
- 1Nerf学习笔记(1)--简介_nerf 的法线
- 2Session攻击手段(会话劫持/固定)及其安全防御措施_session固定
- 3NFT将变成Web3钱包?了解以太坊新标准——ERC-6551
- 4Docker部署单机rabbitmq_docker 安装离线rabbitmq
- 5测试面试题_下列选项中 用于执行测试用例或测试套件并返回测试结果的是
- 6【实用教程】使用AlphaFold2进行蛋白质结构在线预测
- 7大学生毕设神器 | 全国天气分析 全国天气爬虫 基于Python的全国天气可视化分析 基于大数据的全国天气可视化分析 基于sklearn的全国天气预测_基于python的天气预报系统设计和可视化数据分析
- 8华为云正式发布Workspace on CloudPond,一文了解所有亮点
- 9Spock测试框架中的注解使用_spock 注解@see
- 10华为OD机试C卷-- 最富裕的小家庭(Java & JS & Python & C)_在一棵树中,每个节点代表一个家庭成员,节点的数字表示其个人的财富值
【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板_chattts:开源文本转语音大模型
赞
踩

目录
一、引言
我很愿意推荐一些小而美、高实用模型,比如之前写的YOLOv10霸榜百度词条,很多人搜索,仅需100M就可以完成毫秒级图像识别与目标检测,相关的专栏也是CSDN付费专栏中排行最靠前的。今天介绍有一个小而美、高实用性的模型:ChatTTS。
二、TTS(text-to-speech)模型原理
2.1 VITS 模型架构
由于ChatTTS还没有公布论文,我们也不好对ChatTTS的底层原理进行武断。这里对另一个TTS里程碑模型VITS原理进行简要介绍,让大家对TTS模型原理有多认知。VITS详细论文见链接
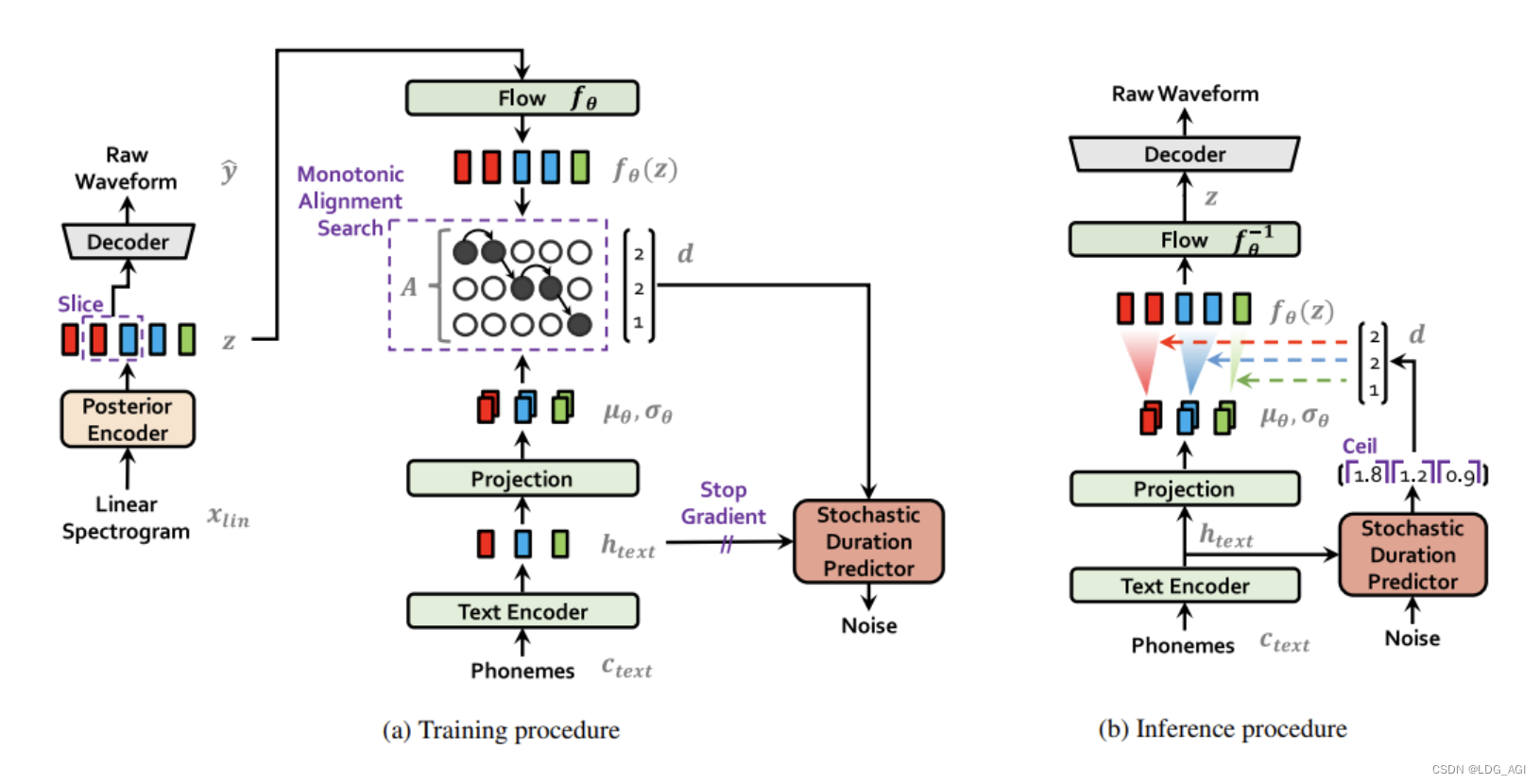
VITS论文对训练和推理两个环节分别进行讲述:
2.2 VITS 模型训练
VITS模型训练:在训练阶段,音素(Phonemes)可以被简单理解为文字对应的拼音或音标。它们经过文本编码(Text Encode)和映射(Projection)后,生成了文本的表示形式。左侧的线性谱(Linear Sepctrogram)是从用于训练的音频中提取的 wav 文件的音频特征。这些特征通过后验编码器(Posteritor)生成音频的表示,然后通过训练对齐这两者(在模块 A 中)。节奏也是表达的重要因素,因此还加入了一个随机持续时间预测器(Stochasitic Duration Predictor)模块,根据音素和对齐结果对输出音频长度进行调整。
2.3 VITS 模型推理
VITS模型推理:在推理过程中,输入是文本对应的音素。将映射和对长度采样输入模型,将其转换为语音表示流,然后通过解码器将其转换为音频格式。
根据论文中描述的逻辑,文本数据被转换为音素(即词的拼音)并输入模型。模型学习了音素与音频之间的关系,包括说话者的音质、音高、口音和发音习惯等。
三、ChatTTS 模型实战
3.1 ChatTTS 简介
ChatTTS 是一款专门为对话场景(例如 LLM 助手)设计的文本转语音模型。
3.2 ChatTTS 亮点
- 对话式 TTS: ChatTTS 针对对话式任务进行了优化,能够实现自然且富有表现力的合成语音。它支持多个说话者,便于生成互动式对话。
- 精细的控制: 该模型可以预测和控制精细的韵律特征,包括笑声、停顿和插入语。
- 更好的韵律: ChatTTS 在韵律方面超越了大多数开源 TTS 模型。我们提供预训练模型以支持进一步的研究和开发。
3.3 ChatTTS 数据集
- 主模型使用了 100,000+ 小时的中文和英文音频数据进行训练。
- HuggingFace 上的开源版本是一个在 40,000 小时数据上进行无监督微调的预训练模型。
3.4 ChatTTS 部署
3.4.1 创建conda环境
- conda create -n chattts
- conda activate chattts
3.4.2 拉取源代码
- git clone https://github.com/2noise/ChatTTS
- cd ChatTTS
3.4.3 安装环境依赖
pip install -r requirements.txt3.4.4 启动WebUI
- export CUDA_VISIBLE_DEVICES=3 #指定显卡
- nohup python examples/web/webui.py --server_name 0.0.0.0 --server_port 8888 > chattts_20240624.out 2>&1 & #后台运行
执行后会自动跳转出webui,地址为server_name:server_port
3.4.5 WebUI推理
个人感觉:其中夹杂着“那个”、“然后”、“嗯...”等口头禅,学的太逼真了,人类说话不就是这样么。。

- [uv_break]、[laugh]等符号进行断句、微笑等声音控制。
- Audio Seed:用于初始化随机数生成器的种子值。设置相同的 Audio Seed 可以确保重复生成一致的语音,便于实验和调试。推荐 Seed: 3798-知性女、462-大舌头女、2424-低沉男。
- Text Seed:类似于 Audio Seed,在文本生成阶段用于初始化随机数生成器的种子值。
- Refine Text:勾选此选项可以对输入文本进行优化或修改,提升语音的自然度和可理解性。
- Audio Temperature️:控制输出的随机性。数值越高,生成的语音越可能包含意外变化;数值较低则趋向于更平稳的输出。
- Top_P:核采样策略,定义概率累积值,模型将只从这个累积概率覆盖的最可能的词中选择下一个词。
- Top_K:限制模型考虑的可能词汇数量,设置为一个具体数值,模型将只从这最可能的 K 个词中选择下一个词。
3.5 ChatTTS 代码
- import os, sys
-
- if sys.platform == "darwin":
- os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-
- now_dir = os.getcwd()
- sys.path.append(now_dir)
-
- import random
- import argparse
-
- import torch
- import gradio as gr
- import numpy as np
-
- from dotenv import load_dotenv
- load_dotenv("sha256.env")
-
- import ChatTTS
-
- # 音色选项:用于预置合适的音色
- voices = {
- "默认": {"seed": 2},
- "音色1": {"seed": 1111},
- "音色2": {"seed": 2222},
- "音色3": {"seed": 3333},
- "音色4": {"seed": 4444},
- "音色5": {"seed": 5555},
- "音色6": {"seed": 6666},
- "音色7": {"seed": 7777},
- "音色8": {"seed": 8888},
- "音色9": {"seed": 9999},
- "音色10": {"seed": 11111},
- }
-
- def generate_seed():
- new_seed = random.randint(1, 100000000)
- return {
- "__type__": "update",
- "value": new_seed
- }
-
- # 返回选择音色对应的seed
- def on_voice_change(vocie_selection):
- return voices.get(vocie_selection)['seed']
-
- def generate_audio(text, temperature, top_P, top_K, audio_seed_input, text_seed_input, refine_text_flag):
-
- torch.manual_seed(audio_seed_input)
- rand_spk = chat.sample_random_speaker()
- params_infer_code = {
- 'spk_emb': rand_spk,
- 'temperature': temperature,
- 'top_P': top_P,
- 'top_K': top_K,
- }
- params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}
-
- torch.manual_seed(text_seed_input)
-
- if refine_text_flag:
- text = chat.infer(text,
- skip_refine_text=False,
- refine_text_only=True,
- params_refine_text=params_refine_text,
- params_infer_code=params_infer_code
- )
-
- wav = chat.infer(text,
- skip_refine_text=True,
- params_refine_text=params_refine_text,
- params_infer_code=params_infer_code
- )
-
- audio_data = np.array(wav[0]).flatten()
- sample_rate = 24000
- text_data = text[0] if isinstance(text, list) else text
-
- return [(sample_rate, audio_data), text_data]
-
-
- def main():
-
- with gr.Blocks() as demo:
- gr.Markdown("# ChatTTS Webui")
- gr.Markdown("ChatTTS Model: [2noise/ChatTTS](https://github.com/2noise/ChatTTS)")
-
- default_text = "四川美食确实以辣闻名,但也有不辣的选择。[uv_break]比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。[laugh]"
- text_input = gr.Textbox(label="Input Text", lines=4, placeholder="Please Input Text...", value=default_text)
-
- with gr.Row():
- refine_text_checkbox = gr.Checkbox(label="Refine text", value=True)
- temperature_slider = gr.Slider(minimum=0.00001, maximum=1.0, step=0.00001, value=0.3, label="Audio temperature")
- top_p_slider = gr.Slider(minimum=0.1, maximum=0.9, step=0.05, value=0.7, label="top_P")
- top_k_slider = gr.Slider(minimum=1, maximum=20, step=1, value=20, label="top_K")
-
- with gr.Row():
- voice_options = {}
- voice_selection = gr.Dropdown(label="音色", choices=voices.keys(), value='默认')
- audio_seed_input = gr.Number(value=2, label="Audio Seed")
- generate_audio_seed = gr.Button("\U0001F3B2")
- text_seed_input = gr.Number(value=42, label="Text Seed")
- generate_text_seed = gr.Button("\U0001F3B2")
-
- generate_button = gr.Button("Generate")
-
- text_output = gr.Textbox(label="Output Text", interactive=False)
- audio_output = gr.Audio(label="Output Audio")
-
- # 使用Gradio的回调功能来更新数值输入框
- voice_selection.change(fn=on_voice_change, inputs=voice_selection, outputs=audio_seed_input)
-
- generate_audio_seed.click(generate_seed,
- inputs=[],
- outputs=audio_seed_input)
-
- generate_text_seed.click(generate_seed,
- inputs=[],
- outputs=text_seed_input)
-
- generate_button.click(generate_audio,
- inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],
- outputs=[audio_output, text_output])
-
- gr.Examples(
- examples=[
- ["四川美食确实以辣闻名,但也有不辣的选择。比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。", 0.3, 0.7, 20, 2, 42, True],
- ["What is [uv_break]your favorite english food?[laugh][lbreak]", 0.5, 0.5, 10, 245, 531, True],
- ["chat T T S is a text to speech model designed for dialogue applications. [uv_break]it supports mixed language input [uv_break]and offers multi speaker capabilities with precise control over prosodic elements [laugh]like like [uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation. [uv_break]it delivers natural and expressive speech,[uv_break]so please[uv_break] use the project responsibly at your own risk.[uv_break]", 0.2, 0.6, 15, 67, 165, True],
- ],
- inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],
- )
-
- parser = argparse.ArgumentParser(description='ChatTTS demo Launch')
- parser.add_argument('--server_name', type=str, default='0.0.0.0', help='Server name')
- parser.add_argument('--server_port', type=int, default=8080, help='Server port')
- parser.add_argument('--root_path', type=str, default=None, help='Root Path')
- parser.add_argument('--custom_path', type=str, default=None, help='the custom model path')
- args = parser.parse_args()
-
- print("loading ChatTTS model...")
- global chat
- chat = ChatTTS.Chat()
-
- if args.custom_path == None:
- chat.load_models()
- else:
- print('local model path:', args.custom_path)
- chat.load_models('custom', custom_path=args.custom_path)
-
- demo.launch(server_name=args.server_name, server_port=args.server_port, root_path=args.root_path, inbrowser=True)
-
-
- if __name__ == '__main__':
- main()
通过import ChatTTS和chat = ChatTTS.chat()以及chat.infer对ChatTTS类进行引用,通过装载多个配置项进行不同语音类型的生成。
四、总结
本文首先以VITS为例,对TTS基本原理进行简要讲解,让大家对TTS模型有基本的认知,其次对ChatTTS模型进行step by step实战教学,个人感觉4万小时语音数据开源版本还是被阉割的很严重,可能担心合规问题吧。其次就是没有特定的角色与种子值对应关系,需要人工去归类,期待更多相关的工作诞生。
实用性上来讲,对于语音聊天助手,确实是一种技术上的升级,不需要特别多的GPU资源就可以搭建语音聊天服务,比LLM聊天上升了一个档次。最近好忙,主要在做一个人工智能助手,3天涨了1.3万粉丝。最近计划把ChatTTS应用于这个人工智能助手(微博:面子小行家)的私信回复中,涉及到音频文件与业务相结合。期待我的成果吧!
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
AI智能体研发之路-模型篇(十):【机器学习】Qwen2大模型原理、训练及推理部署实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
【AI大模型】Transformers大模型库(六):torch.cuda.OutOfMemoryError: CUDA out of memory解决

