
- 1机器学习在网络安全领域的应用(二)_信息网络 机器学习
- 2【蓝桥杯Web】第十三届蓝桥杯(Web 应用开发)第二次线上模拟赛_【蓝桥杯web】第十三届蓝桥杯(web 应用开发)第二次线上模拟赛小兔子爬楼梯
- 3基于TLC5615的多路可调数控直流稳压电源,51单片机,含Proteus仿真和C代码等_proteus仿真电源芯片
- 4最详细的Keycloak教程(建议收藏):Keycloak实现手机号、验证码登陆——(三)基于springboot&keycloak+vue的前后端分离项目_keycloak 教程
- 5网络是怎样连接的-小笔记
- 6Linux下SPI驱动原理及实现详解_spi linux
- 7高精度压缩Transformer,NNI剪枝一站式指南_transformer自注意力剪枝
- 8WZ-S甲醛传感器使用说明代码应用案例笔记_wz-s怎么用
- 9ICRA 2024 | RGBManip:仅基于单目RGB相机的机器人自主环境感知和操纵
- 10git reset后恢复数据_gitreset后怎么恢复
Spark SQL 源码分析之 In-Memory Columnar Storage 之 cache table_spark cache table源码解析
赞
踩
/** Spark SQL源码分析系列文章*/
Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效率。
这就涉及到内存中的数据的存储形式,我们知道基于关系型的数据可以存储为基于行存储结构 或 者基于列存储结构,或者基于行和列的混合存储,即Row Based Storage、Column Based Storage、 PAX Storage。
Spark SQL 的内存数据是如何组织的?
Spark SQL 将数据加载到内存是以列的存储结构。称为In-Memory Columnar Storage。
若直接存储Java Object 会产生很大的内存开销,并且这样是基于Row的存储结构。查询某些列速度略慢,虽然数据以及载入内存,查询效率还是低于面向列的存储结构。
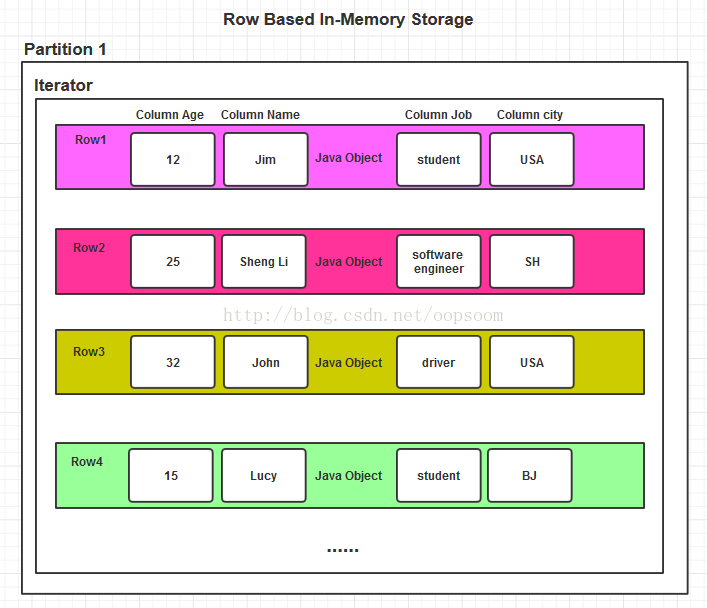
基于Row的Java Object存储:
内存开销大,且容易FULL GC,按列查询比较慢。
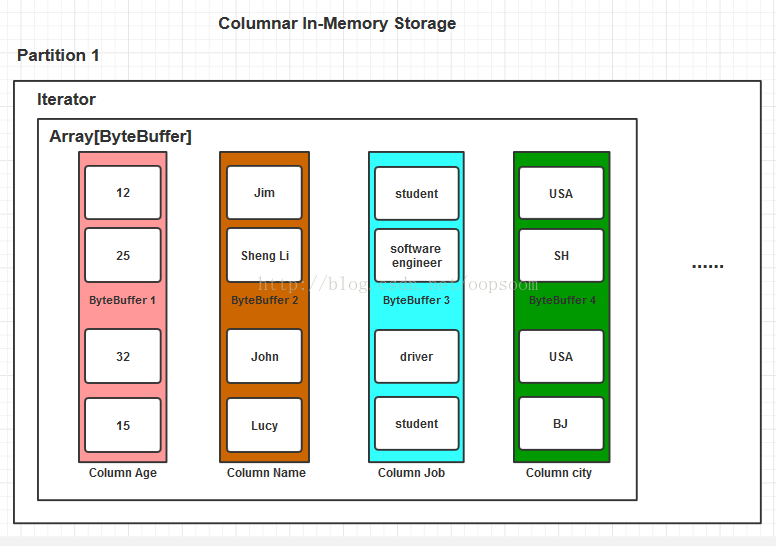
基于Column的ByteBuffer存储(Spark SQL):
内存开销小,按列查询速度较快。
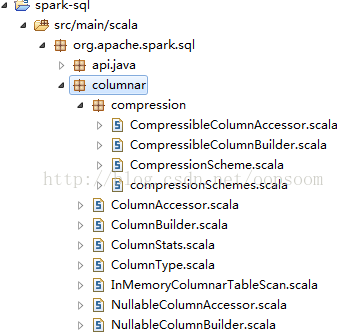
Spark SQL的In-Memory Columnar Storage是位于spark列下面org.apache.spark.sql.columnar包内:
核心的类有 ColumnBuilder, InMemoryColumnarTableScan, ColumnAccessor, ColumnType.
如果列有压缩的情况:compression包下面有具体的build列和access列的类。
一、引子
当我们调用spark sql 里的cache table command时,会生成一CacheCommand,这个Command是一个物理计划。
scala> val cached = sql("cache table src")- cached: org.apache.spark.sql.SchemaRDD =
- SchemaRDD[0] at RDD at SchemaRDD.scala:103
- == Query Plan ==
- == Physical Plan ==
- CacheCommand src, true
这里打印出来tableName是src, 和一个是否要cache的boolean flag.
我们看下CacheCommand的构造:
CacheCommand支持2种操作,一种是把数据源加载带内存中,一种是将数据源从内存中卸载。
对应于SQLContext下的cacheTable和uncacheTabele。
- case class CacheCommand(tableName: String, doCache: Boolean)(@transient context: SQLContext)
- extends LeafNode with Command {
-
- override protected[sql] lazy val sideEffectResult = {
- if (doCache) {
- context.cacheTable(tableName) //缓存表到内存
- } else {
- context.uncacheTable(tableName)//从内存中移除该表的数据
- }
- Seq.empty[Any]
- }
- override def execute(): RDD[Row] = {
- sideEffectResult
- context.emptyResult
- }
- override def output: Seq[Attribute] = Seq.empty
- }

cached.collect()将会调用SQLContext下的cacheTable函数:
首先通过catalog查询关系,构造一个SchemaRDD。
- /** Returns the specified table as a SchemaRDD */
- def table(tableName: String): SchemaRDD =
- new SchemaRDD(this, catalog.lookupRelation(None, tableName))
找到该Schema的analyzed计划。匹配构造InMemoryRelation:
- /** Caches the specified table in-memory. */
- def cacheTable(table

