
- 1【机器学习】人力资源管理的新篇章:AI驱动的高效与智能化_机器学习人力资源
- 2基于Android的美团外卖_android仿美团外卖
- 3人工智能与人机交互:如何提高效率和用户体验
- 4使用SSH在github或者gitlab上配置多个账户_gitlab配置多个ssh
- 5Linux安装Jenkins结合内网穿透实现远程访问测试软件_jenkins局域网内网访问另一台电脑
- 6测试你的逻辑推理能力1_艾斯曼德的逻辑题
- 7代购集运系统平台一键上传淘宝商品至韩国coupang经验分享_淘宝能上传韩语图片吗
- 8HBase常用命令(超全超详细)_hbase命令
- 9python redis_Python操作Redis缓存数据库
- 10java bufferedimage_5分钟!用Java实现目标检测 | PyTorch
VALSE 2024 Tutorial内容总结--开放词汇视觉感知
赞
踩
视觉与学习青年学者研讨会(VALSE)旨在为从事计算机视觉、图像处理、模式识别与机器学习研究的中国青年学者提供一个广泛而深入的学术交流平台。该平台旨在促进国内青年学者的思想交流和学术合作,以期在相关领域做出显著的学术贡献,并提升中国学者在国际学术舞台上的影响力。
2024年视觉与学习青年学者研讨会(VALSE 2024)于5月5日到7日在重庆悦来国际会议中心举行。本公众号将全方位地对会议的热点进行报道,方便广大读者跟踪和了解人工智能的前沿理论和技术。欢迎广大读者对文章进行关注、阅读和转发。文章是对报告人演讲内容的理解或转述,可能与报告人的原意有所不同,敬请读者理解;如报告人认为文章与自己报告的内容差别较大,可以联系公众号删除。
5月6日的VALSE 2024会议主要内容包括2个Tutorial和10个Workshop。
2个Tutorial:在这两个Tutorial中,来自中山大学的李冠彬教授、浙江大学的彭思达研究员和香港中文大学的韩晓光教授呈现了3个报告,分别为《开放词汇视觉感知》、《NeRF的基础及后续扩展》和《3GDS, 三维重建的终点吗?》。
10个Workshop: 这些Workshop涵盖了从视觉大模型的高效迁移、因果推断与机器学习的深入研究,到三维重建与内容生成技术的实际应用,以及大模型在智慧医疗中的创新应用。还讨论了智能算法的安全性与伦理问题、生成式模型在艺术智能中的应用,具身智能的新研究进展,以及视频生成技术和移动终端上的AI图像增强技术的最新发展。此外,还讨论了海洋多模态计算的挑战与机遇。这些讨论不仅展示了技术的多样化应用,还强调了科研在推动技术前沿和解决实际问题中的核心作用。
本文主要对来自中山大学的李冠彬教授所做的Tutorial《开放词汇视觉感知》进行介绍。
1.报告人简介
李冠彬,中山大学计算机学院副教授,博士生导师,国家优秀青年基金获得者,主要研究领域为跨模态视觉感知、理解与生成。
2.开放词汇视觉感知的基本概念
开放词汇视觉感知是计算机视觉领域中的一个重要概念。它指的是一种允许计算机视觉系统在面对新的物体或场景时,能够自我更新并学习到新的标签的方法。这种方法通过构建一个可扩展的标签集合(即开放词汇),使系统能够更好地适应现实世界的多样性。在视觉感知的过程中,计算机视觉系统首先通过视觉感知器官(如摄像头)获取图像信息,然后对这些信息进行处理和分析,以实现对图像中物体的准确定位和识别。开放词汇视觉感知的引入,使得计算机视觉系统能够处理更广泛、更复杂的场景,提高了系统的适应性和准确性。
3.内容整理
李冠彬教授从开放词汇的分类、检测、分割、下游任务应用和多模态大模型这几部分展开讲述。
(1)开放词汇的分类
开放词汇的分类方式使得机器学习模型或计算机视觉系统能够更好地适应现实世界的多样性,提高模型的泛化能力和适应性。在实际应用中,开放词汇的分类可以应用于多个领域,例如:
1)自然语言处理(NLP):在NLP任务中,开放词汇可以帮助模型处理和理解新的词汇、短语和表达方式。例如,在情感分析任务中,模型可以学习新的情感词汇,以便更准确地识别文本中的情感倾向。
2)计算机视觉:在计算机视觉任务中,开放词汇可以用于描述图像中的物体、场景和事件。通过不断学习和更新标签集合,模型可以更好地识别和理解图像中的新内容。
3)语音识别:在语音识别任务中,开放词汇可以帮助模型识别新的语音词汇和表达方式。这对于处理口音、方言和非标准发音等复杂情况非常重要。
(2)开放词汇的检测
开放词汇的检测是一种先进的技术,特别是在计算机视觉领域。它的主要目标是使机器能够识别并定位图像中那些未在训练集中出现过的新类别的物体。这种技术对于机器人技术、自动驾驶等领域具有重要的应用价值。传统的目标检测方法通常依赖于一个固定的、预定义的标签集合,这限制了它们识别未在训练集中出现过的新类别物体的能力。而开放词汇检测技术的出现,克服了这一限制。它利用深度学习和自然语言处理等技术,通过在大规模数据集上预训练模型,并结合视觉和语言信息,使得模型能够识别并定位出图像中的新类别物体。具体来说,开放词汇检测技术可能会采用一些创新的方法,如YOLO-World等。YOLO-World的架构见图1,更多的介绍读者可以下载论文进行阅读,论文下载地址https://arxiv.org/abs/2401.17270。
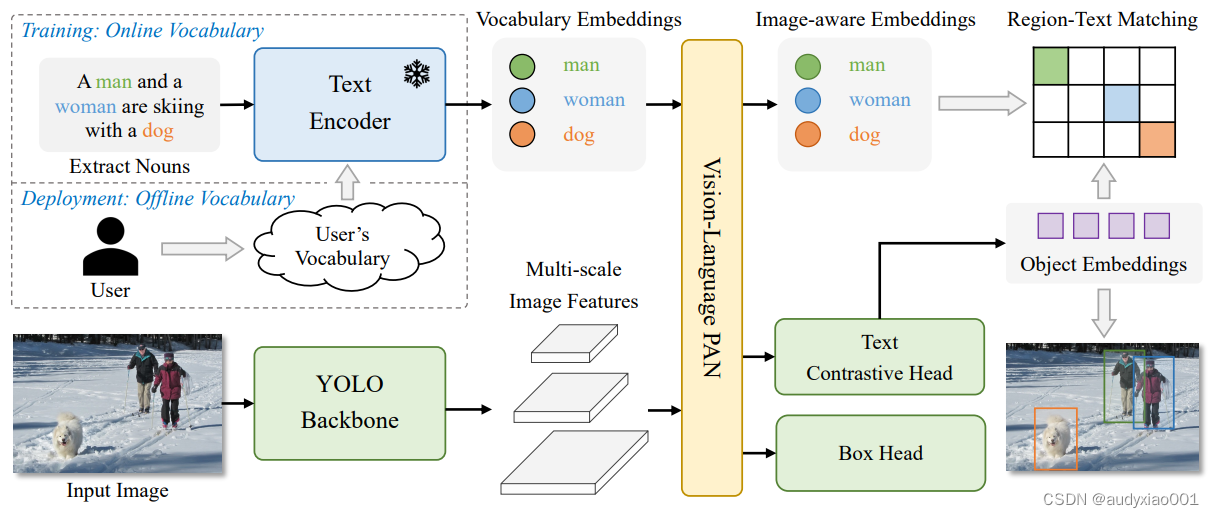
图 1 YOLO-World的架构
(3)开放词汇的分割
开放词汇的分割主要指的是一种处理文本或图像数据的方法,旨在将连续的文本序列或图像中的物体切分成独立的词汇单元或类别。与传统的封闭词汇分割方法不同,开放词汇分割方法能够处理未在训练数据中出现过的类别,因此具有更强的适应性和灵活性。开放词汇分割方法的优点在于它能够处理大量的类别,而不需要对每个类别进行单独的训练。此外,这种方法还可以利用预训练的模型来提高分割的准确性和效率。例如,CLIP(Contrastive Language-Image Pre-Training)模型就是一个常用的预训练模型,它通过在大量图像和文本数据上进行训练,学习到了丰富的视觉和语义信息,可以用于支持开放词汇分割任务,如图2所示。CLIP论文链接:https://arxiv.org/abs/2103.00020。
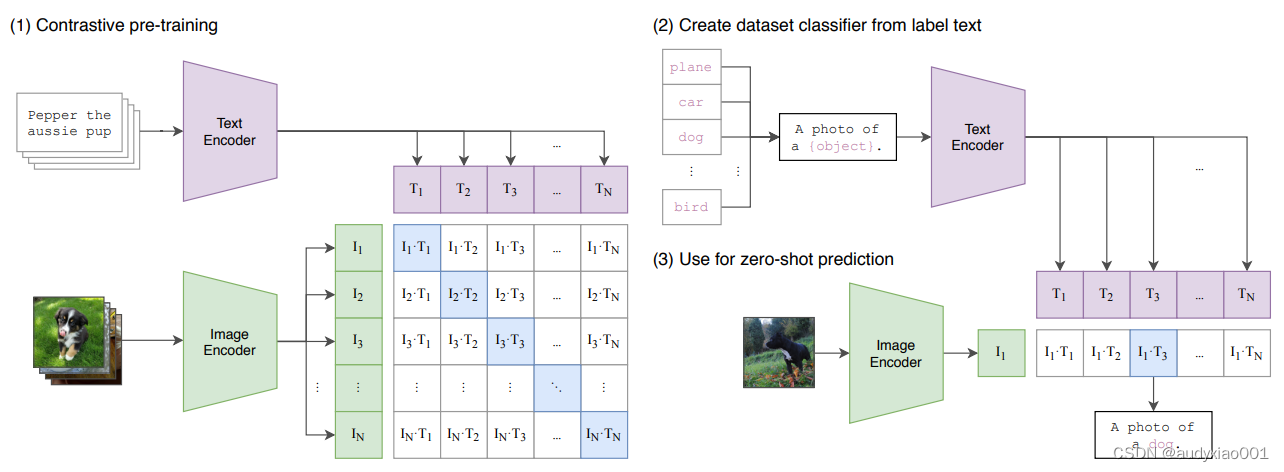
图 2 CLIP方法的基本原理
(4)下游任务中的应用
开放词汇视觉感知在下游任务中的应用中展现出了强大的潜力和实用性。它使得计算机视觉系统能够识别和理解现实世界中更多样化、更复杂的场景和物体,为自动驾驶、智能安防、机器人导航等领域提供了更精准、更灵活的视觉处理能力。通过不断学习和适应新的视觉词汇,这些系统能够更好地满足实际应用的需求,推动人工智能技术的进一步发展。
(5)多模态大模型
多模态大模型是一种强大的深度学习架构,它能够整合和处理来自不同模态的信息,如文本、图像、音频和视频等。结合开放视觉感知,多模态大模型不仅能够分析已知的图像类别,还能学习并识别那些未在训练集中出现过的新视觉词汇。这种跨模态的学习能力使得多模态大模型在智能安防、自动驾驶、机器人导航等领域具有广泛的应用前景,能够提供更全面、更准确的视觉感知和决策支持。

