
- 1【Android】Could not install Gradle distribution from(最简单) - gradle
- 2在gitlab提MR时因为代码冲突提交不上去 该怎么解决?_gitlab mr冲突
- 3网页 js 逆向分析 ( v_jstools )、jshook ( 安卓上用js实现Hook )
- 4GitHub代理_githu代理网址
- 5Python:爬山法/随机重启爬山法/允许侧移的爬山法解决八皇后问题_侧向移动爬山法
- 6如何用 AI 工具建立自己的知识库?_训练自己的ai知识库
- 7使用uniapp框架开发微信小程序的分包具体流程
- 8学生宿舍门禁维修报修管理系统 微信小程序nodejs+python+nodejs+php+java_学校微信小程序门禁系统
- 9FPGA多周期路径约束_什么时候会用到multicycle的约束
- 10linux screen 命令的使用教程_screen -s
When 多模态 meets 信息抽取
赞
踩

©PaperWeekly 原创 · 作者 | 宁金忠
单位 | 大连理工大学
研究方向 | 信息抽取
都 2222 年了,信息抽取领域早已经是诸神黄昏。然而,多模态方法的兴起给这个卷成麻花的领域带来的新的希望。就像阳光穿过黑夜,黎明悄悄划过天边,既然新的多模态风暴已经出现,我们怎能停滞不前?

让我们通过本文了解一下信息抽取领域中多模态方法的最新进展。本文分为两大主要章节,第一章介绍多模态关系抽取任务(Multimodal Neural Relation Extraction, MNRE),第二章介绍多模态命名实体识别任务(Multimodal Named Entity Recognition MNER)。

多模态关系抽取
任务介绍:多模态关系抽取任务的一个例子如下图所示。和基于文本的关系抽取方法相比,其他模态数据(例如图片)中的提示信息有利于性能的提升。

1.1 MNRE

论文标题:
MNRE: A Challenge Multimodal Dataset for Neural Relation Extraction with Visual Evidence in Social Media Posts
收录会议:
ICME 2021
论文链接:
https://ieeexplore.ieee.org/document/9428274
代码链接:
https://github.com/thecharm/MNRE
Motivation:关系抽取模型在面对社交媒体领域中长度偏短且缺少有效内容的文本时表现乏善可陈。同样,远程监督方法面对这种情景也显得力不从心。于是,寻找文本之外的内容来补充文本信息势在必行。
Contribution:
作者首次提出了多模态关系抽取这个任务,即利用图片中的视觉内容来对文本中缺失的信息进行补充。
作者构建并发布了一个人工标注的多模态关系抽取数据集。该数据集包含 10089 条实例,包含 31 中关系类别。
作者提出了几个多模态关系抽取的 baseline。
作者选择 Glove+CNN,BERTNRE,BERT+CNN 为本文的对比实验。在三个对比实验的基础上分别增加 Image Labels、Visual Objects、Visual Attention 做为多模态关系抽取的基准模型。
1.2 Mega
论文标题:
Multimodal Relation Extraction with Efficient Graph Alignment
收录会议:
ACM MM 2021
论文链接:
https://dl.acm.org/doi/abs/10.1145/3474085.3476968
代码链接:
https://github.com/thecharm/Mega
Motivation:使用 image-related information 对纯 text-based 信息中的缺失内容进行补充,从而提升社交媒体领域的关系抽取任务的性能。
Method:
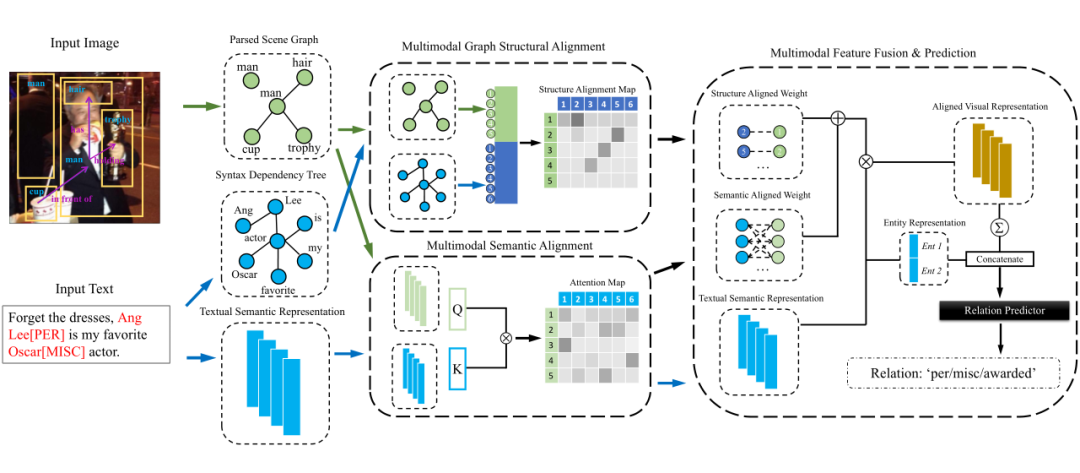
对于输入文本,作者使用 BERT 作为语义特征编码器。除此之外,作者使用句法解析工具提取了文本的句法解析树。对于输入图片,作者提取出其中目标的 scene graph。作者使用双流模型结构分别从图关系结构和语义两个方面来对齐文本和图像两个模态的信息。在模态特征融合阶段,作者把包含双模态的图结构对齐信息和语义表示对齐信息融合成一个向量,然后将其与头尾实体的表示向量进行拼接,最终得出关系的预测。

多模态命名实体识别
相比于多模态关系抽取任务,多模态多模态命名实体(MNER)任务由于起步较早已经涌现出了较多的工作。本章节中,我们把多模态命名实体识别任务按照使用的模态划分为:(1)基于语音-文本的 MNER(2)基于汉字结构特征 MNER(3)基于图片-文本的 MNER。

