
- 1推荐一款开源的RTSP服务器:rtsp-server
- 2Specified key was too long; max key length is 767 bytes解决方案_specified key was too long; max key length is 767
- 3第一个网页设计-奶茶店页面
- 4git忽略文件不生效_git忽略文件不起作用
- 5【消息队列】RocketMQ 消息的 topic 和 tag 区别以及使用方式_rocketmq topic tag
- 6AI人工智能和边缘技术结合的应用
- 7like多个值_SQL基础知识——LIKE运算符
- 8一个自定义调查问卷的数据表结构,可以自由创建调查问卷_java自定义问卷表结构
- 9stm32-DHT11原理及代码解读_stm32拉低dq是什么意思
- 10GitHub开源项目
Elastic Cloud 将 Elasticsearch 向量数据库优化配置文件添加到 Microsoft Azure
赞
踩
作者:来自 Elastic Serena Chou, Jeff Vestal, Yuvraj Gupta
今天,我们很高兴地宣布,我们的 Elastic Cloud Vector Search 优化硬件配置文件现已可供 Elastic Cloud on Microsoft Azure 用户使用。 此硬件配置文件针对使用 Elasticsearch 作为向量数据库来存储密集或稀疏嵌入的应用程序进行了优化,以用于由 RAG(检索增强生成)支持的搜索和生成 AI 用例。
向量搜索优化的硬件配置文件:你需要了解的内容
Elastic Cloud 用户受益于跨所有主要云提供商(Azure、GCP 和 AWS)的 Elastic 托管基础设施以及对 Microsoft Azure 用户的广泛区域支持。 此版本是继之前发布的针对 GCP 的向量搜索优化硬件配置文件之后发布的。 自 2023 年 11 月起,AWS 用户就可以访问向量搜索优化配置文件。有关此 Azure 硬件配置文件的实例配置的更多具体详细信息,请参阅我们的实例类型文档:azure.es.datahot.lsv3
向量搜索、HNSW 和内存
Elasticsearch 使用分层可导航小世界图 (Hierarchical Navigable Small World ,HNSW) 数据结构来实现其近似最近邻搜索 (ANN)。 由于其分层方法,HNSW 的分层方面提供了出色的查询延迟。 为了获得最佳性能,HNSW 要求将向量缓存在节点的内存中。 此缓存是自动完成的,并使用 Elasticsearch JVM 未占用的可用 RAM。 因此,内存优化是可扩展性的重要步骤。
请参阅我们的向量搜索调整指南,以确定向量搜索嵌入的正确设置以及你是否有足够的内存用于部署。
考虑到这一点,向量搜索优化的硬件配置文件配置为小于标准 Elasticsearch JVM 堆设置。 这为在节点上缓存向量提供了更多的 RAM,从而允许用户为其向量搜索用例配置更少的节点。
如果你使用标量量化等压缩技术,则内存要求会降低 4 倍。要存储量化嵌入(在 Elasticsearch 8.12 及更高版本中提供),只需确保你存储在正确的 element_type: byte 中即可。 要使用 float 向量的自动量化,请更新嵌入以使用索引类型:int8_hnsw,如以下映射示例所示。
- PUT my-byte-quantized-index
- {
- "mappings": {
- "properties": {
- "my_vector": {
- "type": "dense_vector",
- "dims": 512,
- "index_options": {
- "type": "int8_hnsw"
- }
- }
- }
- }
- }
在即将推出的版本中,Elasticsearch 将提供此作为默认映射,从而无需用户调整其映射。 为了进一步阅读,我们在本博客中提供了 Elasticsearch 中标量量化的评估。
将这种优化的硬件配置文件与 Elasticsearch 的自动量化相结合是两个例子,其中 Elastic 专注于矢量搜索,而我们的矢量数据库既具有成本效益,同时仍然具有极高的性能。
入门
在 Elastic Cloud 上开始免费试用,只需选择新的向量搜索优化配置文件即可开始。

迁移现有 Elastic Cloud 部署
只需点击几下鼠标即可迁移到这个新的向量搜索优化硬件配置文件。 只需导航到你的 Elastic Cloud 管理 UI,单击即可管理特定部署,然后编辑硬件配置文件。 在此示例中,我们将从 “Storage optimized” 配置文件迁移到新的 “Vector Search” 优化配置文件。 当选择这样做时,可用存储会略有减少,但获得的是以较低的成本通过向量搜索在每个内存中存储更多向量的能力。
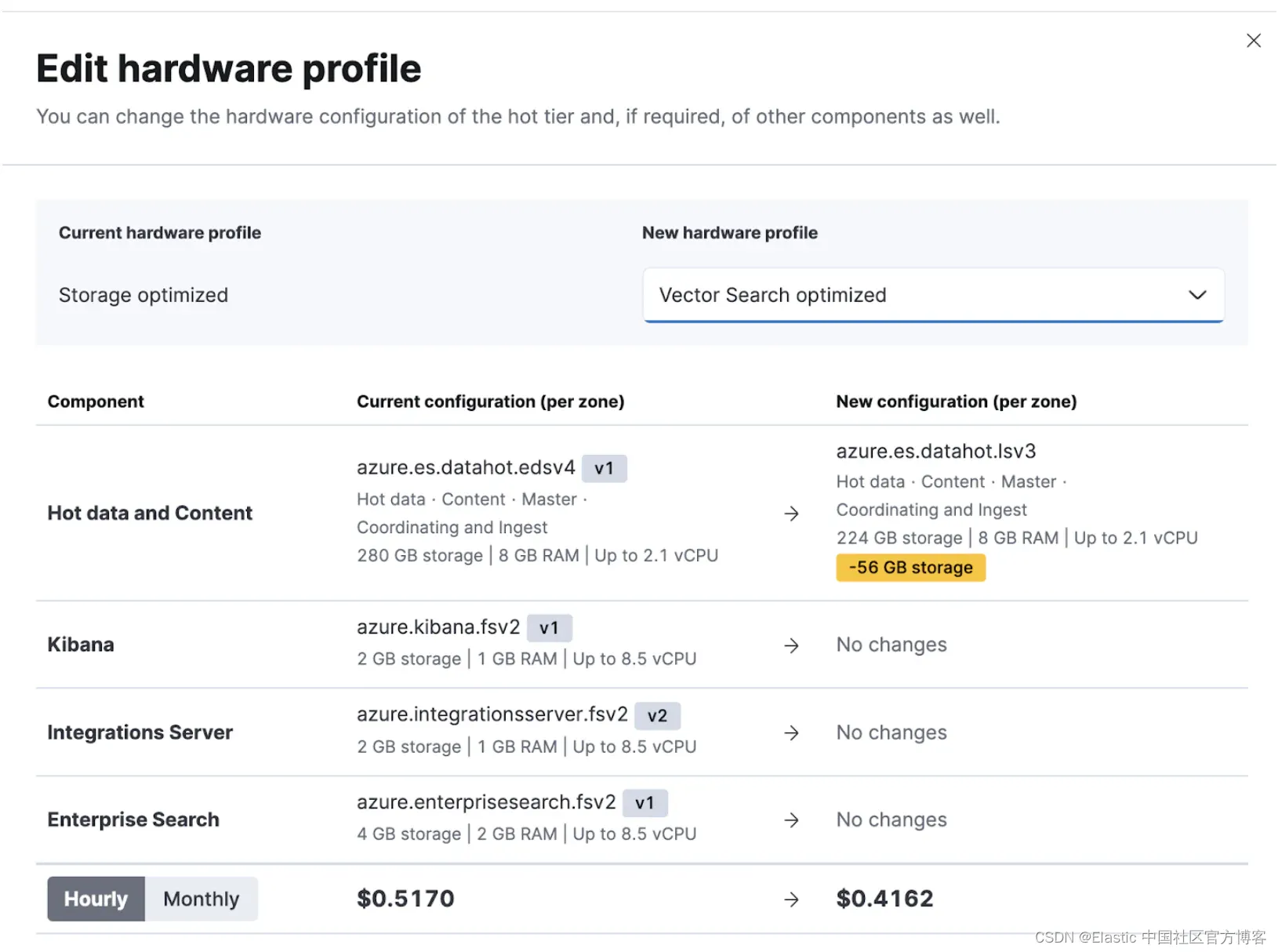
迁移到新的硬件配置文件使用增长和收缩方法来部署更改。 此方法添加新实例,将数据从旧实例迁移到新实例,然后通过删除旧实例来缩减部署。 即使对于单个可用性区域,此方法也可以在配置更改期间实现高可用性。
下图显示了在 Elastic Cloud 中运行的部署的典型架构,其中向量搜索将是主要用例。

此示例部署使用我们新的向量搜索优化硬件配置文件,现已在 Azure 中提供。 此设置包括:
- 我们的热层中的两个数据节点以及我们的向量搜索配置文件
- 1 个 Kibana 节点
- 一个机器学习节点
- 一台集成服务器
- 一个 master tiebreaker
通过使用向量搜索优化的硬件配置文件部署这两个 “全尺寸” 数据节点,同时利用 Elastic 的自动密集向量标量量化,你可以索引大约 6000 万个向量,包括一个副本(具有 768 个维度)。

