
- 1新手neo4j安装艰辛历程+经验_neo4j卸载
- 29月最新Jmeter面试题_jmeter接口压测常见面试题,软件测试高级工程师必备知识_jmeter常用面试题
- 3基于GA遗传优化的CNN-GRU的时间序列回归预测matlab仿真
- 4金三银四面试必看,复盘字节测试开发面试:一次测试负责人岗位面试总结_测试部门负责人面试
- 5python:pymysql的基本使用_pymysql cursorclass
- 6python和pycharm-python与pycharm有何区别
- 7毕设项目分享 基于tensorflow的nlp深度学习项目_tensorflow 毕设
- 8数据库迁移要怎么做?有哪些好用的迁移工具?
- 9Java中的JSON神器,如何轻松玩转复杂数据结构
- 10【工业互联网】漫谈“工业互联网”与“智能制造”_工业互联网与智能制造的区别
docker gpu 创建 训练环境_基于虚拟化的模型训练平台实践
赞
踩
写在前面
近几年,人工智能快速发展,与各行各业的结合也成为业界不断探索的方向。在金融科技领域,风控逐步从传统风控转向大数据风控以及智能风控,主要通过人工智能核心技术(知识图谱、机器学习、深度学习)作为主要驱动力,为金融业的各参与主体、各业务环节进行赋能,突出人工智能技术对于金融业的产品创新、流程再造、服务升级的重要作用。
金融业凭借海量数据和多维度应用场景给金融风控发展应用提供了优良的“土壤”, 海量的训练数据可以提高模型的上限。然而数据规模的增大给训练也带来了挑战。硬件的发展带来了性能的提高,但在特定时间内,单机系统总是有性能上限。海量数据场景可能导致单机无法加载或是训练模型时间过长。机器学习不仅需要数据科学家研发新模型,软件工程师应用新模型,还需要软件工程师来建设模型训练平台。在应用机器学习的企业和团队中,建设模型训练平台是重要的一环。目前业界的主流解决方案是使用异构计算资源加速并采用分布式训练解决海量数据带来的训练难问题。
本文将为大家分享在建设模型训练平台过程中的一些经验和探索,希望对大家能有所帮助或者启发。
1. 为什么要做模型训练平台?
模型实验阶段对平台支持有较多要求。好的工具能够提高生产力,帮助大家脱离繁琐的工程化开发,减少人为错误,把有限的精力聚焦于业务算法模型的迭代上,同时还能充分利用资源,让算力尽可能产生价值。

公司内部计算资源有限

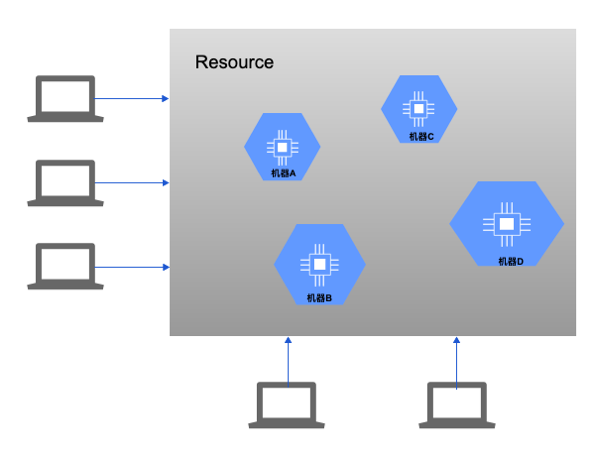
想要在一个企业环境中运行大规模的ML和DL应用程序不是一件简单的事情,ML和DL预测模型的训练和推理是密集型的计算。使用硬件加速器(如GPU)是提供所需计算能力的关键。在传统企业环境中,用户如果需要使用公共资源来训练模型,就需要独占整个机器(CPU, GPU, Memory),。如果有新有用户训练新的模型,可以又需要占用另一台机器。企业内部虽然说可以采购扩充新的机器资源,但是在一段时间内,资源总量不会有太大变化,这个导致可能有些用户没有资源去训练模型,还有就是已经分配给用户的资源并不会被充分利用,但是难以发现。在运行单个负载任务时,ML、DL应用程序对GPU的利用率会发生显著变化。这意味着即使GPU共享,它们也不会被充分利用。
业界深度学习框架与业务模型种类多样

