
- 1【机器学习】第5章 朴素贝叶斯分类器
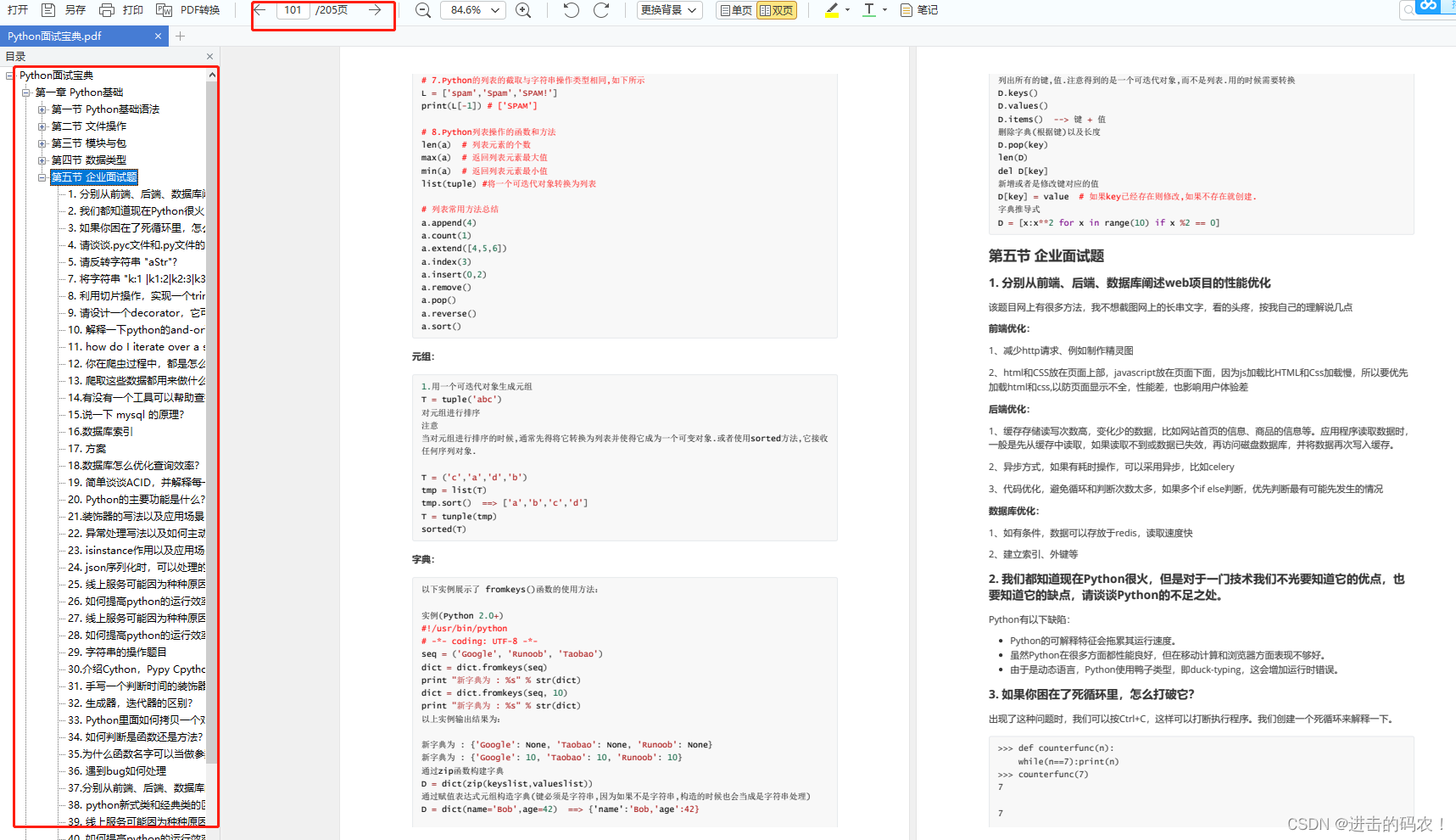
- 22024年网络安全最新网络安全方面 关于渗透 可以选择那些书?_渗透测试书籍(3),2024年最新2024年网络安全面试心得_渗透测试相关书籍
- 3一款开源免费图床聚合平台 ImageHosting
- 4【jenkins】教你jenkins设置为中文_jenkins 中文插件,2024年最新这操作真香_jenkins设置中文
- 5NullPointerException: println needs a message_permission revoked nullpointerexception: println n
- 6基于SpringBoot的校园闲置物品交易系统
- 7数据同步工具Sqoop_sqoop hcatalog更新数据
- 8识局者生,破局者存,掌局者赢
- 9Python图像边缘检测:边缘检算法原理及实现过程_python 边缘检测
- 10html插入视频的方法_html怎么插入视频
【Python爬虫学习】总结了八种学习爬虫的常用技巧
赞
踩
此篇内容小结:
1)基本网页获取
2)爬虫ip被封的6个解决方法
3)爬虫绕过登录
4)Cookies处理
5)应对反爬的小招
6)验证码处理
7)gzip 压缩
8)爬虫中文乱码问题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

基本网页获取
首先向一个 Url 地址发送请求,随后远端服务器将会返回整个网页。
常规情况下,当我们使用浏览器访问网站也是这么一个流程:用户在浏览器输入一个地址,浏览器将会发送一个服务器请求,服务器返回请求的内容,随后浏览器解析内容。其次,发送请求后,将会得到整个网页的内容。最后,通过我们的需求去解析整个网页,通过正则或其它方式获取需要的数据。
- requests.get() ----get请求方法
1.requests.get( url=请求url, headers=请求头字典, params=请求参数子弹, timeout=超时时长, )----- 返回一个response对象 2.response对象的属性 服务器响应包含:状态行(协议,状态码)、响应头、空行、响应正文。 (1)响应正文: 字符串格式:response.text bytes类型:response.content (2)状态码:response.status_code (3)响应头:response.headers(字典) response.headers('cookie') (4)响应正文的编码:response.encoding respons.text获取到的字符串类型的响应正文,其实是通过下面的步骤获取的: response.text=response.content.decode(response.encoding) (5)乱码问题的解决办法: 产生的原因:编码和解码的编码格式不一致造成的 str.encode('编码')---将字符串按指定编码解码成bytes类型 bytes.decode('编码')---将bytes类型按指定编码编码成字符串 解决方法: 解决一:response.content.decode('页面正确的编码格式') 解决二:找到正确的编码,设置到response.encoding中 response.encoding=正确的编码 response.text--->正确的页面内容 3.get请求小结: (1)没有请求参数的情况下,只需要确定url和headers字典 (2)get请求是有请求参数 在chrome浏览器中,下面找query_string_params,将里面的参数封装到params字典中。 (3)分页主要是查看每页中,请求参数页码字段的变化,找到变化规律,用for循环就可以做到分页。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- post请求方法
requests.post( url=请求url, headers=请求头字典, data=请求数据字典, timeout=超时时长, )-----返回response对象 post请求一般返回数据都是json数据 *解析json数据的方法: 1.response.json() ---- json字符串所对应的python的list或者dict 2.用json模块: json.loads(json_str) --->json_data(python的list或者dict) json.dumps(json_data)--->json_str post请求能否成功,关键看请求参数。 如何查找是哪个请求参数在影响数据获取?---通过对比,找到变化的参数。 变化参数如何找到参数的生成方式,就是解决这个ajax请求数据获取的途径。 寻找的办法有以下几种: (1)写死在页面 (2)写在js中 (3)请求参数是在之前的一条ajax请求的数据里面提前获取好的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
最简单的一个爬虫示例:获取百度页面
import requests
url="https://www.baidu.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
html=requests.get(url,headers=headers)
print(html.text)
- 1
- 2
- 3
- 4
- 5
- 6
- import requests:引入 requests 模块
- url=“[https://www.baidu.com/]”:设置要请求的url值,这里为百度。
- headers:为了更好的伪造自己是浏览器访问的,需要加一个头,让自己看起来是通过浏览器访问。
- html=requests.get(url,headers=headers):requests使用get方法,请求网站为url设置的值,头部为headers。
- print(html.text):显示返回的值html中的text文本,text文本则为网页的源代码。
接下来使用BeautifulSoup库解析,使用bs4可以快速的让我们获取网页中的一般信息,例如我们需要获取刚刚得到网页源码中的title标题,首先引入 bs库。
随后使用 beautifulsoup 进行解析,html.parser 代表html的解析器,可以解析html代码;其中 html.text 为网页源码为html。
完整代码示例
import requests
from bs4 import BeautifulSoup
url="https://www.baidu.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
html=requests.get(url,headers=headers)
val = BeautifulSoup(html.text, 'html.parser')
print(val.title)
f = open(r'D:\html.html',mode='w')
f.write(html.text)
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以上代码可能会出现编码不一致,出现“乱码”的情况,可以通过以下方式解决:
f = open(r'D:\html.html',mode='w',encoding="utf-8")
- 1
最终打开保存的文件如下:

由于有些资源是动态加载,获取的链接有时效性,所以并没有显示。
以上是最最简单的一个爬虫示例,仅针对刚学爬虫的新手,对已入门的朋友们没有什么挑战性,跟高手过招才过瘾呀。
爬虫ip被封的6个解决方法
方法1
- IP必须需要,如果有条件,建议一定要使用代理IP
- 在有外网IP的机器上,部署爬虫代理服务器
- 你的程序使用轮训替换代理服务器来访问想要采集的网站,就算具体IP被屏蔽了,你可以直接把代理服务器下线就OK,程序逻辑不需要变化。
方法2
- ADSL+脚本,监测是否被封,然后不断切换ip
- 设置查询频率限制,调用该网站提供的服务接口
方法3
- useragent伪装和轮换
- cookies的处理,有的网站对登陆用户没有那么严
方法4
尽可能的模拟用户行为,比如:
- UserAgent经常换一换
- 访问时间间隔设长一点,访问时间设置为随机数;
- 访问页面的顺序也可以随机来
方法5
网站封IP的依据一般是单位时间内特定IP的访问次数;
将采集的任务按目标站点的IP进行分组,通过控制每个IP在单位时间内发出任务的个数来避免被封。当然,这个前提是采集很多网站,如果只需要采集一个网站,那么只能通过多外部IP的方式来实现了。
方法6
对爬虫抓取进行压力控制,可以考虑使用代理的方式访问目标站点。例如:
- 降低抓取频率,时间设置长一些,访问时间采用随机数
- 频繁切换UserAgent(模拟浏览器访问)
- 多页面数据,随机访问然后抓取数据
- 更换用户IP,这是最直接有效的方法!
在requests模块中如何设置代理?
proxies = {
'代理服务器的类型':'代理ip'
}
response = requests.get(proxies=proxies)
代理服务器的类型:http,https,ftp
代理ip:http://ip:port
- 1
- 2
- 3
- 4
- 5
- 6
爬虫绕过登录
有时候做 Python 爬虫时经常会卡在登录,登录验证码是最头疼的事情,特别是现在的文字验证码和图形验证码。
例如:我们最常用到的 12306 的图形验证码;
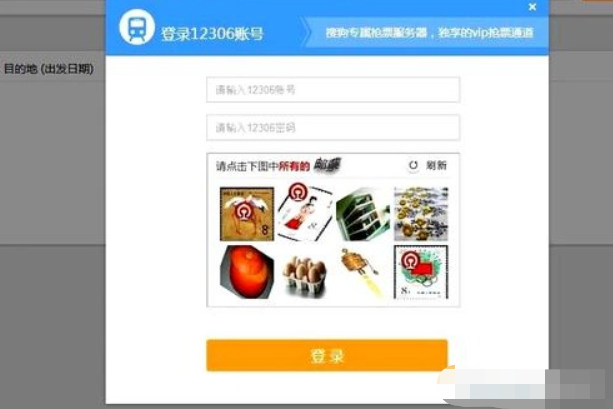
绕过登录方法基本有两种方法:
第一种方法是登录后查看网站的 cookie,请求 url 的时候把 cookie 带上;
cookie 方法我们要分析别人网站的 cookie 值,找出相应的值然后添加进去,对于我们不熟的网站,他们可能也会做加密或者动态处理,所以有些网站也不是那么好操作。如果是自己公司的网站需要测试,我们可以询问对应的开发那个 cookie 值是区分独立用的值,拿出来放在请求里面就行。
第二种方法是启动浏览器带上浏览器的全部信息,包括添加的书签和访问网页的 cookie 信息;
添加 cookie 绕过登录
比如我们登录百度账号比较费劲,每次都需要登录也比较繁琐,我们 F12 打开页面调试工具,登录后找到[http://www.baidu.com]文件,在 cookie 中,我们发现很多值,其中图中圈起来的就是我们要找的值。
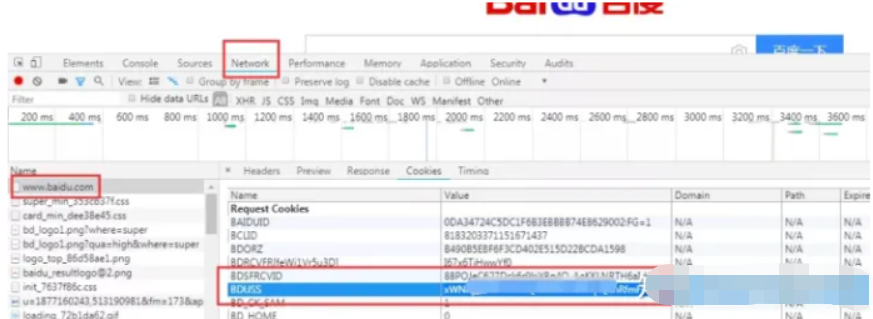
我们在访问 baidu 链接的时候加上这个 cookie 值,这样就是直接登录后的百度账号了。
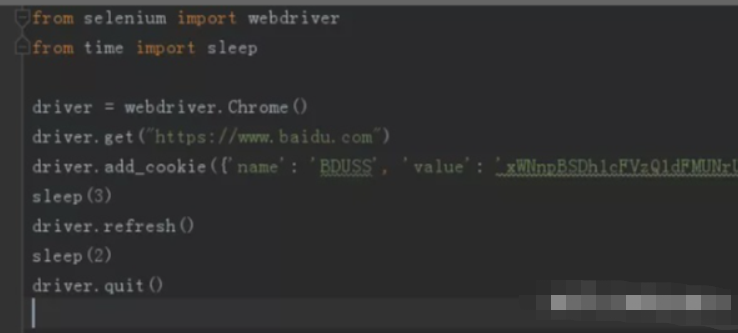
下载浏览器驱动
我们用 selenium 启动浏览器时,需要下载后对应的驱动文件并放在 Python 安装的根目录下,比如我会用到谷歌 Chrome 浏览器。
谷歌浏览器驱动下载地址:
http://chromedriver.storage.googleapis.com/index.html
- 1
启动 Chrome 浏览器绕过登录
我们每次打开浏览器做相应操作时,对应的缓存和 cookie 会保存到浏览器默认的路径下,我们先查看个人资料路径,以 chrome 为例,我们在地址栏输入 chrome://version/
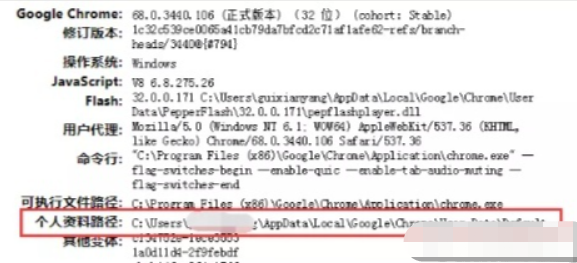
图中的个人资料路径就是我们需要的,我们去掉后面的 \Default,然后在路径前加上「–user-data-dir=」就拼接出我们要的路径了。
profile_directory = r'--user-data-dir=C:\Users\xxx\AppData\Local\Google\Chrome\User Data'
- 1
接下来,我们启动浏览器的时候采用带选项时的启动,这种方式启动浏览器需要注意,运行代码前需要关闭所有的正在运行 chrome 程序,不然会报错。
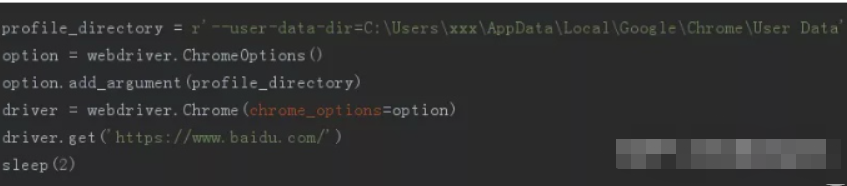
selenium 自动化启动浏览器后我们会发现我之前保存的书签完整在浏览器上方,baidu 账号也是登录的状态。

另外,下面的这种图形验证码,我们可以登录后(cookie 有一定的时效,貌似有 10 天半个月左右),把上面代码中的链接换一下,再用上面的方法也可以实现绕过登录页的图形验证码。

Cookies处理
cookies是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密);
python提供了cookielib模块用于处理cookies,cookielib模块的主要作用是提供可存储cookie的对象。
在python2.0版本导入cookielib直接import cookielib
python3中为http.cookiejar
from http import cookiejar
# 声明一个CooieJar对象实例来保存cookie
cookie = cookiejar.CookieJar()
- 1
- 2
- 3
- 4
在爬虫中如果遇到了cookie的反爬如何处理?
- 手动处理
在抓包工具中捕获cookie,将其封装在headers中
应用场景:cookie没有有效时长且不是动态变化
- 自动处理
使用session机制
使用场景:动态变化的cookie
session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中。
需要注意的一点:并不是所有网站都适合保存cookies进行登录!
怎么检查哪些网站可以使用保存cookies进行登录呢?
我们可以在浏览器中进行登录操作,登录成功后,关闭浏览器,然后重新打开浏览器以后访问此网站,看看是否处于登录状态,如果是登录状态,那么这个网站很大程度上是可以使用cookies进行访问操作的。
应对反爬的小招
爬取人家网站的时候控制一下频率,有事没事睡一会,睡久了没效率,睡短了,被反爬搞掉了那也不行……
随机数更具有欺骗性,random可以用得上了!
import time import random for i in range(1,11): time = random.random()*5 print(f'第{i}次睡了:', time, 's') ''' 第1次睡了: 0.6327309035891232 s 第2次睡了: 0.037961811128097045 s 第3次睡了: 0.7443093721610153 s 第4次睡了: 0.564336149517787 s 第5次睡了: 0.39922345839757245 s 第6次睡了: 0.13724989845026703 s 第7次睡了: 0.7877693301824763 s 第8次睡了: 0.5641490602064826 s 第9次睡了: 0.05517343036931721 s 第10次睡了: 0.3992618299505627 s '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
可以试着在爬虫代码加入这句代码,安心喝茶无后顾之忧!
time.sleep(random.random()*5)
- 1
模拟浏览器访问页面
User-Agent中文名为用户代理,简称 UA;
它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
简单来说就是我们经常说到的模拟浏览器去访问页面,避免被被网站反爬到。
fake-useragent:一个非常好用的伪装请求头的库,你绝对值得拥有!
安装fake-useragent库
pip install fake-useragent
- 1
获取各浏览器的fake-useragent
from fake_useragent import UserAgent ua = UserAgent() #ie浏览器的user agent print(ua.ie) #opera浏览器 print(ua.opera) #chrome浏览器 print(ua.chrome) #firefox浏览器 print(ua.firefox) #safri浏览器 print(ua.safari) #最常用的方式 #写爬虫最实用的是可以随意变换headers,一定要有随机性,支持随机生成请求头 print(ua.random) print(ua.random) print(ua.random)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
看看下面的示例:够用不?
from fake_useragent import UserAgent for i in range(1,11): ua = UserAgent().random print(f'第{i}次的ua是', ua) ''' 第1次的ua是 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36 第2次的ua是 Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130401 Firefox/21.0 第3次的ua是 Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; es-es) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27 第4次的ua是 Mozilla/5.0 (X11; CrOS i686 4319.74.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36 第5次的ua是 Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; fr-ch) AppleWebKit/533.19.4 (KHTML, like Gecko) Version/5.0.3 Safari/533.19.4 第6次的ua是 Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36 第7次的ua是 Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36 第8次的ua是 Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0 第9次的ua是 Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Zune 3.0) 第10次的ua是 Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
所以可以试着在爬虫代码加入一下代码,让 UA更具有欺骗性;
headers= {'User-Agent':str(UserAgent().random)}
- 1
在一些网站服务中,除了对 user-agent 的身份信息进行检测、也对客户端的 ip 地址做了限制,如果是同一个客户端访问此网站服务器的次数过多就会将其识别为爬虫,因而,限制其客户端 ip 的访问。
这样的限制给我们的爬虫带来了麻烦,所以使用代理 ip 在爬虫中是非常有必要的。
由Urllib提供urllib.request.ProxyHandler()方法可动态设置代理IP池,代理IP主要以字典格式写入方法
from urllib import request
proxy_handle = request.ProxyHandle({
‘http':http://代理ip
'https':https://代理IP
})
opener = request.builder_opener(proxy_handle)
response = opener.open('www.baidu.com')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
还有headers这也是最常见的,最基本的反爬虫手段,主要是初步判断你是否是真实的浏览器在操作。
遇到这类反爬机制,可以直接在自己写的爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中。
验证码处理
验证码我们在很多网站会遇到,如果请求量大了之后就会遇到验证码的情况。
列举三种最常见的验证码:
① 输入式验证码

这种验证码主要是通过用户输入图片中的字母、数字、汉字等进行验证
解决思路:这种是最简单的一种,只要识别出里面的内容,然后填入到输入框中即可,这种识别技术叫OCR,推荐使用Python的第三方库tesserocr,对于没有什么背影影响的验证码如图2,直接通过这个库来识别就可以。
简单的OCR识别验证码:
from PIL import Image
import tesserocr
#tesserocr识别图片的2种方法
img = Image.open("code.jpg")
verify_code1 = tesserocr.image_to_text(img)
#print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
② 滑动式验证码
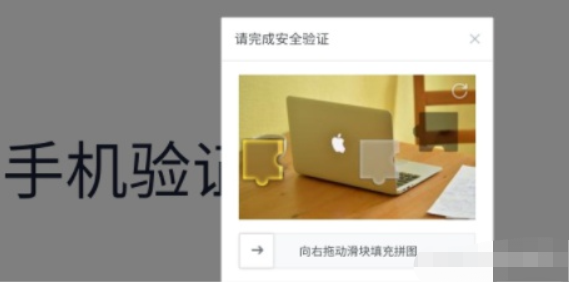
这种是将备选碎片直线滑动到正确的位置;
解决思路:对于这种验证码就比较复杂一点,但也是有相应的办法。我们直接想到的就是模拟人去拖动验证码的行为,点击按钮,然后看到了缺口 的位置,最后把拼图拖到缺口位置处完成验证。
③ 点击式的图文验证和图标选择
这两种原理相似,只不过是一个是给出文字,点击图片中的文字,一个是给出图片,点出内容相同的图片。
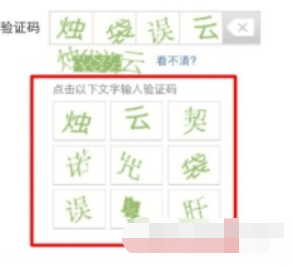
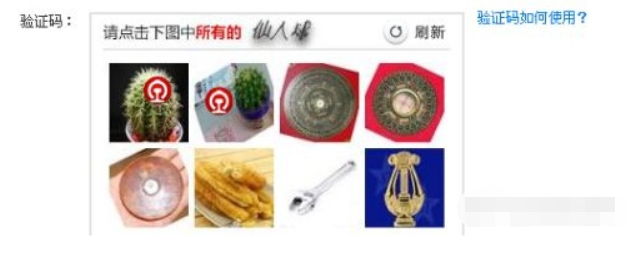
这两种没有特别好的方法,只能借助第三方识别接口来识别出相同的内容,然后再使用selenium模拟点击即可。
gzip 压缩
有没有遇到过某些网页,不论怎么转码都是一团乱码哈哈,那说明你还不知道许多web服务具有发送压缩数据的能力,这可以将网络线路上传输的大量数据消减 60% 以上。
这尤其适用于 XML web 服务,因为 XML 数据 的压缩率可以很高。
但是一般服务器不会为你发送压缩数据,除非你告诉服务器你可以处理压缩数据。
于是需要这样修改代码:
import urllib2, httplib
request = urllib2.Request('http://xxxx.com')
request.add_header('Accept-encoding', 'gzip') 1
opener = urllib2.build_opener()
f = opener.open(request)
- 1
- 2
- 3
- 4
- 5
- 6
关键:创建Request对象,添加一个 Accept-encoding 头信息告诉服务器你能接受 gzip 压缩数据;
然后就是解压缩数据:
import StringIO
import gzip
compresseddata = f.read()
compressedstream = StringIO.StringIO(compresseddata)
gzipper = gzip.GzipFile(fileobj=compressedstream)
print gzipper.read()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
爬虫中文乱码问题
写爬虫时肯定是要去考虑乱码的问题,可以参考一下以下思路:
1)解析服务端返回的header中content-type. 得到编码,改编码是什么就按照什么去解析返回的字节流。
2)如果服务端header中没有content-type 信息,就按照 utf-8 解析返回的内容 。
再去解析meta标签得到编码,并作为最终的解析服务端返回字节流的编码。(因为按照gbk 或者 utf-8 还是其他的编码 解析charset=utf-8 的结果都是一样的,因为它们都兼容ascii编码,也就是前2个字节的码表都一样)
3)如果标签meta中也没有编码的话,那么可以尝试着去得到 en ,zh-CN ,zh. 然后用相应的编码解析返回的内容。
4)如果上面条件1,2,3都不满足的话,可以通过智能探测,如cpdetector,有些特殊网页,它确实是不准确的,如网页的meta中charset和实际的浏览器识别的正常显示的charset不相同的情况,它的识别也是错误的。所以这种办法会有误判的的情况。
不过经过前面的3步也基本能得到编码类型了。
5)还有一种情况就是国内的网页写的不规范,比如实际类型是utf-8,但是写成charset=gbk….这种情况也要考虑。
对于有些网页编码为utf-8的网址,输出时发现中文为乱码,此时我们需要进行两次重编码。
response = requests.get(url, headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
- 1
- 2
- 3
一些琐碎的个人经验:
代码规范;这本身就是一个非常好的习惯,如果开始不注意,以后会很痛苦。
多动手;很多人学Python就一味的看书,这不是学数理化,看看例题可能就会了,学习Python主要还是靠实践。
勤练习;学完新的知识点,一定要记得如何去应用,不然学完就会忘。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以手机保存下方图片微信扫描CSDN官方认证二维码免费领取【保证100%免费】
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/785050


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

