
- 1Android如何防止apk程序被反编译_apk防反编译
- 2大模型时代下的决策范式转变_大模型的统计分析和辅助决策
- 3union all和union的区别以及怎么使用_union all和union的区别用法
- 4oracle的SQL语句中的(+)是干什么用的?
- 5Qt 3D:线框 QML 示例_qml qt3d 画线
- 6SpringBoot升级3.2报错Invalid value type for attribute ‘factoryBeanObjectType‘: java.lang.String_invalid value type for attribute 'factorybeanobjec
- 7七年级上册英语第三单元单词课文翻译_answer是七年级上册第几单元学的
- 8网络编程1 - socket基本函数_socket函数pf
- 9大学生如何选择人生第一份工作
- 10安装g++,在centos上执行yum -y install gcc gcc-c++ libstdc++-devel
LLaMa系列模型详解(原理介绍、代码解读):LLaMA 2
赞
踩
LLaMA 2
大型语言模型(LLMs)作为高度能力的人工智能助手,在需要跨多个领域专家知识的复杂推理任务中表现出巨大潜力,包括编程和创意写作等专业领域。它们通过直观的聊天界面与人类互动,这导致了快速和广泛的公众采用。考虑到训练方法的看似简单性,LLMs 的能力令人瞩目。自回归变压器首先在大量自监督数据上进行预训练,然后通过强化学习与人类反馈(RLHF)等技术与人类偏好对齐。尽管训练方法简单,但高计算需求限制了 LLMs 的开发,仅由少数参与者进行。

虽然有一些预训练的 LLMs 公开发布(如 BLOOM、LLaMa-1 和 Falcon),它们在性能上可以匹敌封闭的预训练竞争对手(如 GPT-3 和 Chinchilla),但这些模型都不适合作为封闭“产品”LLMs(如 ChatGPT、BARD 和 Claude)的替代品。这些封闭的产品 LLMs 被大量微调以对齐人类偏好,这大大提高了它们的可用性和安全性。这个步骤可能需要大量的计算成本和人类注释,并且往往不透明或不易复制,限制了社区在 AI 对齐研究方面的进展。
为了推动这一领域的发展,Llama 2 系列模型被开发并发布,包括预训练和微调的 LLMs:Llama 2 和 Llama 2-Chat,参数规模高达 70B。在一系列有用性和安全性基准上,Llama 2-Chat 模型通常表现优于现有的开源模型。根据人类评估结果,这些模型似乎也与一些封闭源模型相当。Llama 2 系列模型通过安全特定的数据注释和调优,以及红队测试和迭代评估,增加了其安全性。此外,这些模型的微调方法和改进 LLM 安全性的途径也被详细描述。希望这种开放性能够使社区复制微调的 LLMs 并继续提高这些模型的安全性,为更负责任的 LLM 开发铺平道路。在开发 Llama 2 和 Llama 2-Chat 过程中,还发现了一些新奇的现象,例如工具使用的出现和知识的时间组织。
以下模型已向公众发布,用于研究和商业使用:
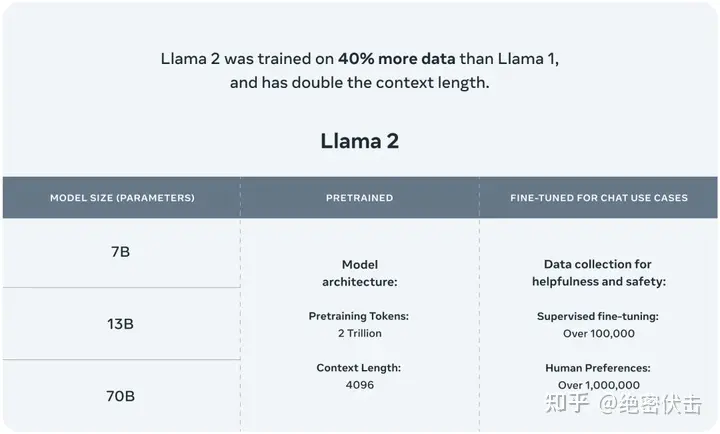
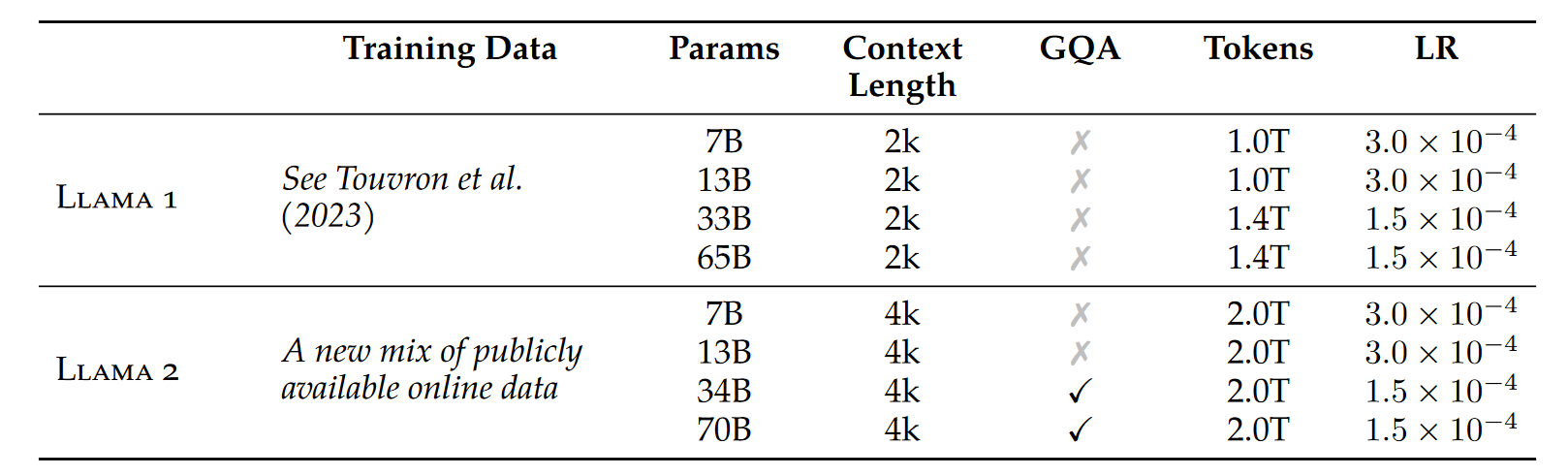
- Llama 2,Llama 1 的更新版本,训练于新的公开数据混合体上。预训练语料库的大小增加了 40%,模型的上下文长度翻倍,并采用了分组查询注意力。发布了 7B、13B 和 70B 参数的 Llama 2 变体。
- Llama 2-Chat,Llama 2 的微调版本,针对对话用例进行了优化。发布了 7B、13B 和 70B 参数的这个模型变体。
模型架构
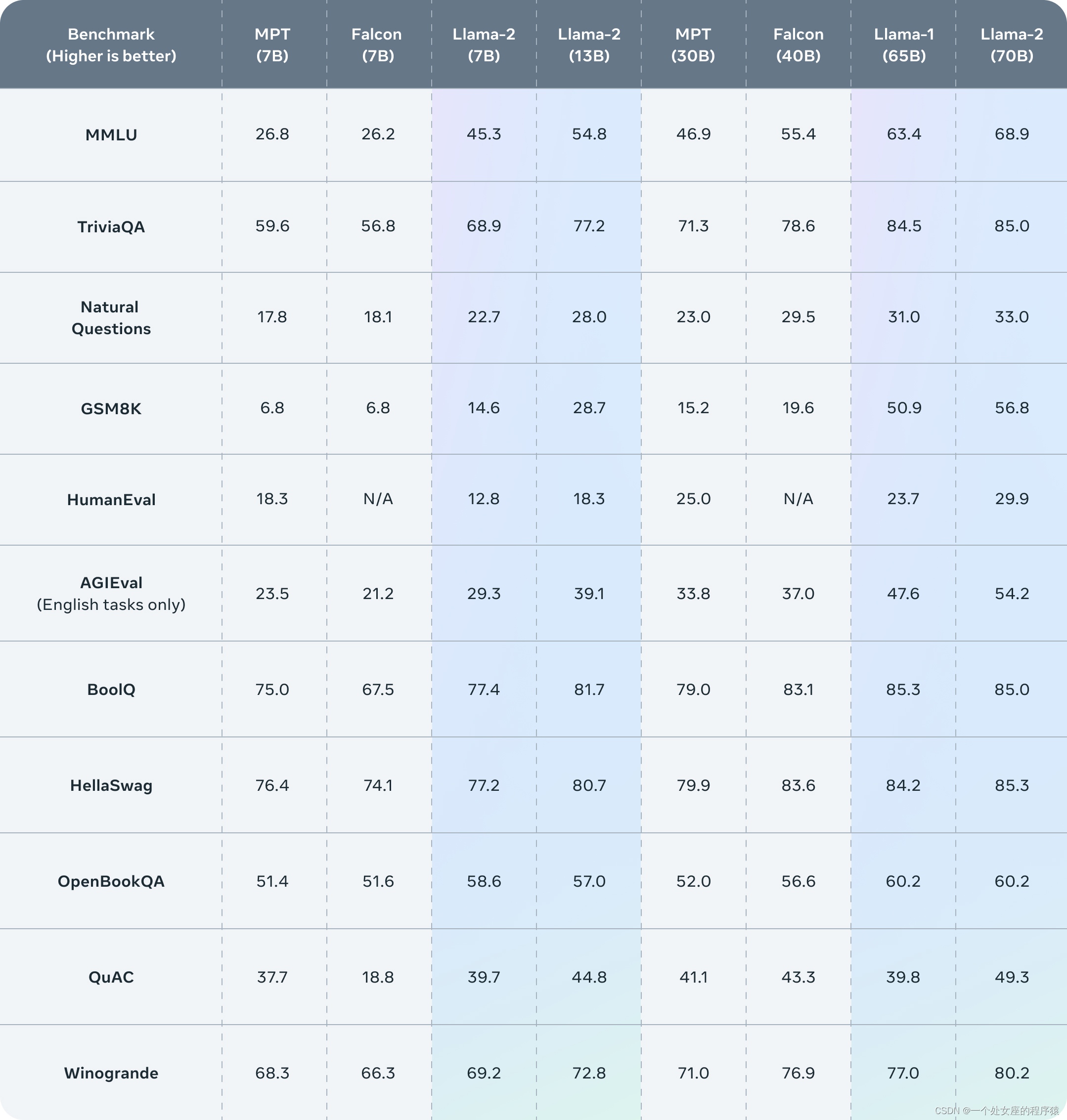
采用 Llama 1 中的大部分预训练设置和模型架构。使用标准 Transformer 架构,使用 RMSNorm 应用预归一化,使用 SwiGLU 激活函数和旋转位置嵌入。与 Llama 1的主要架构差异包括增加的上下文长度和分组查询注意力 (GQA)。
本文主要介绍LLaMA 2和LLaMA 1的区别部分,如果想具体了解LLaMA 1的模型架构和代码解读请点击此处
分组查询注意力 (GQA)
增加上下文长度比较好理解,简单的在训练前规定了最大上下文长度为4096,本文主要介绍LLaMA2中改进的注意力机制。
在理解什么是GQA之前,我们还需要知道两个概念:MHA和MQA,下图展示了MHA,MQA,GQA的区别:
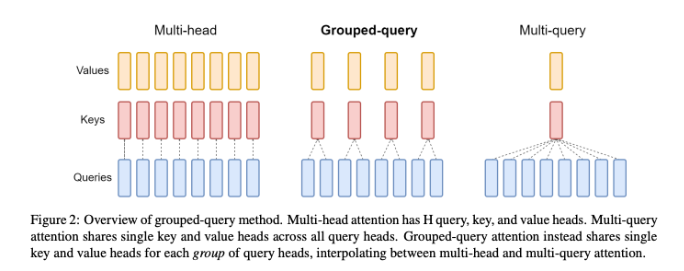
MHA
多头注意力机制MHA(Multi-Head Attention),将输入数据分成多个头(heads),每个头独立地执行注意力计算。这些头通常具有不同的权重矩阵,因此可以关注输入序列中的不同部分和特征。QKV 三部分有相同数量的头,且一一对应。每次做 Attention,head1 的 QKV 就做好自己运算就可以,输出时各个头加起来就行。
MQA
多查询注意力机制MQA(Multi-Query Attention),MQA的原理很简单,简单来说Q仍然是多头,K,V是共享的。它将原生Transformer每一层多头注意力的Key线性映射矩阵、Value线性映射矩阵改为该层下所有头共享,也就是说K、V矩阵每层只有一个。举例来说,以ChatGLM2-6B为例,一共28层,32个注意力头,输入维度从4096经过Q、K、V矩阵映射维度为128,若采用原生多头注意力机制,则Q、K、V矩阵各有28×32个,而采用MQA的方式则整个模型包含28×32个Q矩阵,28×1个K矩阵,28×1个V矩阵。这种方法在提高推理效率的同时,也能够保持模型的性能。
GQA
MQA虽然能最大程度减少KV Cache所需的缓存空间,但是可想而知参数的减少意味着精度的下降,所以为了在精度和计算之间做一个trade-off,GQA (Group Query Attention)应运而生,即Q依然是多头,但是分组共享K,V,既减少了K,V缓存所需的缓存空间,也暴露了大部分参数不至于精度损失严重。
KV Cache
大模型推理性能优化的一个常用技术是KV Cache,那么什么是KV Cache呢?
在自回归生成任务中,模型需要逐个生成序列中的tokens,每次生成一个新token时,都会更新输入序列并重新计算自注意力。然而,已生成的部分(历史tokens)对应的Key和Value向量在生成后续token时往往保持不变或变化较小。KV Cache正是利用了这一性质,通过将这些历史tokens对应的Key和Value向量存储起来(缓存),在后续计算中直接复用,而不是每次都重新计算。
代码详解
RMSNorm(均方根归一化)
代码实现的是对输入张量 x 进行RMS归一化,将每个元素除以其均方根(RMS),并确保计算过程的数值稳定性。
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
"""
初始化 RMSNorm 归一化层。
参数:
dim (int): 输入张量的维度。
eps (float, 可选): 添加到分母的小值,以确保数值稳定性。默认值为 1e-6。
属性:
eps (float): 添加到分母的小值,以确保数值稳定性。
weight (nn.Parameter): 可学习的缩放参数。
"""
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
"""
对输入张量应用 RMSNorm 归一化。
参数:
x (torch.Tensor): 输入张量。
返回:
torch.Tensor: 归一化后的张量。
"""
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
"""
通过 RMSNorm 层的前向传递。
参数:
x (torch.Tensor): 输入张量。
返回:
torch.Tensor: 应用 RMSNorm 后的输出张量。
""" output = self._norm(x.float()).type_as(x)
return output * self.weight
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
旋转位置嵌入
为了便于理解,给出RoPE的具体实现步骤:
-
频率向量的计算:
f i = 1 θ 2 i d f_i = \frac{1}{\theta^{\frac{2i}{d}}} fi=θd2i1
其中 θ \theta θ是一个常数(通常取 10000), i i i是向量维度的索引。 -
旋转角度的计算:
angle ( t ) = t ⋅ f i \text{angle}(t) = t \cdot f_i angle(t)=t⋅fi
其中 t t t是位置索引。 -
应用旋转变换:
对每个位置 t t t的输入向量 x t x_t xt,在复数域进行旋转变换:
x t ′ = x t ⋅ e j ⋅ angle ( t ) x_t' = x_t \cdot e^{j \cdot \text{angle}(t)} xt′=xt⋅ej⋅angle(t)
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
"""
预计算复数指数的频率张量(cis),具有给定的维度。
此函数使用给定的维度 'dim' 和结束索引 'end' 计算一个复数指数的频率张量。'theta' 参数用于缩放频率。
返回的张量包含复数值,数据类型为 complex64。
参数:
dim (int): 频率张量的维度。
end (int): 用于预计算频率的结束索引。
theta (float, 可选): 用于频率计算的缩放因子。默认为 10000.0。
返回:
torch.Tensor: 预计算的复数指数频率张量。
"""
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # 类型忽略
freqs = torch.outer(t, freqs).float() # 类型忽略
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
代码相当于预先了计算了angle[t]列表,将每个位置的旋转矩阵保存下来,减少训练中的计算。
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
"""
重塑频率张量以便与另一个张量进行广播。
此函数将频率张量重塑为与目标张量 'x' 具有相同的形状,以便在进行逐元素操作时进行广播。
参数:
freqs_cis (torch.Tensor): 需要重塑的频率张量。
x (torch.Tensor): 目标张量,用于广播兼容性。
返回:
torch.Tensor: 重塑后的频率张量。
抛出:
AssertionError: 如果频率张量的形状不符合预期。
AssertionError: 如果目标张量 'x' 没有预期的维数。
""" ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
假设
freqs_cis的形状为(L, D),其中L是序列长度,D是特征维度。x的形状为(B, L, H, D),其中B是批量大小,L是序列长度,H是头数,D是每个头的特征维度。
结果- 将频率张量
freqs_cis重塑为[1, L, 1, D],这个形状可以和x进行广播。
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
使用给定的频率张量对输入张量应用旋转嵌入。
此函数使用提供的频率张量 'freqs_cis' 对给定的查询 'xq' 和键 'xk' 张量应用旋转嵌入。
输入张量被重塑为复数,并重塑频率张量以进行广播兼容性。返回的张量包含旋转嵌入,并以实数形式返回。
参数:
xq (torch.Tensor): 应用旋转嵌入的查询张量。
xk (torch.Tensor): 应用旋转嵌入的键张量。
freqs_cis (torch.Tensor): 预计算的复数指数频率张量。
返回:
Tuple[torch.Tensor, torch.Tensor]: 包含旋转嵌入的查询张量和键张量的元组。
""" xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
函数实现了在Attention中使用旋转位置嵌入,与一般位置嵌入不同,旋转位置嵌入在计算完QK后进行,直接在QK上增加旋转位置信息。
应用KV-Cache和GQA的注意力机制
class Attention(nn.Module):
"""多头注意力模块。"""
def __init__(self, args: ModelArgs):
"""
初始化 Attention 模块。
参数:
args (ModelArgs): 模型配置参数。
属性:
n_kv_heads (int): 键和值的头数。
n_local_heads (int): 本地查询头数。
n_local_kv_heads (int): 本地键和值头数。
n_rep (int): 本地头的重复次数。
head_dim (int): 每个注意力头的维度大小。
wq (ColumnParallelLinear): 查询的线性变换。
wk (ColumnParallelLinear): 键的线性变换。
wv (ColumnParallelLinear): 值的线性变换。
wo (RowParallelLinear): 输出的线性变换。
cache_k (torch.Tensor): 注意力的缓存键。
cache_v (torch.Tensor): 注意力的缓存值。
""" super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
Attention 模块的前向传递。
参数:
x (torch.Tensor): 输入张量。
start_pos (int): 缓存的起始位置。
freqs_cis (torch.Tensor): 预计算的频率张量。
mask (torch.Tensor, 可选): 注意力掩码张量。
返回:
torch.Tensor: 注意力后的输出张量。
""" bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# 如果 n_kv_heads < n_heads,则重复 k/v heads keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
KV缓存机制
代码定义了KV缓存机制:
self.cache_k = torch.zeros( ( args.max_batch_size, args.max_seq_len, self.n_local_kv_heads, self.head_dim, ) ).cuda() self.cache_v = torch.zeros( ( args.max_batch_size, args.max_seq_len, self.n_local_kv_heads, self.head_dim, ) ).cuda()
- 1
具体实现是,每次计算完KV后,将本次计算结果加入cache_k和cache_v后:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
- 1
- 2
GQA的实现
初始化头的分割
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
- 1
- 2
- 3
n_local_heads是Q的头数,n_local_kv_heads是KV的头数,n_rep是为每个KV头的重复次数。
变换和重塑
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
- 1
- 2
- 3
重塑为对应的形状
键和值的重复使用
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里,键和值被重复以匹配查询的数量,确保每组中的查询都有相应的键和值可用。
keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
- 1
- 2
注意力分数计算与应用
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
- 1
整体实现
上面解释了LLaMA系列对Transformer的改进,下面给出全部的LLaMA模型实现:
注:LLaMA系列统一对输入进行归一化,而不是对输出进行归一化。
# 版权所有 (c) Meta Platforms, Inc. 及其子公司。
# 本软件可以根据 Llama 2 社区许可协议的条款使用和分发。
import math
from dataclasses import dataclass
from typing import Optional, Tuple
import fairscale.nn.model_parallel.initialize as fs_init
import torch
import torch.nn.functional as F
from fairscale.nn.model_parallel.layers import (
ColumnParallelLinear,
ParallelEmbedding,
RowParallelLinear,
)
from torch import nn
@dataclass
class ModelArgs:
dim: int = 4096
n_layers: int = 32
n_heads: int = 32
n_kv_heads: Optional[int] = None
vocab_size: int = -1 # 稍后由 tokenizer 定义
multiple_of: int = 256 # 使 SwiGLU 隐藏层大小成为大的2的幂的倍数
ffn_dim_multiplier: Optional[float] = None
norm_eps: float = 1e-5
max_batch_size: int = 32
max_seq_len: int = 2048
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
"""
初始化 RMSNorm 归一化层。
参数:
dim (int): 输入张量的维度。
eps (float, 可选): 添加到分母的小值,以确保数值稳定性。默认值为 1e-6。
属性:
eps (float): 添加到分母的小值,以确保数值稳定性。
weight (nn.Parameter): 可学习的缩放参数。
""" super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
"""
对输入张量应用 RMSNorm 归一化。
参数:
x (torch.Tensor): 输入张量。
返回:
torch.Tensor: 归一化后的张量。
""" return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
"""
通过 RMSNorm 层的前向传递。
参数:
x (torch.Tensor): 输入张量。
返回:
torch.Tensor: 应用 RMSNorm 后的输出张量。
""" output = self._norm(x.float()).type_as(x)
return output * self.weight
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
"""
预计算复数指数的频率张量(cis),具有给定的维度。
此函数使用给定的维度 'dim' 和结束索引 'end' 计算一个复数指数的频率张量。'theta' 参数用于缩放频率。
返回的张量包含复数值,数据类型为 complex64。
参数:
dim (int): 频率张量的维度。
end (int): 用于预计算频率的结束索引。
theta (float, 可选): 用于频率计算的缩放因子。默认为 10000.0。
返回:
torch.Tensor: 预计算的复数指数频率张量。
""" freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # 类型忽略
freqs = torch.outer(t, freqs).float() # 类型忽略
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
"""
重塑频率张量以便与另一个张量进行广播。
此函数将频率张量重塑为与目标张量 'x' 具有相同的形状,以便在进行逐元素操作时进行广播。
参数:
freqs_cis (torch.Tensor): 需要重塑的频率张量。
x (torch.Tensor): 目标张量,用于广播兼容性。
返回:
torch.Tensor: 重塑后的频率张量。
抛出:
AssertionError: 如果频率张量的形状不符合预期。
AssertionError: 如果目标张量 'x' 没有预期的维数。
""" ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
使用给定的频率张量对输入张量应用旋转嵌入。
此函数使用提供的频率张量 'freqs_cis' 对给定的查询 'xq' 和键 'xk' 张量应用旋转嵌入。
输入张量被重塑为复数,并重塑频率张量以进行广播兼容性。返回的张量包含旋转嵌入,并以实数形式返回。
参数:
xq (torch.Tensor): 应用旋转嵌入的查询张量。
xk (torch.Tensor): 应用旋转嵌入的键张量。
freqs_cis (torch.Tensor): 预计算的复数指数频率张量。
返回:
Tuple[torch.Tensor, torch.Tensor]: 包含旋转嵌入的查询张量和键张量的元组。
""" xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
class Attention(nn.Module):
"""多头注意力模块。"""
def __init__(self, args: ModelArgs):
"""
初始化 Attention 模块。
参数:
args (ModelArgs): 模型配置参数。
属性:
n_kv_heads (int): 键和值的头数。
n_local_heads (int): 本地查询头数。
n_local_kv_heads (int): 本地键和值头数。
n_rep (int): 本地头的重复次数。
head_dim (int): 每个注意力头的维度大小。
wq (ColumnParallelLinear): 查询的线性变换。
wk (ColumnParallelLinear): 键的线性变换。
wv (ColumnParallelLinear): 值的线性变换。
wo (RowParallelLinear): 输出的线性变换。
cache_k (torch.Tensor): 注意力的缓存键。
cache_v (torch.Tensor): 注意力的缓存值。
""" super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
Attention 模块的前向传递。
参数:
x (torch.Tensor): 输入张量。
start_pos (int): 缓存的起始位置。
freqs_cis (torch.Tensor): 预计算的频率张量。
mask (torch.Tensor, 可选): 注意力掩码张量。
返回:
torch.Tensor: 注意力后的输出张量。
""" bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# 如果 n_kv_heads < n_heads,则重复 k/v heads keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
"""
初始化 FeedForward 模块。
参数:
dim (int): 输入维度。
hidden_dim (int): 前馈层的隐藏维度。
multiple_of (int): 确保隐藏维度是该值的倍数。
ffn_dim_multiplier (float, 可选): 隐藏维度的自定义乘数。默认为 None。
属性:
w1 (ColumnParallelLinear): 第一层的线性变换。
w2 (RowParallelLinear): 第二层的线性变换。
w3 (ColumnParallelLinear): 第三层的线性变换。
""" super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# 自定义维度因子乘数
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
"""
初始化一个 TransformerBlock。
参数:
layer_id (int): 层的标识符。
args (ModelArgs): 模型配置参数。
属性:
n_heads (int): 注意力头数。
dim (int): 模型的维度大小。
head_dim (int): 每个注意力头的维度大小。
attention (Attention): 注意力模块。
feed_forward (FeedForward): 前馈模块。
layer_id (int): 层的标识符。
attention_norm (RMSNorm): 注意力输出的层归一化。
ffn_norm (RMSNorm): 前馈输出的层归一化。
""" super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim,
hidden_dim=4 * args.dim,
multiple_of=args.multiple_of,
ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
通过 TransformerBlock 的前向传递。
参数:
x (torch.Tensor): 输入张量。
start_pos (int): 注意力缓存的起始位置。
freqs_cis (torch.Tensor): 预计算的余弦和正弦频率。
mask (torch.Tensor, 可选): 注意力的掩码张量。默认值为 None。
返回:
torch.Tensor: 应用注意力和前馈层后的输出张量。
""" h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
"""
初始化一个 Transformer 模型。
参数:
params (ModelArgs): 模型配置参数。
属性:
params (ModelArgs): 模型配置参数。
vocab_size (int): 词汇表大小。
n_layers (int): 模型的层数。
tok_embeddings (ParallelEmbedding): 词嵌入。
layers (torch.nn.ModuleList): Transformer 块的列表。
norm (RMSNorm): 模型输出的层归一化。
output (ColumnParallelLinear): 最终输出的线性层。
freqs_cis (torch.Tensor): 预计算的余弦和正弦频率。
""" super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
"""
通过 Transformer 模型的前向传递。
参数:
tokens (torch.Tensor): 输入的标记索引。
start_pos (int): 注意力缓存的起始位置。
返回:
torch.Tensor: 应用 Transformer 模型后的输出 logits。
""" _bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full(
(1, 1, seqlen, seqlen), float("-inf"), device=tokens.device
)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453

