
热门标签
热门文章
- 1自定义RadioButton_自定义组合的radiobutton
- 2深度学习方法(十五):知识蒸馏(Distilling the Knowledge in a Neural Network),在线蒸馏_hinton, g,distilling the knowledge in a neural net
- 3数据并行和模型并行的区别_数据并行模型并行
- 4QT中 子对话框访问主窗口变量。_qt子窗口调用父窗口变量
- 5Java实现发送邮件功能_java邮件功能
- 6uni原生导航栏相关设置_uni.settabbaritem
- 7FPGA时序分析与时序约束(四)——时序例外约束
- 8idea:项目添加到github_idea 添加项目到guithub指定组织下
- 9Zxing一维条码/二维条码生成与读取开发实例_zxing生成条码如何设置显示字符串
- 10Qt lnk1158 无法运行rc.exe 解决_qtlnk1158: 无法运行“rc.exe”
当前位置: article > 正文
10.第十章 列表
作者:知新_RL | 2024-06-16 01:39:08
赞
踩
10.第十章 列表
10. 列表
本章介绍Python语句最有用的内置类型之一: 列表.
你还能学到更多关于对象的知识, 以及同一个对象有两个或更多变量时会发生什么.
- 1
- 2
10.1 列表是一个序列
和字符串相似, 列表(list)是值的序列.
在字符串中, 这些值是字符;
在列表中, 它可以是任何类型.
列表中的值称为元素(element), 有时也称为列表项(item).
- 1
- 2
- 3
- 4
创建一个列表有好几种方法. 其中最简单的方式是使用方括号[]将元素扩起来.
- 1
[10, 20, 30, 40]
['crunchy', 'ram bladder', 'lark vomit']
- 1
- 2
- 3
第一个例子是4个整数的列表.
第二个例子是3个字符串的列表.
列表中的元素并不一定非得是同一类型的.
下面的列表包含了一个字符串, 一个浮点数, 一个整数及(瞧!)另一个列表:
- 1
- 2
- 3
- 4
['span', 2.0, 5, [10, 20]]
- 1
- 2
列表中出现的列表是嵌套的(nested).
不包含任何元素的列表被称为空列表, 可以使用空方括号[]来创建空列表.
如你所预料的, 列表可以赋值给变量:
- 1
- 2
- 3
>>> chesses = ['Cheddar', 'Edam', 'Gouda']
>>> numbers = [42, 123]
>>> empty = []
>>> print(chesses, numbers, empty)
['Cheddar', 'Edam', 'Gouda'] [42, 123] []
- 1
- 2
- 3
- 4
- 5
- 6
10.2 列表是可变的
访问列表元素的语法和访问字符串中字符的语法是一样的--使用方括号操作符.
方括号中表达式指定下标, 请记住下标是从0开始的:
- 1
- 2
>>> chesses[0]
'Cheddar'
- 1
- 2
- 3
和字符串不同的是, 列表是可变的.
当方括号操作符出现在赋值语句的左侧时, 它用于指定列表中哪个元素会被赋值.
- 1
- 2
>>> numbers = [42, 123]
>>> numbers[1] = 5
>>> numbers
[42, 5]
- 1
- 2
- 3
- 4
- 5
numbers的第一位元素, 原先的值是123, 现在是5了.
下图显示了chesses, numbers和empty的状态图.
- 1
- 2

在图中, 外面写有list的图框表示列表, 里面显示的列表中的元素.
cheeses变量引用着一个列表, 包含三个元素, 下标分别是0, 1, 2.
numbers包含两个元素. 涂总显示了其第二个元素从123重新赋值为5的过程.
empty引用一个没有任何元素的空列表.
列表下标和字符串下标工作方式相同.
* 任何整型的表达式都可以用作下标.
* 如果尝试读写写一个并不存在的元素, 则会得到IndexError.
* 如果下标是负数, 则从列表的结尾处反回来数下标访问.
in操作符也可以用于列表.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
>>> cheeses = ['Cheddar', 'Edam', 'Gouda']
>>> 'Edam' in cheeses
True
>>> 'brie' in cheeses
False
- 1
- 2
- 3
- 4
- 5
- 6
10.3 遍历一个列表
遍历一个列表元素的最常见方式是使用for循环. 语法和字符串的遍历相同:
- 1
cheeses = ['Cheddar', 'Edam', 'Gouda']
for cheese in cheeses:
print(cheese)
- 1
- 2
- 3
- 4
- 5
# 运行终端显示:
Cheddar
Edam
Gouda
- 1
- 2
- 3
- 4
- 5
在只需要读取列表的元素本身时, 这样的遍历方式很好.
但如果需要写入或者更新元素时, 则需要下标.
一个常见的方式是使用内置函数range和len.
- 1
- 2
- 3
numbers = [42, 5]
for i in range(len(numbers)):
numbers[i] = numbers[i] * 2
print(numbers) # [84, 10]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个循环遍历列表, 并更新每个元素.
len返回列表中元素的个数.
range返回一个下标的列表, 从0到n-1, 其中n是列表的长度. 每次迭代时, i获得下一个元素的下标.
循环体中的赋值语句使用i来读取元素的旧值并赋值为新值.
在空列表上使用for循环, 则循环体从不会被运行.
- 1
- 2
- 3
- 4
- 5
- 6
for x in []:
print('This never happens.')
- 1
- 2
- 3
虽然列表可以包含其它的列表, 嵌套的列表仍然被看作一个单独的元素. 下面的列表长度是4:
- 1
['span', 1, ['Brie', 'Roquefort', 'Pol le Veq'], [1, 2, 3]]
- 1
10.4 列表操作
+操作符可以拼接列表:
- 1
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = a + b
>>> c
[1, 2, 3, 4, 5, 6]
- 1
- 2
- 3
- 4
- 5
- 6
*操作符重复一个列表多次:
- 1
>>> [0] * 4
[0, 0, 0, 0]
>>> [1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
- 1
- 2
- 3
- 4
- 5
10.5 列表切片
切片操作符也可以用于列表:
- 1
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3]
['b', 'c']
>>> t[:4]
['a', 'b', 'c', 'd']
>>> t[3:]
['d', 'e', 'f']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果省略掉第一个下标, 则切片从列表开头开始.
如果省略掉第二个下标, 则切片至列表结尾结束.
如果两个下标都省略, 则切片就是整个列表的副本.
- 1
- 2
- 3
>>> t[:]
['a', 'b', 'c', 'd', 'e', 'f']
- 1
- 2
- 3
因为列表是可变的, 所有在对列表进行修改操作之前, 复制一份是很有用的.
如果切片操作符出现在赋值语句的左侧, 则开始更新多个元素:
- 1
- 2
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3] = ['x', 'y']
>>> t
['a', 'x', 'y', 'd', 'e', 'f']
- 1
- 2
- 3
- 4
- 5
10.6 列表方法
Python为列表提供了不少操作方法.
例如, append可以在列表尾部添加新的元素:
- 1
- 2
>>> t = ['a', 'b', 'c']
>>> t.append('d')
>>> t
['a', 'b', 'c', 'd']
- 1
- 2
- 3
- 4
- 5
extend方法接收一个列表作为参数, 并将其所有的元素附加到列表中: (这个例子中t2没有被修改.)
- 1
>>> t1 = ['a', 'b', 'c']
>>> t2 = ['d', 'e']
>>> t1.extend(t2)
>>> t1
['a', 'b', 'c', 'd', 'e']
- 1
- 2
- 3
- 4
- 5
- 6
sort方法将列表中的元素从低到高重新排序:
- 1
>>> t = ['d', 'c', 'e', 'b', 'a']
>>> t.sort()
>>> t
['a', 'b', 'c', 'd', 'e']
- 1
- 2
- 3
- 4
- 5
列表的大多数方法全是无返回值的. 它们修改列表, 并返回None.
如果不小心写了 t = t.sort(), 你可能对结果感到很失望(t的值是None).
- 1
- 2
10.7 映射, 过滤和化简
如果想把列表中所有的元素加起来, 可以使用下面这样的循环:
- 1
def add_all(t):
# total是累加器
total = 0
for x in t:
total += x
retunr total
- 1
- 2
- 3
- 4
- 5
- 6
total被初始化为0, 每次循环中, x获取列表中的一个元素.
+= 操作符为更新变量提供了一个简洁的方式.
这个增加赋值语句:
- 1
- 2
- 3
tatal += x
- 1
等价于:
- 1
total = total + x
- 1
随着循环的运行, total会累积列表中的值的和; 这样使用一个变量有时称为累加器(accumulator).
对列表元素累加是如此常见的操作, 以至于Python提供了一个内置函数sum:
- 1
- 2
>>> t = [1, 2, 3]
>>> sum(t)
6
- 1
- 2
- 3
- 4
类似这样, 将一个列表的元素值合起来到一个单独的变量的操作, 有时称为化简(reduce).
(累积所有元素的值并计算出一个单独的结果, 就是化简.)
有时候你想要在遍历一个列表的同时构建另一个列表.
例如, 下面的函数接收一个字符串列表, 并返回一个新列表, 其元素是大写的字符串:
- 1
- 2
- 3
- 4
t = ['a', 'b', 'c', 'd', 'e', 'f'] def capitalize_all(t): res = [] for s in t: # 把…首字母大写 res.append(s.capitalize()) return res res1 = capitalize_all(t) print(res1) # ['A', 'B', 'C', 'D', 'E', 'F']

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
res初始化为一个空列表; 每次循环, 我们给它附加一个元素. 所以res也是一种累加器.
像capitalize_all这样的操作, 有时称为映射(map),
因为它将一个函数(在这个例子里是capitalize方法)'映射'到一个序列的每个元素上.
另一个常见的操作是选择列表中的某些元素, 并返回一个子列表.
例如, 下面的函数接收一个字符串列表, 并返回那些只包含大写子母的字符串:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
t1 = ['A', 'b', 'c', 'd', 'e', 'f'] def only_upper(t): res = [] for s in t: # 过滤操作 if s.isupper(): res.append(s) return res res1 = only_upper(t1) print(res1) # ['A']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
isupper是一个字符串方法, 当字符串中只包含大写子母时返回True.
类似only_upper这样的操作成为过滤(filter), 因为它选择列表中的某些元素, 并过滤掉其他的元素.
列表的绝大多数常用操作都可以用映射, 过滤, 和化简的组合来表达.
- 1
- 2
- 3
- 4
- 5
10.8 删除元素
从列表中删除元素, 有多种方法.
如果知道元素的下标, 可以使用pop:
- 1
- 2
>>> t = ['a', 'b', 'c']
>>> x = t.pop(1)
>>> t
['a', 'c']
>>> x
'b'
- 1
- 2
- 3
- 4
- 5
- 6
pop修改列表, 并返回被删除掉的值. 如果不提供下标, 它会删除并返回最后一个元素.
如果不需要使用删除的值, 可以使用del操作符:
- 1
- 2
>>> t = ['a', 'b', 'c']
>>> def t[1]
>>> t
['a', 'c']
- 1
- 2
- 3
- 4
- 5
若要删除多个元素, 可以使用del和切片下标:
(和通常一样, 切片会选择所有的元素, 直到第二个下标(并不包含)).
- 1
- 2
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del t[1:5]
>>> t
['a', 'f']
- 1
- 2
- 3
- 4
- 5
如果知道要删除的元素(而不是下标), 则可以使用remove:
(remove方法的返回值是None.)
- 1
- 2
>>> t = ['a', 'b', 'c']
>>> t.remove('b')
>>> t
['a', 'c']
- 1
- 2
- 3
- 4
- 5
10.9 列表和字符串
字符串是字符的序列, 为列表时值的序列, 但字符的列表和字符串并不相同.
若要将一个字符串转换为一个字符的列表, 可以使用函数list:
- 1
- 2
>>> s = 'apam'
>>> t = list(s)
>>> t
['s', 'p', 'a', 'm']
- 1
- 2
- 3
- 4
- 5
由于list是内置函数的名称, 所以应当尽量避免使用它作为变量名称.
我也避免使用l, 因为它看起来太像数字1l. 因而我使用t.
list函数会将字符串拆成单个的字母. 如果想要将字符串拆成单词, 可以使用split方法:
- 1
- 2
- 3
- 4
>>> s = 'pining for the fjords'
# 默认以空格作为分隔符.
>>> t = s.split()
>>> t
['pining', 'for', 'the', 'fjords']
- 1
- 2
- 3
- 4
- 5
- 6
split还接收一个可选的形参, 称为分隔符(delimiter), 用于指定用哪个字符来分隔单词.
下面的例子中使用连字符(-)作为分隔符:
- 1
- 2
>>> s = 'spam-spam-spam'
>>> delimiter = '-'
>>> t = s.split(delimiter)
>>> t
['spam', 'spam', 'spam']
- 1
- 2
- 3
- 4
- 5
- 6
join是split的逆操作. 它接收字符串列表, 并拼接每个元素.
join是字符串的方法, 所以必须在分割符上调用它, 并传入列表作为实参:
- 1
- 2
>>> t = ['pining', 'for', 'the', 'fjords']
>>> delimiter = ' '
>>> s = delimiter.join(t)
>>> s
'pining for the fjords'
- 1
- 2
- 3
- 4
- 5
- 6
在这个例子里, 分隔符是空格, 所以join会再每个单词之间放一个空格.
若想不用空格直接连接字符串, 可以使用空字符串''作为分隔符.
- 1
- 2
10.10 对象和值
a = 'banana'
b = 'banana'
- 1
- 2
- 3
我们知道a和b都是一个字符的引用. 但我们不知道它们是否指向同一个字符串. 有两种可能的状态, 如图:
- 1

一种可能是, a和b引用着不同的对象, 它们的值相同.
另一种情况下, 它们指向同一个对象.
要检查两个变量是否引用同一个对象, 可以使用is操作符.
- 1
- 2
- 3
- 4
>>> a = 'banana'
>>> b = 'banana'
>>> a is b
True
- 1
- 2
- 3
- 4
- 5
在这个例子里, Python只建立了一个字符串对象, 而a和b都引用它.
但当你新建两个列表时, 会得到两个对象:
- 1
- 2
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
False
- 1
- 2
- 3
- 4
- 5
所以状态图如下:
- 1

在这个例子里我们会说:
这两个列表是相等的(equicalent), 因为它们有相同的元素,
但它们不是相同的(identical), 因为它们并不是同一个对象.
如果两个对象相同, 则必然也相等, 但如果两个对象相等, 并不一定相同.
- 1
- 2
- 3
- 4
到目前为止, 我们都不加区分地使用'对象'和'值', 但更精确的说法是对象有一个值.
如果求值[1, 2, 3], 会得到一个列表对象, 它的值是一个整数的序列.
如果另一个列表包含相同的元素, 我们说它有相同的值, 但它们不是同一个对象.
- 1
- 2
- 3
10.11 别名
如果a引用一个对象, 而你赋值b = a, 则两个变量都会引用同一个对象:
- 1
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
True
- 1
- 2
- 3
- 4
- 5
这里的状态图如下:
- 1

变量和对象之间的关联关系称为引用(reference). 在这个例子里, 有两个指向同一对象的引用.
当一个对象有多个引用, 并且引用有不同的名称时, 我们说这个对象有别名(aliased).
如果有别名的对象是可变, 则另一个别名的修改会影响另一个:
- 1
- 2
- 3
- 4
- 5
>>> b[0] = 42
>>> a
[42, 2, 3]
- 1
- 2
- 3
- 4
虽然这种行为可能很有用, 但它也很容易导致错误.
通常来说, 但处理可变对象时, 避免使用别名会更加安全.
- 1
- 2
对于字符串这样的不可变对象, 别名则不会带来问题. 在下面的例子中:
- 1
a = 'banana'
b = 'banana'
- 1
- 2
- 3
不论a和b是否引用同一个字符串, 都不会有什么区别.
- 1
10.12 列表参数
当你将一个列表传递给函数中, 函数会得到列表的一个引用.
如果函数中修改了列表, 则调用者也会看到这个修改.
例如, delete_head函数删除列表中的第一个元素:
- 1
- 2
- 3
def delete_head(t):
def t[0]
- 1
- 2
- 3
下面使用它:
- 1
>>> letters = ['a', 'b', 'c']
>>> delete_head(letters)
>>> letters
['b', 'c']
- 1
- 2
- 3
- 4
- 5
参数t和变量letters是同一个对象的别名. 栈图如下:
(因为列表被两个帧共享, 所以我将它画在中间.)
- 1
- 2
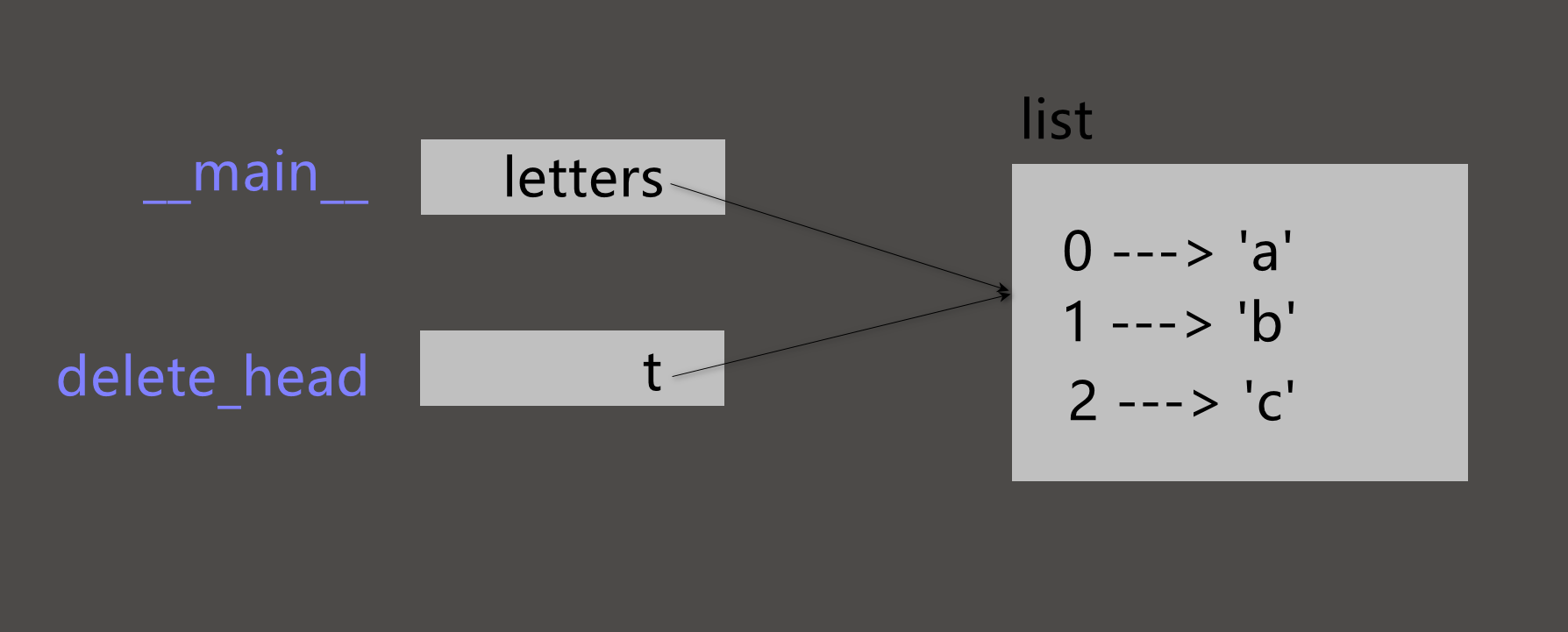
区分修改列表的操作和新建列表的操作十分重要.
例如, append方法修改列表, 但是+操作符新建一个列表:
- 1
- 2
>>> t1 = [1, 2]
>>> t2 = t1.append(3)
>>> t1
[1, 2, 3]
>>> t2
- 1
- 2
- 3
- 4
- 5
- 6
append修改列表, 返回None.
操作符+创建一个新列表, 而原始的列表并不改变.
- 1
- 2
>>> t3 = t1 + [4]
>>> t1
[1, 2, 3]
>>> t3
[1, 2, 3, 4]
- 1
- 2
- 3
- 4
- 5
- 6
这个区别, 在编写希望修改列表的函数是十分重要.
例如, 下面的函数并不会删除列表的开头:
- 1
- 2
def bad_delete_head(t):
t = t[1:]
- 1
- 2
- 3
切片操作会新建一个列表, 而赋值操作让t引用指向这个新的列表, 但这些操作对调用者没有影响.
- 1
>>> t4 = [1, 2, 3]
>>> bad_delete_head(t4)
>>> t4
[1, 2, 3]
- 1
- 2
- 3
- 4
- 5
在bad_delete_head的开头, t和t4指向同一个列表.
在函数的最后, t指向了一个新的列表, 但t4仍然执行原先的那个没有改变的列表.
另外一种方法是编写函数创建和返回一个新的列表.
例如, tail返回处理第一个以外所有的元素的列表:
- 1
- 2
- 3
- 4
def tail(t)
return t[1:]
- 1
- 2
- 3
这个函数不会修改原始列表. 下面的代码展示如何使用它:
- 1
>>> letters = ['a', 'b', 'c']
>>> rest = tail(letters)
>>> rest
['b', 'c']
- 1
- 2
- 3
- 4
- 5
10.13 调试
对列表(以及其他可变对象)的不慎使用, 可能会导致长时间的调试.
下面介绍一些常见的陷阱, 以及如何避免它们.
- 1
- 2
* 1. 大部分列表方法都是修改参数并返回None的.
这和字符串的方法正相反, 字符串方法新建一个字符串, 并保留着原始的字符串不动.
- 1
- 2
如果你习惯与写下面这样的字符串代码:
- 1
# strip()方法: 返回一个清除前后空格字符的字符串副本.
word = word.strip()
- 1
- 2
- 3
则容易倾向于这么写列表代码:
- 1
# sort()方法: 修改列表的排序, 返回None.
t = t.sort()
- 1
- 2
- 3
因为sort返回None, 接下来对t进行的操作很可能会失败.
在使用列表方法和操作符之前, 应当仔细阅读文档, 并在交互模式中测试它们.
- 1
- 2
* 2. 选择一种风格, 并保持不变.
列表的问题之一是同样的事情有太多可能的做法.
例如, 要从列表中删除一个元素, 可以使用pop, remove, del或者甚至是切片赋值.
要添加一个元素, 可以使用append方法或者+操作符.
选择一种风格作为常用的.
- 1
- 2
- 3
- 4
- 5
假设t是一个列表, x是一个列表元素, 下面操作正确的:
- 1
t.append(x)
t = t + [x]
t += [x]
- 1
- 2
- 3
- 4
而下面的操作是错误的:
- 1
t.append([x]) # 添加的不是列表, 不单单是元素.
t = t.append(x) # append 方法返回None, t的值是None.
t + [x] # 生成一个新的列表, 并不修改t本身.
t = t + x # 列表仅支持与列表进行拼接操作, x如果不是列表则报错.
- 1
- 2
- 3
- 4
- 5
在交互模式实验这些例子, 确保你明白它们的运行细节.
注意只有最后一个会导致运行时错误; 其他的三个都是合法的, 但是他们的结果不正确.
- 1
- 2
* 3. 通过复制来的避免别名.
如果想要使用类似sort的方法来修改参数, 但有需要保留原先的列表, 可以复制一个副本:
- 1
- 2
>>> t = [3, 1, 2]
# 切片方式复制一个副本, 直接使用赋值不行!
>>> t2 = t[:]
>>> t2.sort()
>>> t
[3, 1, 2]
>>> t2
[1, 2, 3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个例子里也可以使用内置函数sorted, 它会返回一个新的排好序的列表, 并且留着原先的列表不动.
- 1
>>> t2 = sorted(t)
>>> t
[3, 1, 2]
>>> t2
[1, 2, 3]
- 1
- 2
- 3
- 4
- 5
- 6
10.14 术语表
列表(list): 值的序列. 元素(element): 列表(或其他序列)中的一个值, 也称为列表项. 嵌套列表(nested list): 作为其他列表的元素的列表. 累加器(accumulator): 在循环中用于加和或者累积某个结果的变量. 增加赋值(augmented assignment): 使用类似+=操作符来更新变量值的语句. 化简(reduce): 一种处理模式, 遍历一个序列, 并将元素的值累积起来计算为一个单独的结果. 映射(map): 一种处理模式, 遍历一个序列, 对每个元素进行操作. 过滤(filter): 一种处理模式, 遍历列表, 并选择满足某种条件的元素. 对象(object): 变量可以引用的东西, 对象有类型和值. 相等(equivalent): 拥有相同的值. 相同(identical): 是同一个对象(并且也意味着相等). 引用(reference): 变量和它的值之间的关联. 别名(aliasing): 多个变量同时引用一个对象的情况. 分隔符(delimiter): 用于分隔字符串的一个字符或字符串(可以使用多个字符作为分隔符).
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
10.15 练习
你可以从↓下载这些练习的解答.
https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/list_exercises.py
- 1
- 2
1. 练习1
编写一个名为nested_sum的函数, 接收一个由内嵌的整数列表组成的列表作为参数,
并将内嵌列表中的值全部加起来. 例如:
- 1
- 2
>>> t = [[1, 2], [3], [4, 5, 6]]
>>> nested_sum(t)
21
- 1
- 2
- 3
- 4
t1 = [[1, 2], [3], [4, 5, 6]]
def nested_sum(t):
count = 0
for i in t:
count += sum(i)
# 需要打印, 如果在交互模式中使用return返回, 它会打印的.
print(count)
nested_sum(t1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2. 练习2
编写一个名为cumsum的函数, 接收一个数字的列表, 返回累计和;
也就是说, 返回一个新的列表, 其中第i个元素是原先列表的前i+1个元素的和. 例如:
- 1
- 2
>>> t = [1 , 2, 3]
>>> cumsum(t)
[1, 3, 6]
- 1
- 2
- 3
- 4
t1 = [1, 2, 3] def cumsum(t): count = 0 list1 = [] for i in t: count += i list1.append(count) return list1 res = cumsum(t1) print(res) # [1, 3, 6]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3. 练习3
编写一个函数middle, 接收一个列表作为形参, 并返回一个新列表,
包含除了第一个和最后一个元素之外的所有元素. 例如:
- 1
- 2
>>> t = [1, 2, 3, 4]
>>> middle(t)
[2, 3]
- 1
- 2
- 3
- 4
t1 = [1, 2, 3, 4]
def middle(t):
return t[1:-1]
res = middle(t1)
print(res) # [2, 3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. 练习4
编写一个名为chop的函数, 接收一个列表, 修改它, 删除它的第一个和最后一个元素, 并返回None, 例如:
- 1
>>> t = [1, 2, 2, 4]
>>> chop(t)
>>> t
[2, 3]
- 1
- 2
- 3
- 4
- 5
t1 = [1, 2, 3, 4]
def chop(t):
# 弹出第一个元素
t.pop(0)
# # 弹出最后一个元素
t.pop(-1)
return None
res = chop(t1)
print(res) # None
print(t1) # [2, 3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5. 练习5
编写一个名为is_sorted的函数, 接收一个列表作为形参,
并当列表是按照升序排好序的时候返回True, 否则返回False. 例如:
- 1
- 2
>>> is_sorted([1, 2, 3])
True
>>> is_sorted(['b', 'a'])
False
- 1
- 2
- 3
- 4
- 5
def is_sorted(t):
# 切片拷贝一份
tem = t[:]
# 排序
tem.sort()
# 对比
if t == tem:
return True
else:
return False
print(is_sorted([1, 2, 3])) # True
print(is_sorted(['b', 'a'])) # False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
6. 练习6
两个单词, 如果重新排列其中一个的字母可以得到另一个, 它们互为回文(anagram).
编写一个名为is_anagram的函数, 接收两个字符串, 当它们互为回文时返回True.
- 1
- 2
def is_anagram(word1, word2):
if word1 == word2[::-1]:
return True
print(is_anagram('boob', 'boob')) # Ture
- 1
- 2
- 3
- 4
- 5
- 6
- 7
7. 练习7
编写一个名为has_duplicates的函数接收一个列表, 当其中任何一个元素出现多一次时返回True.
它不应当修改原始列表.
意思是: 复制一个列表副本, 检查列表中是都有重复的元素.
- 1
- 2
- 3
def has_duplicates(list1): # 新建一个空列表 tem_list = [] # 遍历原来的列表. for i in list1: # i不在新列表中, 则添加. if i not in tem_list: tem_list.append(i) else: return True return False print(has_duplicates([1, 1, 2, 3, 4, 5, 5, 6])) # True print(has_duplicates([1, 2, 3, 4, 5, 6])) # False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
# 答案中的设计思路
def has_duplicates(t):
s = t[:]
s.sort()
# 检查相邻元素是否相等
for i in range(len(s)-1):
if s[i] == s[i+1]:
return True
return False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8. 练习8
这个练习谈的是所谓的生日悖论, (生日悖论是指在不少于23个人中至少有两人生日相同的概率大于50%.)
你可以在http://en.wikipedia.org/wiki/Birthday_paradox阅读相关资料.
如果你的班级中有23个学生, 那么其中有两个人生日相同的概率有多大?
你可以通过随机生成23个生日的样本并检查是否有相同的匹配来估计这个概率.
可以使用random模块中的randint函数来生成随机生日.
你可以从↓下载解答.
https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/birthday.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
import random student = 23 # 生成23个随机数字(1-365之间, 每天一个生日). def random_num(): tem_list = [] for i in range(student): num = random.randint(1, 365) tem_list.append(num) return tem_list # 重复计数 def duplicate_count(): birthday_list = random_num() tem_list = [] for i in birthday_list: if i not in tem_list: tem_list.append(i) # 有重复的就返回True else: return True # 检查1000次, 查看占比. count = 0 for i in range(1000): if duplicate_count(): count += 1 print('检查1000次, 其中有', count, '次至少有两个同学生日在同一天.') # 检查1000次, 其中有 525 次至少有两个同学生日在同一天.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
9. 练习9
编写一个函数, 读取words.txt, 并构建一个列表, 每个元素时一个单词.
给这个函数编写两个版本, 其中一个使用append方法, 另一个使用t = t + [x]的用法.
哪一个运行时间更长, 为什么?
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/wordlist.py
- 1
- 2
- 3
- 4
import time fin = open(r'C:\Users\13600\Desktop\words.txt') def read_words1(rf): word_list = [] for i in rf: # 去除\n word = i.strip() word_list.append(word) print(len(word_list)) start_time = time.time() read_words1(fin) end_time = time.time() print('花费时间为:', end_time - start_time, '秒') # 必须重新读取文件, 否则读文件是空的! fin = open(r'C:\Users\13600\Desktop\words.txt') def read_words2(rf): word_list = [] for i in rf: # 去除\n word = i.strip() word_list = word_list + [word] print(len(word_list)) start_time = time.time() read_words2(fin) end_time = time.time() print('花费时间为:', end_time - start_time, '秒')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
# 运行工具窗口显示:
113783
花费时间为: 0.01985931396484375 秒
113783
花费时间为: 110.68916153907776 秒
- 1
- 2
- 3
- 4
- 5
使用append方法只需向列表的末尾添加一个元素.
而使用t = t + [x]会创建一个新的列表对象, (t + [x] 会创建一个新的对象)
并将旧列表中的所有元素复制到新列表中, 然后将新元素添加到新列表中.
这意味着t = t + [x]的操作需要更多的内存, 并且需要更多的时间来执行.
因此, 在列表增长时, 使用append方法通常比使用t = t + [x]更有效率.
- 1
- 2
- 3
- 4
- 5
10. 练习10
要检查一个单词是否出现在单词列表中, 可以使用in操作符, 但由于它需要按顺序搜索所有单词, 可能会比较慢.
因为单词是按字母顺序排列的, 我们可以使用二分查找(也叫作二分搜索)来加快速度.
二分查找的过程类似于在字典中查找单词.
从中间开始, 检查需要的单词是不是在列表的中间出现的单词之前,
如果是, 则继续用同样的方法搜索前半部分, 否则搜索后半部分.
不论哪种情形, 都将搜索空间减小了一半.
如果单词列表有113783个单词, 那么大概耗费17步就能找到单词, 或者确认它不在列表之中.
编写一个函数in_bisect, 接收一个排好序的列表, 以及一个目标值, 当目标值在列表之中, 返回其下标,
否则返回None.
或者你可以阅读bisect模块(二分模块)的文档, 并使用它! (作者忘记了返回下标...)
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/inlist.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
fin = open(r'C:\Users\13600\Desktop\words.txt') # 创建空列表 words_list = [] for i in fin: word = i.strip() # 将读取的单词追加到列表中 words_list.append(word) # 排序, 操作原始列表 words_list.sort() def my_bisect(sort_list, target_value): # 获取列表长度 list_count = len(sort_list) # 设置低位. low = 0 # 设置高位 high = list_count - 1 # 循环, 循环结束的条件为 高位大于或等于低位. while high >= low: # 设置中间值(这个值也当前的下标) middle = (low + high) // 2 # 判断列表的中间值是否等于目标值 if sort_list[middle] == target_value: # 将下标返回 return middle # 中间值 > 目标值, 向左<<<查询. elif sort_list[middle] > target_value: # 修改高位(实现二分) high = middle - 1 # 中间值 < 目标值, 向右>>>查询. else: # 修改低位(实现二分) low = middle + 1 # 找不到值返回None return None # 测试列表 l1 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'g', 'h'] print(my_bisect(l1, 'a')) # 0 print(my_bisect(l1, 'b')) # 1 print(my_bisect(l1, 'c')) # 2 print(my_bisect(l1, 'd')) # 3 # 真实数据测试. print(my_bisect(words_list, 'bob')) # 10707
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
11. 练习11
两个单词, 如果其中一个是另一个的反向序列, 则称它们为'反向对'.
编写一个程序找到单词中出现的全部反向对.
比如, dog反过来是god, eye反过来还是eye.
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/reverse_pair.py
解题思路, 单词数量太多, 使用二分发查找, 不要使用in操作符(in操作从索引0开始遍历末尾, 非常耗时间!).
- 1
- 2
- 3
- 4
- 5
def my_bisect(sort_list, target_value): # 获取列表长度 list_count = len(sort_list) # 设置低位. low = 0 # 设置高位 high = list_count - 1 # 循环, 循环结束的条件为 高位大于或等于低位. while high >= low: # 设置中间值(这个值也当前的下标) middle = (low + high) // 2 # 判断列表的中间值是否等于目标值 if sort_list[middle] == target_value: # 将下标返回 return middle # 中间值 > 目标值, 向左<<<查询. elif sort_list[middle] > target_value: # 修改高位(实现二分) high = middle - 1 # 中间值 < 目标值, 向右>>>查询. else: # 修改低位(实现二分) low = middle + 1 # 找不到值返回None return None fin = open(r'C:\Users\13600\Desktop\words.txt') # 列表 words_list = [] # 获取所有单词, 存到列表中 for line in fin: word = line.strip() words_list.append(word) # 遍历单词列表 while len(words_list) > 0: # 从尾部开始弹出, 循环一次弹出一个词, 避免重复, 越到后面速度越快, 单词越来越少了! word = words_list.pop() revers_word = word[::-1] res = my_bisect(words_list, revers_word) if res: print(word + '<-->' + revers_word) print(len(words_list))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
12. 练习12
两个单词, 如果从每个单词中交错去除一个字母可组成一个新的单词, 我们称它们为'互锁'(interlocking).
例如, 'shoe'和'cold'可以互锁组成单词'schooled'.
编写一个程序找到所有互锁的词, 提示: 不全要穷举所有的词对!
- 1
- 2
- 3
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/interlock.py
谢明: 这个练习启发自http://puzzlers.org的一个示例.
- 1
- 2
1. 编写一个程序找到所有互锁的词, 提示: 不全要穷举所有的词对!
- 1
设计思路: 将一个单词拆成成两个单词, 使用二分法去查询单词表中是否有这两个单词!
- 1
# 不返回下标, 返回布尔值 def my_bisect(sort_list, target_value): # 获取列表长度 list_count = len(sort_list) # 设置低位. low = 0 # 设置高位 high = list_count - 1 # 循环, 循环结束的条件为 高位大于或等于低位. while high >= low: # 设置中间值(这个值也当前的下标) middle = (low + high) // 2 # 判断列表的中间值是否等于目标值 if sort_list[middle] == target_value: # return True # 中间值 > 目标值, 向左<<<查询. elif sort_list[middle] > target_value: # 修改高位(实现二分) high = middle - 1 # 中间值 < 目标值, 向右>>>查询. else: # 修改低位(实现二分) low = middle + 1 return False def make_words_list(): fin = open(r'C:\Users\13600\Desktop\words.txt') # 列表 words_list = [] # 获取所有单词, 存到列表中 for line in fin: word = line.strip() words_list.append(word) words_list.sort() return words_list def interlock(): words_list = make_words_list() # 遍历单词列表 for word in words_list: # 拆分单词, 第一个单词由偶数数组成, 第二个单词由奇数组成. split_word1 = word[::2] split_word2 = word[1::2] # 将拆分的单词, 使用二分法查找 if my_bisect(words_list, split_word1) and my_bisect(words_list, split_word2): print('可以将 ' + word + ' 拆分为 ' + split_word1 + ' 与 ' + split_word2) interlock()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
2. 能不能找到'三互锁'的单词? 也就是, 从第一, 第二, 第三个字母开始, 每第三个字母合起来形成一个单词.
- 1
# 不返回下标, 返回布尔值 def my_bisect(sort_list, target_value): # 获取列表长度 list_count = len(sort_list) # 设置低位. low = 0 # 设置高位 high = list_count - 1 # 循环, 循环结束的条件为 高位大于或等于低位. while high >= low: # 设置中间值(这个值也当前的下标) middle = (low + high) // 2 # 判断列表的中间值是否等于目标值 if sort_list[middle] == target_value: # return True # 中间值 > 目标值, 向左<<<查询. elif sort_list[middle] > target_value: # 修改高位(实现二分) high = middle - 1 # 中间值 < 目标值, 向右>>>查询. else: # 修改低位(实现二分) low = middle + 1 return False def make_words_list(): fin = open(r'C:\Users\13600\Desktop\words.txt') # 列表 words_list = [] # 获取所有单词, 存到列表中 for line in fin: word = line.strip() words_list.append(word) words_list.sort() return words_list def interlock(): words_list = make_words_list() # 遍历单词列表 for word in words_list: # 拆分单词, 第一个单词由偶数数组成, 第二个单词由奇数组成. split_word1 = word[::3] split_word2 = word[1::3] split_word3 = word[2::3] # 将拆分的单词, 使用二分法查找 if my_bisect(words_list, split_word1) and \ my_bisect(words_list, split_word2) and \ my_bisect(words_list, split_word3): print('可以将 ' + word + ' 拆分为 ' + split_word1 + ' 与 ' + split_word2 + ' 与 ' + split_word3) interlock()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/724633
推荐阅读

相关标签

