
- 1为什么 卷积网络输出特征图会越来越多_卷积操作中的填充与池化
- 2linux基础篇:Linux中磁盘的管理(分区、格式化、挂载)_linux格式化磁盘
- 3用Git远程仓库实现多人协同开发_git仓库开放给多人
- 4AI:184-神经网络应用与实战案例详解(AIGC技术方向)_aigc使用的是神经网络吗
- 5python干货_ypeerror: save() takes exactly 1 argument (2 given
- 6Python-Selennium之爬虫实战--链家二手房爬虫项目_爬取链家网二手房数据
- 76月28日PolarDB开源社区长沙站,NineData联合创始人周振兴将带来《数据库DevOps最佳实践》主题分享
- 8【LLM多模态】Qwen-VL模型架构和训练流程_position-aware vision-language adapter
- 9IDEA安装插件出现incompatible错误_idea’安装腾讯ai编程助手插件出现版本不匹配
- 10个人简历与自我介绍_oovih
Tele-FLM:开源多语言大型语言模型技术报告_tele-flm 论文
赞
踩
随着模型规模的不断扩大,如何高效地训练并优化这些拥有超过500亿参数的庞大模型,同时降低试错成本和计算资源消耗,成为了一个亟待解决的问题。北京智源人工智能研究院、中国电信的研究团队及其合作者提出Tele-FLM模型:一个52亿参数的开源多语言大型语言模型,它不仅在技术上实现了这一规模模型的稳定和高效预训练,还在事实判断能力上进行了增强。更重要的是,Tele-FLM展示了在多语言环境下的卓越性能,为解决上述问题提供了一种创新的解决方案。
预训练数据
Tele-FLM的预训练数据集由多个子集组成,包括Web文本、代码、书籍、世界知识、问答、学术论文和专业领域等。为了处理这些数据,研究团队构建了一个基于Spark集群的自定义数据处理流水线。该流水线包括从HTML/WARC中提取文本、基于启发式规则的清洗和段落级去重、基于模型的文本质量过滤以及使用MinHash算法进行文档级去重等步骤。
在预训练数据中,不同语言和领域数据的采样比例是根据其质量和重要性进行调整的。例如,Web文本(WebText)和代码(Code)数据占据了较大的比例,以反映它们在现实世界数据中的丰富性和多样性。表1详细列出了各个子集的语言、采样比例、在训练中完成的轮次以及磁盘大小。
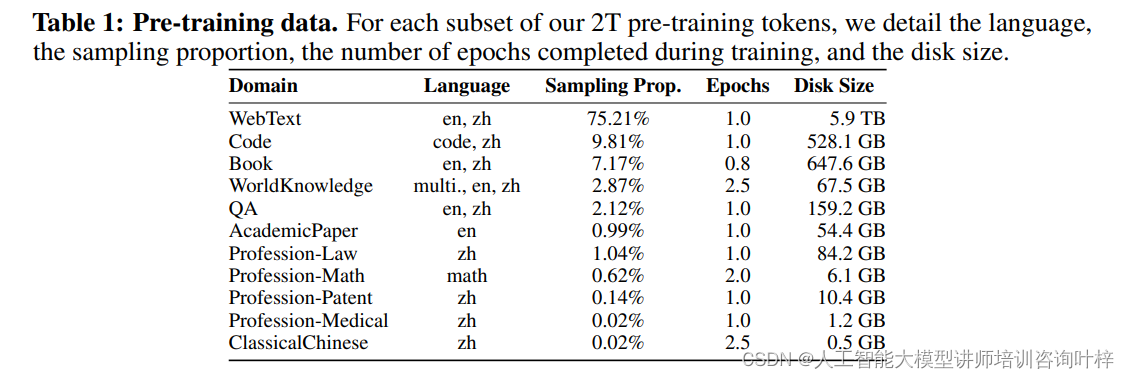
为了保证预训练数据的质量,Tele-FLM团队采取了多种措施来过滤低质量内容和进行去重。例如,对于Web文本数据,使用了FastText分类器来辅助过滤;对于书籍数据,则开发了一系列清理步骤来移除冗余格式、乱码文本、公式错误和重复段落。
Tele-FLM模型的一个显著特点是其多语言能力。为了增强模型对不同语言的理解,研究团队整合了多种语言的数据集,包括英语、中文和其他22种语言的维基百科数据。这些数据经过专门的多语言清洗功能处理,以去除与主文本不相关的参考内容和后续内容。
除了通用数据外,Tele-FLM还特别关注了某些专业领域的数据收集,如医学、法律、专利和数学。这些特定领域的数据有助于模型在这些领域的应用中表现出更好的性能。
预训练
Tele-FLM模型的架构基于FLM-101B,但进行了针对性的改进以适应更大规模的参数和更高效的训练。模型采用了标准的GPT风格的解码器仅Transformer架构,并引入了RMSNorm作为归一化方法,SwiGLU作为激活函数。此外,Tele-FLM放弃了Extrapolatable Position Embedding (xPos),转而使用Rotary Positional Embedding (RoPE),进一步优化了模型的表示能力。

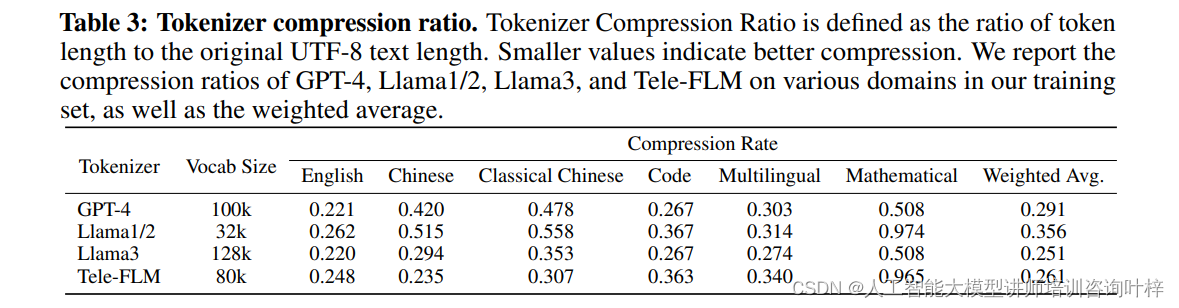
Tele-FLM的分词器是专门为其预训练数据分布而训练的,采用了Byte-level BPE (BBPE) 算法。为了在中文文本压缩比上达到更好的性能,同时保持在多语言环境下的效率,Tele-FLM的分词器在设计上做了特别的考量。通过从预训练数据集中采样1200万个多样化的文本样本进行训练,Tele-FLM的分词器在中英文以及古典中文、代码和数学内容上都展现出了优秀的压缩性能。
Tele-FLM的训练是在112个A800 SXM4 GPU服务器上进行的,这些服务器每个都配备了8个NVLink A800 GPU和2TB的RAM。这些节点通过InfiniBand网络互联,确保了高效的数据传输和模型训练。
为了充分利用硬件资源并提高训练效率,Tele-FLM采用了3D并行训练方法,结合了数据并行、张量并行和流水线并行。这种综合方法通过优先将通信开销大的张量并行组分配到同一节点上,最大化了节点内通信并最小化了节点间通信。
超参数的调整对于模型训练至关重要。Tele-FLM采用了基于µP的方法进行超参数搜索,这种方法基于Tensor Programs理论,揭示了在模型宽度接近无穷大时训练动态中的普遍关系。通过使用较小的模型Tele-FLMµP进行网格搜索,研究团队能够更有效地预测最终大型模型的行为,并找到最优的超参数配置。
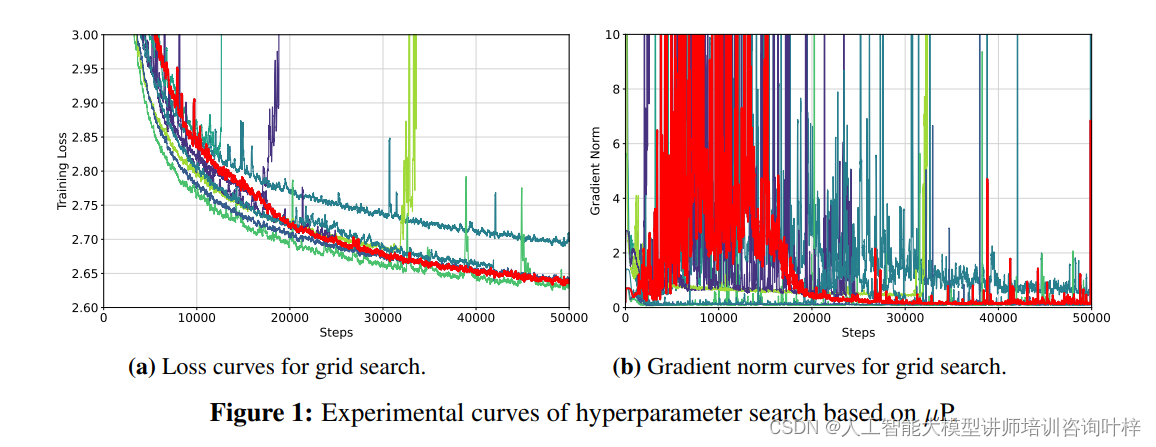
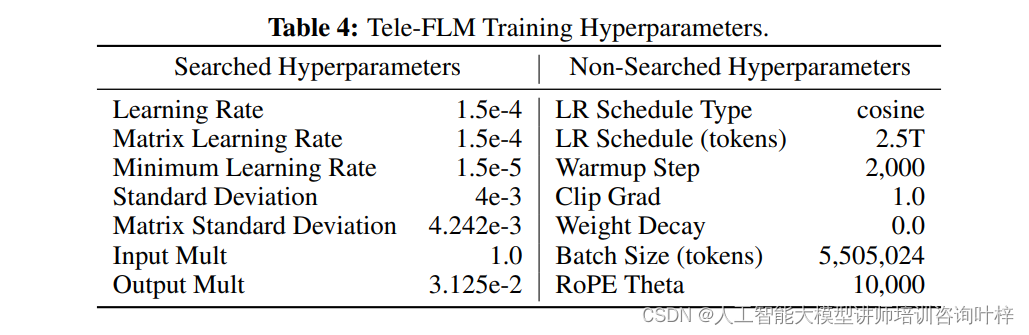
损失动态与BPB评估
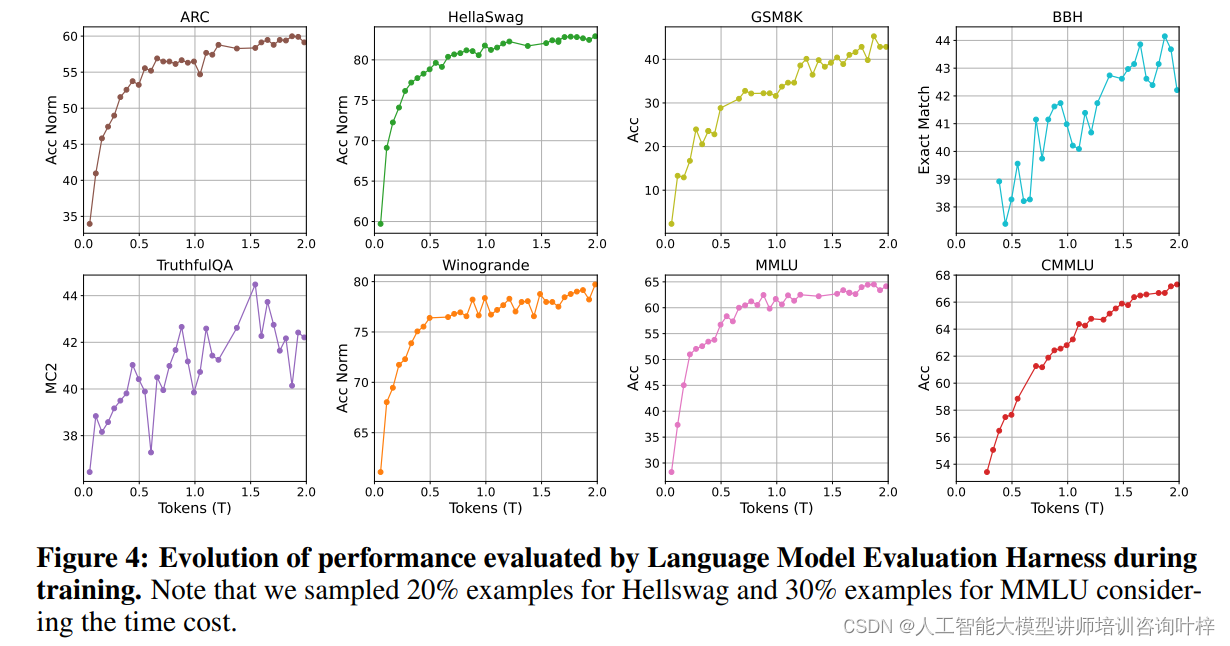
在预训练过程中,损失函数的动态变化对于评估模型训练的稳定性和有效性至关重要。Tele-FLM模型的损失动态表现出了良好的稳定性和收敛性。
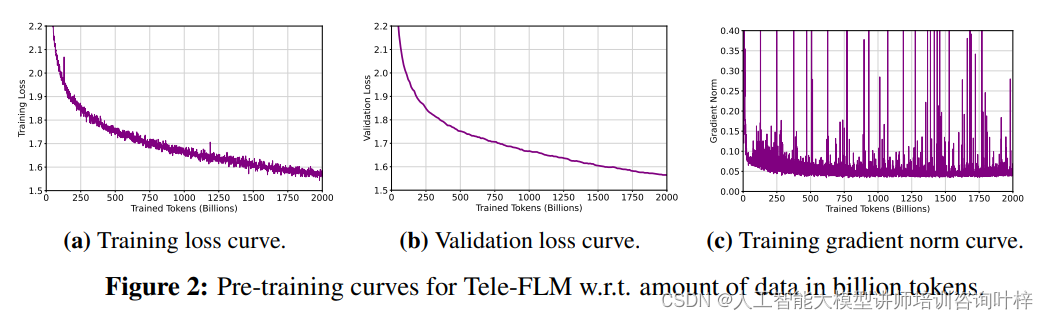
Tele-FLM模型在训练过程中展示了单一稳定运行的损失曲线,没有出现发散现象。这一结果归功于精心设计的超参数搜索策略,确保了模型训练的顺利进行。通过监控训练和验证损失以及梯度范数的变化,研究团队能够及时发现并解决潜在的训练问题。
BPB(Bits-Per-Byte)是一种评估语言模型压缩能力的指标,它考虑了每个token的损失以及领域和分词器的影响。Tele-FLM在多个英文和中文数据集上进行了BPB评估,结果显示其在不同领域的压缩性能均优于或至少可与现有的大型模型相媲美。特别是在英文数据集上,Tele-FLM在WebText、Github和StackExchange等数据集上超越了Llama系列模型,证明了其在英文基础能力上的强大表现。在中文数据集上,Tele-FLM同样展现出了较低的BPB,证明了其在中英文上的均衡性能。
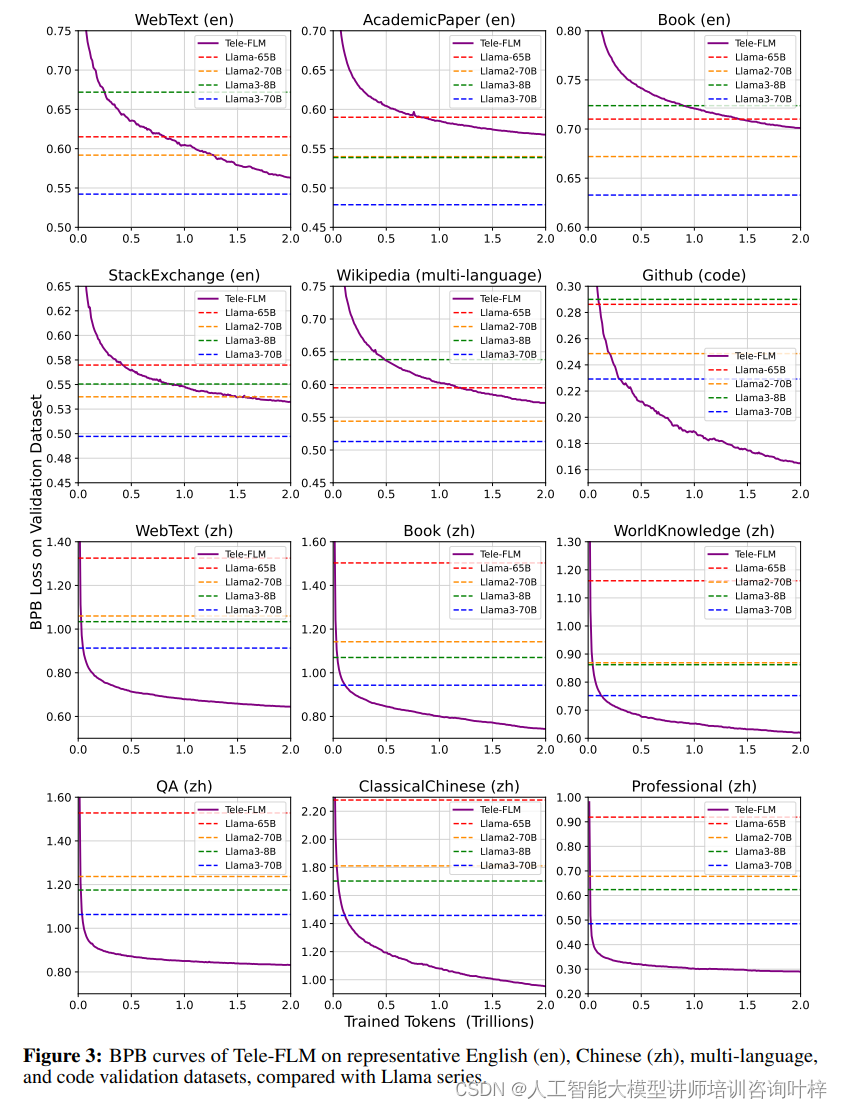
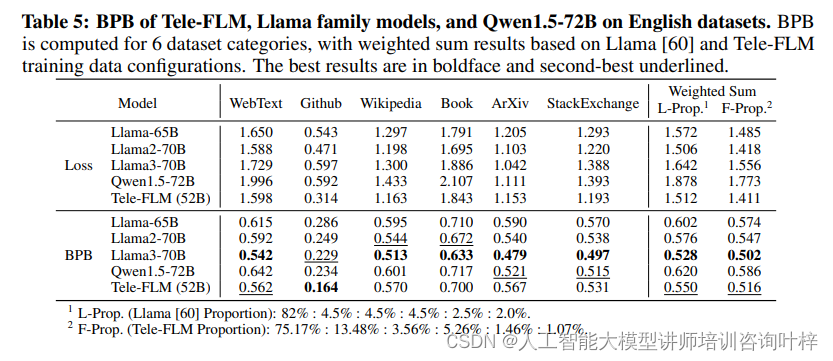
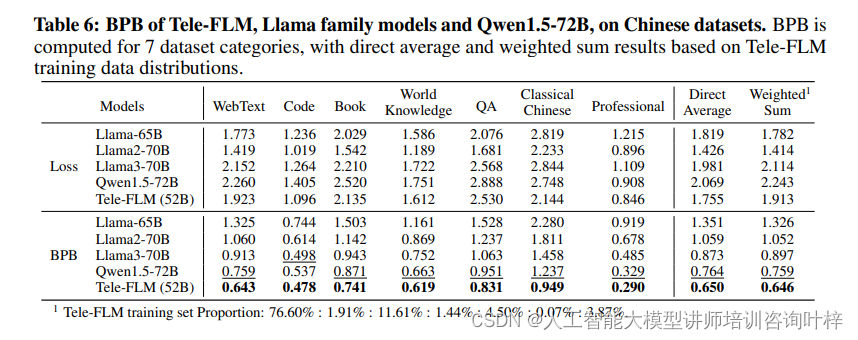
基准评估
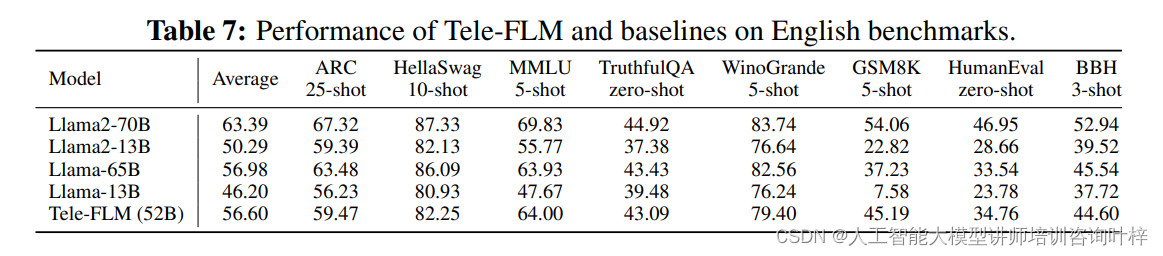
在英文基准评估中,Tele-FLM参与了多个公共且广泛使用的评估平台和测试,包括Open LLM Leaderboard、HumanEval和BIG-Bench Hard。这些评估覆盖了常识推理、知识容量、真实性判断和数学问题解决等多个方面。
Open LLM Leaderboard:这是一个由Huggingface托管的平台,它包括了多种任务,用于衡量模型在不同领域的表现。Tele-FLM在这些任务上的表现与Llama系列模型相当,显示出其在多任务学习上的均衡能力。
HumanEval:这个评估专注于代码生成能力,通过测量模型输出与文档字符串提示的功能正确性来评估。Tele-FLM在这项评估中的表现突出了其在代码生成任务上的潜力。
BIG-Bench Hard:这个评估包含了23个挑战性任务,代表了当前语言模型尚未超越平均人类表现的领域。Tele-FLM在这些任务上的表现提供了对其高级推理能力的洞察。
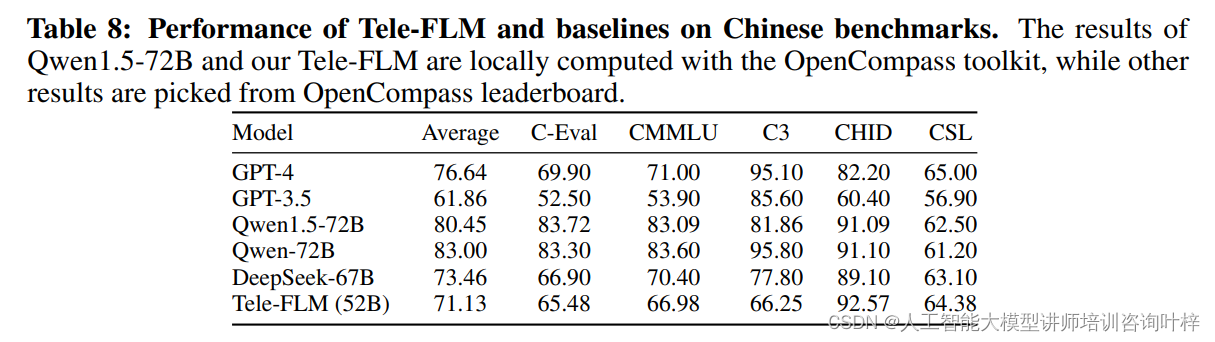
为了衡量Tele-FLM在中文语言和知识理解方面的能力,研究团队使用了OpenCompass工具包进行评估。Tele-FLM在以下中文任务上进行了测试:
C-Eval:这是一个多学科的中文评估套件,用于衡量模型在多个领域的中文理解能力。
CMMLU:这个评估专注于多学科知识的中文理解,Tele-FLM在这项评估中的表现显示了其在中文多学科知识掌握上的深度。
C3:阅读理解任务,Tele-FLM在这项任务上的表现证明了其在处理中文文本和理解其含义方面的能力。
CHID:中文文化和语言理解评估,Tele-FLM在这项评估中的表现尤为突出,显示了其对中文文化特定概念的理解。
CSL:关键词识别任务,Tele-FLM在这项任务上的表现显示了其在科学领域中文文献处理上的能力。
通过这些基准评估,Tele-FLM证明了自己作为一个多语言基础模型,在中英文任务上都能达到与更大模型相近或更高的水平。
经验教训
在预训练数据的选择上,数据的质量和数量对于模型性能至关重要。特别是在需要在质量和数量之间做出权衡时,数据质量应被视为优先考虑的因素。在Tele-FLM项目中,发现英文和中文数据的比例为2:1时效果更佳,这可能是因为中文网络数据的平均质量相对较低。
关于超参数搜索,团队发现基于µP的方法在寻找最佳超参数和预测最终大型模型行为方面非常有效。初始化标准差和输出乘数对模型性能的影响比通常认为的要大。
在损失动态方面,损失曲线的斜率在训练了大约500亿个tokens后通常会趋于平缓。所以如果早期损失值不满意,应立即重新启动训练。随机损失的尖峰是常见且可接受的,只要梯度范数曲线看起来正常。
关于梯度范数,早期的梯度范数曲线并不是训练稳定性的强指标。在超参数搜索中,即使梯度曲线模式不同,也可能出现发散,但持续增加的梯度趋势与更高的发散概率相关。
论文链接:https://arxiv.org/abs/2404.16645

