
- 1Rocky Linux 9.4 部署Zabbix 7.0_zabbix7
- 2(三十四)大数据实战——scala运行环境安装配置及IDEA开发工具集成_scala项目实战
- 3在linux下配置与安装mysql-5.6.40_mysql5.6.40
- 4Oracle中的CASE WHEN语句使用详解与实例_oracle的case when语句
- 5对#多种编程语言 性能的研究和思考 go/c++/rust java js ruby python_golang 和 java 和c++ 性能对比
- 6ORB-SLAM3 导航图/编译/运行_orbslam3 快速加载 bin
- 7Fastjson的学习与使用_fastjson github
- 8开源:基于Vue3.3 + TS + Vant4 + Vite5 + Pinia + ViewPort适配..搭建的H5移动端开发模板
- 9香橙派AIpro初体验:搭建无线随身NAS_香橙派aipro连接wifi
- 10java开发工程师—如何让你的简历脱颖而出?(1)_java开发简历怎么写
Hadoop目录详解_hadoop 可执行命令位于 填空 1 目录下 start-all.sh 位于 填空 2 目录下
赞
踩
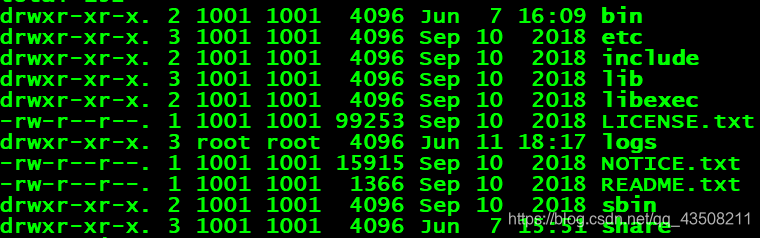
-
bin:Hadoop基本管理脚本和使用脚本所在目录,是sbin目录下管理脚本的基础实现。可直接使用这些脚本管理及使用Hadoop。简而言之,存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本。
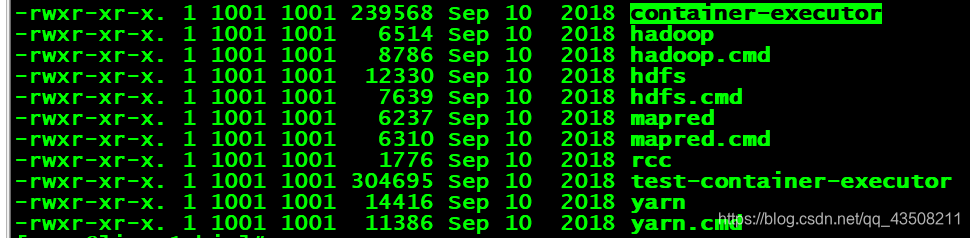
-
sbin: 存放的是我们管理脚本的所在目录,重要是对hdfs和yarn的各种开启和关闭和单线程开启和守护
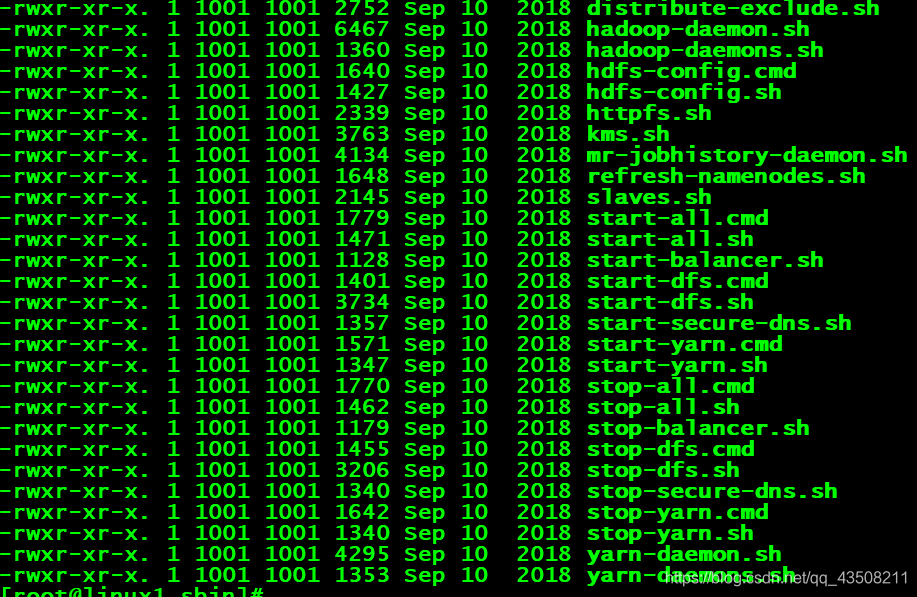
常用的说一下:
1,hadoop-daemon.sh(hadoop-daemons) : 通过执行hadoop命令来启动/停止一个守护进程(daemon);他可以单独开启一个进程也可以使用hadoop-daemons来开启多个进程,这样我们在某台机器挂掉时,就不用全部重新开启了
2,start-all.sh : 他会调用 start-dfs.sh和start-yarn.sh(官方不建议使用)
3, stop-all.sh : 他会调用 stop-dfs.sh和stop-yarn.sh(官方不建议使用)
4,start-dfs.sh: 启动NameNode ,SecondaryNamenode ,DataNode这些进程 需要先配置etc下的slaves文件 才能一键启动集群。
5,stop-dfs.sh: 关闭NameNode ,SecondaryNamenode ,DataNode这些进程
6,start-yarn.sh: 启动ResourceManager,nodeManager 这些进程
7, stop-yarn.sh: 关闭ResourceManager,nodeManager 这些进程
-
etc:存放一些hadoop的配置文件
etc/hadoop下的.xml配置文件
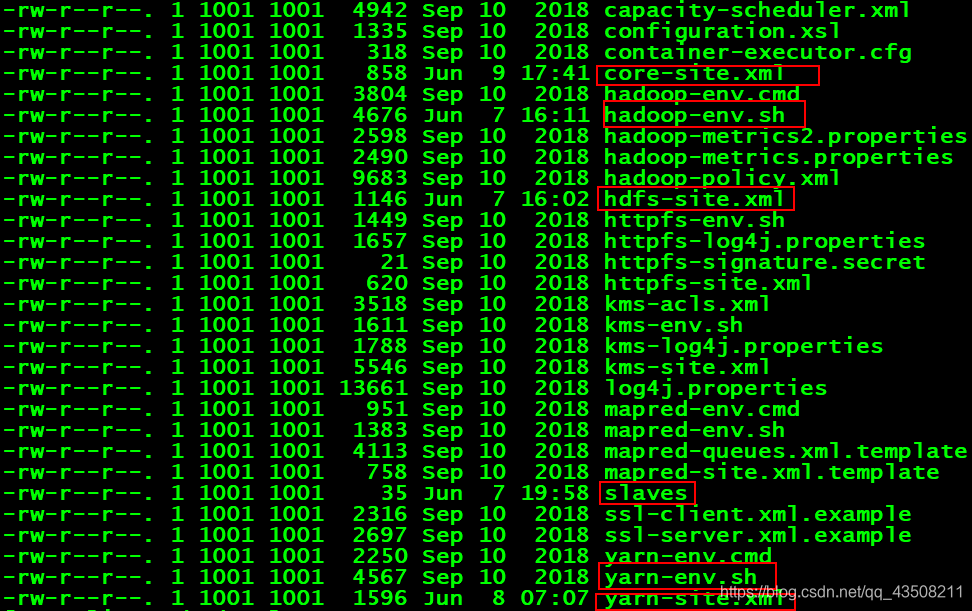
(1)core-site.xml:
Hadoop核心全局配置文件,可以其他配置文件中引用该文件中定义的属性,如在hdfs-site.xml及mapred-site.xml中会引用该文件的属性;
该文件的模板文件存在于 H A D O O P H O M E / s r c / c o r e / c o r e − d e f a u l t . x m l , 可 将 模 板 文 件 复 制 到 c o n f 目 录 , 再 进 行 修 改 。 ( 2 ) h a d o o p − e n v . s h H a d o o p 环 境 变 量 ( 3 ) h d f s − s i t e . x m l H D F S 配 置 文 件 , 该 模 板 的 属 性 继 承 于 c o r e − s i t e . x m l ; 该 文 件 的 模 板 文 件 存 于 HADOOP_HOME/src/core/core-default.xml,可将模板文件复制到conf目录,再进行修改。 (2)hadoop-env.sh Hadoop环境变量 (3)hdfs-site.xml HDFS配置文件,该模板的属性继承于core-site.xml;该文件的模板文件存于 HADOOPHOME/src/core/core−default.xml,可将模板文件复制到conf目录,再进行修改。(2)hadoop−env.shHadoop环境变量(3)hdfs−site.xmlHDFS配置文件,该模板的属性继承于core−site.xml;该文件的模板文件存于HADOOP_HOME/src/hdfs/hdfs-default.xml,可将模板文件复制到conf目录,再进行修改
(4)yarn-site.xml
yarn的配置文件,该模板的属性继承于core-site.xml;该文件的模板文件存于$HADOOP_HOME/src/mapred/mapredd-default.xml,
可将模板文件复制到conf目录,再进行修改
(5)slaves
用于设置所有的slave的名称或IP,每行存放一个。如果是名称,那么设置的slave名称必须在/etc/hosts有IP映射配置
文件具体内容可以cat进入阅读一下。 -
lib目录:该目录下存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中。

-
logs目录:该目录存放的是Hadoop运行的日志,查看日志对寻找Hadoop运行错误非常有帮助。
(虽然看不懂,但是出现错误了还是要试着看看哟)
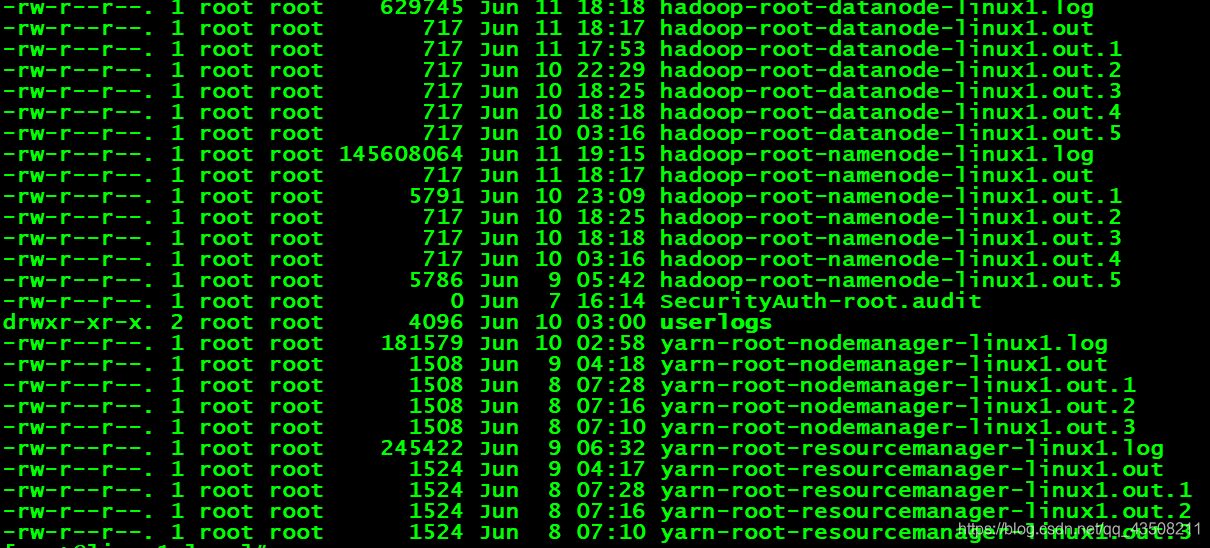
-
include目录:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。

别问我是什么,不懂,很少用! -
share目录:Hadoop各个模块编译后的jar包所在的目录。
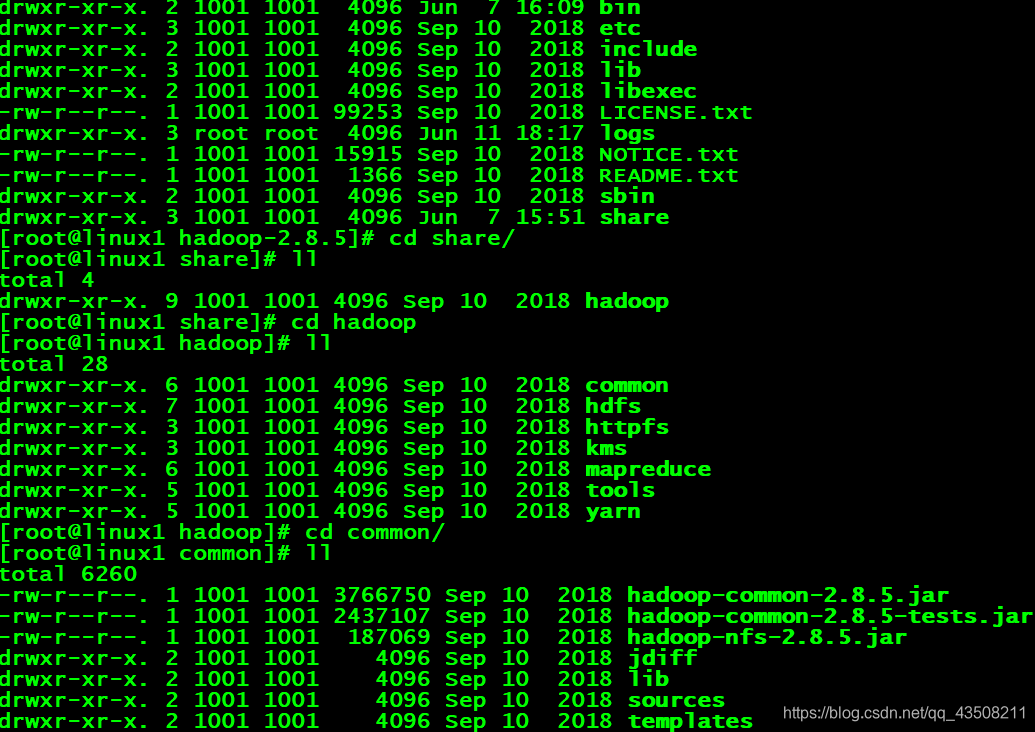
-
libexec目录:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
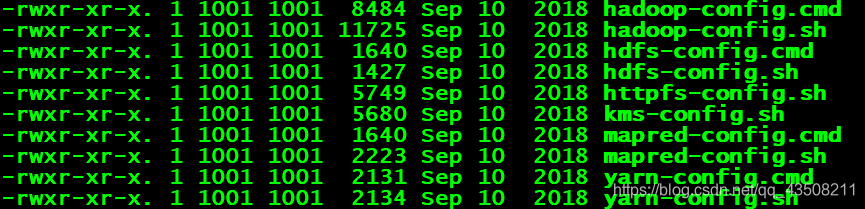
最后重要的东西再说一遍:
sbin下的
先格式化./bin/hadoop namenode -format
hadoop-daemon.sh start namenode or datanode 单个启动
start-all.sh 不建议使用
start-dfs.sh 配置slaves后一键启动
start-yarn.sh stop命令差不多
etc下的xml:
1.hadoop-env.sh
由于Hadoop是java进程,所以需要添加jdk
# The java implementation to use.
```bash
export JAVA_HOME=/usr/local/jdk1.8.0_171//加入JAVA_HOME
- 1
- 2
- 3
- 4
2.core-site.xml
2.1指定namenode的位置
2.2hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.8.3/tmp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.hdfs-site.xml
3.1配置namenode和datanode存放文件的具体路径
3.2配置副本的数量,最小值为3,否则会影响到数据的可靠性
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop-2.8.3/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop-2.8.3/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hadoop-master:50090</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.yarn-site.xml
Yarn.resourcemanager.hostname:资源管理器所在节点的主机名
Yarn.nodemanager.aux-services:一个逗号分隔的辅助服务列表,这些服务由节点管理器执行。该属性默认为空。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5:slaves是配置集群中datanode的机器节点
其他目录下的文件不会涉及修改操作就不说了。

