
- 1Python中collections模块中的deque_from collections import deque
- 2DS18B20温度传感器学习笔记_ds18b20测量范围
- 32022科大讯飞AI开发者大赛,来了!_led生产封装瑕疵检测识别代码
- 4“AI作曲家”Suno引爆音乐圈!_suno 元标签详解
- 5eclipse 提交git失败_简单10步教你使用eclipse整合gitee码云实现共享开发
- 6关于分布式和集群的介绍_分布式集群作用
- 7【数据结构】树、二叉树与堆(长期维护)
- 8python学习-pandas基础
- 9微信小程序使用openid生成唯一数字ID(哈希算法)_微信openid生成规则
- 10系统集成项目管理工程师~关于成本的计算题_系统集成计算两种材料投入数量
大模型RAG_大模型reg
赞
踩
RAG
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。经历今年年初那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG(中文为检索增强生成) = 检索技术 + LLM 提示。例如,我们向 LLM 提问一个问题(answer),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
RAG架构
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
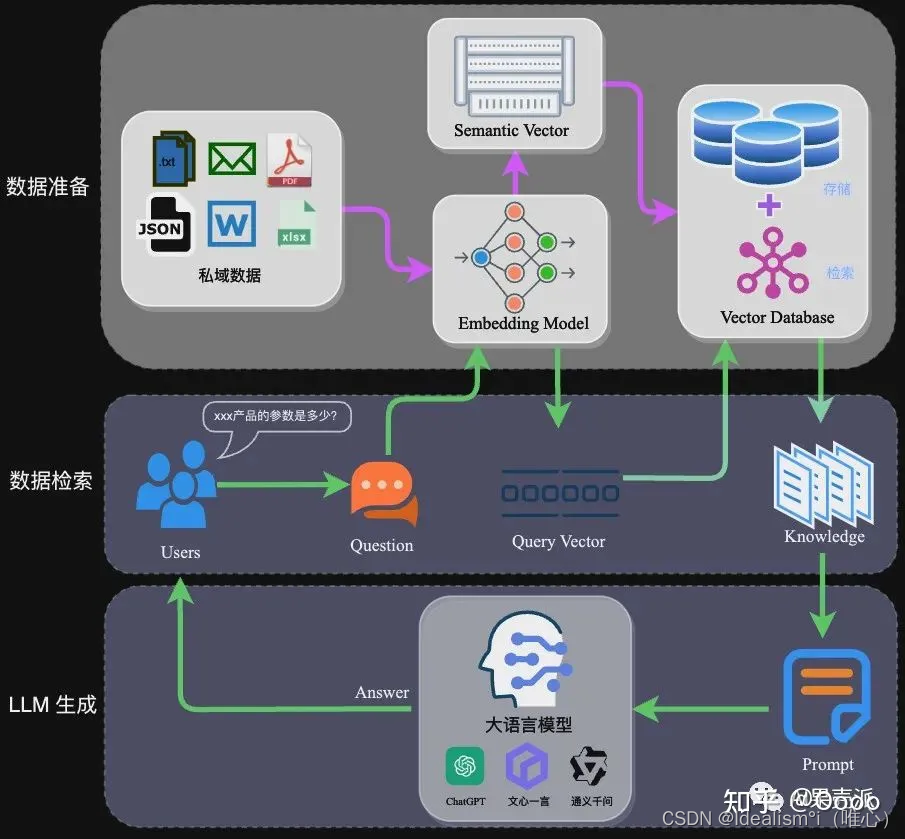
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
文本分割
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下: - 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding)
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
数据入库
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
应用阶段
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
数据检索
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
注入Prompt
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示:
原始 RAG
标准的 RAG 流程简介:将文本分块,然后使用一些 Transformer Encoder 模型将这些块嵌入到向量中,将所有向量放入索引中,最后创建一个 LLM 提示,告诉模型根据我们在搜索步骤中找到的上下文回答用户的查询。
在运行时,我们使用同一编码器模型对用户的查询进行向量化,然后搜索该查询向量的索引,找到 top-k 个结果,从我们的数据库中检索相应的文本块,并将它们作为上下文输入到 LLM 提示中。:

