
- 1Android Studio 期末大作业超市记账管理app_android studio期末项目
- 2什么是RabbitMQ、与RocketMQ什么区别(面试官视角版)_rabbitmq与rocketmq 面试
- 3阿里AI补充代码免费使用!通义灵码pycharm使用教程_pycharm 通义灵码
- 4笔记---mongodb && mongoid
- 5C/C++log日志库比较_c 日志库
- 6MySQL数据库source命令导入sql文件_source导入sql文件
- 7详细安装和彻底删除RabbitMQ图文流程_windows卸载rabbitmq_rabbitmq卸载
- 8Flink CDC详解_flinkcdc
- 9python网络编程:通过socket实现TCP客户端和服务端_python socket客户端
- 10我用 Go 开发了一个简易版 shell_go 开发一款shell工具
导出LLaMA ChatGlm2等LLM模型为onnx_chatglm转onnx
赞
踩
通过onnx模型可以在支持onnx推理的推理引擎上进行推理,从而可以将LLM部署在更加广泛的平台上面。此外还可以具有避免pytorch依赖,获得更好的性能等优势。
这篇博客(大模型LLaMa及周边项目(二) - 知乎)进行了llama导出onnx的开创性的工作,但是依赖于侵入式修改transformers库,比较不方便。
这里本人实现了避免侵入式修改transformers库导出LLM为ONNX方法,代码库为:
https://github.com/luchangli03/export_llama_to_onnx
导出的LLM进行onnxsim优化:
一种大于2GB ONNX模型onnxsim优化方法_Luchang-Li的博客-CSDN博客
https://github.com/luchangli03/onnxsim_large_model
可以在这个基础上进行简单修改从而导出其他模型,例如百川,Qwen等模型。当前已经加入了对llama, 清华ChatGlm2和阿里Qwen的导出支持。百川跟llamma相似性很高,可以直接用llama的导出脚本。
除了导出onnx,目前还增加了一个基于onnx推理chatglm2的demo。
该方案优点是无需侵入式修改transformers代码,缺点是你需要提前了解各个模型的输入,相关shape和dtype。这可以在代码里面增加shape,dtype打印,进行一次推理获取。
阿里的Qwen模型导出onnx存在大量琐碎的算子,主要是因为其使用了einops库的rearrange操作。把这些算子替换为reshape,transpose, split等操作后onnx模型会极大简化。此外,还可以进一步优化该模型的RotaryEmbedding相关的代码以优化导出的onnx模型复杂度。
例如
- # context_layer = rearrange(
- # context_layer, "b s h d -> b s (h d)"
- # ).contiguous()
- b, s, h, d = context_layer.shape
- context_layer = context_layer.reshape([b, s, -1])
- # self._rotary_pos_emb_cache = rearrange(emb, "n d -> 1 n 1 d")
- emb = torch.unsqueeze(emb, 0) # [1nd]
- emb = torch.unsqueeze(emb, 2)
- def _rotate_half(x):
- # from einops import rearrange
- # x = rearrange(x, "... (j d) -> ... j d", j=2)
- # x1, x2 = x.unbind(dim=-2)
- last_dim = x.shape[-1]
- x1, x2 = torch.split(x, last_dim//2, dim=-1)
- return torch.cat((-x2, x1), dim=-1)
导出的llama decoder会存在if算子,但是经过符号shape推导和设置相应的符号shape到onnx模型value_info,然后经过onnxsim可以完全去掉。也可以考虑修改llama定义代码去掉if。优化前后:
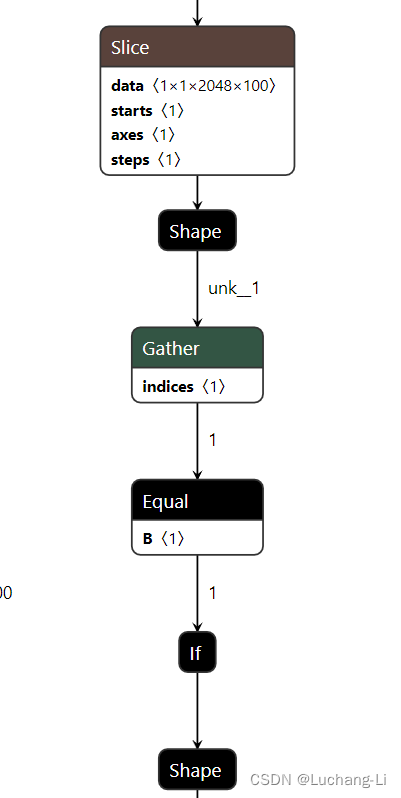
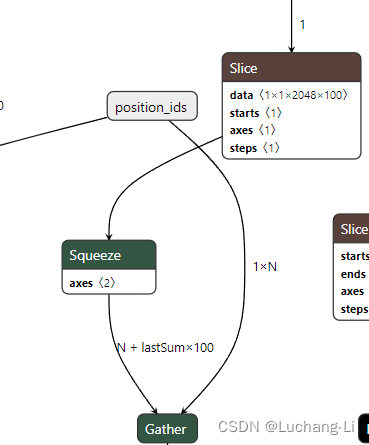
导出模型调试
从导出模型中算子的名称可以大概推断出该算子在那个模块定义的。
如/layers.0/attn/rotary_emb/Slice可以知道该算子定义于第0个decoder层的atten.rotary_emb模块,而slice一般来自于张量切片索引操作。

