
热门标签
热门文章
- 1Github开源项目---使用TF2.0对经典推荐论文进行复现【持续更新中...】
- 2AI技术:分享8个非常实用的AI绘画网站_ai绘画sd动作网站
- 3Windows源码编译运行pgAdmin4
- 4计算连续性状的PRS得分_prs评分
- 5Oracle 多个查询结果的交集、差集和并集_oracle 2个递归查询的交叉
- 6Spark安装-环境搭建_spark without hadoop
- 7mysql 函数和存储过程demo_$$gdatefrom
- 8scikit-learn构建模型_构建基于wine数据集的svm分类模型。 (1)读取wine数据集,区分标签和数据。 (2)将wi
- 9ROS2开发笔记之ROS2 Humble环境安装_ros2 humble的软件包
- 10vmware fusion下win7分辨率自动切换解决办法_vm虚拟机 还原窗口会切换分辨率
当前位置: article > 正文
决策树:什么是基尼系数(“杂质 增益 指数 系数”辨析)_决策树中gini是什么意思
作者:知新_RL | 2024-06-27 21:27:09
赞
踩
决策树中gini是什么意思
决策树:什么是基尼系数
在我翻译学习这篇Random Forests for Complete Beginners的时候,对基尼系数和它相关的一些中文表达充满了疑问,查了一些资料以后,完成了这篇文章。其中基尼杂质系数的计算和解释参考了A Simple Explanation of Gini Impurity。
如果你查看scikit-learn中DecisionTreeClassifier的文档,你会看到这样的参数:

RandomForestClassifier文档里也谈到了gini。那么两者都提到并作为默认标准的基尼系数是什么?
名词辨析
你在不同的地方往往能看到关于基尼的不同名词,我查询了一大堆文献,发现它们的使用遵循以下规律:
- 基尼杂质系数/基尼不纯系数(Gini Impurity):等效于我们通常说的基尼系数,在上面提到的分类器文档里的就是它,计算方法在后面将提到。
- 基尼增益系数/基尼系数增益(Gini Gain):表征某个划分对基尼系数的增益,使用原基尼杂质系数减去按样本占比加权的各个分支的基尼杂质系数来计算,计算方法在后面将提到。
- 基尼指数(Gini index):这是一个尴尬的问题,因为有人把它等价于gini impurity,但也有人把它用作gini coefficient。需要结合上下文来判断。
- 基尼系数(Gini coefficient):表征在二分类问题中,正负两种标签的分配合理程度。当G=0,说明正负标签的预测概率均匀分配,模型相当于是随机排序。这个名词也在经济学中也有使用,本质是相同的,是用来表征一个地区财富的分配的合理程度。当G=0,说明财富均匀分配。
基尼杂质系数(Gini Impurity)的理解和计算
训练决策树包括将当前数据分成两个分支。假设我们有以下数据点:
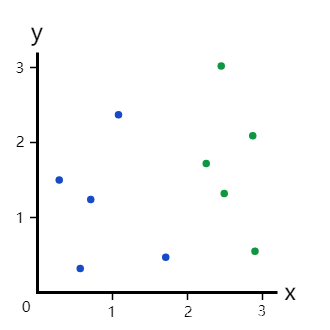
现在,我们的分支里有5个蓝点和5个绿点。
如果我们在x=2处进行划分:

这很明显是个完美划分,因为它把数据集分成了两个分支:
- 左分支全是蓝点
- 右分支全是绿点
但如果我们在x=1.5处进行划分呢?
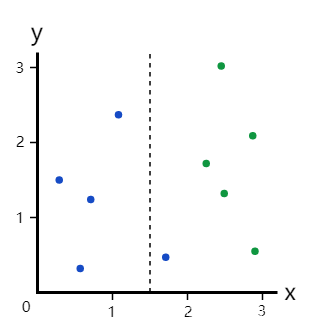
这个划分把数据集分成了两个分支:
- 左分支,4个蓝点
- 右分支,1个蓝点+5个绿点
很明显,这种划分更糟糕,但我们如何量化呢?
解决方法就是基尼杂质系数。
示例1:整个数据集
我们来计算整个数据集的基尼杂质系数。
如果随机选择一个数据点并随机给它分类,我们错误分类数据点的概率是多少?
| 我们的选择 | 实际的分类 | 可能性 | 对错 |
|---|---|---|---|
| 蓝 | 蓝 | 25% | ✓ |
| 红 | 蓝 | 25% | ❌ |
| 蓝 | 红 | 25% | ❌ |
| 红 | 红 | 25% | ✓ |
我们只在上面的两个事件中对其进行了错误的分类。因此,我们的错误概率是25% + 25% = 50%,也即基尼杂质系数是0.5.
公式
G = ∑ i = 1 C p ( i ) ∗ [ 1 − p ( i ) ] G = \sum_{i=1}^C {p(i)*[1-p(i)]} G=i=1∑Cp(i)∗[1−p(i)]
- C: 类别数
- p(i):一个样本被归类进第i类的概率
上面这个例子计算式即为:
G = p ( 1 ) ∗ [ 1 − p ( 1 )
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/763803?site
推荐阅读

相关标签

