
热门标签
热门文章
当前位置: article > 正文
python 虚拟变量(Dummy)/热编码(one-hot encoding)_python dummy
作者:知新_RL | 2024-02-10 18:20:23
赞
踩
python dummy
对于分类,pandas 编码有一种非常简单的方法,就是 get_dummies 函数。get_dummies 函数会自动变换所有具有对象类型(比如字符串)的列或所有分类的列,而分类特征的每个可能取值都会被扩展为一个新特征,并且每一个新特征只有 0、1 两种取值。这个过程就是虚拟变量的生成过程。
-
- # 把多分类字段转换为二分类虚拟变量
- category_features = ['城市'] #要转换的特征列表
- df_sales = pd.get_dummies(df_sales, drop_first=True, columns=category_features) #创建哑变量
- df_sales #显示数据
输出如下:
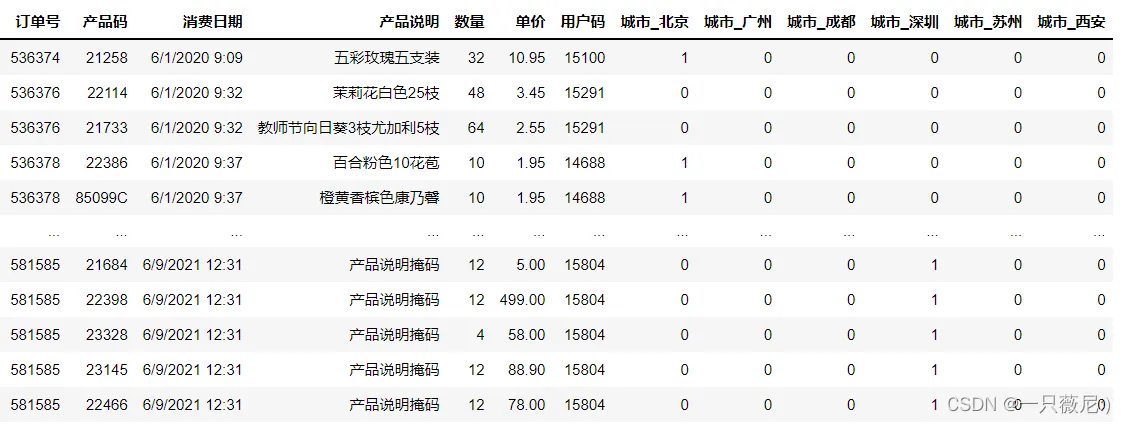
drop_first 参数
这个参数实际上控制着 get_dummies 函数返回的结果,值为 True 返回结果是虚拟变量(Dummy Variable),值为 False 则返回独热编码( One Hot Encoding)。
独热编码与虚拟变量的不同之处
在虚拟编码方案中,当特征具有 m 个不同类别标签时,我们将得到 m-1 个二进制特征,作为基准的特征被完全忽略;而在独热编码方案中,我们将得到 m 个二进制特征。因此,你仔细观察上面 get_dummies 的结果,就会发现“城市 _ 上海”这个特征没有被生成。而如果你把 drop_first 设为 False,“城市 _ 上海”就会出现。
什么时候使用虚拟变量,or独热编码呢?
如果线性模型有截距项,就使用虚拟变量;如果线性模型无截距项,那么使用独热编码。此外,在线性模型有截距项的情况下,如果使用正则化,那么也推荐使用独热编码,因为正则化能处理多余的自由度,可以约束参数;如果不使用正则化,那么就使用虚拟变量,这样多余的自由度都被统摄到截距项 intercept 里去了。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/74918
推荐阅读
相关标签

