
热门标签
热门文章
- 1(DL笔记)Dive into Deep Learning -- 数据操作_built-in method numel of tensor object at
- 2cflow——C语言函数调用关系生成器(1),2024年最新开源至上_tree2dotx
- 3面试+算法之回文(Java):验证回文串、回文数、最长回文子串、回文链表、分割成回文串、最短回文串、_java 回文串
- 4pnpm安装成功但不能用_pnpm 安装没效果
- 5Java学习系列之 Array List_java array list
- 6Yolov7学习笔记(四)数据加载_yolov7tiny带moscia嘛
- 7Elasticsearch:使用 Llamaindex 的 RAG 与 Elastic 和 Llama3
- 8DATASTAGE有关时间类型的转换_datastage 类型转换
- 9FPGA中锁存器(latch)、触发器(flip-flop)以及寄存器(register)详解_fpga寄存器
- 10开源可信隐私计算框架“隐语”_蚂蚁集团全同态
当前位置: article > 正文
redis面试全面总结_redis面试总结
作者:知新_RL | 2024-06-17 20:27:06
赞
踩
redis面试总结
一、你用redis的应用场景是什么?
秒杀的库存扣减,APP首页的访问流量高峰,缓存,排行榜,短信验证码(限流),点赞、好友等相互关系的存储,限时业务的运用
二、redis与memecache有区别?
1、集群:
redis 和memcached都支持集群
2、数据类型
Redis支持的数据类型要丰富得多,Redis不仅仅支持简单的k/v类型的数据,同时还提供String,List,Set,Hash,Sorted
Set,pub/sub,Transactions数据结构的存储。其中Set是HashMap实现的,value永远为null而已
memcache支持简单数据类型,需要客户端自己处理复杂对象
3、持久性
redis支持数据落地持久化存储,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
memcache不支持数据持久存储
4、分布式存储
redis支持master-slave复制模式
memcache可以使用一致性hash做分布式
5、value大小不同
memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
6、数据一致性不同
Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。
而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,
但是比起Memcached,还是稍有逊色。
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,
属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
7、cpu利用
redis单线程模型只能使用一个cpu,可以开启多个redis进程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
三、基础知识部分
1、说说常见的数据结构?
a、5种常见数据结构
String
Hash
List
Set
SortedSet
- 1
- 2
- 3
- 4
- 5
- 6
b、其它数据类型
HyperLogLog、Geo、Pub/Sub
- 1
- 2
2、如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果将大量的 key 设置在同一时间过期,到这个时间点,redis 会出现短暂的卡顿现象。严重的话会出现缓存雪崩。
所以我们一般在时间上加一个随即值,使过期时间分散
- 1
- 2
3、你使用过Redis分布式锁么,它是什么回事?
先拿 setnx 来抢锁,抢到之后,再用expire给锁加一个过期时间防止忘记释放锁
- 1
4、假如Redis里面有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以全部扫出
- 1
5、如果redis正在提供服务,那么使用 keys 指令会有什么问题?
由于 redis 是单线程的,keys 指令会导致线程阻塞一段时间,服务会停顿,直到 keys 执行完毕。所以,
这个时候要用 scan 指令。scan 可以设置每次取出的个数,但是有可能会重复,所以要在客户端作一次去重。
- 1
- 2
6、redis是怎么进行数据持久化的?
目前 redis 持久化有三种实现方式:
(1) RDB
(2) AOF
(3) RDB-AOF混合
先上结论:公司用得最多的是第三种,也就是混合方式。
RDB和AOF比较:
RDB 将数据库的快照(snapshot)以二进制的方式保存到磁盘中。
AOF 则以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,
以此达到记录数据库状态的目的。
RDB 理解为一整个表全量的数据,AOF 理解为每次操作的日志。
由于这两种方式各自存在优缺点,所以目前使用RDB 做镜像全量持久化,AOF 做增量持久化。
服务器重启的时候先把表的数据全部搞进去,但是他可能不完整,你再回放一下日志,数据不就完整了嘛。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
7、RDB的原理可以讲讲吗?
fork 和 cow。fork 是指 redis 通过创建子进程来进行 RDB 操作,cow 指的是 copy on write,子进程创建后,
父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
- 1
- 2
8、redis的主从同步了解吗?
第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,
待完成后将 RDB 文件全量同步到复制节点,
复制节点接受完成后将 RDB 镜像加载到内存。加载完成后,
再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
后续的增量数据通过 AOF 日志同步即可,有点类似数据库的 binlog。
- 1
- 2
- 3
- 4
- 5
- 6
为了方便同学们的理解,我这里用两台docker做实验。
修改两台 redis 的 /etc/redis.cof 文件,将这里改为 0.0.0.0
bind 0.0.0.0
- 1
主机 ip:172.17.0.2 从机 ip:172.17.0.3
主机连接从机,可以看到直接进入了从机的 bash

redis-cli 查看主机信息:
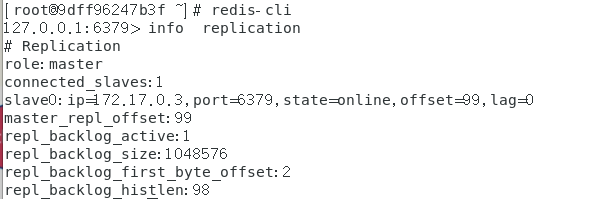
从机连接主机

redis-cli 查看从机信息::

从机设置了只读,这里我们测试从机是否可写

报错:从机只有读权限,无写权限。
测试成功!
9、能说说redis哨兵模式吗?
Redis Sentinal 着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
配置过 Sentinal 的哨兵模式
- 1
- 2
架构图:


这里用 3个 redis,3个 sentinel 来实验
起6个docker
redis:
主:172.17.0.2
从1:172.17.0.3
从2::172.17.0.4
sentinel:
leader:172.17.0.5
slave1:172.17.0.6
slave2:172.17.0.7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
配置哨兵
vi /etc/redis-sentinel.conf
# 添加如下3条
bind 0.0.0.0
protected-mode yes
daemonize yes
启动 /usr/bin/redis-sentinel /etc/redis-sentinel.conf
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
redis主机:可以看到两台从机,分别是 3 和 4
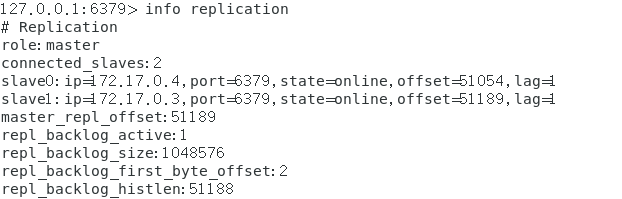
sentinel:主机是 2,两台从机

模拟主机宕机: 将2 停掉

使用从机1 也就是 3 查看:主机已经变成 4 了

再查看哨兵:主机变成4了

恢复 2,查看 2:

结果:2 自动加入集群,并成为从机,监听主机 4
测试成功!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/732702
推荐阅读
相关标签

