
- 1【数据结构】 实验报告13 各排序算法时间性能比较_给出一组实验来比较排序算法的时间性能。作业报告必须。 (九种数据结构的排序算法
- 2如何使用Android平板公网访问本地Linux code-server_平板连接linux服务器
- 3【LSTM分类】基于麻雀算法优化长短期记忆神经网络SSA-LSTM的数据分类预测附matlab代码 标准_lstm神经网络数据分类模型 性能指标
- 4【JEECG技术文档】数据权限自定义SQL表达式用法说明_jeecg自定义数据表达式
- 5华为OD机试真题 C++ 实现【ABR 车路协同场景】_abr 车路协同场景c++
- 6旭日X3派BPU部署教程系列之手把手带你成功部署YOLOv5_yolov5 cpu端后处理代码
- 72024年大数据最全Hadoop大数据集群搭建(超详细)_hadoop集群搭建,快速从入门到精通_hadoop集群搭建完整教程
- 8【华为OD机试】2024年真题C卷(Python)-掌握单词的个数_有一个字符串数组 words 和一个字符串 chars. 假如可以用 chars 中的字母拼写出 w
- 9通过控制台获取Android app签名的sha1值_浏览器控制台看签名算法
- 10机器学习中的九种距离公式(欧式距离,曼哈顿距离,切比雪夫距离,闵可夫斯基距离,标准化欧氏距离,余弦距离,汉明距离,杰卡德距离,马氏距离)_欧式距离是曼哈顿距离吗
Exploring Visual Prompts for Adapting Large-Scale Models
赞
踩
目录
2.1Natural Language Prompting(自然语言提示)
2.2 Prompting with Images(图像提示)
2.3 Adversarial Reprogramming and Unadversarial Examples(对抗性重编程和非对抗性例子)
2.4 Adapting Pre-trained Models in Vision(在视觉中调整预训练模型)

代码:https://hjbahng.github.io/visual_prompting
动机:看到prompting在NLP领域变得越来越火,作者提出问题:Why not visual prompting?为证明在CV领域,Prompt是可行的,并且在某些任务和数据集上效果不错。也就是说本文目的是想证明visual prompting的有效性。
方法:使用预训练模型的方法(迁移),在CV中,将一个预训练模型迁移到新任务上的方法主要包括Fine-tuning,Linear Probe,Visual Prompting。 Fine-tuning会修改预训练模型参数,Linear Probe不会修改预训练模型参数,但是会在预训练模型后增加和任务相关的线性层,Visual Prompting则是不修改预训练模型参数,只修改原图像。
论文原文翻译
摘要
我们研究了视觉提示(visual prompting)对大规模视觉模型的适应性。根据最近的从prompt tuning和adversarial reprogramming(对抗性重编程)的方法,我们学习了一个单一的图像扰动,这样一个被该扰动提示的冻结模型执行一个新的任务。通过综合实验,我们证明了视觉提示对CLIP尤其有效,并且对分布迁移具有鲁棒性,达到了与标准线性探测方法(Linear probes)相竞争的性能。我们进一步分析了下游数据集、提示设计和输出转换的特性,以适应性能。视觉提示的惊人效果为适应预训练的视觉模型提供了一个新的视角。
迁移学习是将前一项任务中获得的知识为基础来学习如何执行另一项任务,同时可以任意更改模型参数。而重编程只能通过操纵输入来改变模型。
1.简介
当我们人类学习一项新任务时,我们倾向于从我们现有的知识基础开始并进行推断。一个开始说话和理解句子的孩子很快就能发展出分析句子所包含的情感语境的能力。例如,“I missed the school bus”这句话承载了一种特定的情感,如果后面跟着“I felt so [MASK]”,小孩就能提供一个适当的情感词。这种范式被恰当地命名为提示,最近在NLP中得到普及,通过将下游数据集转换为预训练任务的格式,使大型预训练的语言模型适应新任务。在不更新任何参数的情况下,语言模型使用其现有的知识库在提供的提示中填写掩码,从而成为新任务的专家。目前,提示方法主要是NLP特定的,尽管该框架有一个通用的目的:通过修改数据空间来适应一个冻结的预训练模型。考虑到通用性,我们能否以像素的形式创建提示符?广义上,我们能否通过修改像素空间来引导冻结的视觉模型来解决新的任务?
对抗性重编程是一类对抗性攻击,其中输入扰动重新利用模型来执行对手选择的任务。尽管有不同的术语和动机,这种输入扰动本质上是作为一个视觉提示——它通过修改像素使模型适应新的任务。然而,现有的方法专注于对抗性目标,或在相对小规模的数据集和模型中应用有限。对抗性重编程和提示起源于不同的领域(communities),但它们有一个共同的思想:通过转换输入(即提示工程)和/或者输出(即回答工程,answeer engineering)执行数据空间适应(data-space adaptation b)。
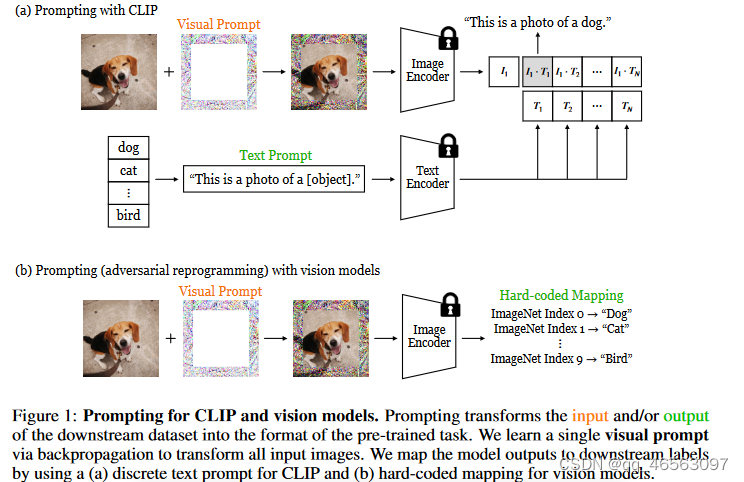
受自然语言提示成功的启发,我们旨在研究视觉提示对规模视觉模型的适应性。由于像素空间本身是连续的,我们遵循最近的方法,将提示作为连续的特定于任务的向量。我们通过反向传播在模型参数冻结的情况下学习单个图像扰动(即“soft prompt”)。通过使用CLIP的离散文本提示和视觉模型的硬编码映射,我们将模型输出映射到下游标签(图1)。
视觉提示与现有的适应方法有何不同?目前在视觉领域,标准的适应方法是fine-tuning和线性探测。这两种方法都需要对模型进行某种level的访问:在fine-tuning的情况下是整个参数,在线性探测的情况下是模型输出(通常在倒数第二层激活)。相比之下,视觉提示使输入适应模型。在获得可视化提示之后,它在测试时不需要访问模型。这打开了独特的应用程序;输入空间自适应将控制权交给了系统的最终用户。例如,行人可以佩戴一个视觉提示,提高他们对汽车的可见度,而无需接触汽车本身或汽车的视觉系统。
我们通过4个预训练的模型和15个图像分类数据集进行了综合实验。我们证明了视觉提示对于CLIP是惊人的有效的,并且对分布迁移具有鲁棒性,实现了与标准线性探针竞争,有时甚至超过标准线性探针的性能。我们进一步分析了下游数据集、提示设计和输出转换的哪些属性会影响性能。请注意,我们的目标不是在特定任务上达到最先进的性能,而是广泛地探索视觉适应的新范式。视觉提示的惊人效果为如何适应和使用预先训练的视觉模型提供了一个新的视角。
2.相关工作
2.1Natural Language Prompting(自然语言提示)
(动机)我们的调查灵感来自于最近自然语言提示的成功。NLP中的提示将下游数据集重新表述为(masked)语言建模问题,以便冻结的语言模型直接适应新的任务,不需要更新任何参数。提示包括构造一个特定于任务的模板(例如,“I felt so [MASK]”)和标签词(例如,“happy/ terrible”)来填充空白。然而,手工制作正确的提示符需要领域的专业知识和大量的努力。
前缀调优或提示调优通过反向传播学习“soft prompt”来缓解这个问题,同时固定模型参数。前缀调优学习特定于任务的连续向量(即前缀),该向量允许语言模型适应各种生成任务。前缀调优为每个编码器层预先准备前缀,而提示调优通过仅为输入预先准备可调tokens来进一步简化。当应用于具有数十亿参数的大型模型时,经过适当优化的提示可以实现有竞争力的性能,从而微调整个模型,同时显著减少内存使用和每个任务存储。由于像素空间中的提示本质上是连续的,我们遵循这条工作线并直接优化像素。
2.2 Prompting with Images(图像提示)
已经有了尝试用图像进行提示的初步方法。与前缀调优类似,Frozen通过使用来自冻结语言模型的梯度训练视觉编码器来创建图像条件提示符。图像被表示为来自视觉编码器的连续embedding,并用作视觉前缀,以允许冻结的语言模型执行多模态任务。CPT通过使用彩色块和基于颜色的文本提示创建可视化提示,将视觉的基础转换为填空问题。然而,这两种方法都关注于扩展基于语言的模型的功能。另一方面,我们重点研究了提示对视觉表示和图像分类数据集的有效性。换句话说,我们假设预先训练的模型包含一个视觉编码器,并专注于重新制定图像数据集。视觉提示调优是针对Vision Transformers提出视觉提示的并行工作。它通过在每个Transformer编码器层预先设置一组可调参数来使用深度提示调优。
2.3 Adversarial Reprogramming and Unadversarial Examples(对抗性重编程和非对抗性例子)
β是一种对抗性攻击,其中一个单一的class-agnostic(类无关)的扰动重编程一个模型,以执行攻击者选择的新任务。尽管该框架的目标是对抗的,但其本质上与提示的目的相同:通过修改下游数据集的输入和/或输出,使冻结的模型适应新任务。然而,现有的视觉方法的设计目的是实现对抗目标,或证明在小规模视觉模型和简单数据集上的应用有限。类似地,非对抗性示例旨在提高(预)训练任务的性能。它学习一种图像扰动,可以提高特定类(即类-条件)的性能。在我们的工作中,我们重新探讨了对抗性重编程作为视觉提示的一种形式,并研究了它在适应大规模视觉模型中的有效性。
2.4 Adapting Pre-trained Models in Vision(在视觉中调整预训练模型)
图2提供了调整预训练模型的不同方法的总结。微调和线性探测在使用上非常灵活:它们可用于使模型适应新的输入领域或具有不同输出语义的新任务。然而,它们也需要对模型的某种level的访问:在微调的情况下是参数,在线性探测的情况下是模型输出(通常在倒数第二层激活)。域自适应是模型自适应的一种有趣的替代方法,因为它只使用图像到图像的转换等技术修改模型的输入。与域适应一样,视觉提示也修改模型的输入。因此,一旦最终用户找到了可视化提示,它就不需要在测试时控制模型本身。这开启了独特的应用;例如,用户可以将域适应的图像提供给在线APIs,这些API只能通过用户的输入进行操作。域适应的重点是使源域看起来像目标域,需要源和目标数据集都可用。另一方面,我们证明了视觉提示可以以更任意的方式引导模型;例如,一个执行一个分类任务的模型可以调整为执行一个完全不同的分类任务,使用新的输出语义,只需要扰动输入像素。此外,尽管域适应方法通常是有输入条件的,但我们在本文中探讨的视觉提示在整个数据集中是固定的(即输入不可知的),就像在NLP中一样,相同的自然语言提示被添加到所有模型查询中。

(a)微调整个模型参数。(b)线性探针通过学习线性层来适应模型输出(通常在倒数第二层激活)。(c)提示通过重新制定输入和/或输出来调整(下游)数据集。
在CV中,将一个预训练模型迁移到新任务上的方法主要包括Fine-tuning,Linear Probe,Visual Prompting
3.方法
在不同的术语下,提示重编程和对抗性重编程的目的是相同的:数据空间适应。它们通常包括两个阶段:输入转换和输出转换。输入转换(或提示工程)的目标是设计一个适当的提示,指定应用于输入的任务。输出转换(或答案工程)的目标是将模型的输出/答案映射到目标标签。我们根据视觉和视觉语言模型的预训练任务,介绍了不同的设计选择。
3.1预训练模型
像素形式的提示基本上可以应用于任何视觉表示。因此,我们选择了三种视觉模型和一种视觉语言模型:Instagram-预训练的ResNeXt (Instagram)、Big Transfer (BiT-M)、在ImageNet-1k (RN50)上训练的ResNet和CLIP。视觉模型被训练来预测一组固定的预先确定的类,通常需要学习一个单独的层来预测不可见的类。相比之下,CLIP是一个视觉语言模型,它能够使用文本提示灵活地向不可见的类执行zero-shot传输。我们在附录中总结了预训练的模型细节。我们在不同的输入模式、预训练的数据集大小和模型架构中选择模型,以评估视觉提示的实际效用。对于instagram预训练的ResNeXt,我们使用在ImageNet-1k上额外微调的模型。
3.2输入转换
有几种方法可以设计视觉提示。由于像素空间与自然语言相比不那么离散,因此很难像NLP中那样手工制作提示(例如,用于图像分类的“a photo of a [LABEL]”)。事实上,目前尚不清楚什么类型的视觉上下文对每个下游任务有用(例如,什么视觉信息对指定卫星图像分类有用?)。直观地说,视觉提示不一定需要对人类进行解释;这是一个视觉提示,有助于机器学习模型的决策。因此,让模型优化视觉上下文!我们遵循一种简单的基于梯度的方法,其中我们通过反向传播直接优化视觉提示。
3.2.1 Prompt Tuning(提示调优)
给定一个冻结的预训练模型F和一个下游任务数据集D = {(x1, y1),…, (xm, ym)},我们的目标是学习一个单一的、任务特定的视觉提示符vφ,用φ参数化。将提示符添加到输入图像中,形成提示图像x + vφ。在训练过程中,模型将正确标签y的可能性最大化,

而梯度更新只适用于提示参数φ,模型参数θ保持冻结。在评估期间,优化的提示被添加到所有测试时图像,然后通过冻结模型F进行处理。
![]()
注意,我们的目标是探索视觉提示作为一种实用的适应方法。因此,我们不需要任何使扰动不被察觉的对抗性约束。此外,对抗性重编程假设下游数据集的分辨率比预先训练的数据集低,这样输入扰动在下游数据集周围填充。在实际应用程序中,下游数据集可能具有不同的分辨率。因此,我们将每个数据集的大小调整为预训练的模型的输入大小,并将提示直接添加到输入区域。
3.2.2提示设计
给图片增加prompt,首先想到的就是添加一些像素,以像素形式添加prompt的优点就是可以做到task-special和input-agnostic;prompt中含有大量数据中学到的信息,所以是任务相关的,对于同一个任务,在测试时,直接使用得到的prompt就可以,不管输入哪张图片,此时与输入无关。
在模板和大小方面,有几种方法可以设计视觉提示。我们探索了三种可视化模板:随机位置的像素patch、固定位置的像素patch和填充。我们探索了各种提示尺寸p,其中patch的实际参数数量为C*p^2, padding的实际参数数量为2C*p (H +W−2p),其中C、H、W分别为图像通道、高度和宽度。第6.2节展示了p = 30的填充比其他设计选择获得了最好的性能。我们在所有的实验中都使用这个默认值。
3.3输出转换
为了将模型输出映射到目标标签,我们对视觉模型和CLIP采取了不同的方法。标准视觉模型将图像类视为数字id(例如,“cat”映射到“index 1”)。我们使用硬编码映射,并将下游类索引任意映射到预训练的类索引,丢弃未分配的索引进行损失计算。对于视觉语言模型CLIP,我们使用文本提示作为输出转换函数。图像类由文本(例如“cat”)表示,然后提示(例如“a photo of a [object]”)指定下游任务的上下文。请注意,我们使用了一个固定的文本提示(参见附录),并且只优化了视觉提示。我们遵循CLIP zero-shot传输协议,并计算每个类的embeddings的余弦相似性,通过softmax将其归一化为概率分布。选择概率最高的类作为模型输出。视觉模型和CLIP的完整概述如图1所示。
3.4 实现细节
为了学习视觉提示,CLIP的目标函数与其评估设置相同,即我们只计算图像上的交叉熵损失,其中通过文本编码器处理一组提示文本字符串以产生线性分类器的权重。对于视觉模型,我们计算新的类指标上的交叉熵损失。对于所有的实验,我们使用提示大小为30的padding template(填充模板)。所有图像都被调整为224 × 224,以匹配预训练模型的输入大小,并且预处理与每个模型的评估设置相同。我们发现密切关注预训练模型的评估设置对于学习一个好的提示是很重要的。所有的视觉提示都经过1000次epoch的训练。我们使用学习率为40的SGD,它使用余弦调度进行衰减。CLIP的批大小为256,BiT-M和RN50的批大小为128,Instagram的批大小为32。
4.实验设置
4.1数据集
为了评估视觉提示如何使模型适应新任务,我们测量了12个数据集的性能:CIFAR100、CIFAR10、Flowers102、Food101、EuroSAT、SUN397、DTD、UCF101、SVHN、OxfordPets、Resisc45和CLEVR。我们还通过评估WILDS中的三个图像分类数据集:Camelyon17, FMoW和iWildCAM,来衡量对分布迁移的鲁棒性,即训练分布不同于测试分布。Camelyon17的训练和测试集包括来自不同医院的组织贴片。对于FMoW,训练集和测试集来自不同的地区和年份。最后,iWildCAM由不相交的相机陷阱拍摄的照片组成。注意,我们在训练集上学习视觉提示,并在测试集上评估其性能。
4.2 Baseline Methods(基线方法)
为了衡量视觉提示与现有适应方法(图2)相比表现如何,我们比较了微调、线性探针和文本提示(即zero-shot transfer)。微调和线性探头是视觉中常用的自适应方法。微调在适应过程中更新整个模型参数。线性探针是一种轻量级的替代方案,它通过学习线性层来适应模型输出(通常在倒数第二层激活),同时冻结模型参数。对于文本提示,我们使用“This is a photo of a [LABEL]”作为默认值。对于CLEVR,我们使用“This is a photo of [LABEL] objects”,类标签为“3”到“10”。对于Camelyon17,我们使用“a tissue region [LABEL] tumor”,分类标签为“containing”和“not containing”。
5.结果
5.1 CLIP的有效性
我们首先将提示性能与线性探测进行比较,线性探测是目前轻量级适应的实际方法。图3显示了每个预训练模型在12个数据集上的平均测试精度。视觉模型提示或对抗性重编程显示出与标准线性探针显著的性能差距(+40%)。另一方面,我们发现提示对于CLIP是惊人的有效的,达到了与线性探测竞争的性能。特别是,在EuroSAT、SVHN和CLEVR上,视觉提示优于线性探测,分别高出1.1%、23%和15.4%(表1)。平均而言,学习视觉提示比只使用文本提示(即“zero-shot transfer”)获得24%的性能提升。有趣的是,我们发现视觉提示的性能在不同的数据集之间有所不同(图4)。关于这一现象,我们将在第6.1节中进一步分析数据集的哪些属性会影响性能。我们在附录中报告了12个视觉模型数据集的完整结果。


5.2对分布迁移的鲁棒性
由于模型参数保持冻结状态,提示阻止修改预训练模型的通用知识库。这减少了对下游数据集中虚假相关性的过度拟合的可能性,从而提高了对分布迁移的鲁棒性。使用WILDS基准测试,我们从包含特定领域图像的训练集中学习视觉提示,并查看它如何转移到来自不同领域的测试集(例如,来自不同医院、地区、年份、相机的图像)。表2显示,与线性探针和微调相比,平均性能差距分别进一步减小到4.5%和3.5%。在Camelyon17上,视觉提示比线性探针和微调分别高出4.9%和6.5%。这表明了在实际部署中提示的实际效用,其中自然会出现各种范围的领域转移。我们在附录中报告了视觉模型的鲁棒性结果。

6.理解视觉提示
在本节中,我们将研究下游数据集的属性、提示设计(即输入转换)和输出转换方面的视觉提示性能。
6.1下游数据集
我们发现视觉提示的性能在下游数据集之间是不同的。如图4所示,性能最好的数据集获得了+83.2%的精度增益,而性能最差的数据集有-1%的精度损失。为了解释这一现象,我们首先假设视觉提示通过将不熟悉的下游数据集转换为更类似于预训练的数据集,来弥补分布差距。在这种假设下,视觉提示不会帮助已经在预训练分布内的数据集,但可以帮助严重分布失衡的数据集。虽然CLIP预训练的数据集还不能向公众提供,但它经过了过度调整,以在ImageNet上实现最先进的zero-shot性能。因此,我们使用ImageNet作为代理。我们通过使用FID评分测量ImageNet和下游数据集之间的分布相似性来验证我们的假设。我们将这些分数与视觉提示的准确率进行比较。由于计算能力的限制,我们从ImageNet-1k训练集中随机抽样了100k张图像来计算指标。在图5中,我们观察到随着下游数据集越来越多地分布到ImageNet(例如,CLEVR, SVHN),总体性能得到了提高。
另一个假设是关于学习每个数据集的单个提示。虽然这对于感知多样性低的数据集可能足够了,但随着多样性的增加,单个视觉提示可能无法捕获完整的分布。我们使用LPIPS来测量感知多样性。对于每个数据集,我们测量两个随机抽样图像对之间的LPIPS,并报告平均得分。图5显示,对于感知多样性较低的数据集,学习单一视觉提示可以获得更好的性能增益。

6.2 提示设计
选择正确的视觉提示设计(即模板和大小)可以极大地影响性能。我们在三种不同的模板上进行消融研究:随机位置的像素patch、固定位置的像素patch和跨提示大小p = 1..., 224的padding。我们使用冻结的CLIP测量EuroSAT数据集的准确性。图6.2显示了使用固定位置模板(即padding、固定patch)可以获得更好的性能。对于固定位置的模板,我们发现随着提示大小的增加(例如,更多可训练的参数),性能会提高,然后当+70k参数时,性能开始下降。令人惊讶的是,我们发现我们最简单的方法——添加单像素提示——比文本提示的CLIP提高了3%(图7)。总的来说,在我们的实验中,p = 30的padding达到了最佳性能。我们认为这是因为我们的应用范围是图像分类,其中感兴趣的对象往往位于图像的中心。我们相信其他视觉任务可能需要明显不同的设计选择。关于如何计算参数的实际数量,请参见3.2.2节。

6.3输出转换
我们研究了如何设计输出转换的提示性能。对于视觉模型,我们遵循[12]并使用硬编码映射;下游类指标被任意分配给预训练的类指标。我们将分析这种映射如何影响下游性能。使用OxfordPets的一个子集,我们构建了一个简单的toy数据集,用于对狗和猫进行分类。使用在ImageNet-1k (RN50)上训练的ResNet,我们比较了两种情况:(1)将下游类分配给语义相似的预训练类(将不可见的“dog”分配给预训练的“chihuahua”索引),(2)交换索引(将cat分配给dog索引,反之亦然)。(1)达到100%,(2)达到62.5%;类索引之间具有相似的语义对性能至关重要。这也许可以解释视觉模型和CLIP之间的性能差距。
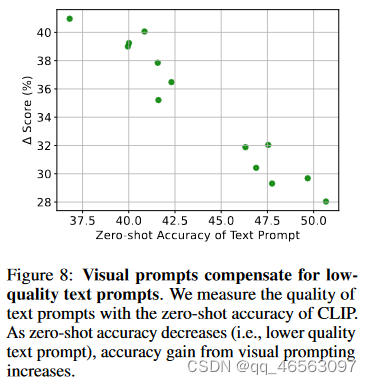
对于CLIP(一种视觉语言模型),我们使用文本提示进行输出转换。当我们通过反向传播学习视觉提示时,学习信号依赖于我们使用的文本提示。据报道,通过使用更好的文本提示,CLIP的zero-shot精度可以显著提高。因此,我们假设文本提示的质量影响视觉提示的性能。在EuroSAT上,我们通过CLIP的zero-shot性能来衡量文本提示质量。图8显示,对于zero-shot性能较低的文本提示,视觉提示的性能增益更高。换句话说,视觉提示可以弥补低质量的文本提示。由于手动搜索最佳文本提示是非常繁琐的,这个结果突出了视觉提示的有用性。
7.讨论
在本文中,我们研究了一种方法,干扰输入到预训练的模型,以提高分类精度。视觉提示的一个更广泛的解释是将其视为一种通过修改输入空间来引导预训练的模型向任何方向前进的方法。例如,可以使用图像对图像模型的视觉提示来更改输入的视觉样式。即使我们在这项工作中探索了“通用的”视觉提示(即,适用于所有输入图像的单一提示),提示也可以使输入有条件,因此不那么通用,但可能更准确。具体的设计选择包括(a)输入特定或输入不可知,(b)提高或降低准确性,以及(c)预训练模型的类型,可以修改以创建未来有趣的提示应用。
随着我们的阐述,一个自然的问题是,在什么情况下,人们更喜欢视觉提示而不是微调或线性探测?微调假设模型可以被修改,但不一定总是这样(例如,如果模型是由第三方拥有的API公开的)。虽然提示在某些情况下确实不如线性探测,但我们想强调的是,这项工作的目标是展示“像素空间”中提示机制的存在,它可以跨多个数据集和预训练的模型,并揭示如何有效适应视觉模型的新途径。我们在这项工作中的重点不是超越最先进的技术;我们注意到,有几种方法可以用于进一步提高性能,包括集成多个提示,将提示与线性探测或微调结合使用,或缩放预先训练的模型(例如,CLIP的VIT-L/14,不幸的是公众无法使用)。我们把这些留给以后的工作。
8.结论
标准的视觉适应方法侧重于引入一个单独的任务特定的头部并适应模型参数或激活,而我们研究了视觉提示作为实用的适应方法。我们使用基于梯度的方案来学习一个单一的、输入不可知的扰动,它重新利用一个冻结的模型来执行下游任务。通过在预训练的模型和数据集上的各种实验,我们证明了CLIP特别适合于视觉提示,可以获得与线性探测相比具有竞争力的结果。我们希望我们独特的发现能刺激进一步的研究:(1)更好地理解像素空间适应——什么时候以及为什么它们能有效地引导深度网络,(2)开发更好的视觉提示,进一步增加我们创建灵活和适应性视觉系统的机制。

