
- 1点云的凹多边形和凸多边形边界获取(附open3d python 代码)_python 点云内围轮廓
- 2【智能金融】【风控】探索大数据时代风控模型技术和应用_继续探索大数据风控建设
- 3大模型日报2024-05-25_hipporag
- 4【人工智能】“AI + 算力 = 最强龙头”,你怎么看?_ai+算力+网络安全龙头
- 5若依前后台分离vue版,前台使用echarts动态调用后台数据_ruoyi -vue 引入echart
- 6目标检测算法之评价标准和常见数据集盘点_目标识别准确率计算表格
- 7基于大数据爬虫技术起点小说数据分析与可视化平台设计和实现(源码+LW+部署讲解)
- 8RT_Thread 文件系统的使用_rt-thread创建文件
- 9RabbitMQ(八):SpringBoot 整合 RabbitMQ(三种消息确认机制以及消费端限流)_rabbitmq消费确认机制 maven
- 10【数字电路】数字电路的学习核心
传神社区|数据集合集第4期|中文NLP数据集合集
赞
踩
自从ChatGPT等大型语言模型(Large Language Model, LLM)出现以来,其类通用人工智能(AGI)能力引发了自然语言处理(NLP)领域的新一轮研究和应用浪潮。尤其是ChatGLM、LLaMA等普通开发者都能运行的较小规模LLM开源之后,业界涌现了大量基于LLM的二次微调和应用案例。
传神社区(Opencsg)旨在收集和整理与中文NLP相关的开源数据集。目前每篇文章整理的资源至少15个!如果本篇文章对您有帮助,欢迎点赞与收藏~
我们也欢迎大家贡献本文未收录的开源数据集,提供对应的资源,描述与链接,感谢您的支持!
目录
1. 文本分类
-
-
-
1.1 初等数学应用问题 (MWP) 的挑战集
-
1.2 多元化数学应用题
-
1.3 数学单词问题数据集
-
1.4 中文生物医学文本
-
1.5 中文谣言数据
1.6 新闻语料库
-
1.7 百度知道问答语料库
-
-
-
2.词库及词法工具
-
-
2.1 textfilter词库
-
2.2 人名抽取功能词法工具
-
2.3 中文缩写库数据集
-
2.4 汉语拆字词典数据集
-
2.5 词汇情感值数据集
-
2.6 中文词库、停用词、敏感词数据集
-
2.7 汉字拼音转换工具
-
2.8 中文繁简体互转数据集
-
-
01 文本分析
1.1 初等数学应用问题 (MWP) 的挑战集
SVAMP:
简介:初等数学应用问题 (MWP) 的挑战集。MWP 由一个简短的自然语言叙述组成,它描述了世界的一种状态,并提出了一个关于一些未知量的问题。SVAMP 中的示例在解决 MWP 的不同方面测试模型:1) 模型问题是否敏感?2)模型是否具有鲁棒的推理能力?3)结构变化是否不变?
地址:https://opencsg.com/datasets/OpenDataLab/SVAMP

1.2 多元化数学应用题
DMath:
简介:DMath(多元化数学应用题),这是论文“ It Ain't Over: A Multi-aspect Diverse Math Word Problem Dataset ”的 10K 高质量小学水平数学应用题的集合。
地址:https://opencsg.com/datasets/OpenDataLab/DMath

1.3 数学单词问题数据集
Ape210K:
简介:Ape210K是一个新的大规模和模板丰富的数学单词问题数据集,包含 210K 个中国小学水平的数学问题,是最大的公共数据集 Math23K 的 9 倍。每个问题都包含黄金答案和得出答案所需的方程式。Ape210K 也具有更大的多样性,有 56K 个模板,是 Math23K 的 25 倍。我们的分析表明,解决 Ape210K 不仅需要自然语言理解,还需要常识知识。
地址:https://opencsg.com/datasets/OpenDataLab/Ape210K

1.4 中文生物医学文本
ChineseBlue:
简介:ChinesseBLUE基准测试由不同的生物医学文本挖掘任务组成。这些任务涵盖了不同的文本类型(生物医学网络数据和临床记录)、数据集大小和难度级别,更重要的是,突出了常见的生物医学文本挖掘挑战。
地址:https://opencsg.com/datasets/billionaire/ChineseBlue
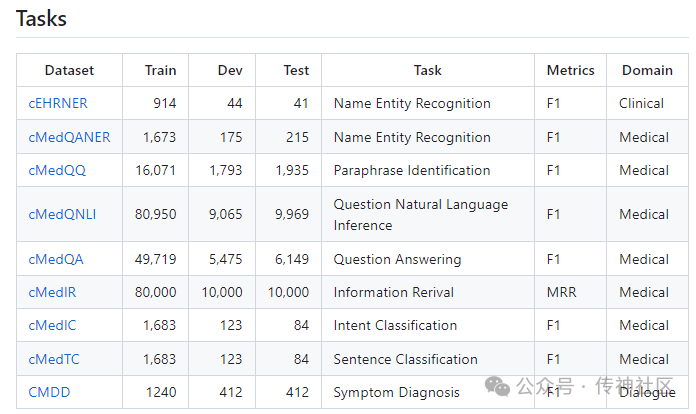
1.5 中文谣言数据
Chinese_Rumor_Dataset:
简介:第一部分数据集(./rumors_v170613.json)共包含从2009年9月4日至2017年6月12日的31669条谣言。
地址:https://opencsg.com/datasets/MagicAI/Chinese_Rumor_Dataset

1.6 新闻语料库
PeoplesDaily:
简介:1946年-2003年人民日报 新闻语料库。
地址:https://opencsg.com/datasets/crazyqq/PeoplesDaily
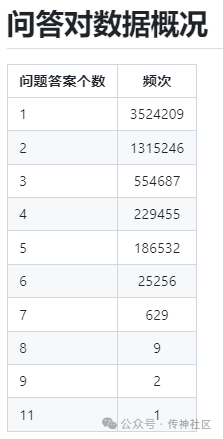
1.7 百度知道问答语料库
MiningZhiDaoQACorpus:
简介:580万百度知道问答数据挖掘项目,百度知道问答语料库,包括超过580万的问题,每个问题带有问题标签。基于该问答语料库,可支持多种应用,如逻辑挖掘。
地址:https://opencsg.com/datasets/MagicAI/MiningZhiDaoQACorpus
2.词库及词法工具
2.1 textfilter词库
textfilter:
简介:敏感词过滤的几种实现+某1w词敏感词库
地址:https://opencsg.com/datasets/MagicAI/textfilter

2.2 人名抽取功能词法工具
cocoNLP:
简介:这是一个中文自然语言处理(NLP)包,可以从文本中提取信息。
地址:https://opencsg.com/datasets/MagicAI/cocoNLP

2.3 中文缩写库数据集
Chinese-abbreviation-dataset:
简介:这是论文《A Chinese Dataset with Negative Full Forms for General Abbreviation Prediction》发布的数据集。
地址:https://opencsg.com/datasets/MagicAI/Chinese-abbreviation-dataset

2.4 汉语拆字词典数据集
chaizi:
简介:膂 | 旅 肉 | 旅 月 鋓 | 金 利 | 釒 利 迴 | 辵 回 | 辶 回 証 | 言 正 | 訁 正
目前一字最多可以有六(6)種拆法,例如:
| 漢字 | 拆法 (一) | 拆法 (二) | 拆法 (三) | 拆法 (四) | 拆法 (五) | 拆法 (六) |
| 絕 | 絲 刀 巴 | 糹 刀 巴 | 糸 刀 巴 | 絲 色 | 糹 色 | 糸 色 |
| 拼 | 手 并 | 扌 并 | 才 并 | 手 幷 | 扌 幷 | 才 幷 |
| 鋶 | 金 亠 厶 川 | 釒 亠 厶 川 | 金 巟 | 釒 巟 | 金 㐬 | 釒 㐬 |
地址:https://opencsg.com/datasets/MagicAI/chaizi
2.5 词汇情感值数据集
SentiBridge:
简介:本词典包含:实体/属性—情感词。例如:“长城 宏伟”、“性价比 高”、“价格 高”。主要目的是刻画人们是怎么描述某个实体的,例如大家通常用 宏伟 来形容长城。
目前词典包含三个领域语料的抽取结果:新闻、旅游、餐饮,共计30万对。
地址:https://opencsg.com/datasets/MagicAI/SentiBridge

2.6 中文词库、停用词、敏感词数据集
Chinese_from_dongxiexidian:
简介:包含素材:Files --
分词词典: 综合了百度、搜狗等词库,以及手动整理的若干人名和新近出现的热词
中文停用词: 综合了"百度停用词表","哈工大停用词表","四川大学机器学习实验室停用词表"等若干停用词表,取交集并去除了不需要的标点符号和英文单词
地址:https://opencsg.com/datasets/MagicAI/Chinese_from_dongxiexidian
2.7 汉字拼音转换工具
python-pinyin:
简介:将汉字转为拼音。可以用于汉字注音、排序、检索(Russian translation_) 。
最初版本的代码参考了 hotoo/pinyin <https://github.com/hotoo/pinyin>__ 的实现。
-
Documentation: https://pypinyin.readthedocs.io/
-
GitHub: https://github.com/mozillazg/python-pinyin
-
License: MIT license
-
PyPI: https://pypi.org/project/pypinyin
-
Python version: 2.7, pypy, pypy3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 3.10, 3.11, 3.12
地址:https://opencsg.com/datasets/MagicAI/python-pinyin

2.8 中文繁简体互转
zhtools:
简介:一些大概没有用了的与 NScript 有关的东西。
License: GPLv2
但 nstemplate.py 和 portable.py 除外。它们并不依赖任何 GPL 项目,并且可以单独运行。这两者均是 Public Domain 的。
gbk2sjis.py 将简体 nscript.dat/00~99.txt 转换为日文编码。
对不支持 GBK 而仅支持日文编码的 ONS 模拟器,当运行简体移植的时候会乱码。这个工具能将原脚本转换为日文编码。
由于很多汉字在日文中并不存在,故会进行简繁转换和一些字符替换。部分无法自动处理的字符替换定义在 gbk2sjis.dat 中。
地址:https://opencsg.com/datasets/MagicAI/zhtools

欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/778806
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

