
- 1git 常见问题_remote: enumerating objects: 418, done. fatal: 远端意
- 2Python深度学习环境配置(Pytorch、CUDA、cuDNN),包括Anaconda搭配Pycharm的环境搭建以及基础使用教程(保姆级教程,适合小白、深度学习零基础入门)_pytorch和cudnn
- 3gitignore python 清单_ignore .py
- 4Hadoop项目实战2---爬取某直聘网站_hadoop爬虫实现
- 5处理:ModuleNotFoundError: No module named '_sqlite3'_modulenotfounderror: no module named 'sqlite3
- 6MySQL 8.0.x 解压版 安装 基础环境配置(Windows 10 && mac )_mysql8 安装配置win10 解压
- 7spring boot 过滤器&拦截器与aop_拦截器和aop
- 8网络攻防——永恒之蓝_永恒之蓝适用于windows
- 9Proxifier与Burp联动 抓取PC端微信小程序_proxifier微信小程序抓包
- 10豆瓣评分9.1!Python最强工具书——《Python编程 从入门到实践》,建议白嫖_《python编程:从入门到实践》
k8s1.28.8版本配置prometheus监控告警_kubernetes1.28 kube-prometheusv0.13
赞
踩
参考文档
[Kubernetes集群监控-使用Alertmanager报警配置-腾讯云开发者社区-腾讯云 (tencent.com)](https://cloud.tencent.com/developer/article/2377069)
- 1
官方架构图

上图是`Prometheus-Operator`官方提供的架构图,其中`Operator`是最核心的部分,作为一个控制器,他会去创建`Prometheus`、`ServiceMonitor`、`AlertManager`以及`PrometheusRule`4个`CRD`资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的`prometheus`这种资源对象就是作为`Prometheus Server`存在,而`ServiceMonitor`就是`exporter`的各种抽象,是用来提供专门提供`metrics`数据接口的工具,`Prometheus`就是通过`ServiceMonitor`提供的`metrics`数据接口去 pull 数据的,当然`alertmanager`这种资源对象就是对应的`AlertManager`的抽象,而`PrometheusRule`是用来被`Prometheus`实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
- 1
- 2
- 3
- 4
- 5
组件的具体介绍
- Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如 Node Exporter Service、Mysql Exporter Service 等等。
- Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
kube-prometheus包含的组件
- Prometheus Operator
- 高可用的 Prometheus 默认会部署2个pod
- 高可用的 Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
简介:
这个kube-prometheus目前应该是开源最好的方案了,该存储库收集Kubernetes清单,Grafana仪表板和Prometheus规则,以及文档和脚本,以使用Prometheus Operator 通过Prometheus提供易于操作的端到端Kubernetes集群监视。以容器的方式部署到k8s集群,而且还可以自定义配置,非常的方便
- 1
文件存储路径:
prometheus的监控规则文件在prometheus Pod中的路径:/etc/prometheus/rules/prometheus-prometheus-kube-prometheus-prometheus-rulefiles-0/
而这些文件都是通过一个叫PrometheusRule的k8s资源生成的,PrometheusRule用于配置Promtheus的 Rule 规则文件,包括 recording rules 和 alerting,可以自动被 Prometheus 加载。
至于为什么 Prometheus 能够识别这个 PrometheusRule 资源对象呢?这就需要查看我们创建的 prometheus 这个资源对象了,里面有非常重要的一个属性 ruleSelector,用来匹配 rule 规则的过滤器,我们这里没有过滤,所以可以匹配所有的,假设要求匹配具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 资源对象
- 1
- 2
- 3
- 4
- 5
结构分析
alertmanager-secret.yaml # 告警配置
prometheus-prometheus.yaml # 监控配置
prometheusOperator-prometheusRule.yaml # 默认监控项
- 1
- 2
- 3
官网自带的一些规则
如果这里你接上告警,他默认的一些配置会一直发消息
alertmanager-prometheusRule.yaml
kubePrometheus-prometheusRule.yaml
kubernetesControlPlane-prometheusRule.yaml #禁用了我先
kubeStateMetrics-prometheusRule.yaml
nodeExporter-prometheusRule.yaml
prometheusOperator-prometheusRule.yaml
prometheus-prometheusRule.yaml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
自己总结流程
1-创建规则*.rules.yaml,他会自己引用到规则里面
2-报警接收器,先定义Alertmanager文件,然后kubectl create 创建成新的yaml,更新引用
3-创建AlertmanagerConfig,定义告警接收模板,预留标签
4-更新alertmanager-alertmanager.yaml,添加模板绑定标签
5-告警模板,创建*.tmpl模板,更新alertmanager-alertmanager.yaml添加configmap,修改 AlertmanagerConfig 配置文件, 指定模板文件
- 1
- 2
- 3
- 4
- 5
1-创建规则
磁盘使用率报警规则
当磁盘可用空间少于 50% 时触发告警,如果需要添加其他规则也是创建*.rules.yaml
创建 prometheus-rules.yaml,
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: demo
namespace: monitoring
spec:
groups:
- name: demo
rules:
- alert: nodeDiskUsage
annotations:
description: |
节点 {{$labels.instance }}
挂载目录 {{ $labels.mountpoint }}
当前可用空间 {{ printf "%.2f" $value }}%
summary: |
挂载目录可用空间低于 50%
expr: |
node_filesystem_avail_bytes{fstype!="",job="node-exporter"} /
node_filesystem_size_bytes{fstype!="",job="node-exporter"} * 100 < 50
for: 1m
labels:
severity: warning
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
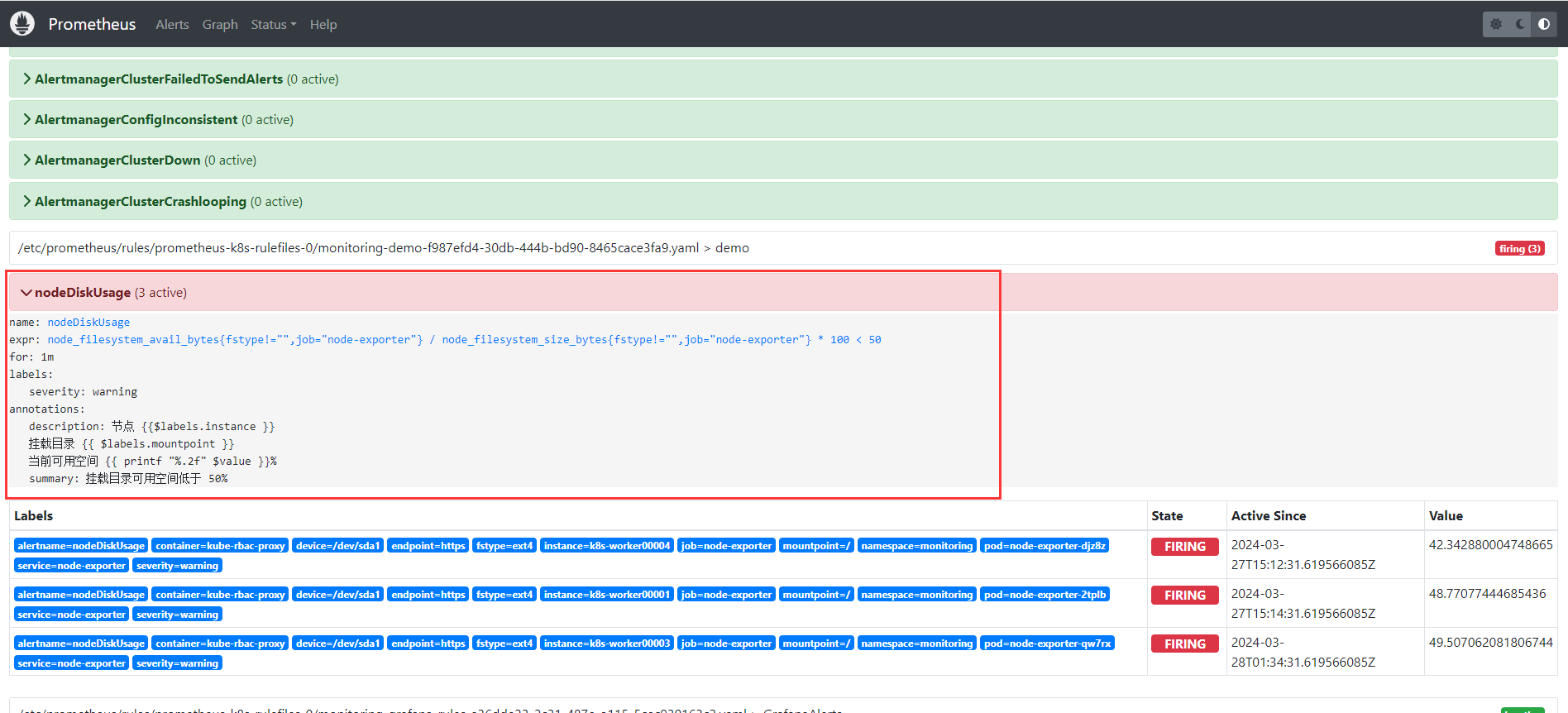
查看生成的告警规则, 当前状态是 pending ,我们设置了 1m 的评估等待时间。一分钟过后进入 firing 状态, 正式发出告警, 此时我们设置的 $label 还没有解析。
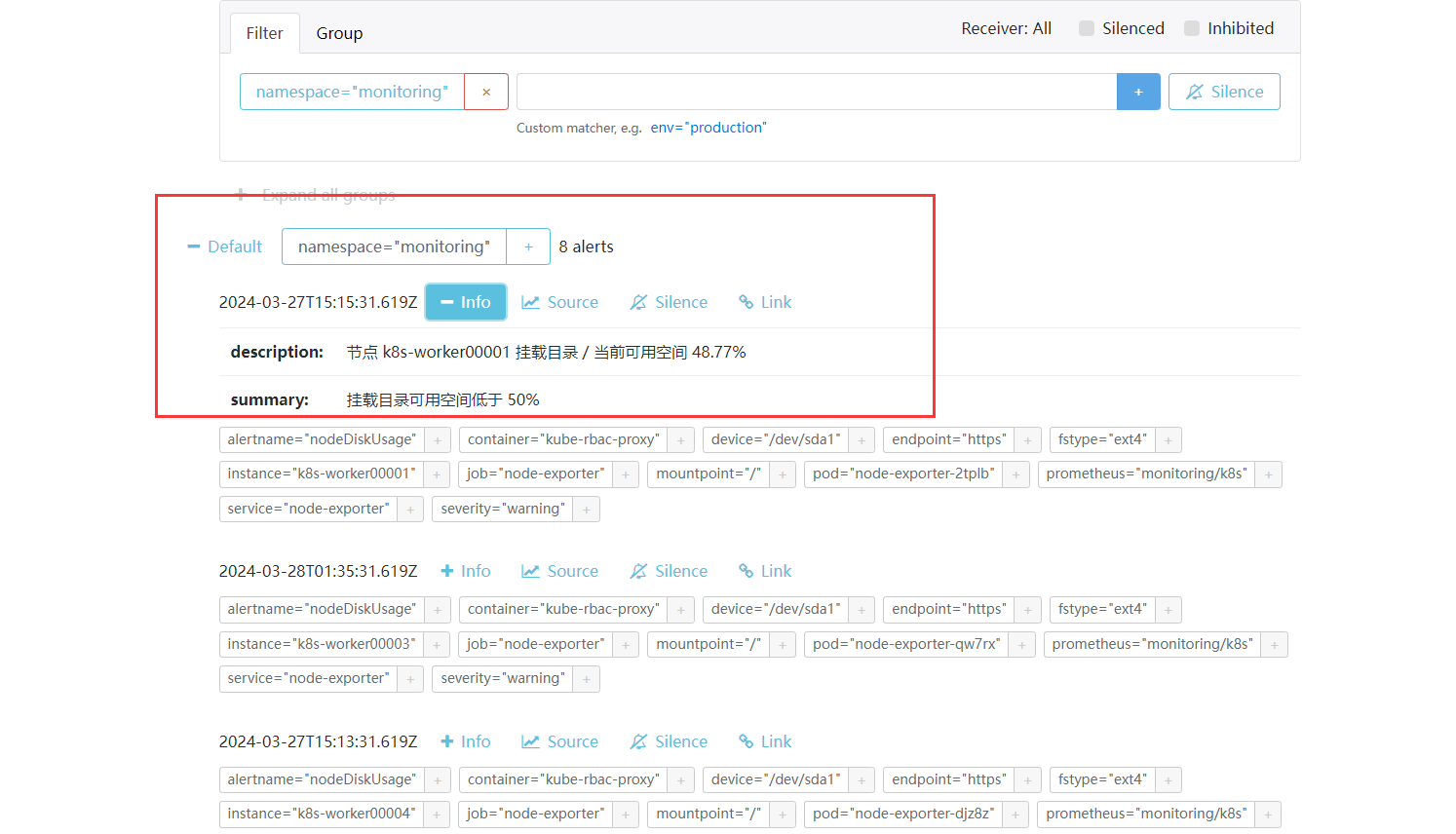
去 Alertmanager 看一下, 成功收到了告警, 且 labels和value 也已经正常解析了
详解上面rule流程
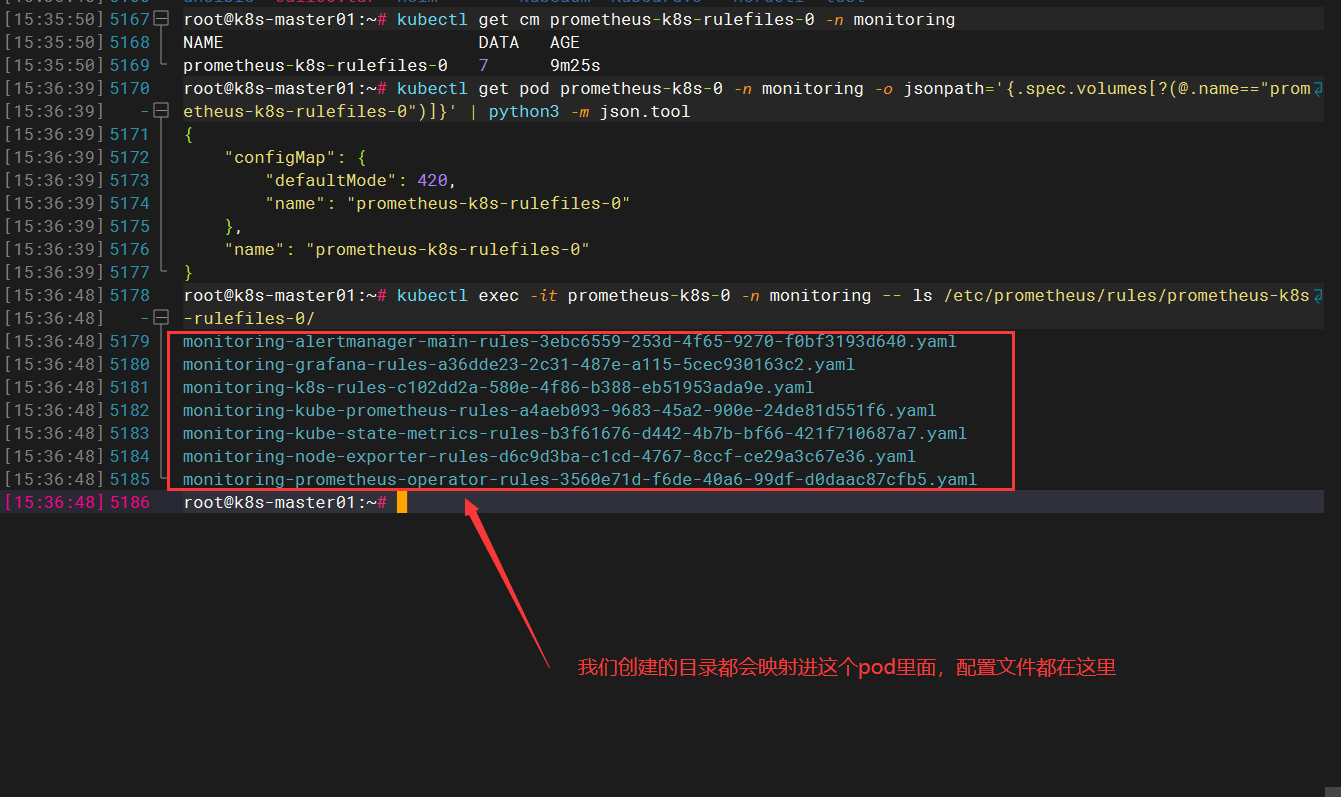
对于 prometheusrule 的更新操作 (create, delete, update) 都会被 watch 到, 然后更新到统一的一个 configmap 中, 然后 prometheus 自动重载配置
每个 prometheusrule 会作为 configmap prometheus-k8s-rulefiles-0 中的一个 data , data 的命名规则为 <namespace>-<rulename>-ruleuid
root@k8s-master01:~# kubectl get cm prometheus-k8s-rulefiles-0 -n monitoring
NAME DATA AGE
prometheus-k8s-rulefiles-0 7 9m25s
# prometheus 实例的挂载信息
root@k8s-master01:~# kubectl get pod prometheus-k8s-0 -n monitoring -o jsonpath='{.spec.volumes[?(@.name=="prometheus-k8s-rulefiles-0")]}' | python3 -m json.tool
{
"configMap": {
"defaultMode": 420,
"name": "prometheus-k8s-rulefiles-0"
},
"name": "prometheus-k8s-rulefiles-0"
}
# prometheus 中实际的存储路径
root@k8s-master01:~# kubectl exec -it prometheus-k8s-0 -n monitoring -- ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
monitoring-alertmanager-main-rules-3ebc6559-253d-4f65-9270-f0bf3193d640.yaml
monitoring-grafana-rules-a36dde23-2c31-487e-a115-5cec930163c2.yaml
monitoring-k8s-rules-c102dd2a-580e-4f86-b388-eb51953ada9e.yaml
monitoring-kube-prometheus-rules-a4aeb093-9683-45a2-900e-24de81d551f6.yaml
monitoring-kube-state-metrics-rules-b3f61676-d442-4b7b-bf66-421f710687a7.yaml
monitoring-node-exporter-rules-d6c9d3ba-c1cd-4767-8ccf-ce29a3c67e36.yaml
monitoring-prometheus-operator-rules-3560e71d-f6de-40a6-99df-d0daac87cfb5.yaml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Alertmanagerg查看
只有当我们设置的规则被触发了我们这边查看才会显示
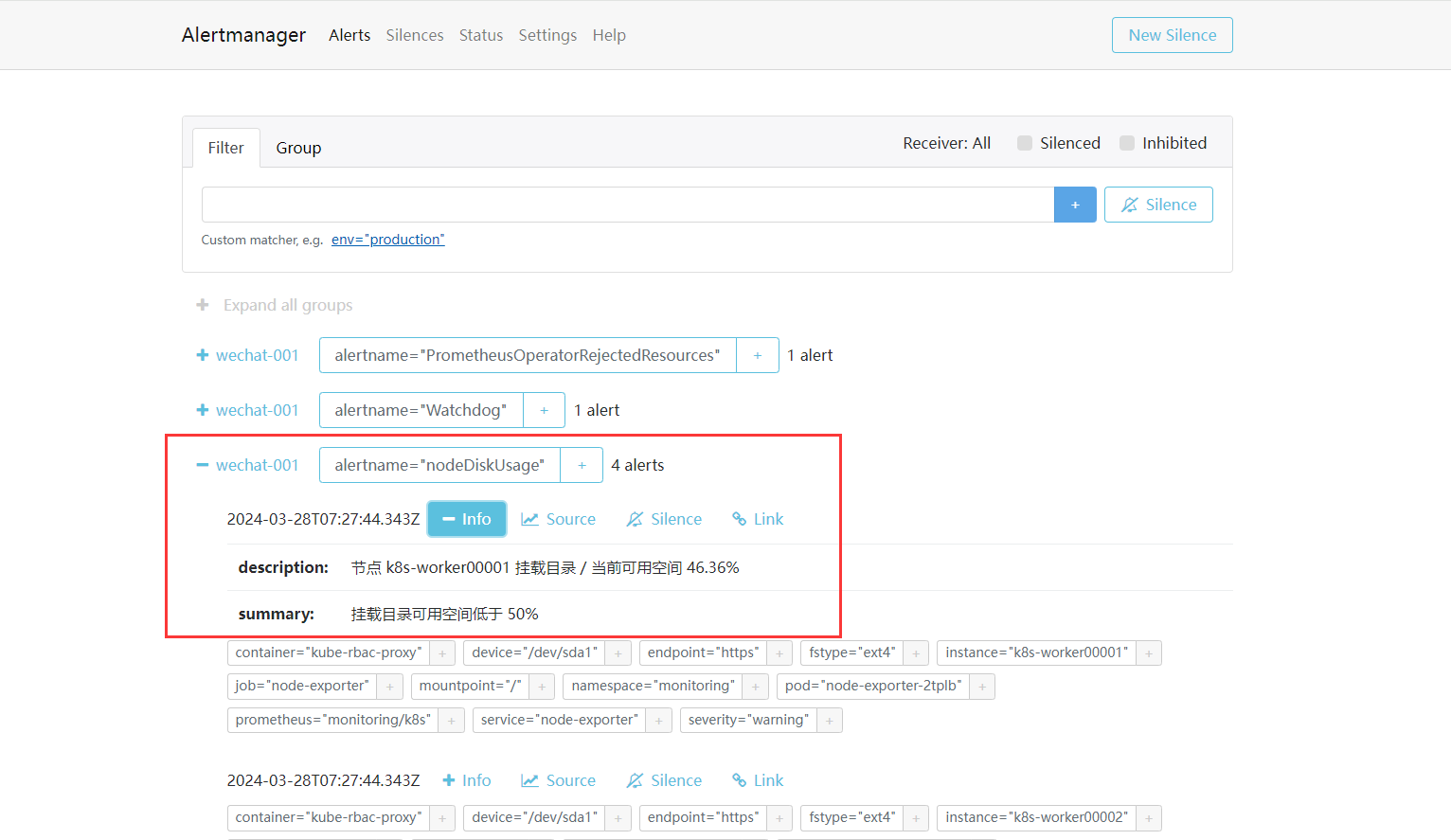
2-报警接收器
Alertmanager 支持很多内置的报警接收器,如 email、slack、企业微信、webhook 等。
2.1-邮件报警
修改Alertmanager配置
vim alertmanager.yaml # 新建的一个yaml
global:
resolve_timeout: 5m
smtp_from: '0@163.com'
smtp_smarthost: 'smtp.163.com:25'
smtp_auth_username: '@163.com'
smtp_auth_password: 'password'
smtp_require_tls: false
smtp_hello: '163.com'
templates:
- '/etc/alertmanager/configmaps/alertmanager-templates/*.tmpl'
route:
receiver: Default
group_by: ['alertname', 'cluster']
continue: false
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receivers:
- name: Default
email_configs:
- to: '@boysec.cn'
send_resolved: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
查看现有的secret alertmanager-main
默认的我们可以看到是没有配置接收器以及告警人
kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' |base64 -d
- 1
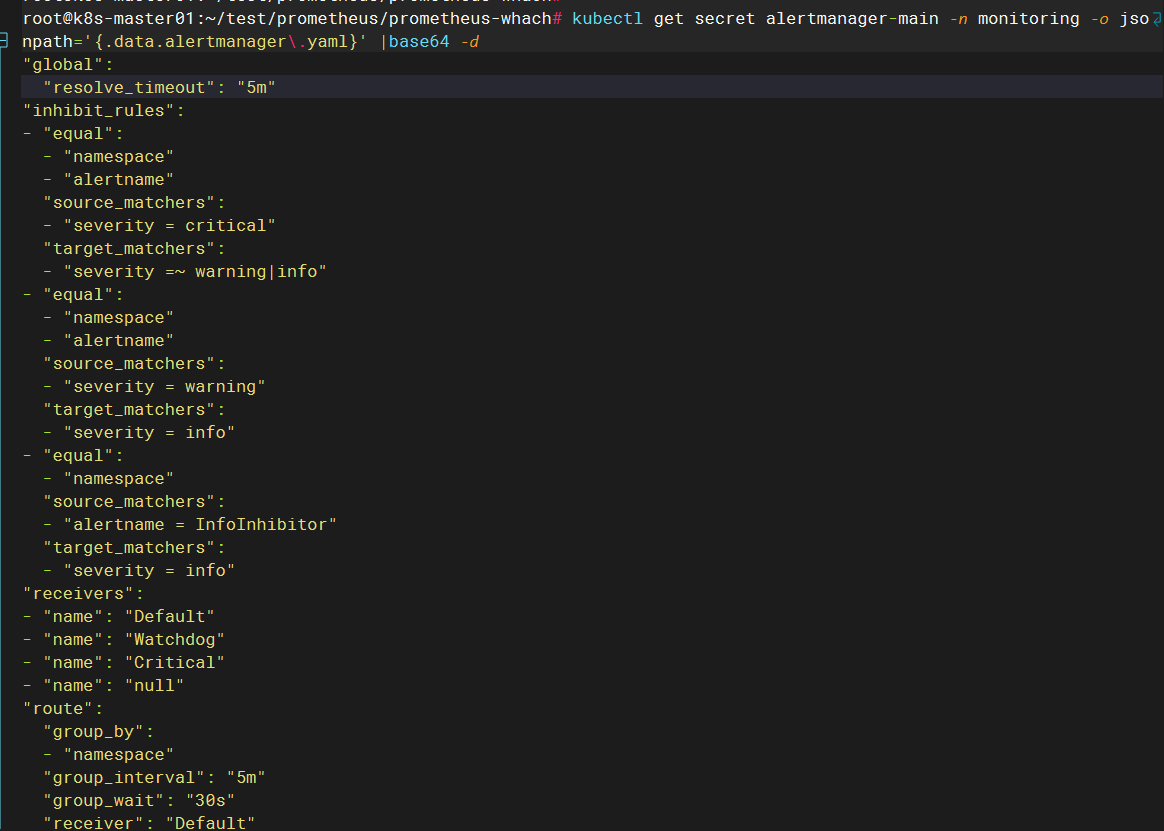
源配置文件
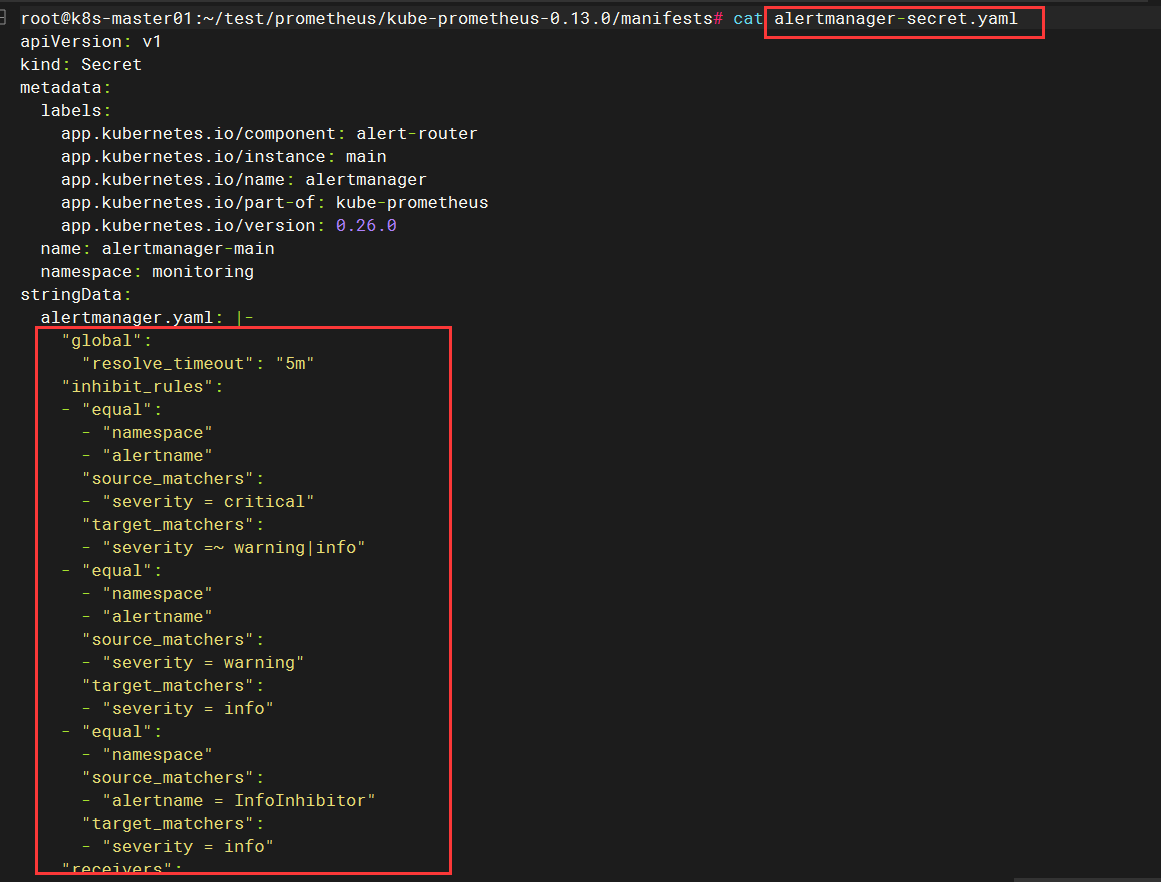
修改 secret alertmanager-main
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
kubectl apply -f alertmanager-main-secret.yaml
- 1
- 2
- 3
参数详解
- `kubectl create secret generic`: 这是创建一个通用类型的Secret的命令,它可以用于存储任何类型的敏感数据。
- `alertmanager-main`: 这是要创建的Secret的名称,这里命名为 `alertmanager-main`。
- `-n monitoring`: `-n` 参数用于指定命名空间,这里将Secret创建在名为 `monitoring` 的命名空间中。
- `--from-file=alertmanager.yaml`: `--from-file` 参数指定了要从文件中读取数据并将其存储在Secret中。在这里,`alertmanager.yaml` 文件中的内容将作为Secret的数据。
- `--dry-run=client`: 这个选项告诉 `kubectl` 仅模拟执行,而不会实际执行创建操作。这样可以将生成的YAML文件输出到标准输出,而不会真正创建Secret。
- `-o yaml`: `-o` 参数指定输出格式,这里指定为YAML格式。
- `> alertmanager-main-secret.yaml`: 将生成的YAML输出重定向到名为 `alertmanager-main-secret.yaml` 的文件中,以供后续使用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
总结
#个人总结就是 创建alertmanager.yaml文件的secret,然后导出成新的yaml,类似configmap。然后再去执行新生成的yaml文件,他就会挂载进pod里面
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
- 1
- 2
查看生成的 secret alertmanager-main
配置文件里面的模板就变成你改的模板了
kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' |base64 -d
- 1
3-AlertmanagerConfig 配置
新建一个 AlertmanagerConfig 类型的资源对象,可以通过 kubectl explain AlertmanagerConfig 或者在线 API 文档来查看字段的含义
3.1-创建alertmanagerconfig.yaml 邮件版本
这个是需要我们创建的,然后修改主alertmanager.yaml,对应标签
# vim alertmanagerconfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen #这里标签注意等下要用
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: '@boysec.cn'
sendResolved: true
webhookConfigs:
- url: http://dingtalk
sendResolved: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
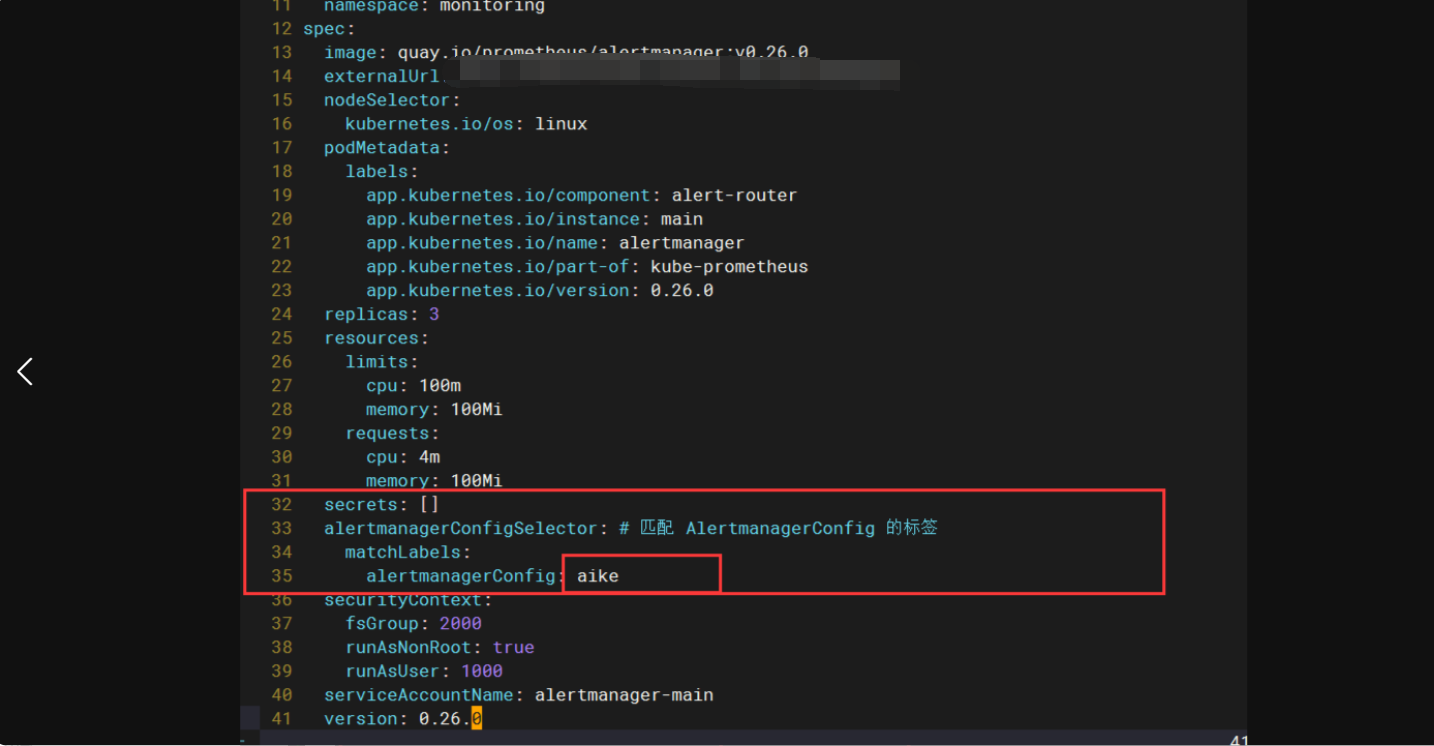
不过如果直接创建上面的配置是不会生效的,我们需要添加一个 Label 标签,并在 Alertmanager 的资源对象中通过标签来关联上面的这个对象,比如我们这里新增了一个 Label 标签:alertmanagerConfig: wangxiansen,然后需要重新更新 Alertmanager 对象,添加 alertmanagerConfigSelector 属性去匹配 AlertmanagerConfig 资源对象
3.2-修改alertmanager-alertmanager.yaml
我的这个主配置文件路径在kube-prometheus-0.13.0/manifests
# vim alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
name: main
namespace: monitoring
spec:
image: quay.io/prometheus/alertmanager:v0.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
replicas: 1 # 资源问题,这里就先启动一个pods
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
secrets: []
alertmanagerConfigSelector: # 匹配 AlertmanagerConfig 的标签
matchLabels:
alertmanagerConfig: wangxiansen # 这个是上面要记得标签
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: 0.26.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
4-告警模板
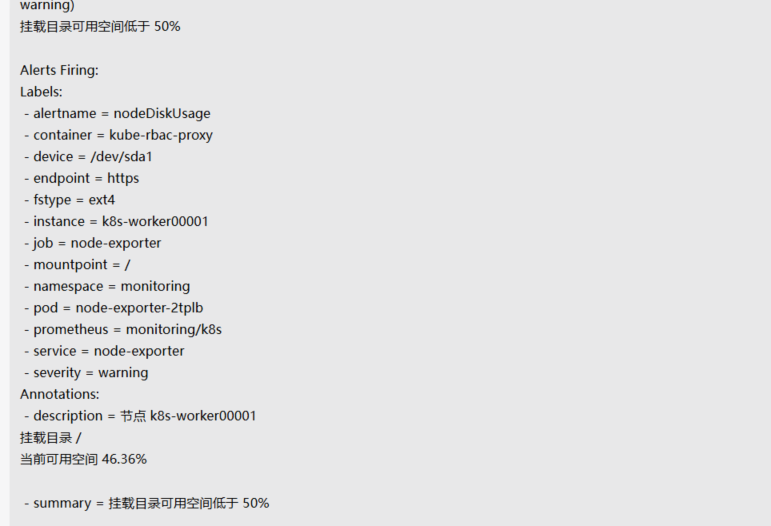
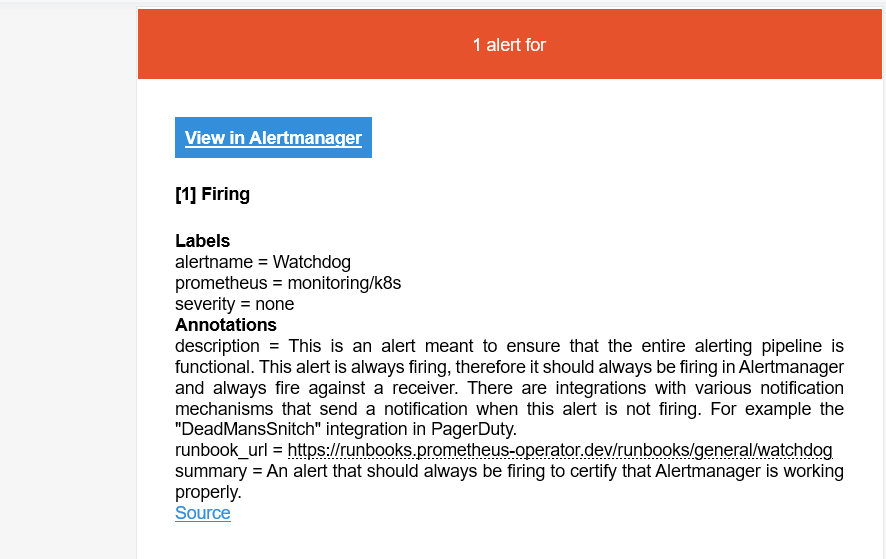
Alertmanager 收到的告警大概长这个样子
4.1-Alertmanager CRD 支持 configMaps 参数, 会自动挂载到 /etc/alertmanager/configmaps 目录, 我们可以将模板文件配置成 configmap,创建模板文件 email.tmpl
vim email.tmpl
{{ define "email.html" }}
<html>
<body>
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
<p>========= ERROR ==========</p>
<h3 style="color:red;">告警名称: {{ .Labels.alertname }}</h3>
<p>告警级别: {{ .Labels.severity }}</p>
<p>告警机器: {{ .Labels.instance }} {{ .Labels.device }}</p>
<p>告警详情: {{ .Annotations.summary }}</p>
<p>告警时间: {{ time (unixMillis .StartsAt) "2006-01-02 15:04:05" }}</p>
<p>========= END ==========</p>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
<p>========= INFO ==========</p>
<h3 style="color:green;">告警名称: {{ .Labels.alertname }}</h3>
<p>告警级别: {{ .Labels.severity }}</p>
<p>告警机器: {{ .Labels.instance }}</p>
<p>告警详情: {{ .Annotations.summary }}</p>
<p>告警时间: {{ time (unixMillis .StartsAt) "2006-01-02 15:04:05" }}</p>
<p>恢复时间: {{ time (unixMillis .EndsAt) "2006-01-02 15:04:05" }}</p>
<p>========= END ==========</p>
{{- end }}
{{- end }}
</body>
</html>
{{- end }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
4.2-创建 configmap
kubectl create configmap alertmanager-templates --from-file=email.tmpl --dry-run=client -o yaml -n monitoring > alertmanager-configmap-templates.yaml kubectl apply -f alertmanager-configmap-templates.yaml
- 1
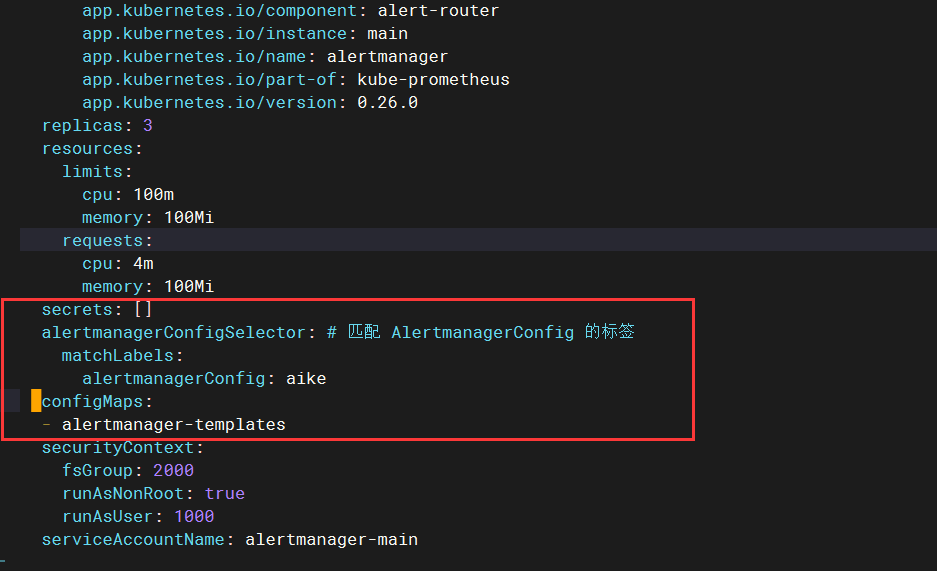
4.3-更新 Alertmanager 示例, 添加 configmap
vim alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
spec:
.....
alertmanagerConfigSelector:
matchLabels:
alertmanager: main
configMaps:
- alertmanager-templates
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.4-修改 AlertmanagerConfig 配置文件, 指定模板文件
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: 'xxxxx@boysec.cn'
html: '{{ template "email.html" . }}' # 添加 与模板中的 define 对应
sendResolved: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
更新报警配置
kubectl apply -f alertmanagerconfig.yaml
- 1
查看新生成的告警邮件
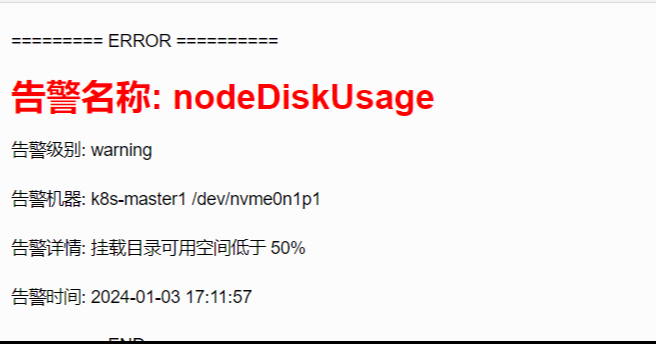
企业微信报警
1告警规则这个自定义的有点长,我后面单独发一篇博客
2-修改Alertmanager配置
vim alertmanager.yaml # 新建的一个yaml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: ''
smtp_auth_username: ''
smtp_auth_password: ''
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: wechat-001
receivers:
- name: 'wechat-001'
wechat_configs:
- corp_id: xxxx # 企业ID
to_user: '@all' # 发送所有人
agent_id: xxxx # agentID
api_secret: # secret
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
步骤跟邮件告警一样,参考上面
3-AlertmanagerConfig 配置
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: aike # 标识此配置对象的标签,用于分类和识别
spec:
route: # 警报路由配置
groupBy: ['alertname'] # 根据警报名称分组
groupWait: 30s # 组等待时间
groupInterval: 5m # 组间隔时间
repeatInterval: 12h # 重复间隔时间
receiver: 'Critical' # 默认接收器
continue: false # 是否继续路由
routes:
- receiver: 'Critical'
match:
severity: critical # 匹配严重程度为 critical 的警报
receivers: # 接收器配置
- name: Critical # 接收器名称
emailConfigs: # 邮件配置,用于发送邮件通知
- to: '' # 接收邮件的邮箱地址
html: '{{ template "email.html" . }}' # 添加 与模板中的 define 对应
sendResolved: true # 发送解决警报的通知
webhookConfigs: # Webhook 配置,用于发送警报通知至钉企业微信
- url: # Webhook URL
sendResolved: true # 发送解决警报的通知
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
修改alertmanager-alertmanager.yaml
步骤一样 省略
企业微信告警模板
{{ define "email.html" }}
<html>
<body>
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
<p>========= xxx环境监控报警 =========</p>
<p>告警状态:{{ .Status }}</p>
<p>告警级别:{{ .Labels.severity }}</p>
<p>告警类型:{{ $alert.Labels.alertname }}</p>
<p>故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }}</p>
<p>告警主题: {{ $alert.Annotations.summary }}</p>
<p>告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description }}</p>
<p>触发阀值:{{ .Annotations.value }}</p>
<p>故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</p>
<p>========= end =========</p>
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
<p>========= xxx环境异常恢复 =========</p>
<p>告警类型:{{ .Labels.alertname }}</p>
<p>告警状态:{{ .Status }}</p>
<p>告警主题: {{ $alert.Annotations.summary }}</p>
<p>告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description }}</p>
<p>故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</p>
<p>恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</p>
{{- if gt (len $alert.Labels.instance) 0 }}
<p>实例信息: {{ $alert.Labels.instance }}</p>
{{- end }}
<p>========= end =========</p>
{{- end }}
{{- end }}
{{- end }}
</body>
</html>
{{- end }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
流程大概就是这样。。。。
然后进行一下热更新
什么是热更新
为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效
怎么热更新
举例:如修改prometheus-cfg.yaml,想要使配置生效可如下操作
# 修改prometheus-cfg.yaml后
kubectl delete -f /root/k8s/monitor/prometheus-cfg.yaml
kubectl apply -f /root/k8s/monitor/prometheus-cfg.yaml
# 告诉prometheus-deploy.yaml 需要重新加载 prometheus-cfg.yaml文件的内容
curl -X POST http://10.244.1.52:9090/-/reload
- 1
- 2
- 3
- 4
- 5
- 6
查看prometheus的pod的ip地址
kubectl get pods -n monitoring -o wide | grep prometheus
- 1

