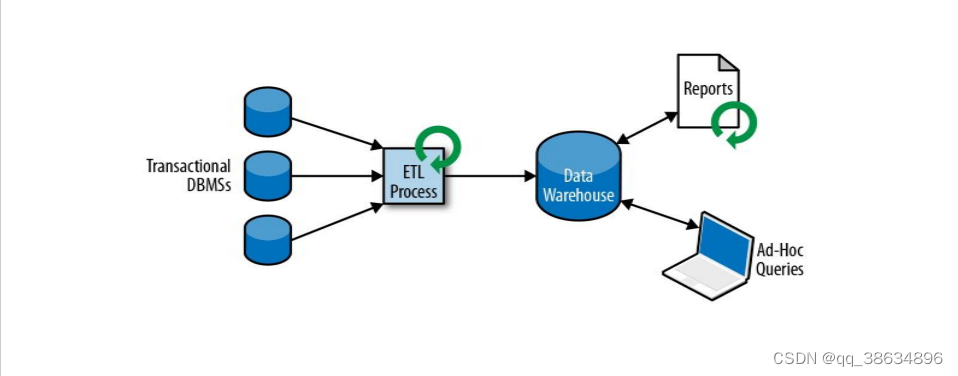
- 分析处理
- 将数据从业务数据库复制到数仓,再进行分析和查询
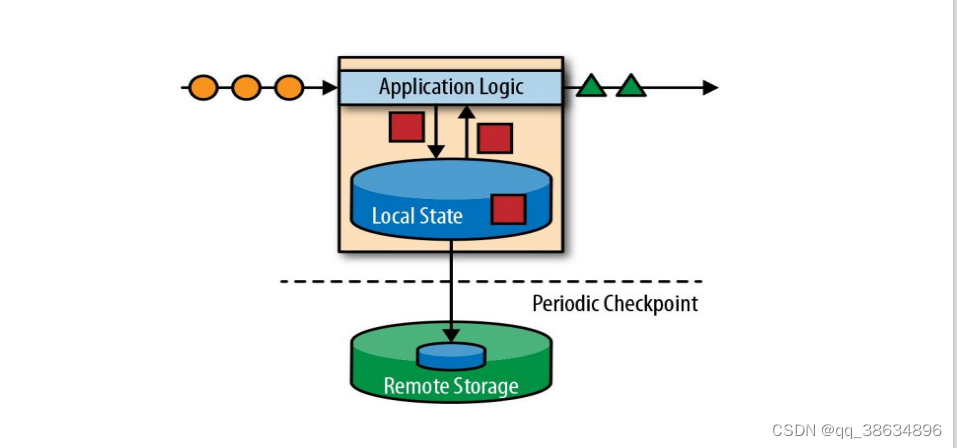
有状态的流处理
流处理的演变
• lambda 架构
用两套系统 同时保证低延迟和结果准确
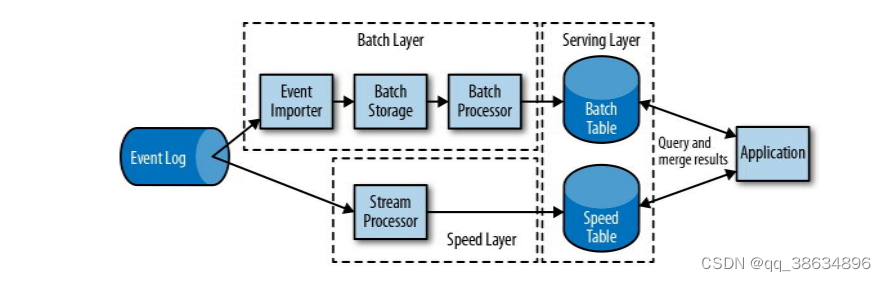
流处理的演变
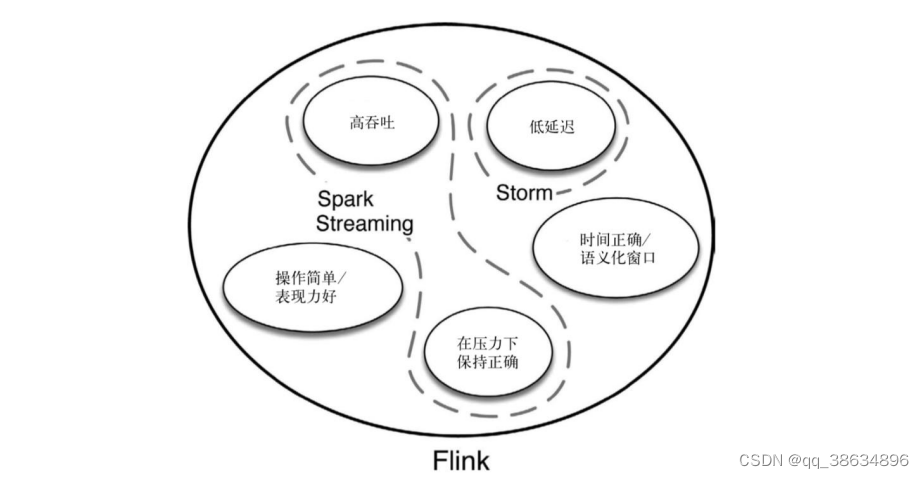
基于流的世界观
- 在Flink的世界观中,一切都是由流组成,离线数据就是有界数据流,实时的数据就是无界数据流;这就是所谓的有界和无界数据流;
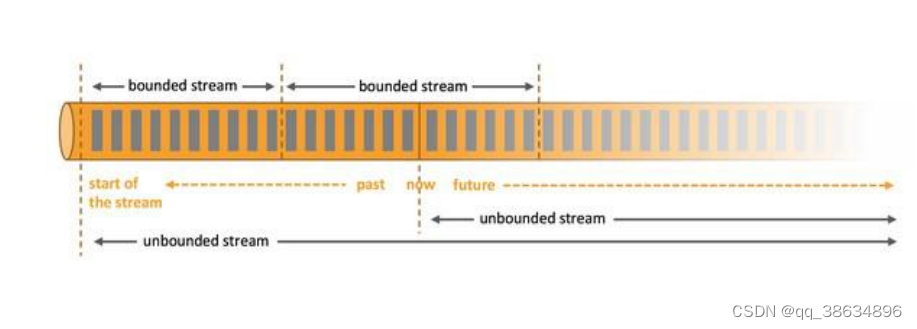
分层API
越顶层的越抽象,表达含义越简明,使用越灵活方便;
越底层的越具体,表达能力越丰富,使用越灵活;
Flink 的其他特点 - 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证;
- 低延迟,每秒处理数百万个事件,毫秒级延迟;
- 与众多存储系统相连接;
- 高可用,动态扩展,实现7 * 24小时全天候运行;
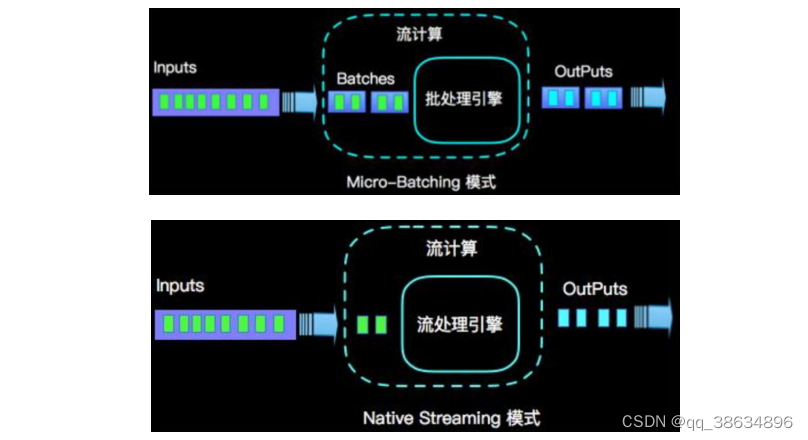
Flink vs Spark Streaming
- 流(stream)和微批(micro-batching)
- 数据模型
- spark 采用RDD模型, Spark Streaming 的 DStream 实际也是一组组小批数据RDD 的集合
- flink 基本数据模型是数据流,以及事件(Event)序列
运行时架构
- flink 是标准的流执行模式,一个事件在节点处理完成之后,可以直接发往下一个环节;
- spark 是批处理,将DAG划分为不同的statge,一个完成之后才可以计算下一个;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/594862
推荐阅读
相关标签

