
李宏毅 自然语言处理(Speech Recognition) 笔记_self-organized language modeling for speech recogn
赞
踩
李宏毅NLP(自然语言处理)完整课程,强推!_哔哩哔哩_bilibili
从Ng那里跑路来学NLP了,之前其实ML入门听的就是宝可梦捕获大师(×)的课,目前计划是,本博文作为上面链接所示课程的笔记记录。听完之后会找个项目练一练,然后去听一些更新的技术的介绍,再找个项目练一练。
引入
本课程语音文字部分half half,老师提到这样安排是因为很多语言是没有文字的,或者这些语言的文字并不被所有使用这些语言的人使用,或者没有统一的文字系统等等,因此不同于其他课程,他将囊括更多的语音的部分。
语音
 简单来说就是一秒钟的语音需要用16k个数字来表示。因此,同样一句话,及时同一个人来说,所得到的声音信号也不可能是相同的,老师在这里举例放了他说四次你好的声音信号图,确实不一样(看图的话,一方面语速、说话的时机、停顿显然会有影响,同时应该我们也不太能非常精准的控制每个字的频率啊时长啊音调啊之类的)
简单来说就是一秒钟的语音需要用16k个数字来表示。因此,同样一句话,及时同一个人来说,所得到的声音信号也不可能是相同的,老师在这里举例放了他说四次你好的声音信号图,确实不一样(看图的话,一方面语速、说话的时机、停顿显然会有影响,同时应该我们也不太能非常精准的控制每个字的频率啊时长啊音调啊之类的)
文字

同时文字的长度也可以达到很长,可以无限套娃来延长最长的句子。
->人类的语言是十分复杂的
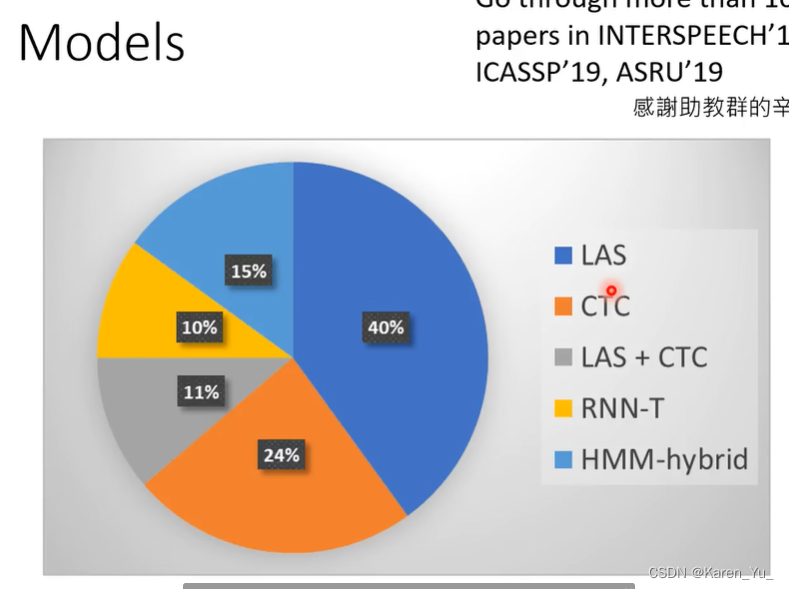
本课程主要涉及的模型:
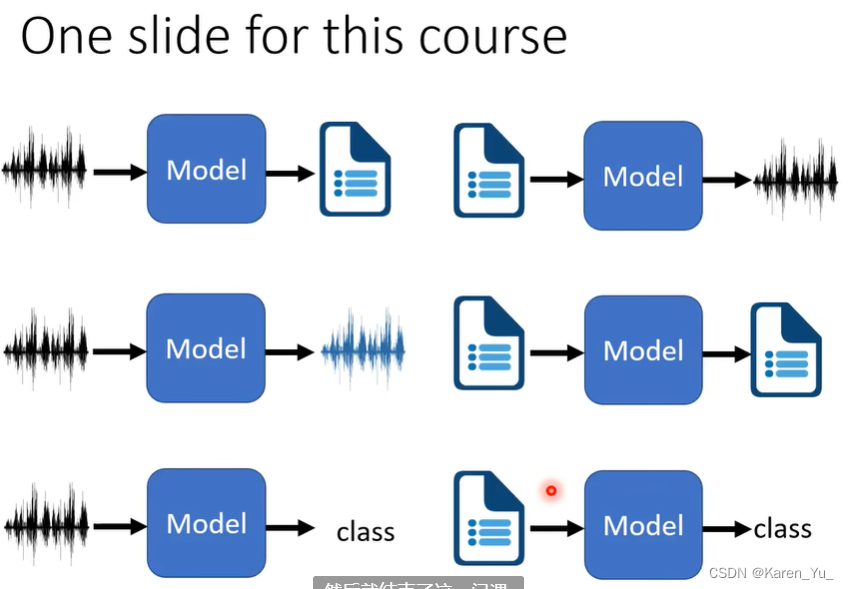
这些模型从左到右从上到下(按[ [1, 2], [3, 4], [5, 6] ])分别为:speech recognition,Text-to-Speech Sythesis,(Speech Separation, voice conversion),输入文字输出文字,很多,看柯南下面那张图中的举例,(Speaker Recognition, keyword Spotting)




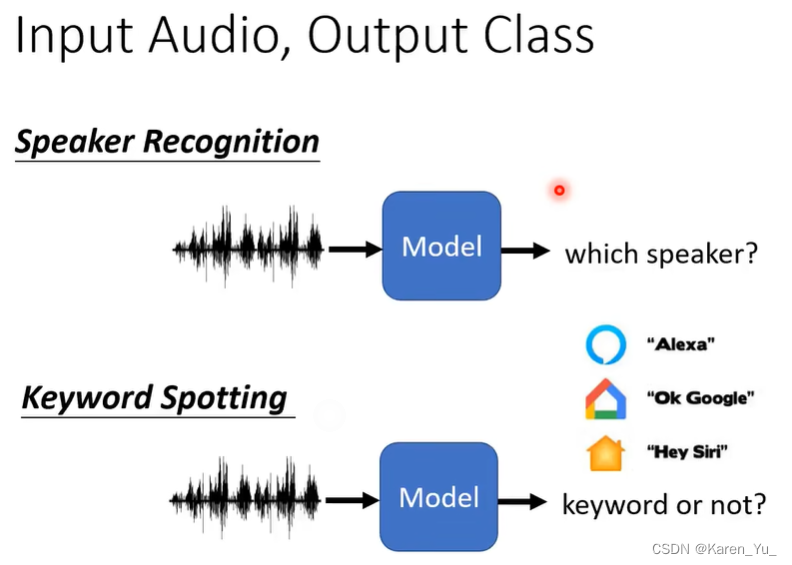
这里提到唤醒词我多句嘴,之前在一门课上做过一个类似的项目,用的arduino,但是当时恰巧google colab不再支持TensorFlow 1.13 还是1.16之前的版本了,而TinyML这本书刚好提供的是这一版本的方法,很迷惑,我们试着把代码改改,但是发现可能是原始的代码本身就有问题,或者是后续的TensorFlow版本不再支持这种打包方式(因为是刚刚不支持几个月之后,完全查不到类似的问题),也可能是arduino不能识别TensorFlow 后续版本的训练结果,总之完全不work,问了老师和助教也没有得到解决方案,最后跑了demo感受了一下唤醒词,似乎对低频信号更敏感(声音比较低沉的男生一般更有可能被识别,我无论怎么说,识别的准确率也只有40%左右,估计实际生产中也不会使用这样的方法,或者有更丰富的语料库,更多的计算资源吧),总之确实主打图一乐。

Meta learning,先在其他很多的任务上进行学习,归纳出更好的学习方法,成为更好的学习者,也许可以用更少的资料在更短的时间内学会新的技术。

Speech Recognition seq2seq模型
引入
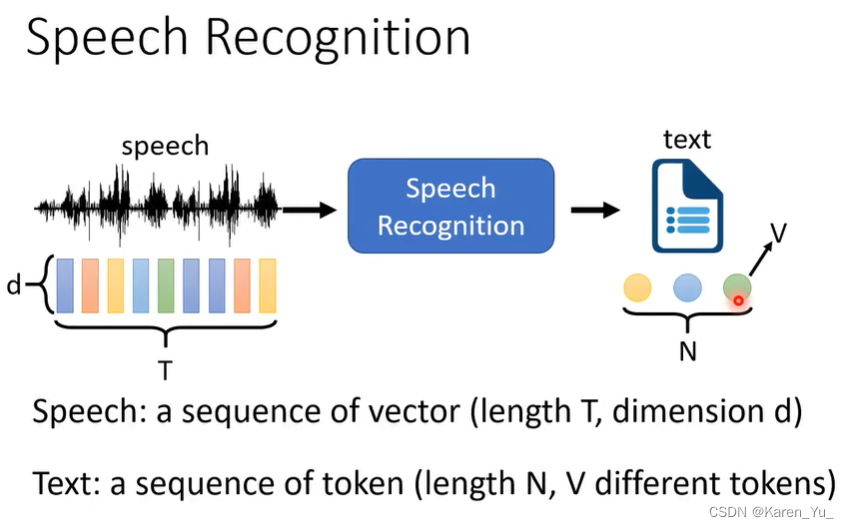
输入的声音被表示成一串向量,其中向量的长度用T表示,向量的维度用d表示。
文字是一个token的序列,长度为N,一共有V种不同的token。
一般而言T>N(输入比输出长)
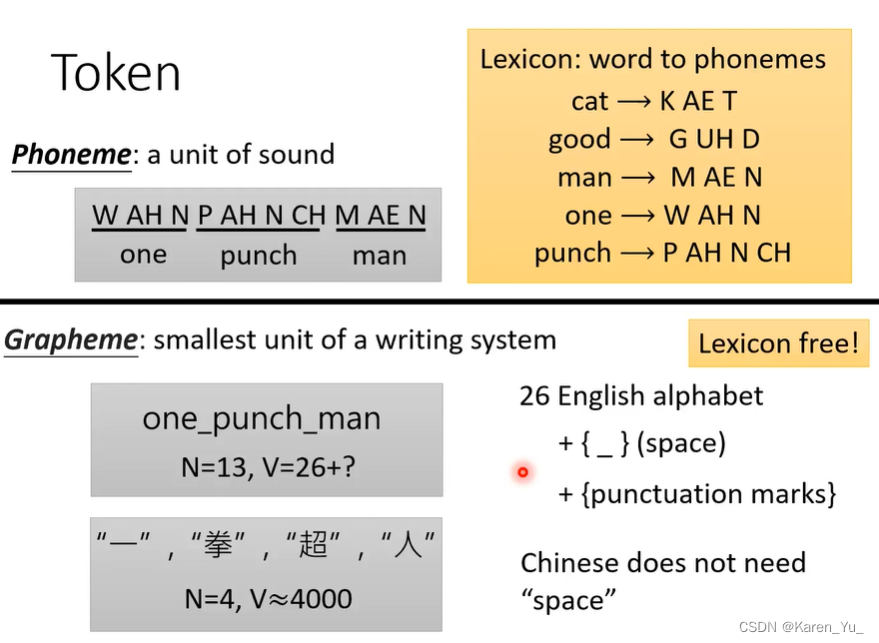
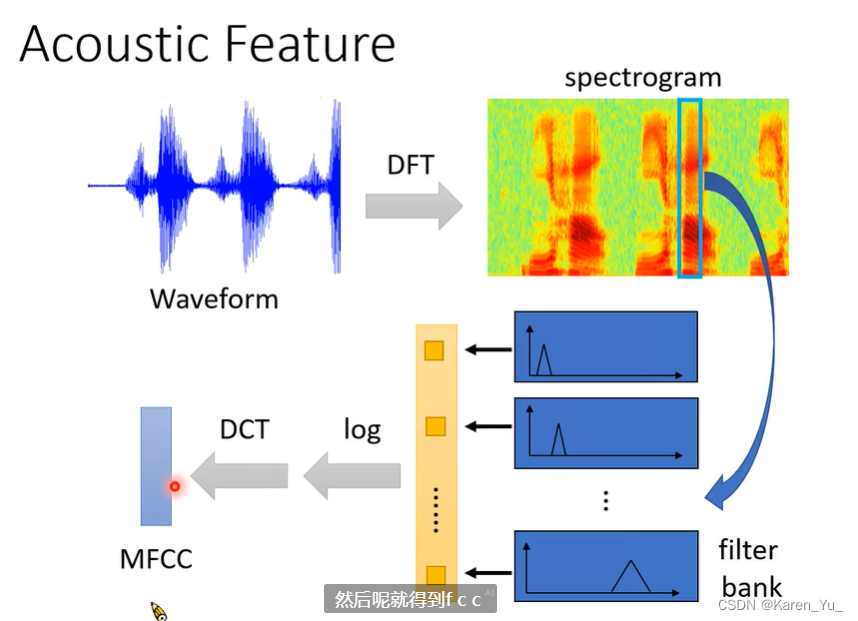
Phoneme: 发音的基本单位,但是直接读很难读懂,因此就需要一个字典lexicon,根据得到的Phoneme,结合字典吧看不懂的输出变成可以读懂的文字。但是lexicon并不是凭空出现的,需要语言学的知识。
Grapheme:书写的基本单位,比如英文中书写的基本单位就是字母,但是除了字母之外至少还需要空格,隔开词汇,可能还需要标点符号。如果是中文,基本的单位就是方块字(但是这里不需要空格了)。使用Grapheme的好处除了不需要很多语言学的知识(还是得知道这门语言文字是由什么组成的),还可以期待他能自己凭借听力拼写出他从来没听过的词汇。但是,可能听到的声音和对应的grapheme的关系是复杂的,比如k,c可能发音是一样的。

Word:更大的token,词。对于英文来说,就不需要空格了。但是也要注意,这种时候一般对应的V(token的种类数)就会非常大(甚至在中文中都很难界定有多少词汇)。课程中,老师举例的是在土耳其文中一个词加不同的词根变成新的单词,变成更长更复杂但完全意思不一样的单词->可以自己造词。没办法穷举所有的词。
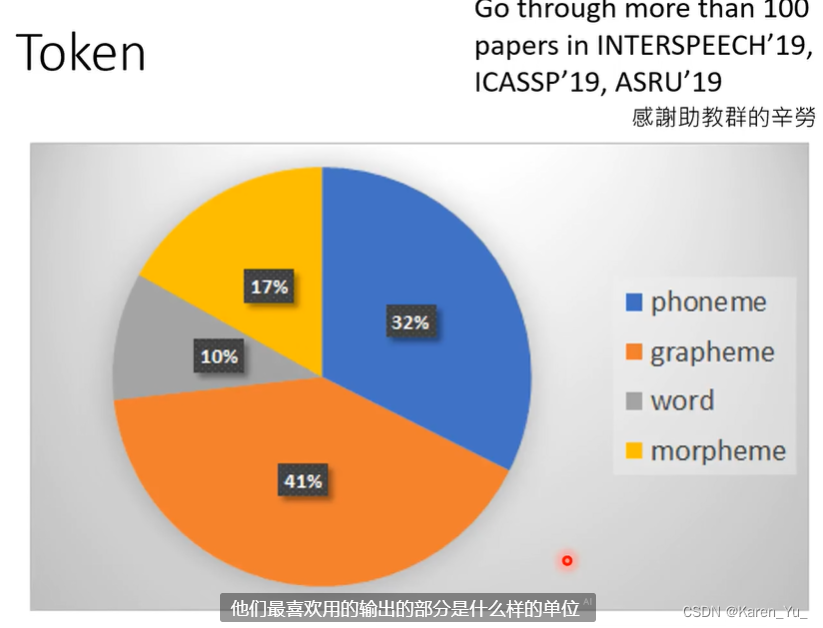
Morpheme:可以传达意思的最小单位,有点类似于英文中的词根、前缀、后缀。可能可以让语言学家提供,也可以通过统计学的方法,不精确的估计。

Bytes:各种语言各种符号都可以用bytes表示,输出UTF-8,再翻译出来。
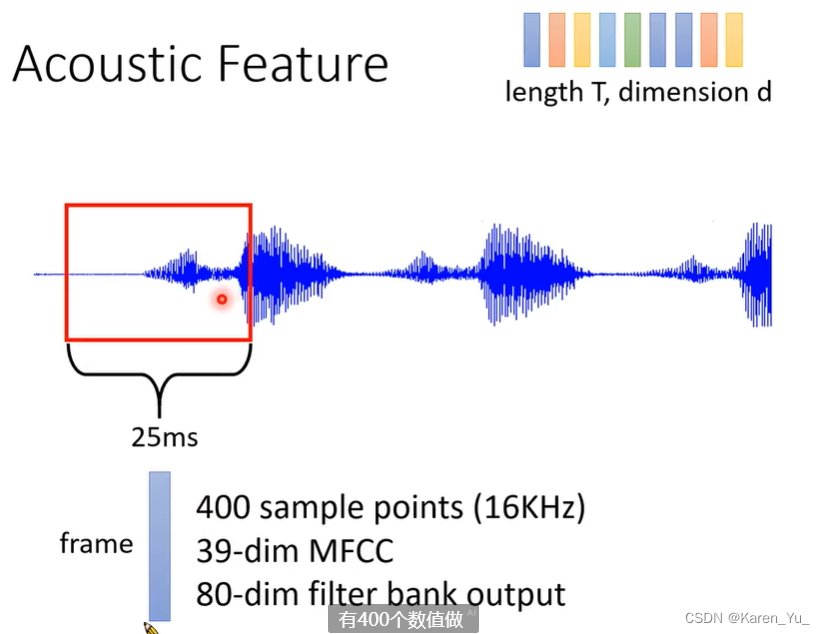
如何把一段声音信号变成一个vector sequence?一段声音信号进来,我们取一个window,这个window的长度通常是25ms,接下来用一个向量来描述这段声音信号中的特征,通常把这一个向量称为一个frame。可以直接什么都不做,直接用400个sample值,也有其他的方法。接下来移动window,一般10ms,如果说1秒钟的话,会被转化成100个向量,相邻的向量是有重合的部分的。
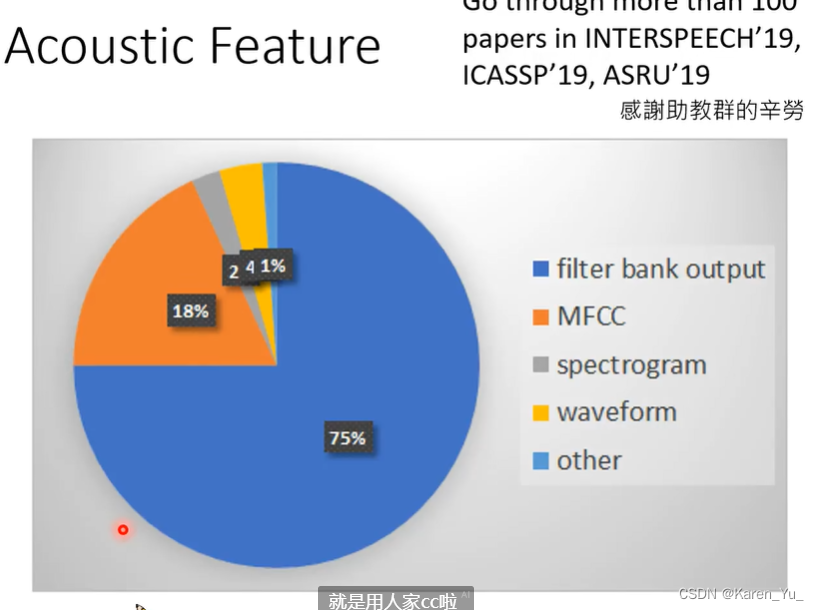

需要多少data?英文的常见语料库,其中librispeech可以免费得到~
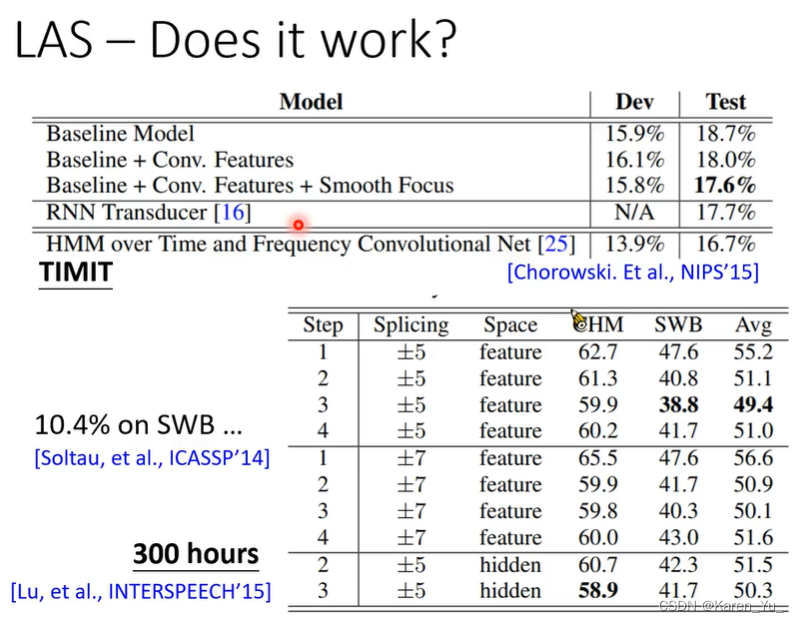
老师举例说TIMIT有点类似于CV中的MNIST,但实际上TIMIT要更大一点(换算的话)

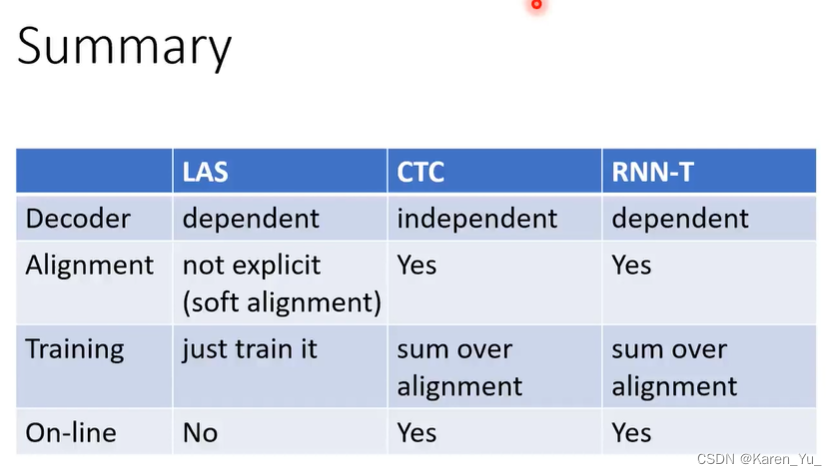
Listen, Attend, and Spell (LAS)
其中Listen指的是encoder,spell指的是decoder。(It is the typical seq2seq with attention)
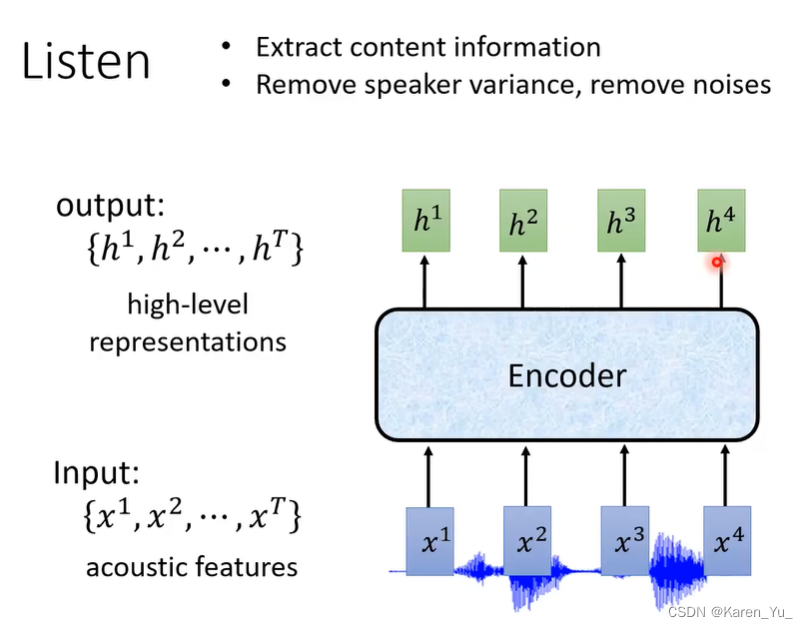
listen的部分就是一个encoder。输入一段acoustic features(声学特征),输出另外一串向量,输入和输出的长度是一样的(输入x1到x4,输出h1到h4)。期待这个encoder可以把声音信号中的噪声去掉知己留下与语音识别有关的信息。
那么怎么进行encoder呢?
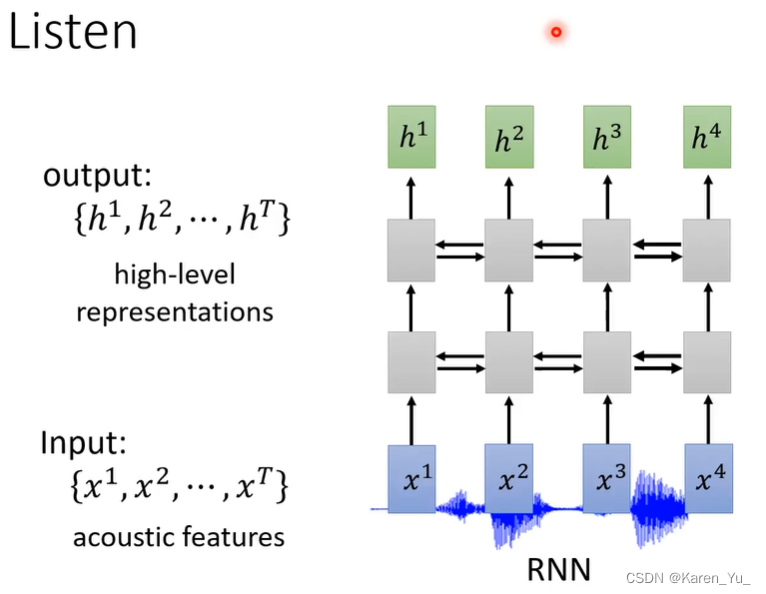
可以使用RNN,这里RNN可以是双向的。
也可以使用CNN。这里采用1D的卷积,方法是把一个滤波器沿着时间的方向扫过这些acoustic features。每一个filter会放一个范围的acoustic features进去,输出一个值。使用多个filter,这样每一个输入的acoustic feature都会被转换成一排向量。

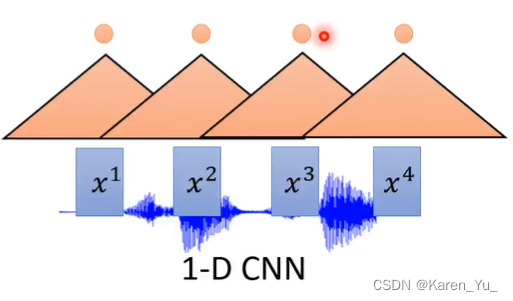
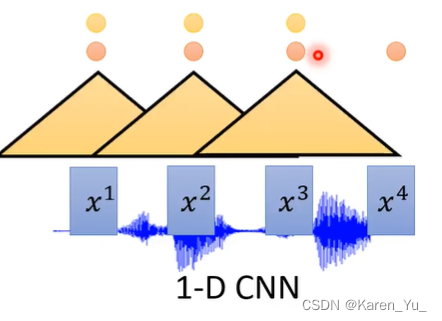
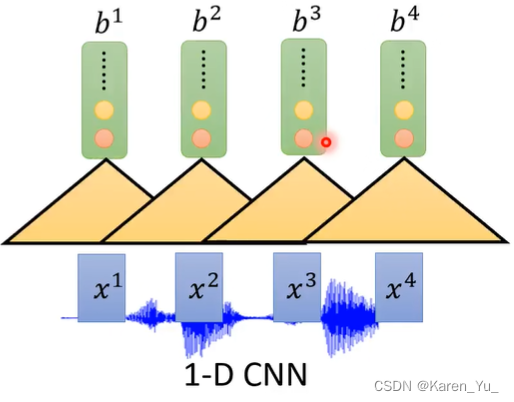
在产生b1这个向量的时候并不是只采用x1的信息,而是也采用了x2的信息,同样,在产生b2向量的时候,不是只采用x2的信息,同样还包含了x1和x3的信息。
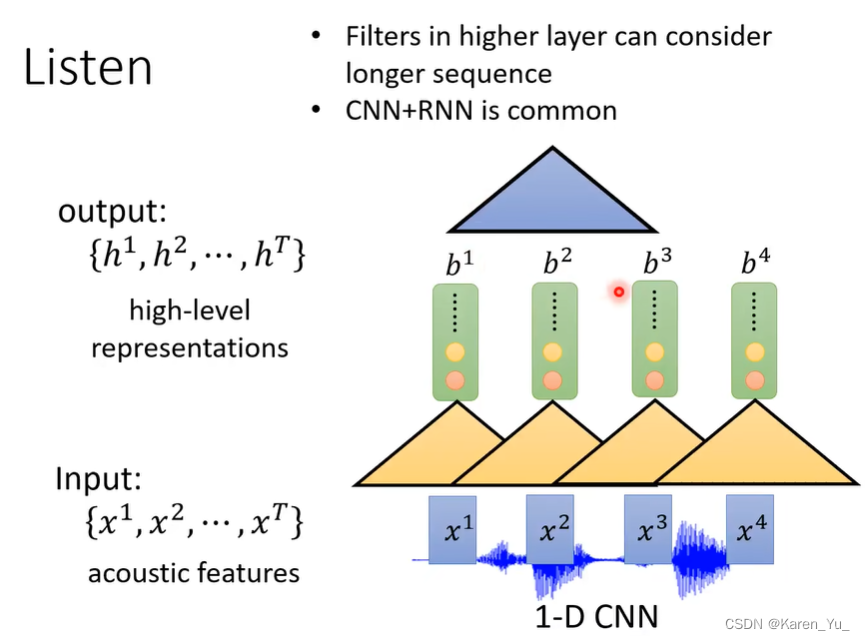
也可以在filter上再叠filter。比如这里输入就是b1 b2 b3。因为产生b1 b2 b3分别要x1 x2,x1 x2 x3,x2 x3 x4的信息,因此这里相当于已经获取了完整的x1 x2 x3 x4的声音信号。老师提到在论文中常把两者一起使用,可能前几层用CNN,后面用RNN(LSTM)。
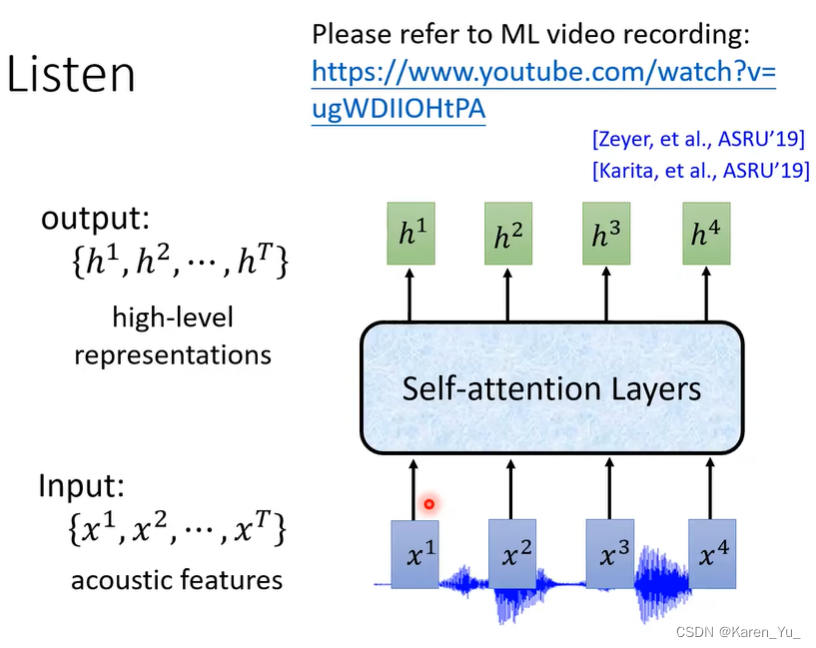
也有使用attention layer的,所做的与上述的类似。
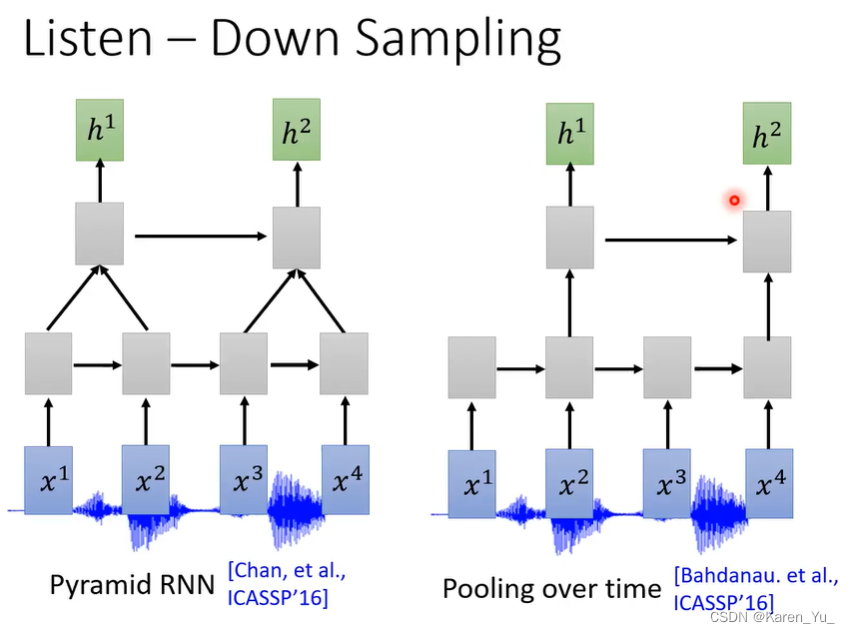
在做语音识别时,往往需要对输入做做down sampling,因为如果把声音信号表示成acoustic feature往往很长,一秒钟的声音信号,要有100个向量,而且相邻的向量间带有的信息量的差异不回很大,为了节省计算量->down sampling。

即使使用的是CNN/self attention也会使用一些down sampling的方法。比如TDNN,filter吃一个范围的声音信号之后生成一个向量(可以减少计算量和参数量)。Truncated Self-attention,每一个时间点(每个feature)都会去append整个input中所有的feature。比如要把x3变成h3要对整个input都做attention->在做attention的时候只允许attention一个范围内的,超过这个范围的就不看了->节省运算量。(范围多大是需要调整的参数)
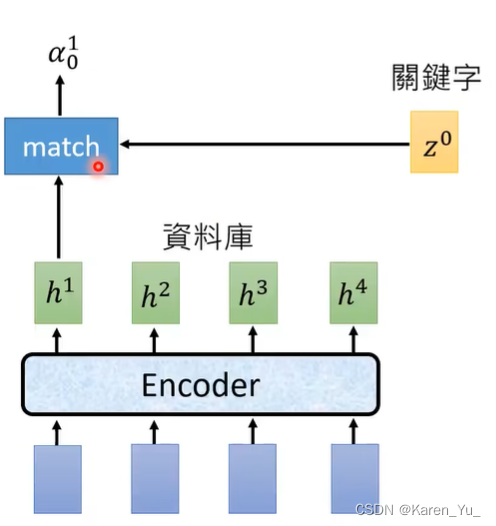
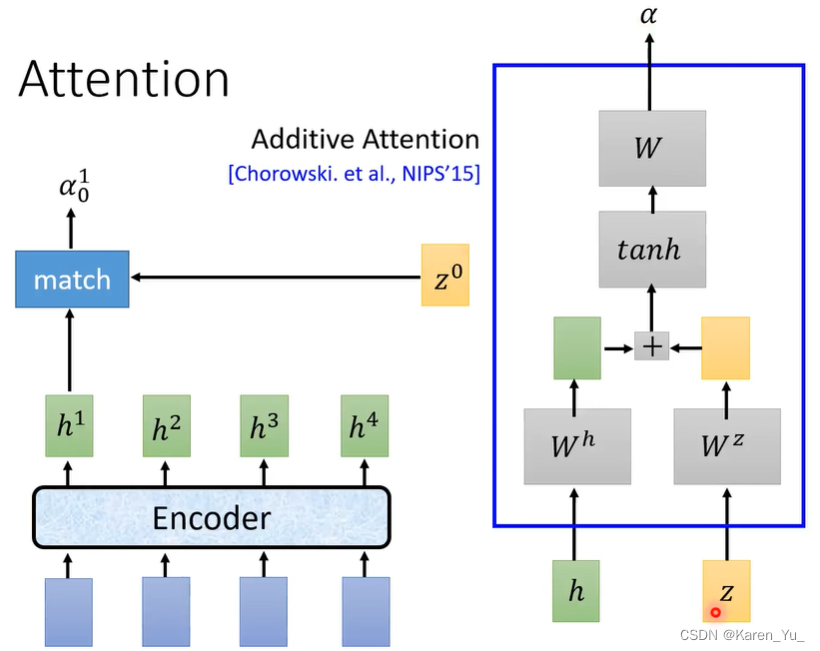
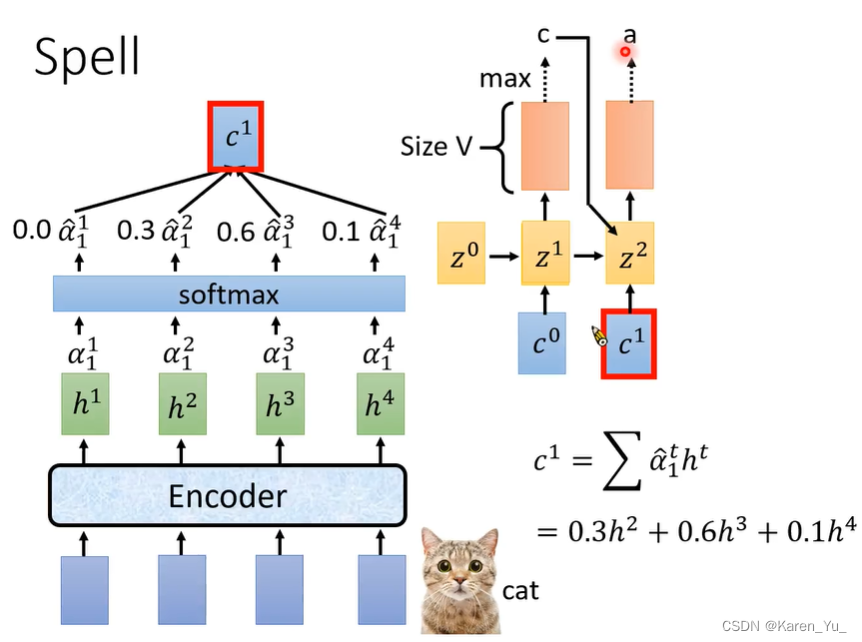
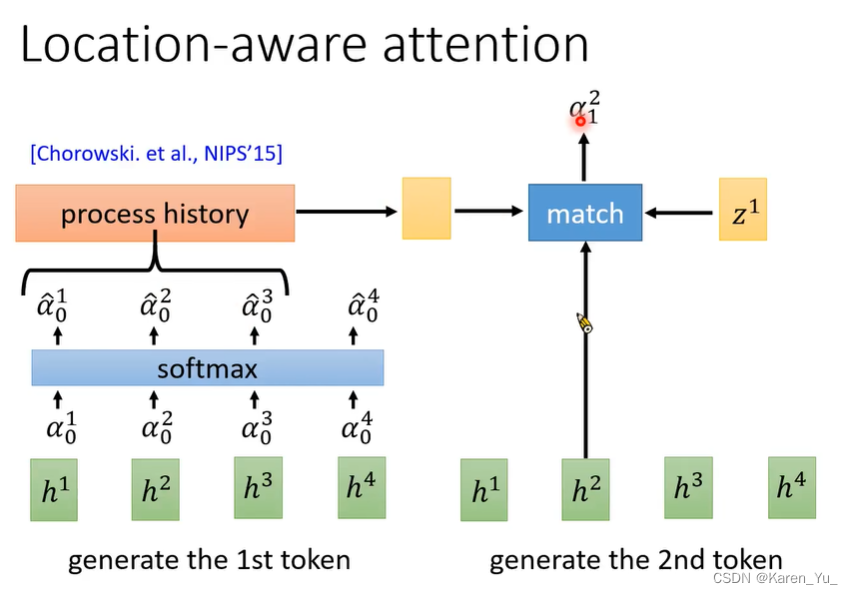
首先有个vector z0,使用z0与encoder的输出计算attention。在做attention的时候会有一个function match,这个match会使用z0和来自encoder的一个vector当输入,输出一个数值α。

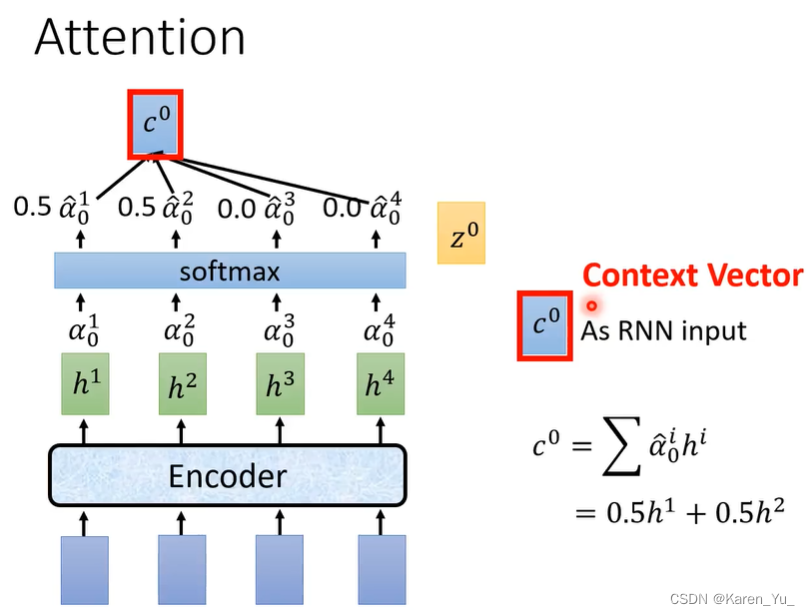
z0分别于h1 h2 h3 h4得到α1 α2 α3 α4,经过softmax,让α的总和为1,将通过softmax以后的α乘h,求和,得到c0。c0会被当做decoder的input
c0是decoder的输入,输出token的distribution。给每个token一个几率,看来自输入的c0决定输出哪个token。

比如现在的输入是cat,经过上述操作后输出了第一个字母c(假设token是字母)。那么怎么输出第二个字母?
使用z1重新做attention(之前是z0),得到c1。注意这里不仅要关注c1也要关注之前的输出。

c:context vector,上下文
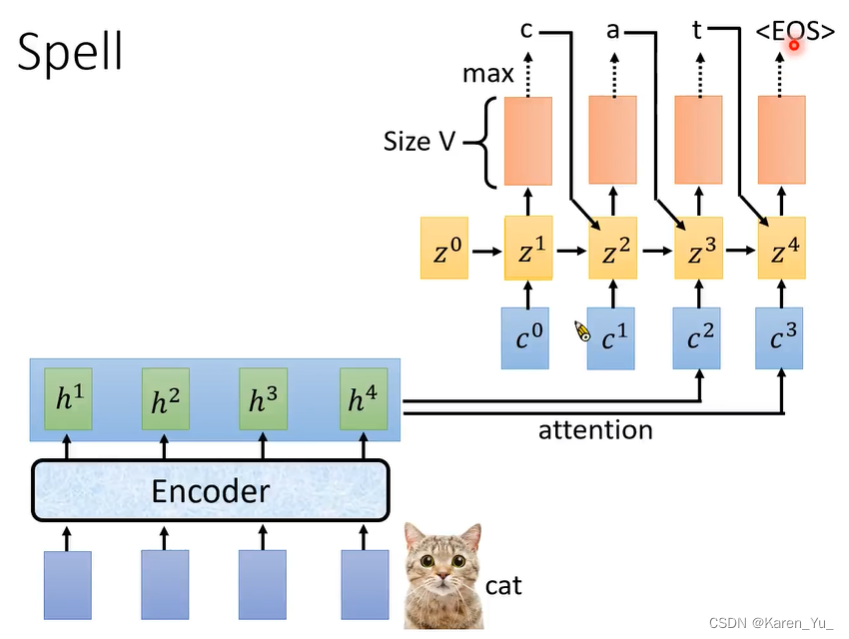
特殊字符<EOS>,end of sentence辨识结束。
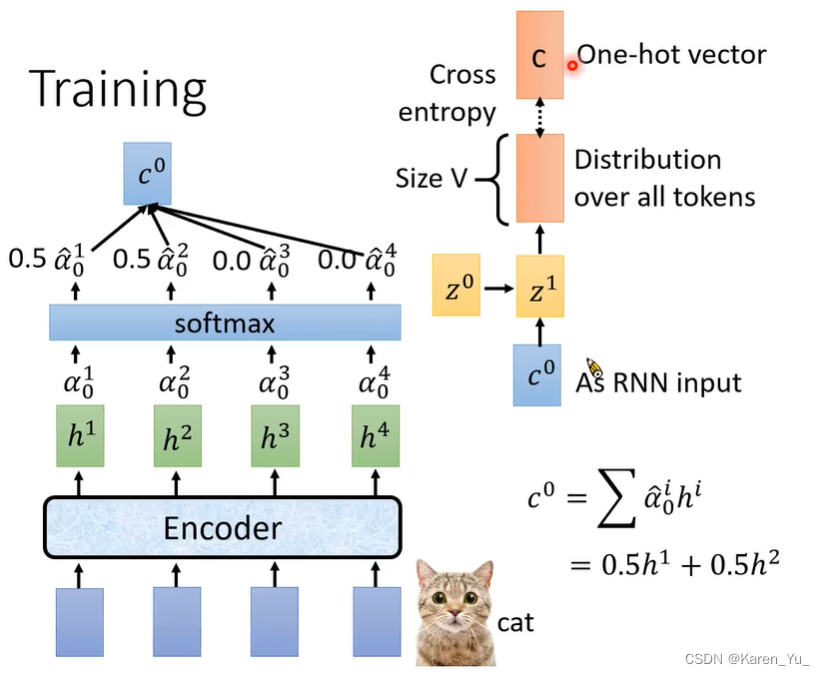
在训练时,希望输出c的概率最大。

类似的第二位也是希望输出的a的概率最大,换言之就是,把a表示成一个one-hot vector,希望输出的distribution和a的cross entropy越小越好。
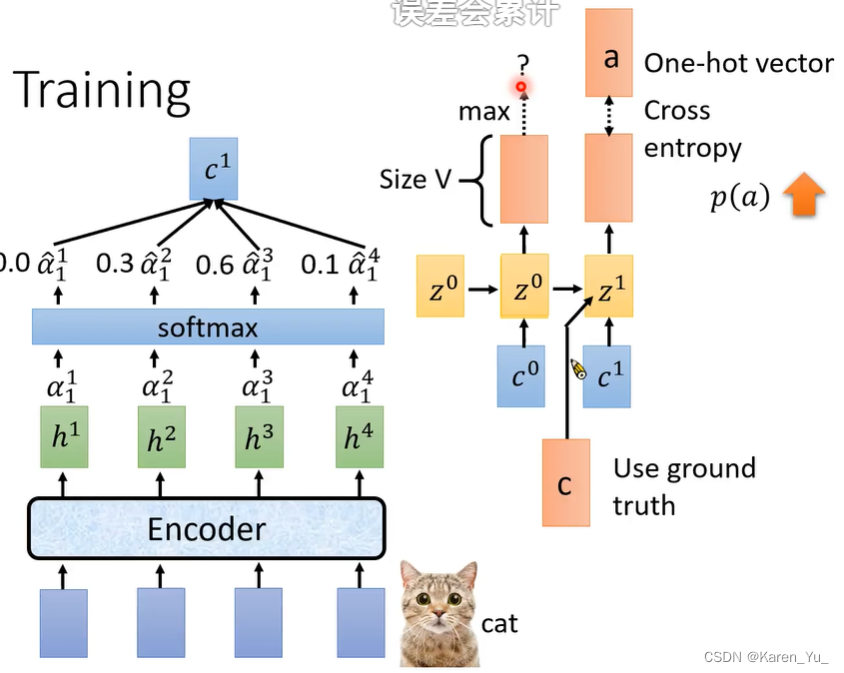
在训练的时候,不会用前一个的输出(最大概率)来训练,而是直接告诉ground truth,称为 teacher forcing。
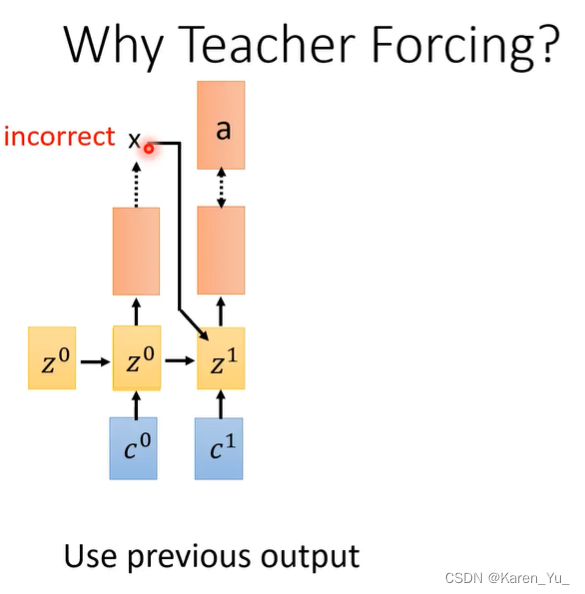
为什么要teacher forcing?因为在训练开始的时候,参数是随机的,model很烂,输出的是乱七八糟的东西,所以这个时候输出不一定正确的。比如这里可能第一位输出的就是x,那么学到的就不是c后面加a而是x后面加a。
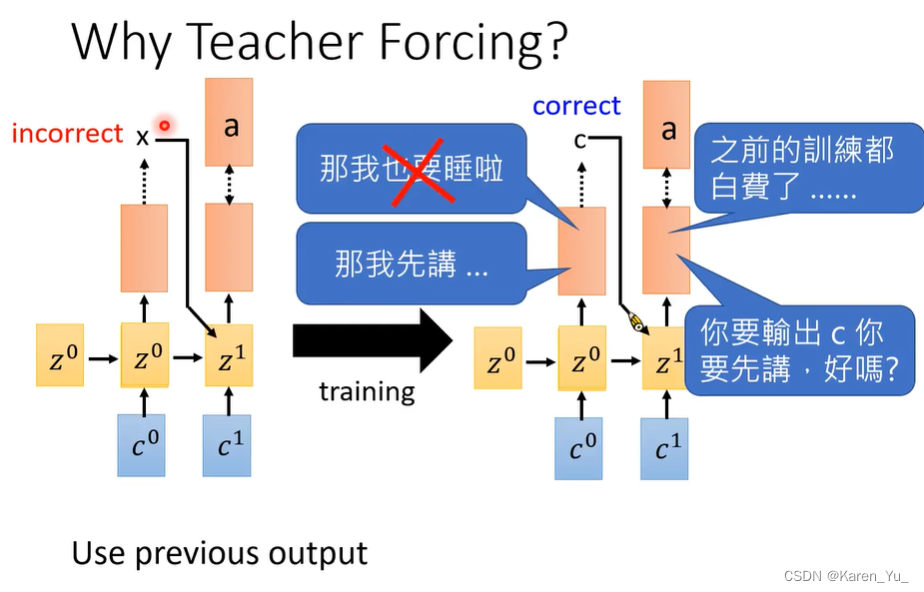
经过一段时间训练之后,model就知道第一个输出应该是c。但是后面的a学到的是前面是x,相当于前面都白学了。



aaa->认为aaa和triple a的可能性是最大的,但是实际上这两种发音完全不一样

LAS的DIS-AD:
我们希望机器可以一边听声音一边出结果,但是LAD要先听完一整个句子,才能输出。
(引出下面的模型)
Connectionist Temporral Classification (CTC)
CTC可以做到一边听一边输出。
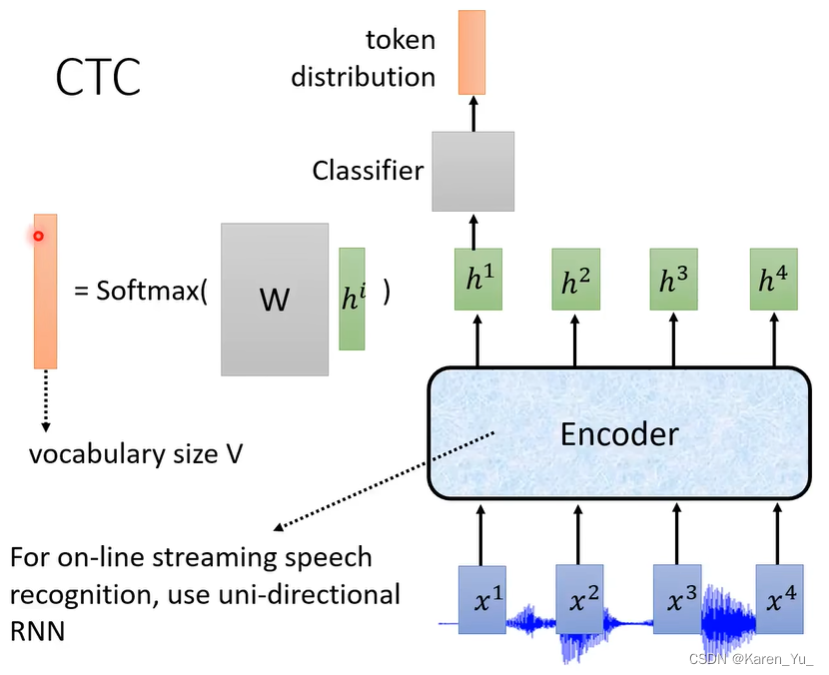
CTC可以说只有encoder,在选encoder的时候,要选择一些可以做on-line的encoder,比如uni-directional RNN(单方向的RNN),如果选择双方向的RNN作为encoder中的network架构,就要把整个句子看完,才能计算出h1 h2 h3 h4;如果选择单方向的RNN就可以看到x1产生h1、x2产生h2、x3产生h3、x4产生h4,就有机会做on-line。

把h1 h2 h3 h4跑出来以后,就把他们丢到一个linear的classifier里面去,然后决定当前的h属于哪一个token。这里的linear classifier就是拿到h,乘以一个transform,再softmax,得到所有token的distribution。

但是我们知道x1只是一个acoustic feature,只是一个很小的声音信号,大概10ms,一小个acoustic feature很难判断是哪个token。因此在CTC中加入一个新的tokenΦ(表示不知道是什么),可能到之后的输入才会知道这是什么。
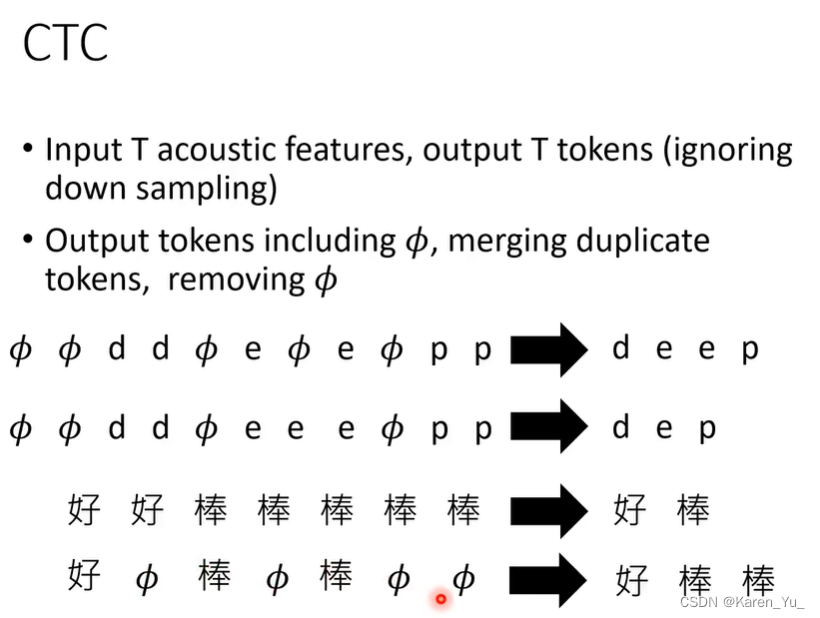
CTC认为无论能不能听出来token,都要输入和输出一一对应,但是在实际输出中我们显然不能直接输出Φ,要进行一些后处理。
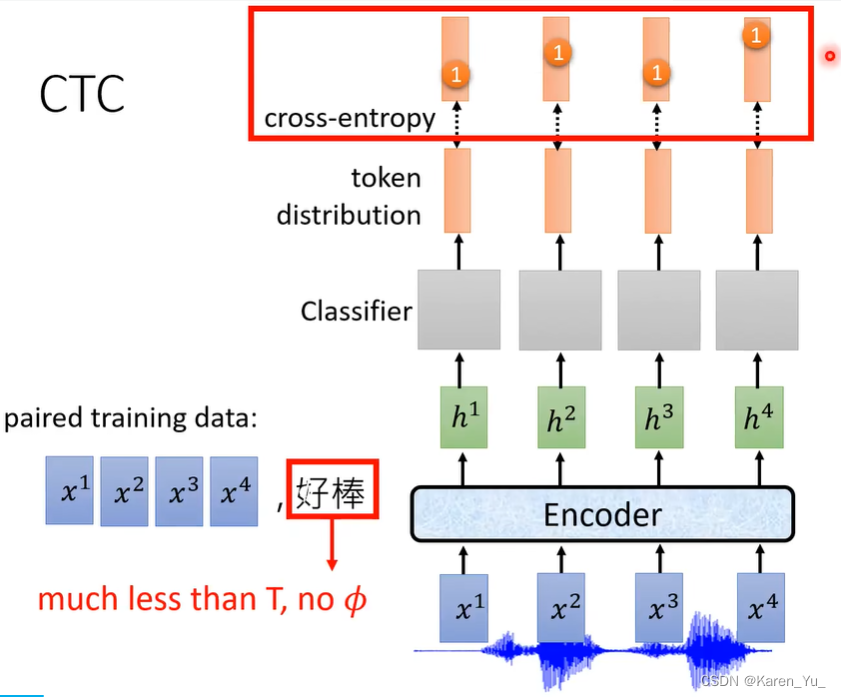
训练的时候,要告诉每个feature对应的是什么,但是对于每个输出的token,我们不知道每个token应该对应什么。比如这里x1 x2 x3 x4是好棒,但是我们不知道这个好棒应该放在哪一个位置,输出远小于输入(而且这里也没有Φ)

因此标注是不够的。->alignment:制造,比如在好棒中间加入两个Φ或者在中间夹Φ等等很多的方式。CTC采取的策略是,这些组合方法都拿做alignment。

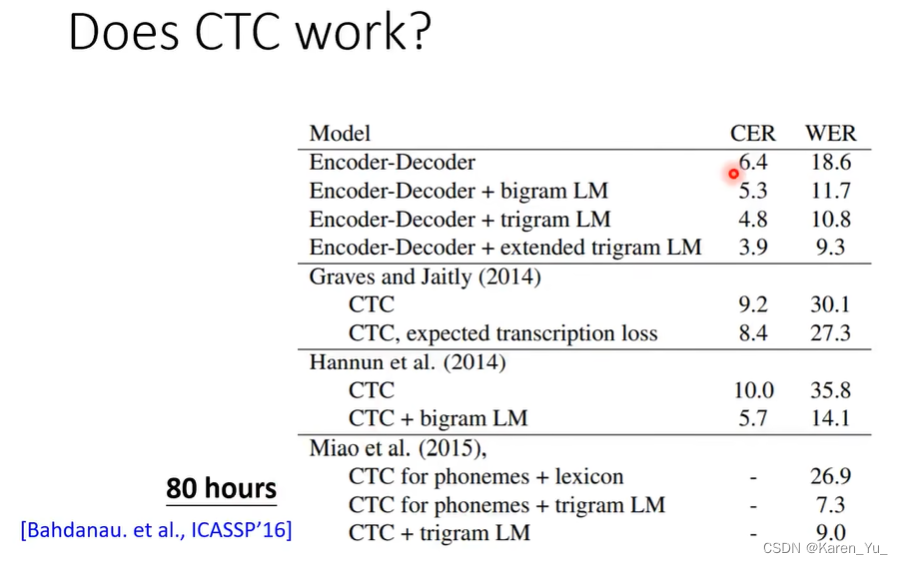
CTC work吗?如上图,其中浅灰色代表的是Φ的几率。在下面的例子里采用词作为tokendiet terry其实是dietary,但是犹豫字典里没有这个词(只有7k个词),因此用这两个词凑出来这个发音。
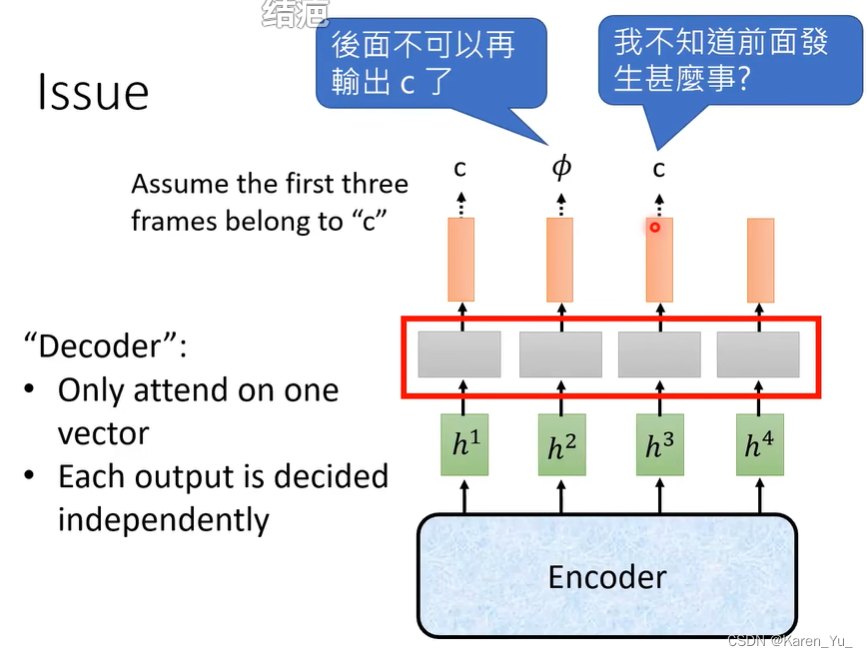
CTC的问题,这里的linear classifier相当于是decoder,但是每次只吃一个vector,决定输出值,并且每次输出都是independent->可能会造成结巴。如果第一个产生c,第二个产生Φ,第三个再产生c,那么只是把Φ去掉,这样就有两个c了,并且这个时候没办法消掉两个c,因为每个都是独立的,并不知道前面输出了什么。
但是呢也不一定就很差,因为这里也有encoder,可能encoder是一个很深的LSTM,知道前面已经出现Φ,就会抑制下一个产生c。
RNN Transducer(RNN-T)
Recurrent Neural Aligner (RNA)
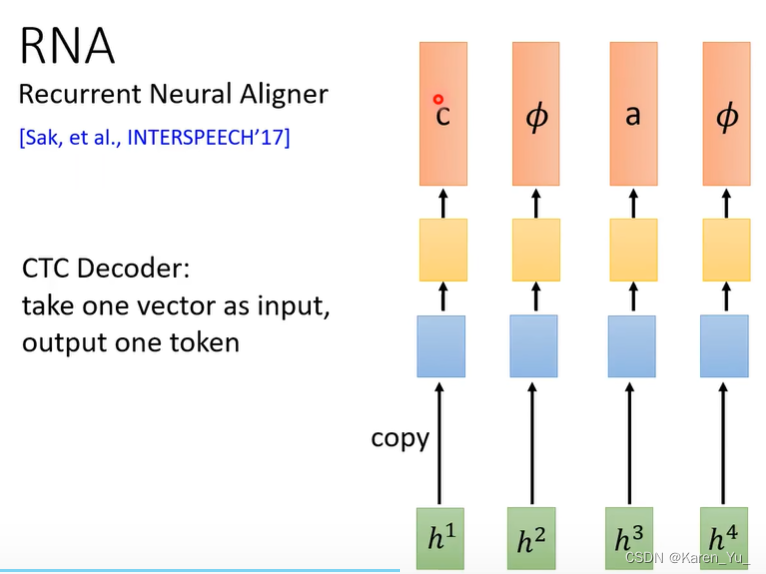
CTC的decoder是独立的,从encoder那边拿一个h进来就要classifier output结果,每一个classifier决定output什么东西是各自独立的。->能不能让每一个classifier在决定的时候看一下前面输出什么呢?
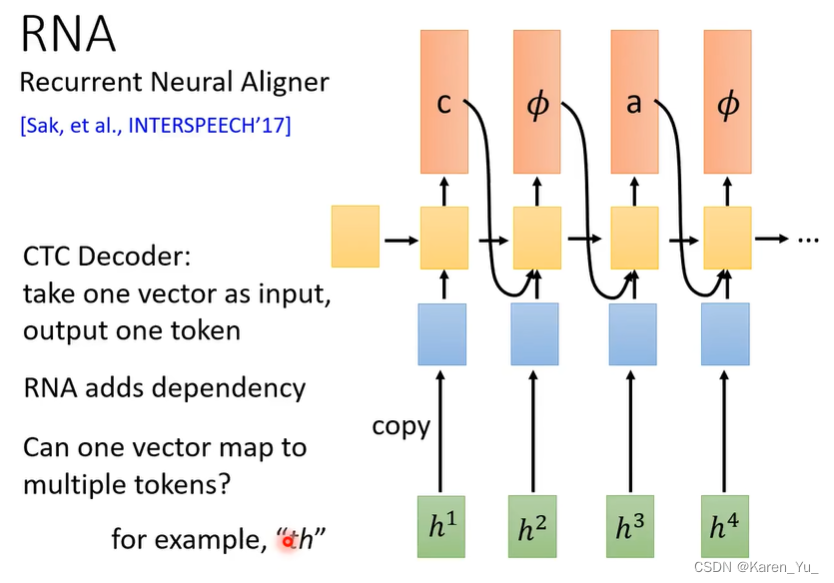
可以,把linear classifier换成RNN/LSTM->RNA
但是也有可能存在一个输入对应多token的情况,比如th。最简单的方法是把th加入token。但是我们希望模型是flexible的,给什么数据都行。
RNN-T
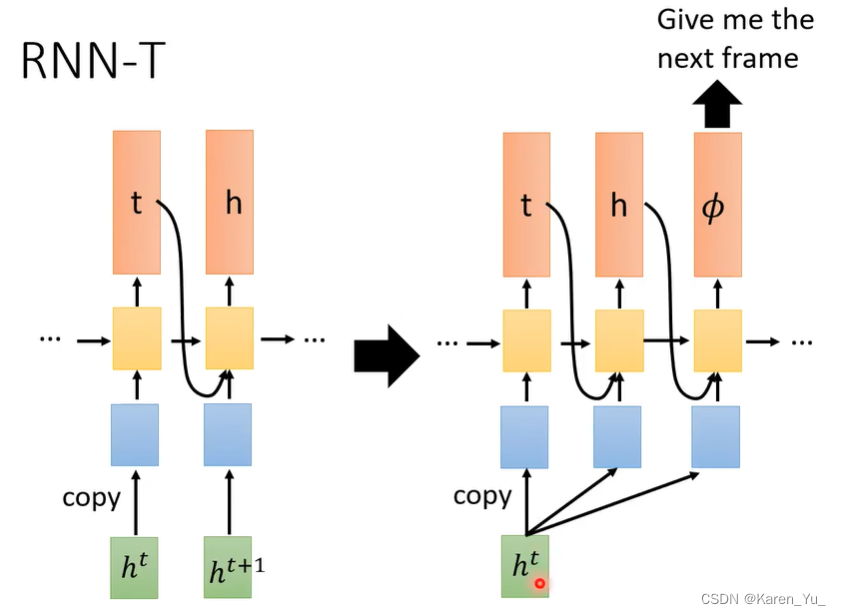
RNN-T可以解决这个问题,其策略是,看到一个输入,就一直输出到满意为止,满意之后就输出Φ。
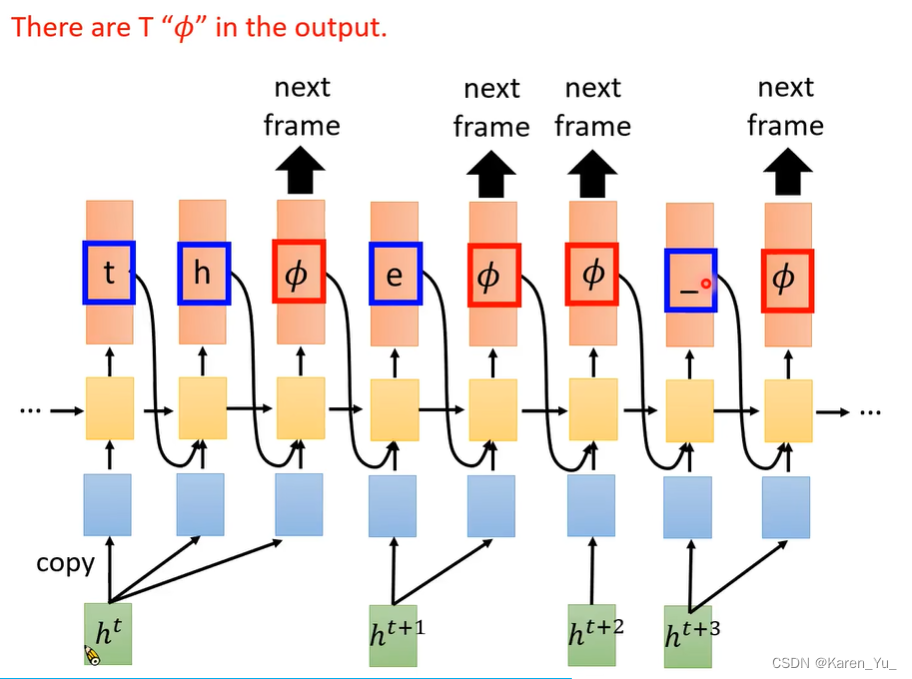
ht先进来,丢给decoder,decoder先output一个t,再output一个h,再说“够了,给我下一个input”。接着把ht+1拿进来decoder,输出e,觉得够了,安排接待下一个ht+2,因为一个acoustic feature很少,所以可能decoder觉得没什么好输出的,因此直接输出Φ,进来下一个ht+3……
要插入T个Φ,一个Φ代表一个acoustic feature读完了,因此T个acoustic feature就要插入T个Φ。
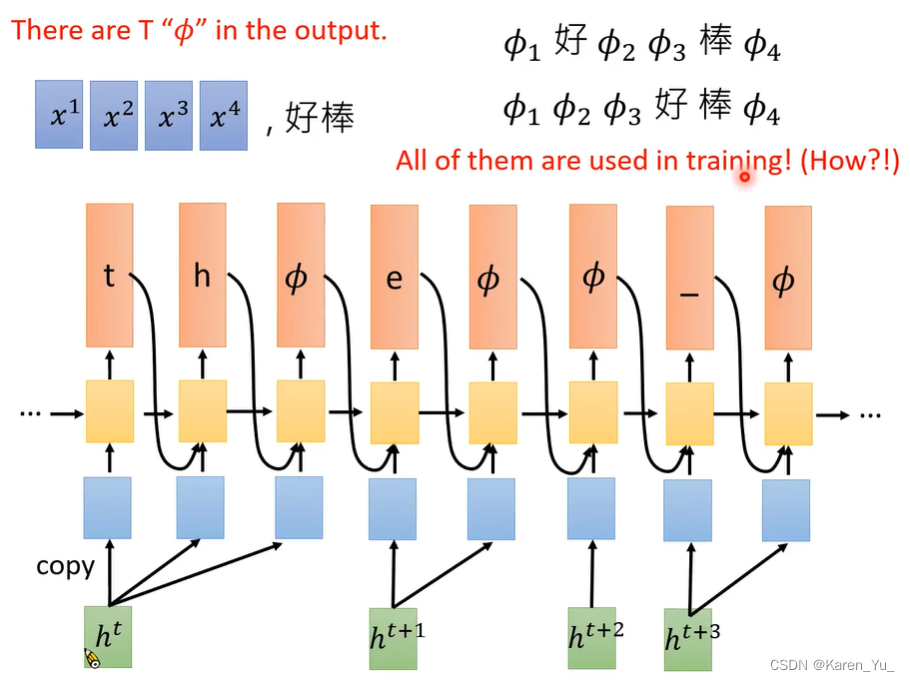
RNN-T也有和CTC一样的问题,alignment。RNN-T需要知道什么时候应该输出Φ(什么时候读入acoustic feature)。因此我们也面临同样的问题,在哪里插入Φ?这里采用的方法与CTC一样,穷举所有alignment,在训练时使用。
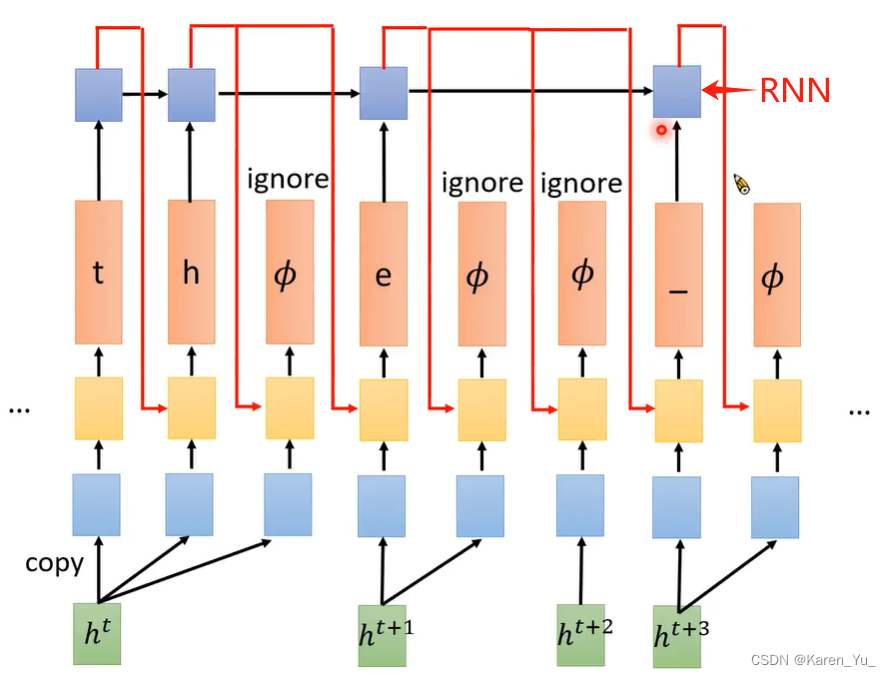
实际上RNN-T会另外训练一个recurrent neural network,这个RNN的作用有点像一个language model->实际上,在考虑每一个linear classifier的dependence时候,RNN-T并不是直接把这些linear classifier改成RNN,是另外用一个RNN来考虑要output哪一个token的dependence。RNN会看如果前面已经输出token,就把这些token丢进RNN。
比如这里输入一个ht,输出一个t,这个t就会被放进RNN里去,这个RNN的输出就会决定RNN-T下一个token的输入。这个RNN会忽视Φ。

可以先训练RNN(用大量数据),无视Φ,老师认为是为了训练,采用这种方法。
Neural Transducer
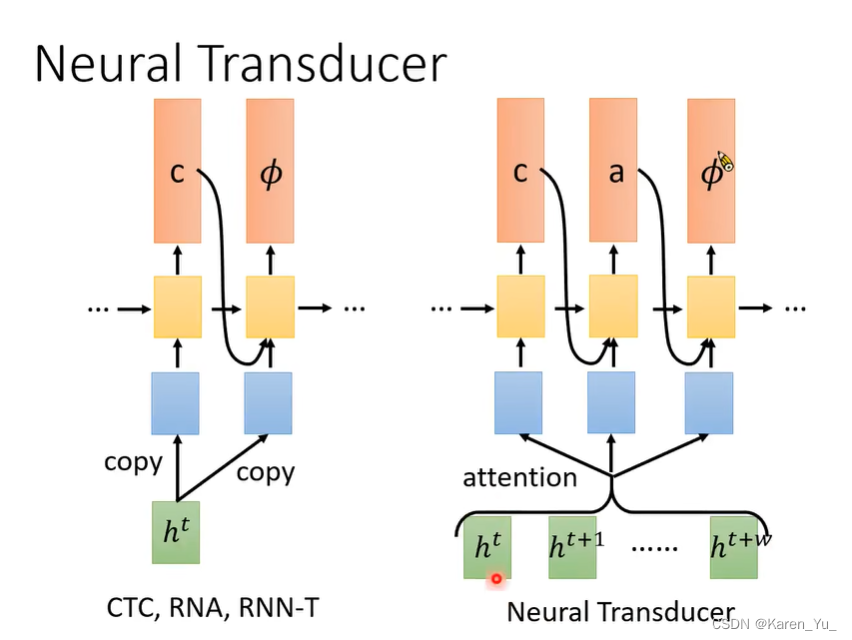
一次多读点acoustic feature中,这一个区域中做attention。
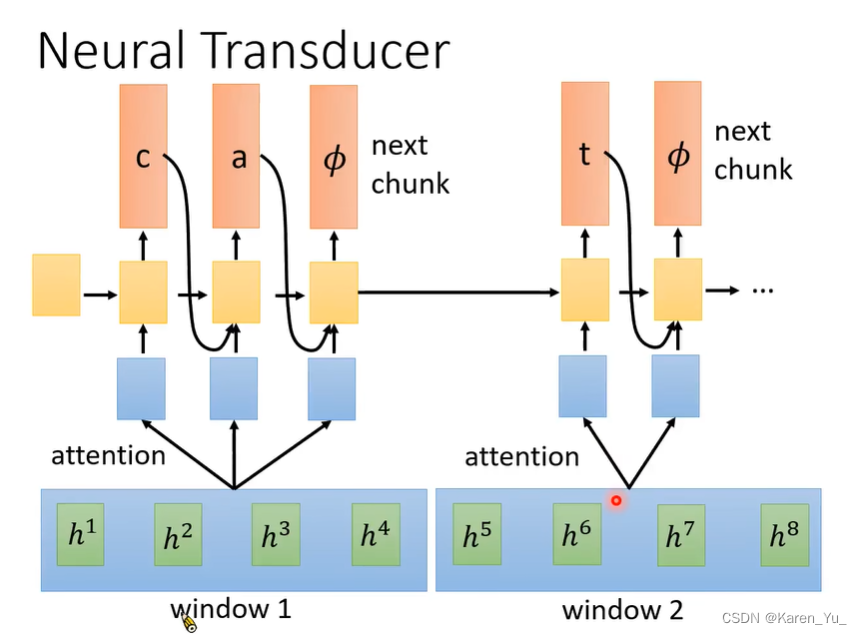
先读一些acoustic feature进来,累积到一定量之后,开始产生输出,获得输出时只在小范围内做attention,如果觉得读完了,输出Φ,开始看下一个Window。
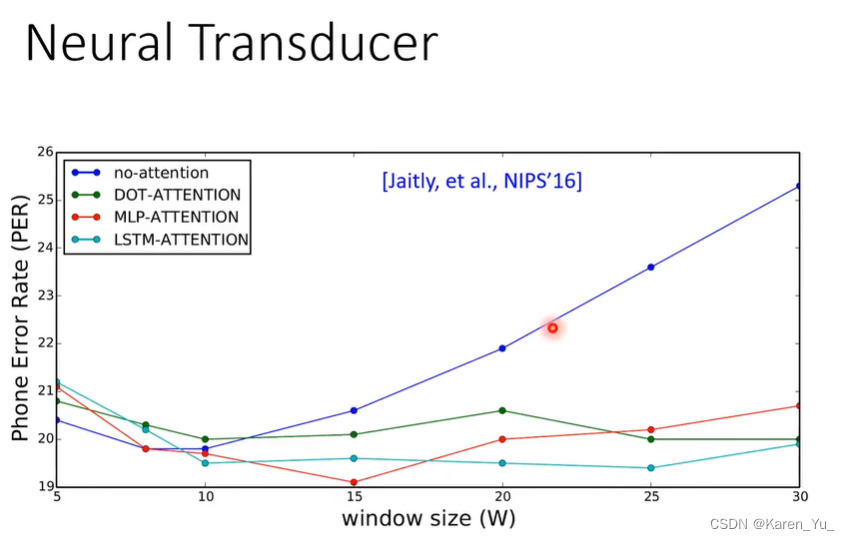
有attention之后,window的size不是那么重要,没有的话,随着window的大小增加,结果就爆炸了。
Monotonic Chunkise Attention (MoChA)
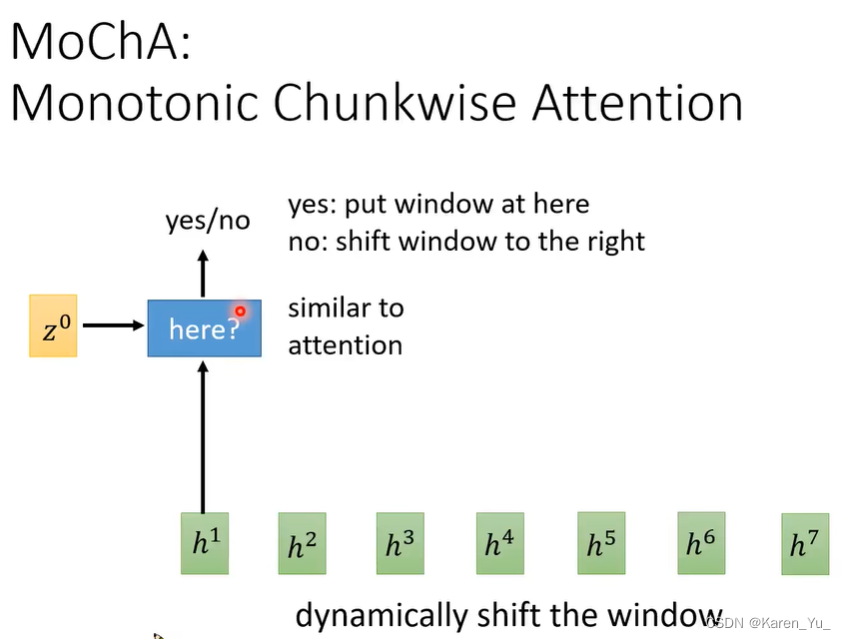
动态的移动window,在之前的neural transducer里面,window移动的距离是固定的。
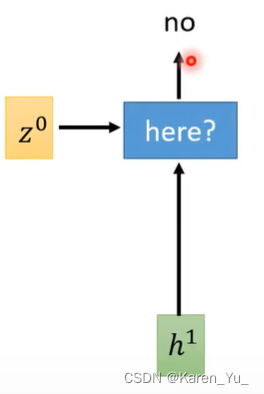
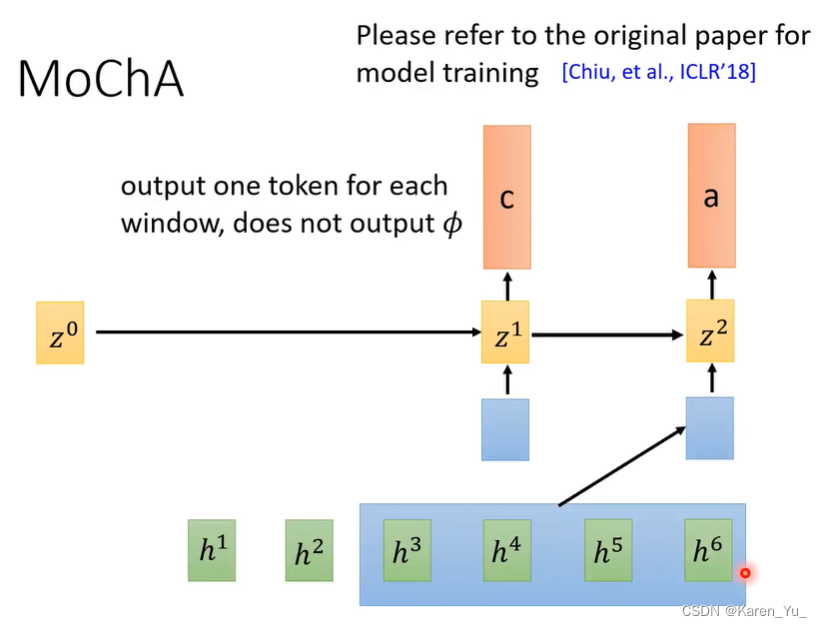
一个model吃一个z和一个frame,得到的结果是要不要把Window放在这里,产生yes/no,然后做attention。mocha要求每次只输出一个token
Summary

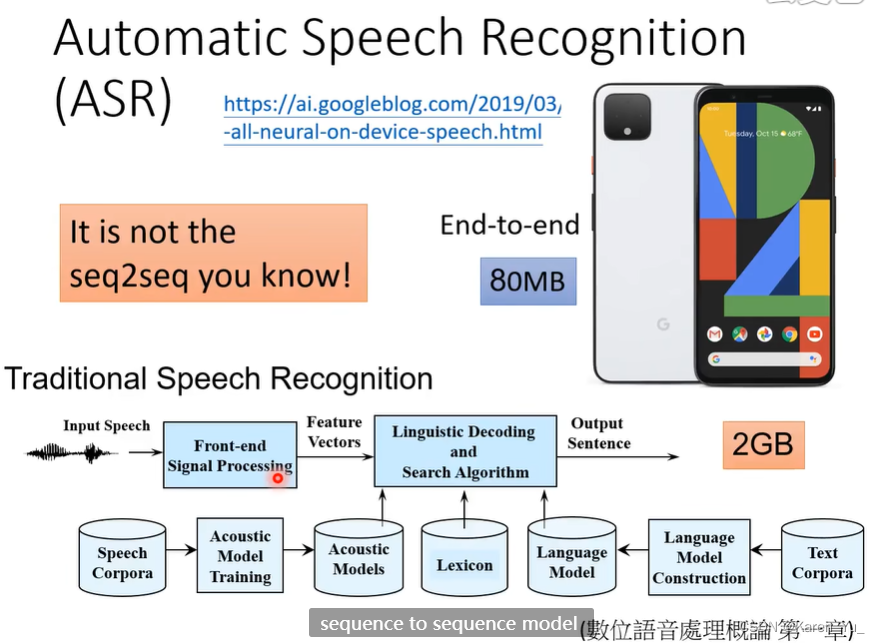
早期语音识别技术
Hidden Markov Model (HMM)
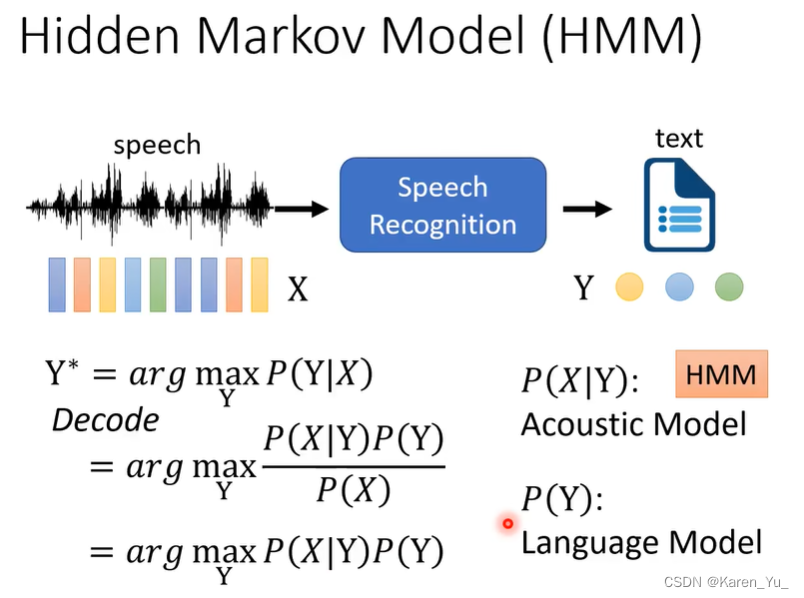
语音辨识就是输入一串vector X,输出一串token Y。过去的idea,采用统计的方法解决:如果可以统计出输入vector X输出token Y的概率,在做语音辨识的时候,要做的就是穷举所有可能的Y,穷举所有可能的token sequence,看哪一个token sequence带进去算出来的概率最大就是语音辨识的结果。这一过程称为decode。
那么怎么穷举所有可能的Y呢?->很复杂
根据贝叶斯定理,可以展开,因为P(X)与最后的结果无关,所以可以拿掉。
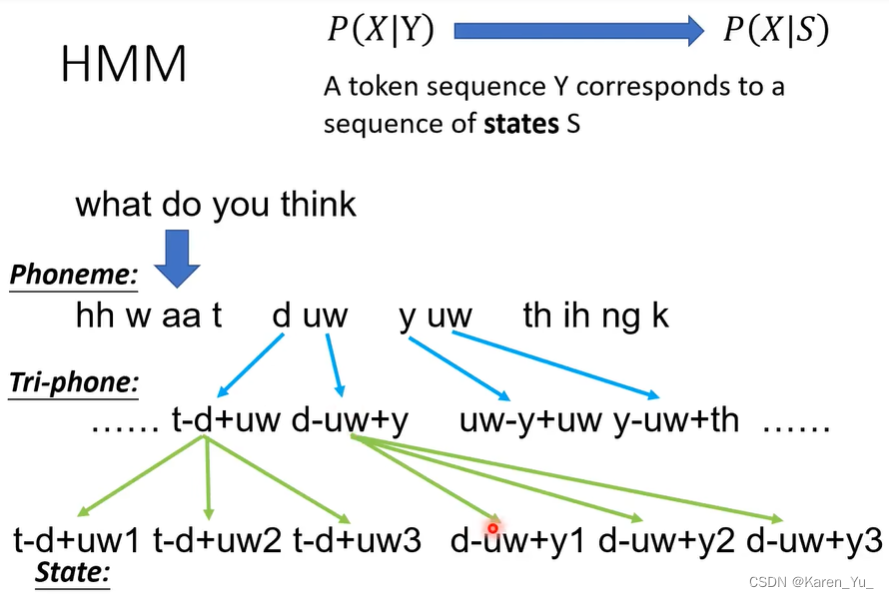
在之前的模型中提到的token,比如Phoneme、字母,单词,都太大了。对于HMM,考虑的是state seq,即在之前提到的模型中采用的是token sequence,这里(这个古早模型),采用的是state sequence。这里的state是认为定义的,比Phoneme还要小的单位。
tri-phone:比Phoneme更细致的单位,并不是吧Phoneme分成三段,是加上前一个和后一个Phoneme。虽然do和we都是都有'uw',但是会受到前一个发音和后一个发音的影响。
state:假设每一个tri-phone是由3or5个state构成的(具体几个自己决定)

假设我们有一段声音信号X,X里面有6个vector。怎么得到vector:进入第一个state产生一些vector,再进入下一个state产生一些vector……
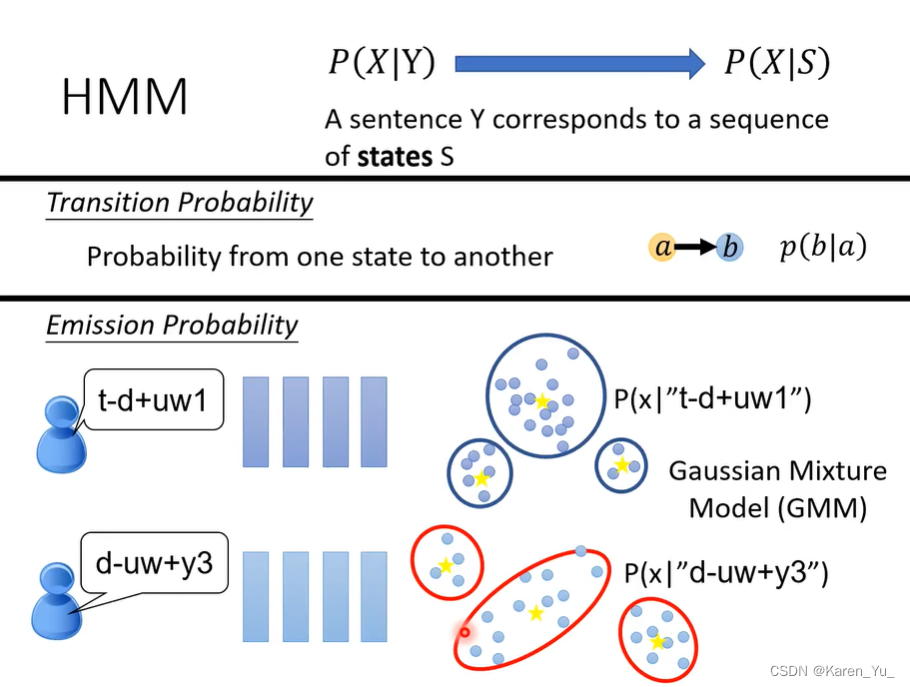
需要两个概率:从某个state跳到另一个state的概率(也包括从自己跳到自己的概率),给一个state产生某个acoustic feature的概率(假设每一个state里面的声音信号有一个固定的distribution,比如想发某个state的声音信号,这个声音信号的vector有一个固定的分布)。因此才要用比Phoneme更小的单位(保证有固定的分布,发音不能变来变去,因此当然不能直接用字母当token,因为同一个字母的发音并不是固定的)。

这就导致一个问题,state实在太多了。因此可能某些state在训练集中只能出现一两次,这样自然也没办法估计其的Gaussian Mixture Model长什么样子。->tied-state,让一些state共用相同的GMM。

这里还是要知道每个vector(acoustic feature)是由哪个state产生的。->alignment(把短的东西和长的东西对应上)->hidden,我们实际上不知道alignment。->穷举所有alignment,再把每个alignment产生acoustic feature的概率加起来
How to use Deep Learning
最早的思路都是基于HMM改。
Tandem

不去改变HMM的部分,用Deep Learning给我们比较好的acoustic feature。
训练一个DNN,判断属于每一个state的概率(state classifier),把DNN的输出当做新的acoustic feature。
DNN-HMM Hybrid

把GMM(计算给定state产生一个acoustic feature的概率)用DNN(训练一个state classifier,给一个X,看其是某个state的概率) 取代掉,看起来毫不相干(但是用数学方法可以统一)。

怎么训练state classifier?需要acoustic feature和state之间的对应关系(这是我们没有的)。
过去的做法是先训练一个HMM-GMM,做alignment,算出state sequence分配给acoustic feature概率最大的alignment

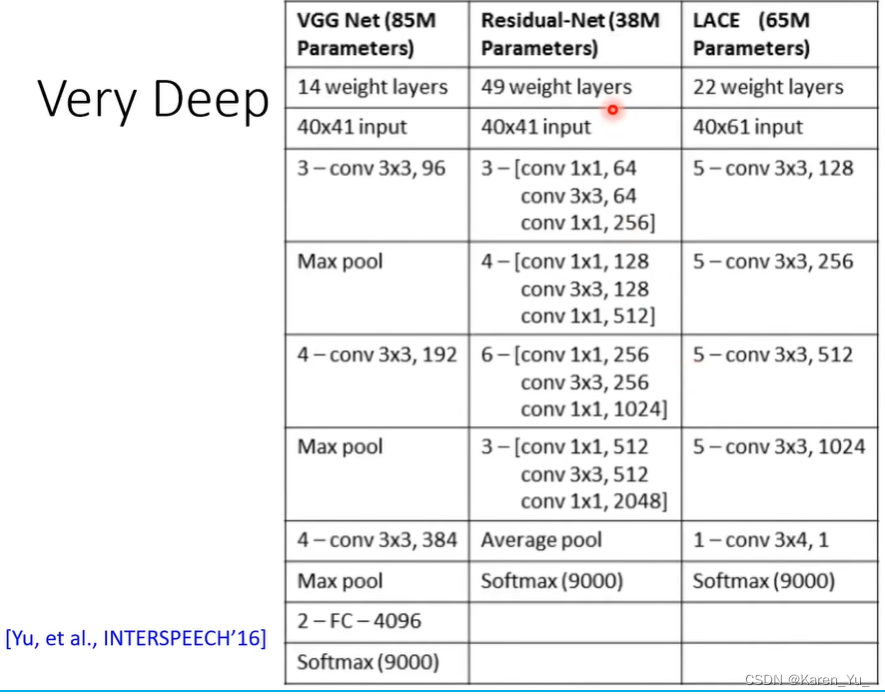
End-to-End
目前的end-to-end技术实际上都是在计算P(Y|X),给一串acoustic feature sequence,产生token sequence的概率。在decode的时候,找一个Y让P(Y|X)最大。
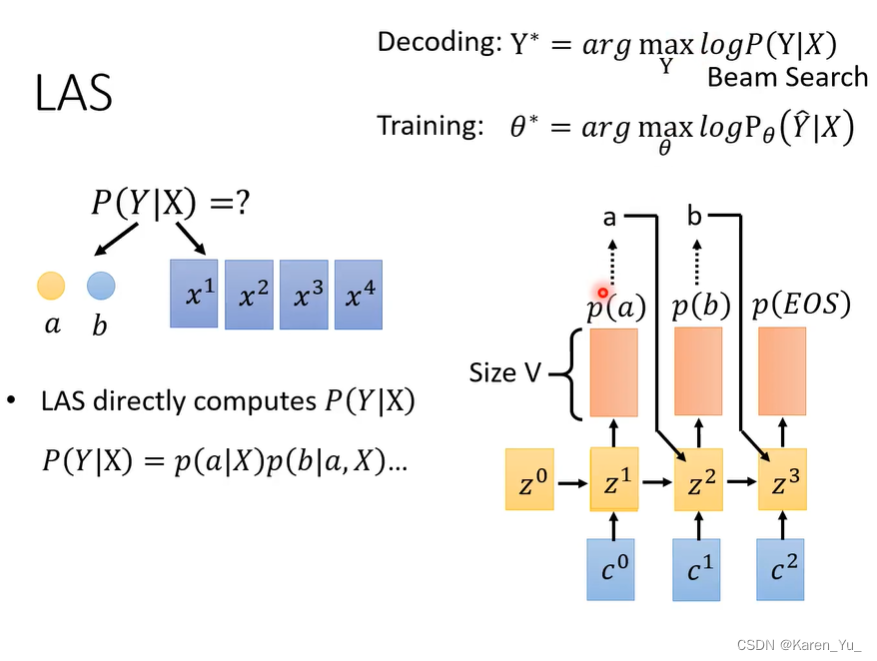
以LAS为例,可以认为LAS可以直接计算P(Y|X)(给一串acoustic feature sequence,产生token sequence的概率)。LAS的decoder,给一个context vector,产生一个probability distribution,给一个声音信号,产生a和b两个token就辨识结束的概率有多少?
先计算第一个distribution产生a的概率,再假设a已经产生出来了,计算第二个distribution产生b的概率,再假设b已经产生出来了,计算第三个是EOS(end of sentence)的概率。把p(a) p(b) p(EOS)乘起来就是产生token sequence的概率。
Y hat:正确答案,在训练的时候看的是正确答案出现的概率(越大越好)
CTC, RNN-T如何计算P(Y|X)

与HMM一样需要alignment。如果要直接计算acoustic feature sequence到token sequence的概率是做不到的,需要先给一个alignment。要计算P(Y|X)就把所有的alignment都取出来,计算acoustic feature产生每一个alignment的概率,再求和。
回忆:
alignment(把短的东西和长的东西对应上)->hidden,我们实际上不知道alignment。->穷举所有alignment,再把每个alignment产生acoustic feature的概率加起来
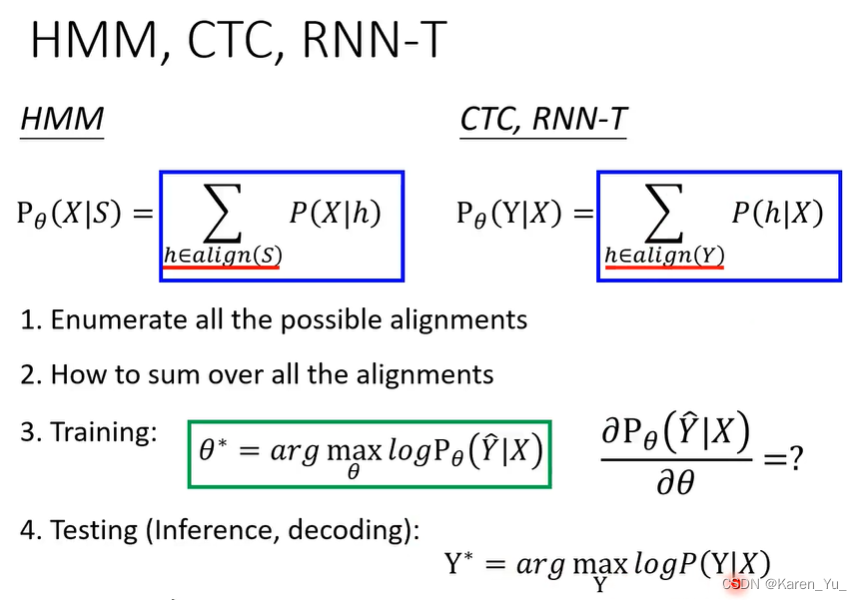
怎么穷举所有可能的alignment?
怎么把所有alignment加起来?
怎么训练?CTC和RNN-T用的是GD,要能计算gradient。
怎么做decoding?
Enumerate all the possible alignments

在举例中,我们假设所有的acoustic feature有6个vector,token sequence有3个token,假设这里都使用字母当做token。
对于HMM,会对c a t分别做一些重复,重复到token sequence的长度与acoustic feature sequence的长度相同。
对于CTC有两个选择,除了做重复之外,还可以加上Φ,知道长度变为T。对于CTC,通过merge重复的token,拿掉Φ,得到最后的语音识别的结果。
对于RNN-T,是加上T个Φ,每output一个Φ的时候,读下一个acoustic feature进来。穷举所有可能的插入的方法。
对于LAS,不存在这个问题。
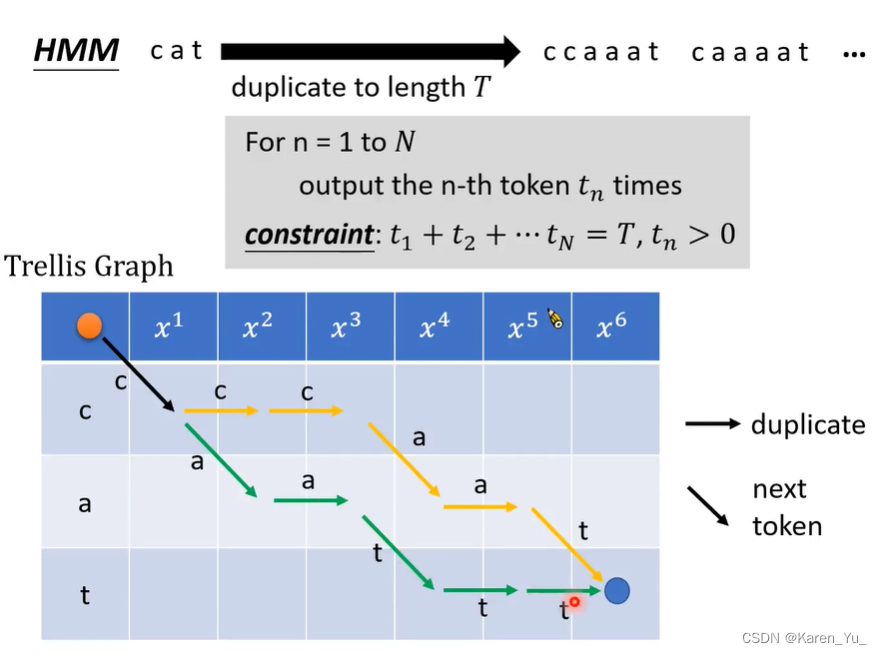
对于现在的N(此时N=3),从1到3,读一个token进来把这个token重复tn次。比如,读进来一个c,把c重复t1次,把a重复t2次,把t重复t3次。限制:重复的次数的和=T,且tn>0(所有的token都必须至少出现一次)。

在表格中的表现就是从左上角走到右下角的一条路径(只能向右、右下角走)。

CTC,多了一个Φ,Φ可以插在开始也可以插在最后。
先输出c0次Φ(在开头也可以放Φ),对每一个token(第1个到第N个)输出tn次,接下来可以选择输出Φ cn次。限制所有token+所有Φ的个数相加=T,且每个token至少出现一次,Φ可以有也可以没有。
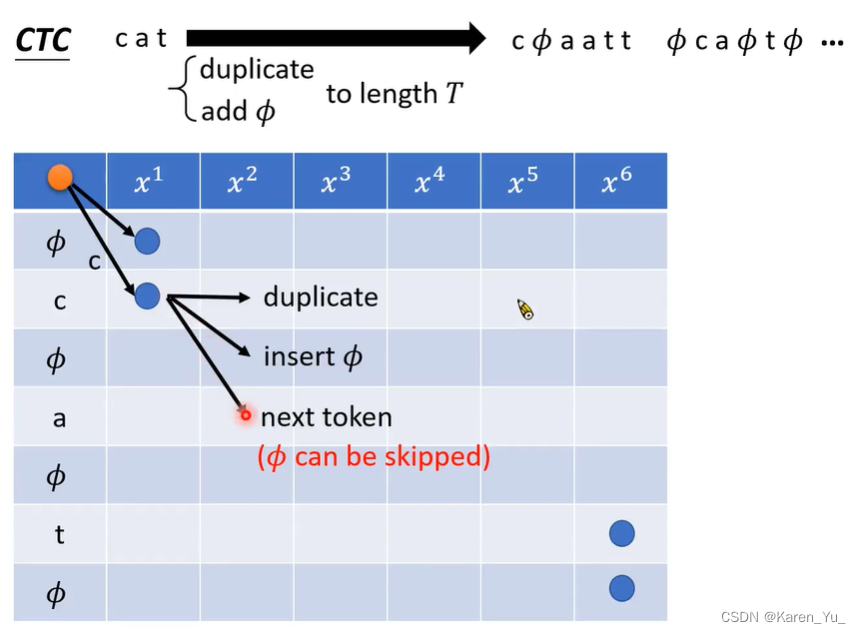
在起始的地方有两个选择,先产生Φor先产生c,接下来有三个选择,重复,插入Φ,跳过Φ直接产生下一个token。

如果前一个是Φ,就只能选择重复或者产生下一个token,不可以跳过token直接产生Φ(这样就漏掉token了)。
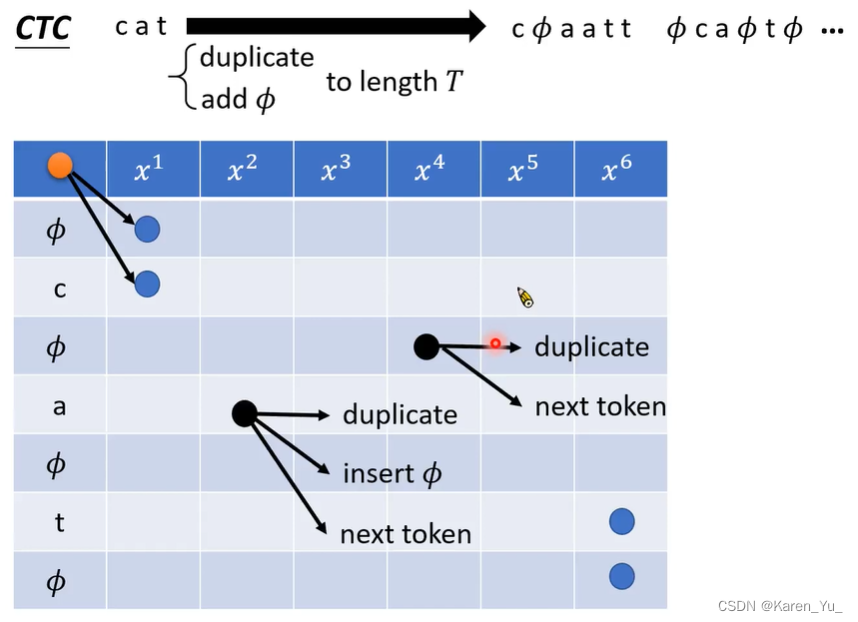
与HMM不同,CTC在不同的行上有不同的走法。
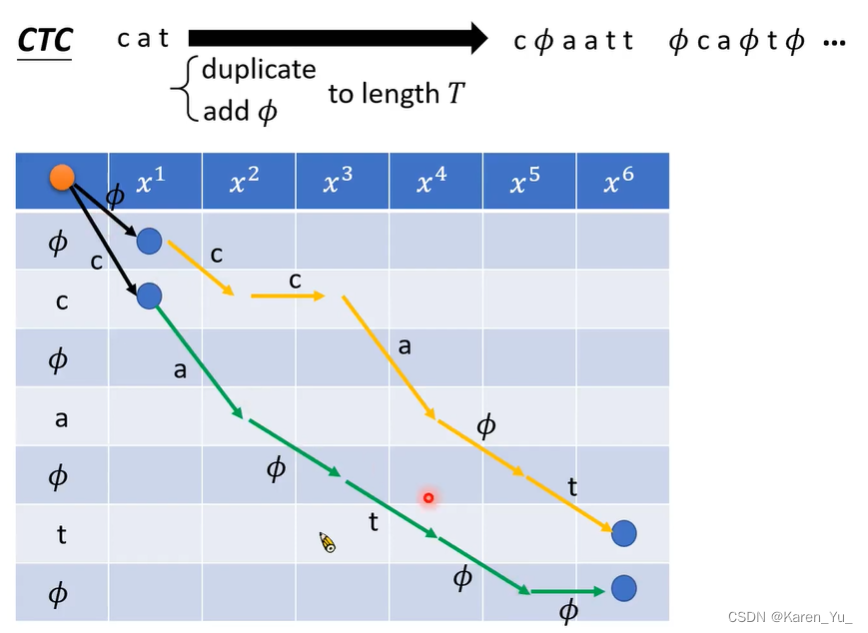
最终一定要走到终点(最后一个token或者最后的token后面再加Φ)。

CTC有一个例外的状况:如果token sequence有连续两个token是相同的,比如这里连续出现两个e,那么走到第一个e就不能直接跳过Φ直接读入下一个token(还是e),因为按照CTC的规则,两个连续的e会被merge。
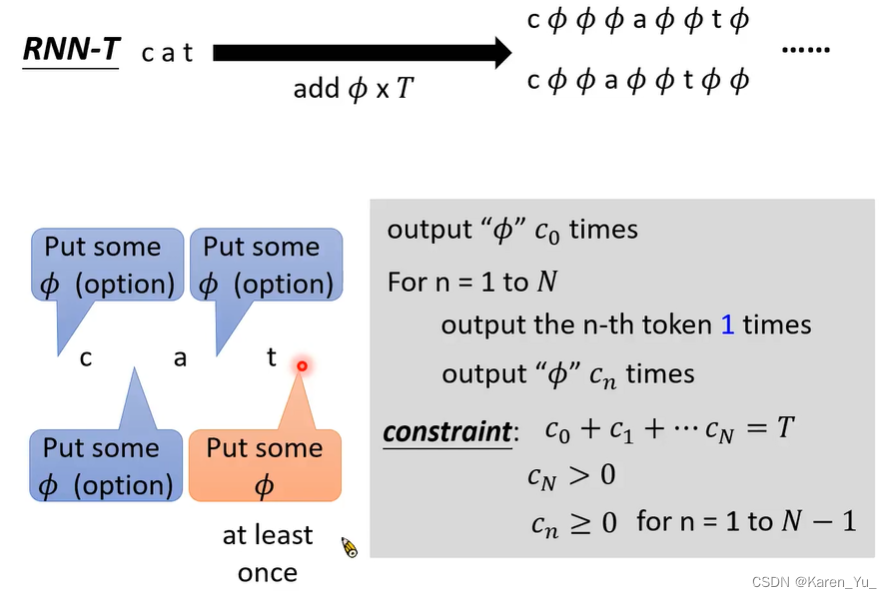
对于RNN-T,要在c a t中间插入T个Φ。要求在最终的token后面一定要插入至少一个Φ,因为插入Φ代表要看下一个acoustic feature,看到Φ才知道要结束。
先输出Φ c0次,再对于1到N,每一个token只输出一次(不可以重复),放Φ,限制:Φ的数量是T,并且最后一个token后面至少要放一个Φ。
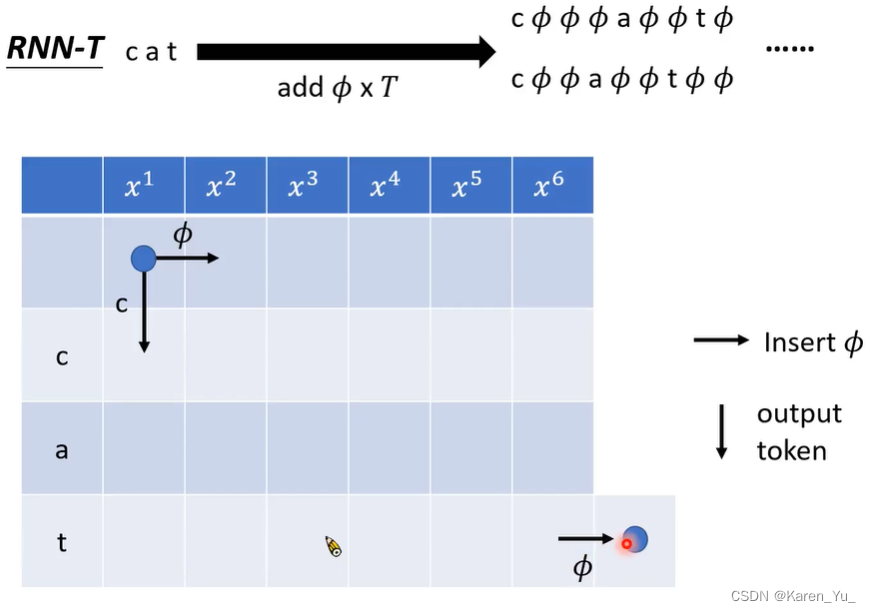
最后多一个角,表示最后一定要产生Φ。

summary

How to sum over all the alignments
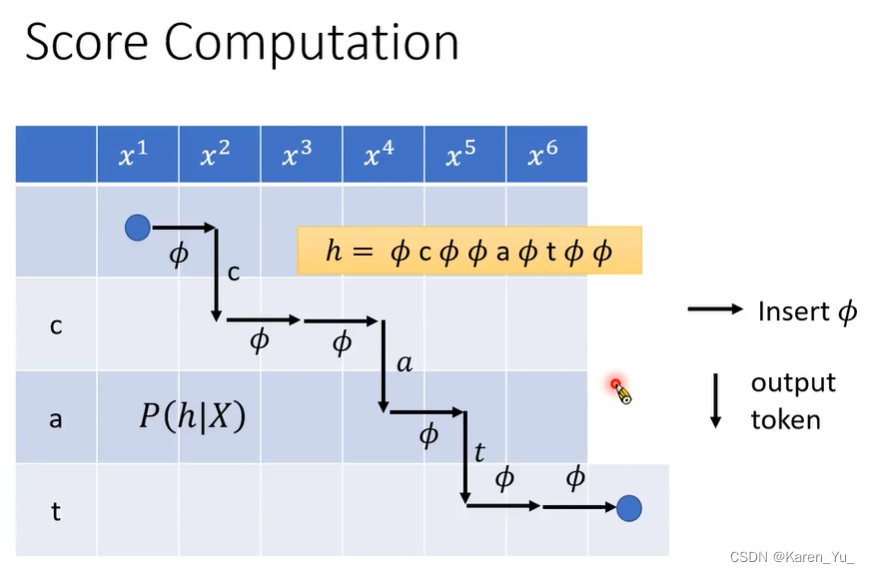
在算所有的alignment之前,我们需要先计算一条路径(一个alignment)的分数。
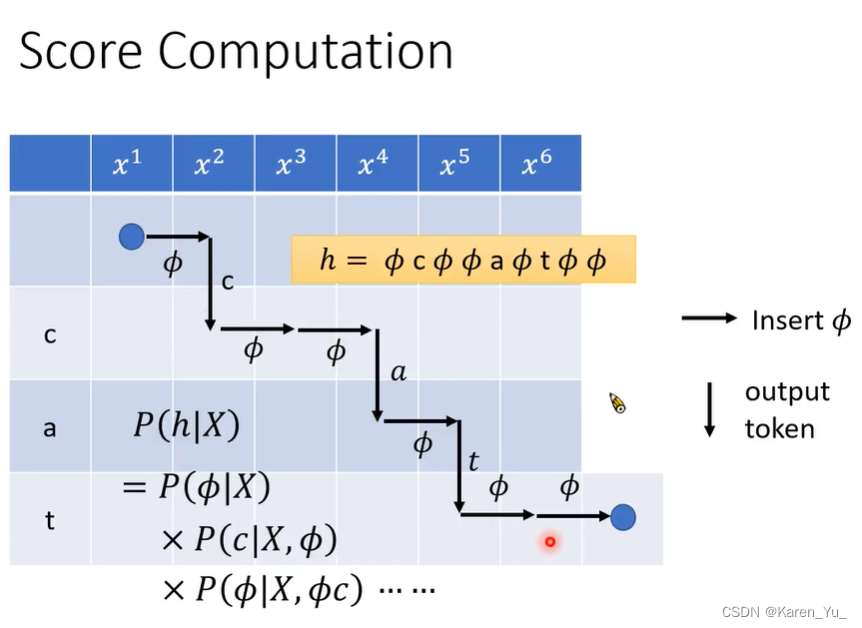
先计算Φ出现在句首的概率P(Φ|X),再计算给了Φ产生c的概率P(c|X,Φ),再计算产生Φ又产生c以后,接下来产生Φ的概率P(Φ|X, Φc)……再把这些概率乘起来,得到alignment的概率。
但是这里的概率怎么计算呢?
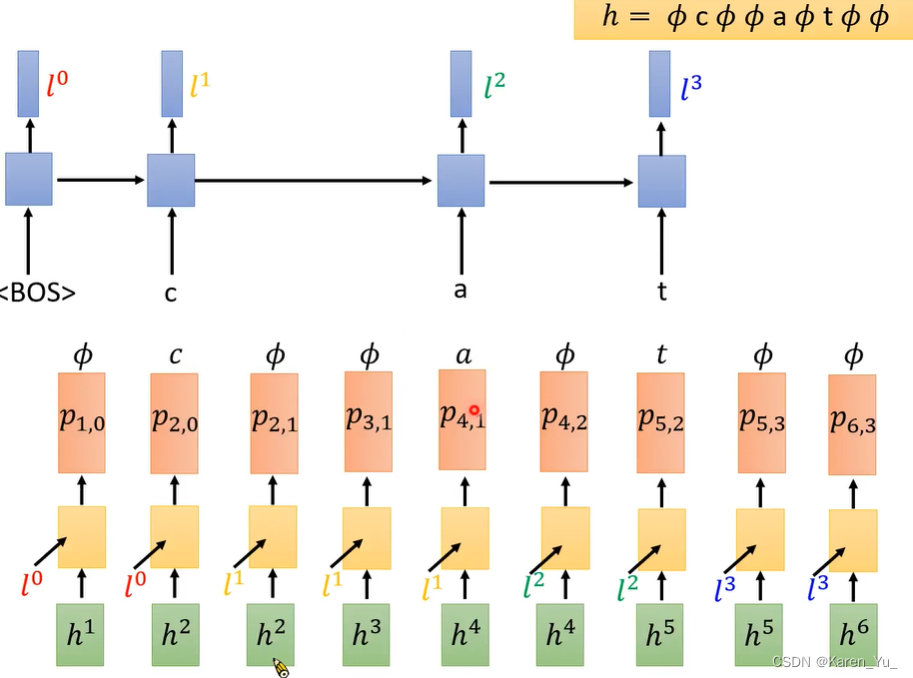
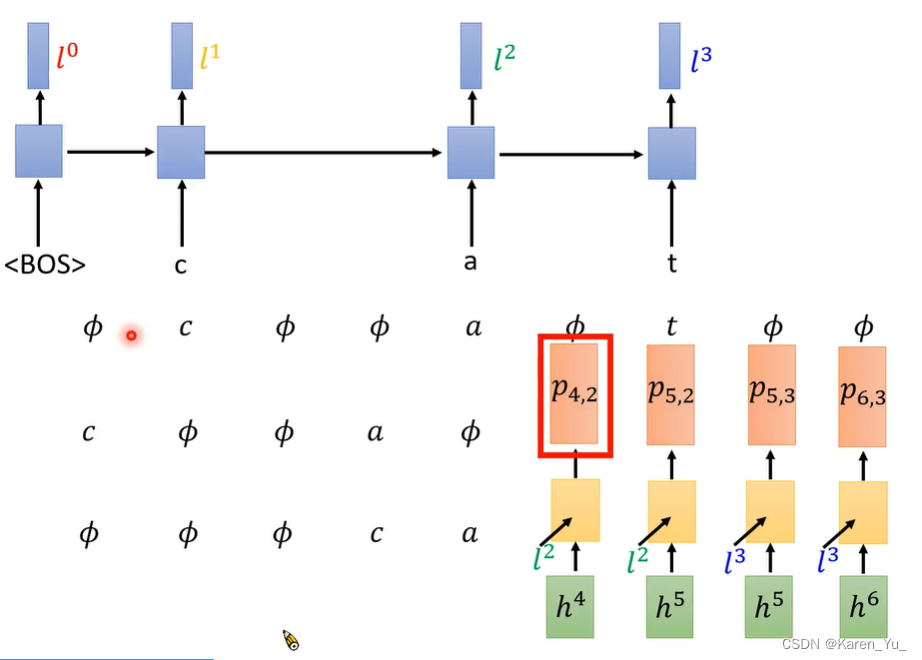
对于RNN-T而言,会先读第一个acoustic feature进来,经过很多层的network,经过很多层的转换之后,得到h1,把h1丢给decoder。
RNN-T另外train了一个RNN,这个RNN会把RNN-T的decoder产生的token当做input,去影响RNN-T接下来的输出。图片左上角的就是这个RNN。在一开始完全没有token,因此先给一个BOS(begin of sentence),产生一个vector l0,代表要开始做事了。
接下来,把从encoder来的h1代表的第一个acoustic feature,以及从RNN产生的l0丢到decoder中,让decoder产生一个probability distribution p1,0(1:h1,0:l0)。看这里产生Φ的概率
接下来,对于RNN,如果下面产生的是Φ,就不用动作。但是encoder这里会改变。decoder产生p2,0(2:h2,0:l0)。
c会影响左上角的RNN,RNN会把c读进去,output就不是l0了,输出l1,encoder的地方依旧是l2。decoder输出p2,1(2:h2,1:l1)。
Φ不影响左上角的RNN,但是会引入一个新的acoustic feature,也就是从encoder那边得到一个新的vector h3,和l1一起产生p3,1(3:h3,1:l1)。
依旧,Φ不会影响左上角的RNN,但是会读入新的vector,h4,产生p4,1,再看产生a的概率。
产生a以后会影响左上角RNN的输出,左上角RNN的输出变为l2,但是因为并不是Φ,所以这里不会读入新的vector,仍然是h4,这里decoder输出p4,2。
产生Φ,左上角RNN不受影响,读入新vector,h5,decoder输出p5,2,计算产生t的概率。
看到t后,RNN会变化,但是由于不是Φ,仍然是h5作为vector输入decoder,同时采用新的l3,输出p5,3。
得到Φ之后,更新vector,h6,最后得到p6,3。
因此,即为Φ在p1,0的概率,乘以,c在p2,0的概率,乘以,Φ在p2,1的概率,乘以,Φ在p3,1的概率,乘以,a在p4,1的概率,乘以,Φ在p4,2的概率,乘以,t在p5,2的概率,乘以,Φ在p5,3的概率,乘以,Φ在p6,3的概率
前面提到RNN-T的特别的地方是,token和token之间的关系独立用另一个RNN表示,而这个RNN不吃Φ。好处:在training的时候会有帮助。
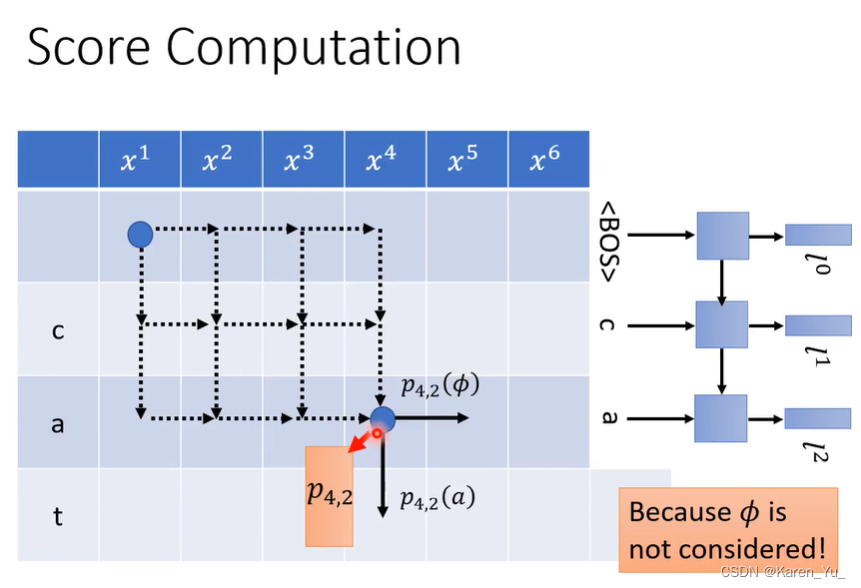
上面每一个格子都对应固定的概率分布,比如右下角的蓝色点代表p4,2,4代表已经读到h4,2代表已经产生出两个token。每一个格子都带有distribution,这个不受到怎么走到格子这里的影响
如图,这里固定要p4,2,但是走到p4,2的路径可以有很多。

那么如何计算所有alignment的总和呢?
HMM采用的是forward-backward algorithm算出所有alignment的分数
αi,j:已经读了i个acoustic feature,并且output了j个token的alignment的分数的和
因此表格中每一个格子都对应一个αi,j
那么怎么计算α4,2呢?α4,2是由α4,1和α3,2算出来的(类似二维DP)
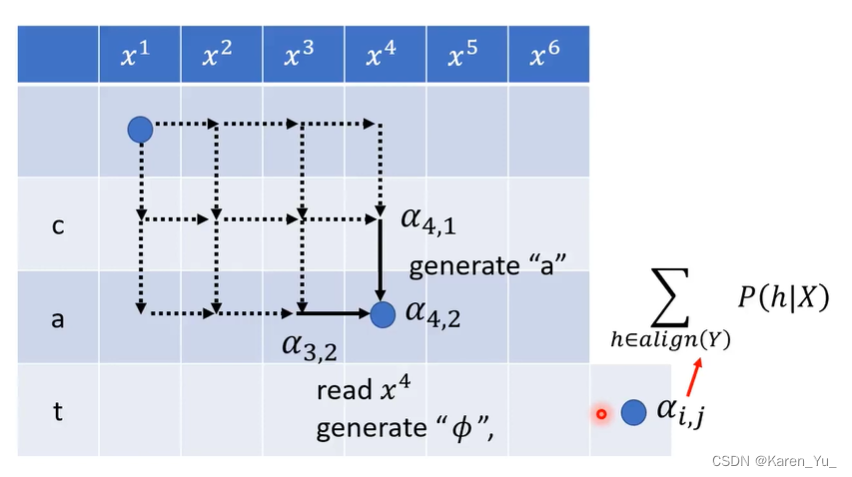
如果可以算出右下角的α值,就能够算出所有alignment的分数的和。
Training
希望learn一个参数使得P(Y hat|X)越大越好。做GD。


表格中每一个箭头都代表一个概率(产生xxx的概率)。
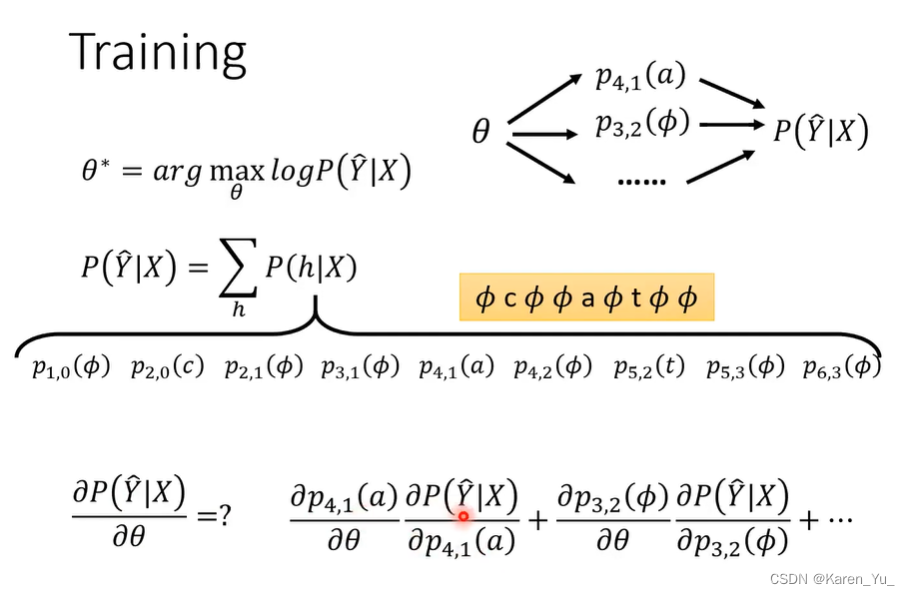

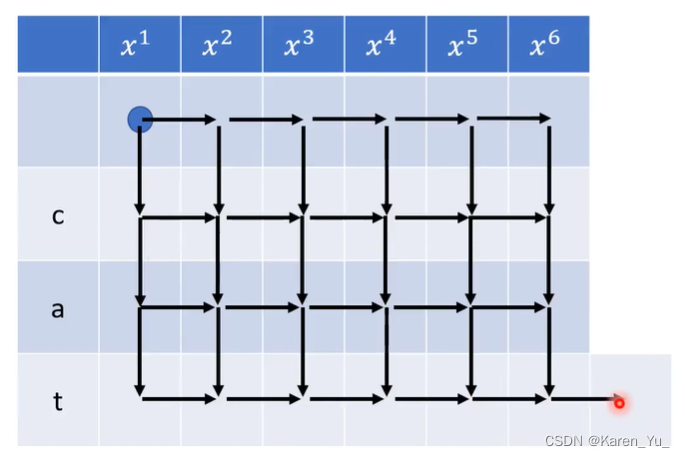
也就是我们需要计算所有通过p4,1的分数和,在这里引入新的概念βi,j

βi,j,如上图所示,表示从第i个acoustic feature和第j个token开始的所有alignment的分数的和
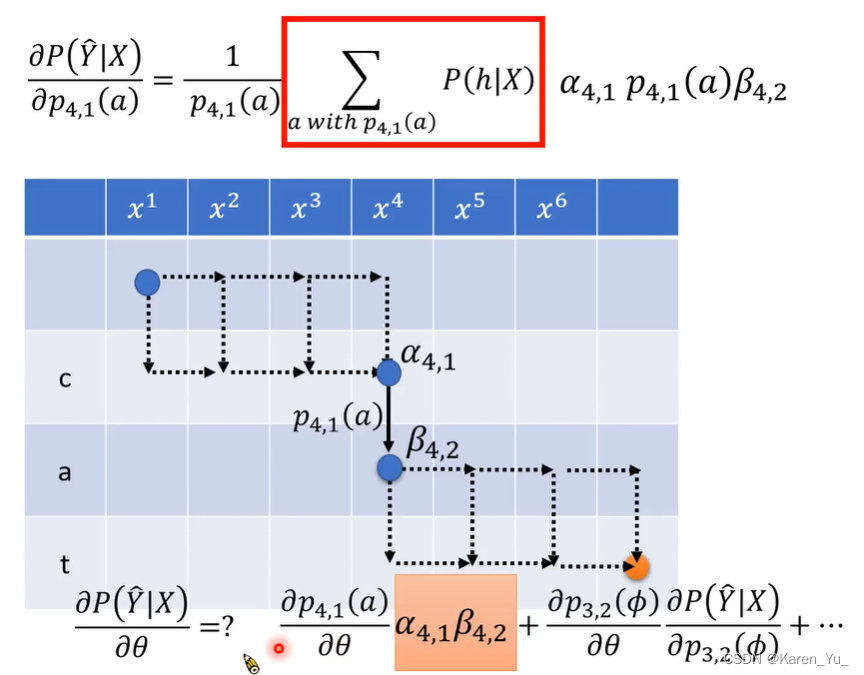
Testing(Inference, decoding)
让P(Y|X)最大的Y就是语音识别的结果。

但是要穷举出所有的Y已经很困难了,理想上我们想找到让所有alignment的分数的和最大的Y,实际上,我们找到的是每个Y分数最多的alignment(用最大分数代表分数和)。

实际操作中,怎么找到概率最大的alignment,假设我们训练好一个RNN-T,每一步RNN-T都会跑出来一个distribution,把每个distribution中概率最大的那个拿出来,得到h*
summary
Language Modeling for Speech Recognition

LM:估计一段token sequence出现的概率。

为什么需要LM?收集难度不同。
N-gram

怎么估测token sequence的概率呢?在DL出现之前,最常用的方法是N-gram。收集大量的文字,然后看这个token sequence出现的概率有多高。但是人类的句子非常复杂,因此随便给一个token sequence在资料中出现的次数可能是0,但是并不代表这种sequence的概率就是0。因此把这个概率拆解成比较小的概率相乘。
上面例子中这种给定一个词汇看下一个词汇出现的概率为2-gram,自然也可以扩展至3-gram,4-gram。

N-gram有什么问题呢?收集的训练资料仍然不够。
Continuous LM

推荐系统。假设某个动画网站,现在有5个使用者在看四部动画,然后一些使用者会给一些动画打分,假设我现在想要给使用者B推荐动画,我们已经知道使用者B曾经给两部动画打过分。可以根据其他使用者的情况推测B会不会喜欢超电磁炮(比如A和C在喜欢凉宫春日的同时也喜欢超电磁炮,那可能推测B也会喜欢)
这里用到的方法叫做matrix factorization,这种方法就是把表格中空着的部分给填上。

那么是否可以把这种方法扩展到LM上呢?
我们现在也构建一个表格,行和列都是词典中所有可能的词汇(token),表格中填写的是在训练资料中,某一个token后面接另一个token出现的次数(比如这里就是dog后面接ran、jumped……的次数)。
在表格中填写0的部分就是在训练资料中没有出现的。
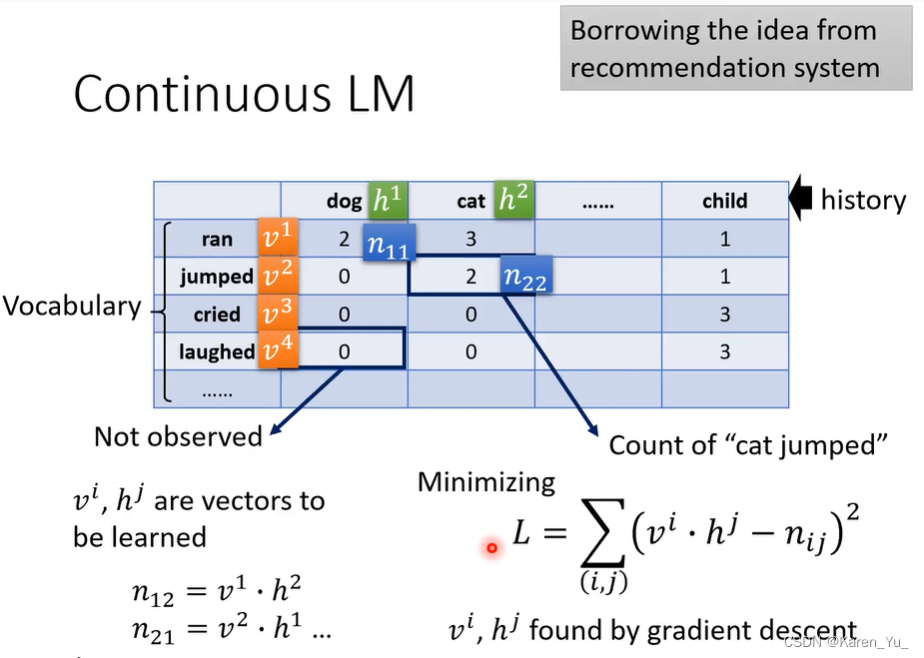
如果我们想要估计这些填0的位置实际上应该填写什么,就可以采用matrix factorization。
每一个词汇都有一个对应的向量,比如这里let dog h1, cat h2,后面接的词也有一个向量,比如ran v1,jumped v2。这里h和v代表词汇的属性。假设表格中的数值用n表示,比如n11,表示h1后面加v1。假设n=v·h(内积)。找出一组v-h让loss越小越好。
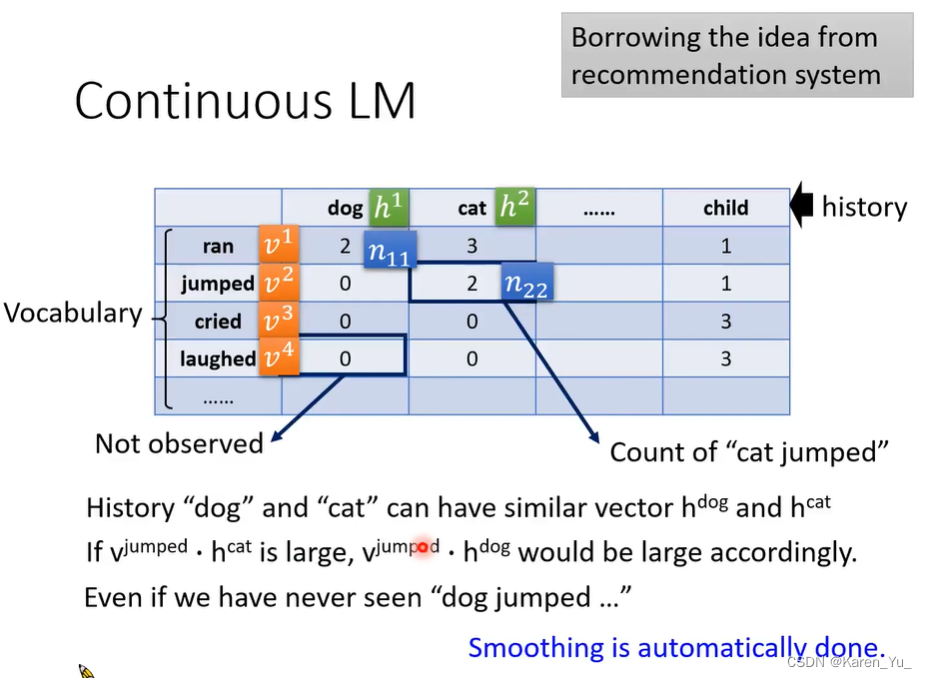

对应到DL,我们输入一个onr-hot vector,只有dog是1,其他都是 0,这样中间的向量输出的就是h^dog。
因此continuous LM可以看做是一个简单的只有一个hidden layer的NN。
既然可以有一层的,当然也就可以拓展到更深的NN。
NN-based LM

最早这一方法是想要取代N-gram LM。预测下一个词汇

有了这一方法就可以取代N-gram。给定之前已经出现的词汇,去预测下一个词汇出现的概率,输出的dimension等于token的size,有几个token,输出就有多大(会给每一个token一个概率)。

RNN-based LM
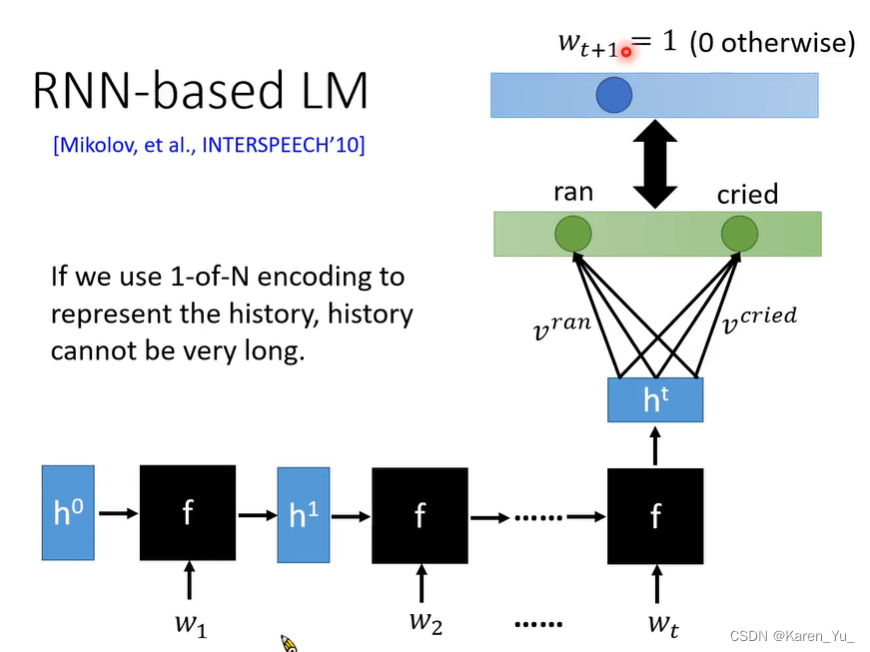
我们可能要看很长的history,来决定下一个word出现的概率,这样我们就有非常长的输入。如果我们不采用RNN,而是使用NN的话,我们就需要非常长的输入(也就需要非常多的参数)。
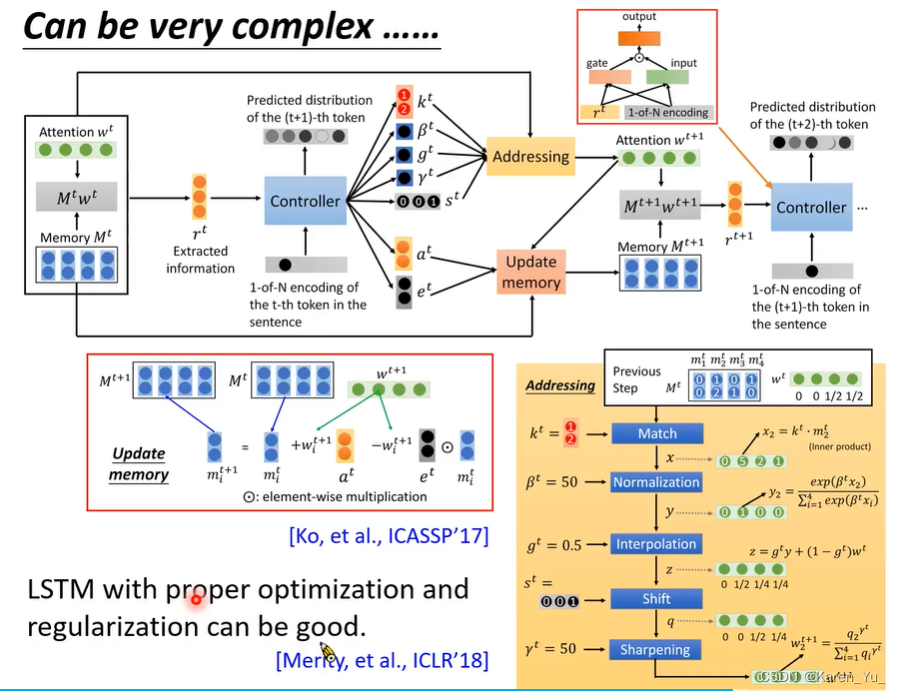
那么怎么和前面介绍的END-TO-END结合起来呢?这里以LAS为例:
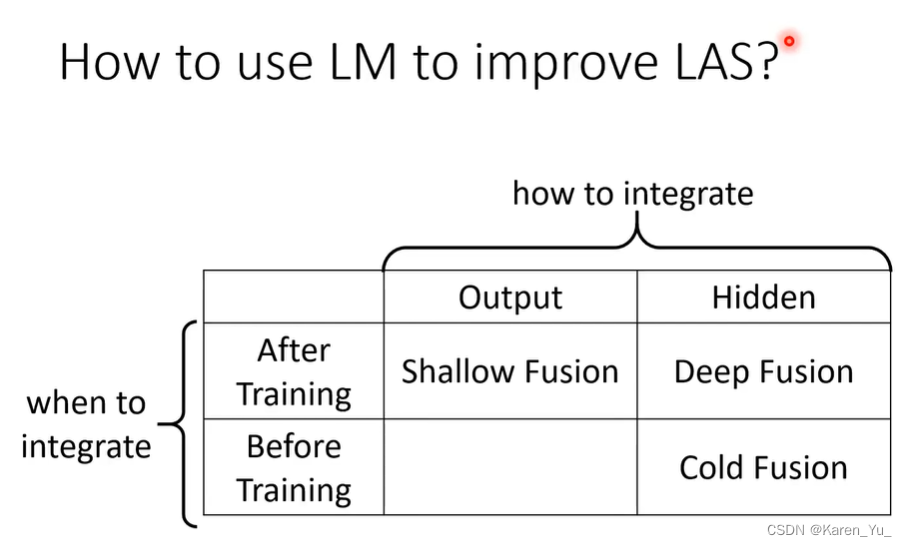
Shallow Fusion

假设我们现在已经有一个训练好的LAS,和一个已经训练好的LM,现在要把两个model结合起来。把两个结果log相加。
Deep Fusion

在hidden layer阶段就把两个结合起来。把两者的hidden layer的输出拉出来,然后接进一个network中,再由这个network决定最终的output。这里用到的network还需要继续训练(之前两个已经训练好的前提下,仍然需要再喂数据)。
这会造成一个问题,我们不能随意改变LM,每次改变都需要重新训练。
什么时候回牵涉到要换LM呢?当更换domain的时候。
很多词汇的发音是一样的。但是不同的领域有比较特定的词(比较好理解的是积分,可以是微积分的积分也可以是商场买东西的积分,如果在商场场景当然就不可能用数学里的积分了)。
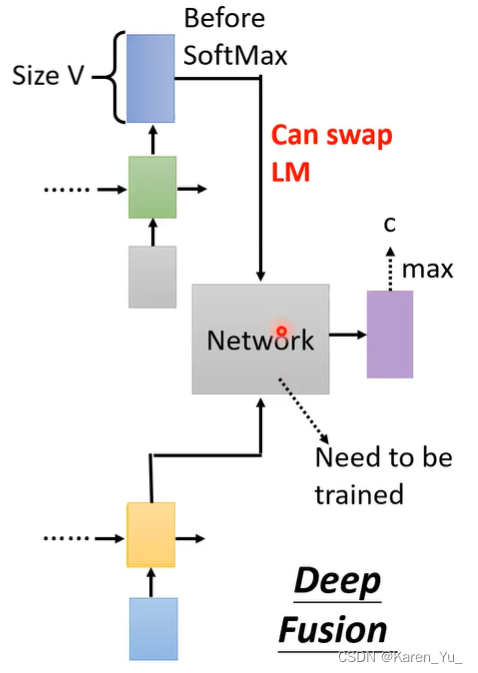
这里为了解决这个问题,可以采用不直接把LM的hidden layer接进去,而是跑到最后(softmax前),得到一个dimension和token的size一样大的向量,把这个向量丢到network里去。
Cold Fusion
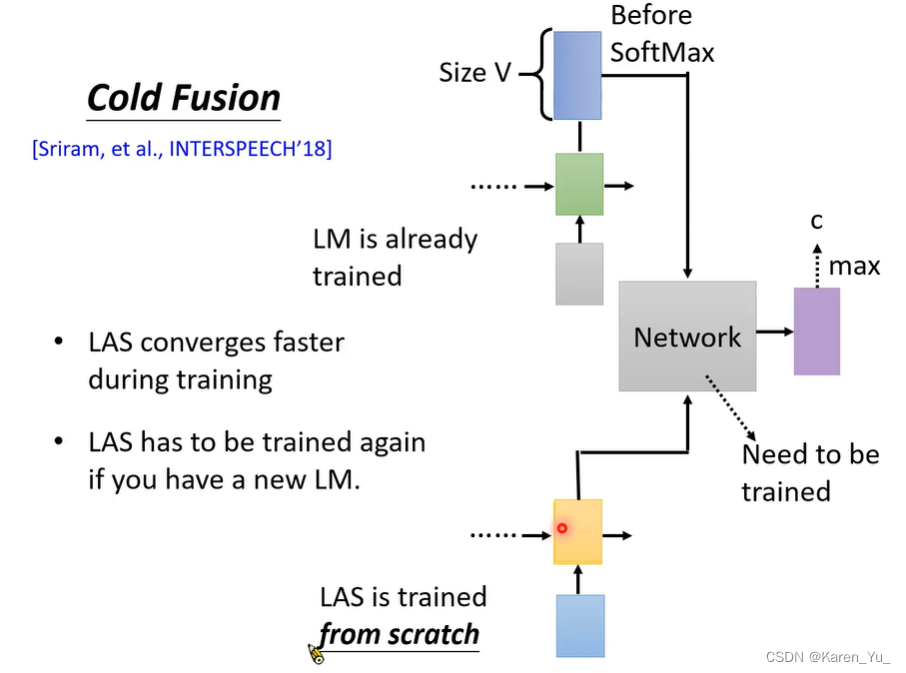
先有一个已经训练好的LM,和一个还没有开始训练的LAS(这时候参数还是random initialize的)。先把这两个model接在一起,再end-to-end训练。这样可以更快的训练LAS。
这个时候LAS只需要考虑声音和文字之间的关系,至于文字和文字之间的关系就依赖LM了,这个时候当然也不能随意换LM。

