
- 1Android的Compose_android compose
- 2MySQL DQL 子查询_mysql子查询
- 3如何保护linux服务器远程使用的安全_linux 服务器 防护
- 4mysql配置utf8mb4_mysql utf8mb4 conf
- 5GDS area estimation
- 6ubuntu下安装git安装及使用_ubuntu git bin文件夹
- 7Config NTP Server
- 8大模型面试经验(一)_大模型 问题提槽怎么做
- 9使用python爬虫技术进行有道词典翻译中英文【修正转载】_有道翻译爬虫 返回none
- 10重启电脑后docker报错,提示wsl有问题_docker desktop -unexpected wsl error
keras 生成句子向量 词向量_自然语言处理——使用词向量(腾讯词向量)
赞
踩
向量化是使用一套统一的标准打分,比如填写表格:年龄、性别、性格、学历、经验、资产列表,并逐项打分,分数范围[-1,1],用一套分值代表一个人,就叫作向量化,虽然不能代表全部,但至少是个量度。因此,可以说,万物皆可向量化。
词向量
同理,词也可以向量化word2vec(word to vector),可以从词性、感情色彩、程度等等方面量度,用一套分值代表一个词,从而词之间可以替换,比较。词与向量间的转换过程就叫作词的向量化。与人为评分不同的是,词向量一般通过训练生成,其每一维量度的作用也并不明确。词向量化常用于提取词的特征,提取后的特征再代入模型计算。
词向量如下图所示:
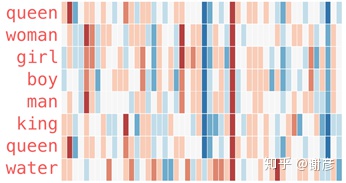
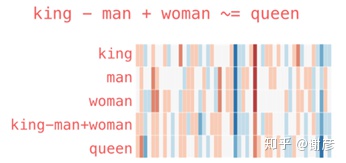
上图把每个单词映射到50个维度(用50种特征表示一个词),每个维度在[-1,1]范围内取值,上图中1为红色,0为白色,-1为蓝色,中间各值为过渡色,从图中可以直观看到词间的相似度。 获取了词向量之后,除了可以计算词间或句间相似度,查找近义词,代入模型以外,还可以做组合词义,以及排除某种含义,如下图所示:
Gensim
Gensim是一款常用的自然语言处理工具,提供Python三方工具包,常用于从文本中提取特征,提供TF-IDF,LSA,LDA,word2vec等功能。开发者可以用它训练自己的词向量,也可以使用他人训练好的词向量。
使用Gensim支持用数据训练词向量,网上例程很多。其原理是一种无监督学习,通过代入大量文章,根据各个词与其上下文关系,挖掘词义。一般自然语言处理的深度学习模型的第一层都是词向量化,因此,除了使用Gensim训练,还可以从其它模型中导出词向量。需要注意的是:高相似度表示两个词通常可以互换。并不一定是同义词,很多情况下,替换成反意词后句子也能读通,但含义完全不同。
腾讯词向量
腾讯词向量提供800多万中文词条,每个词条展开成200维向量,解压后16G。它使用Directional Skip-Gram(Skip-Gram的改进版)训练而成,可使用Ginsim调用。相对于传统的同义词词林和词表,可以说非常先进了。它提供的是通常意义上的词义,但对于具体任务不是很完美。可从以下网址下载腾讯词向量: https://ai.tencent.com/ailab/nlp/embedding.html 下面是官方示例。
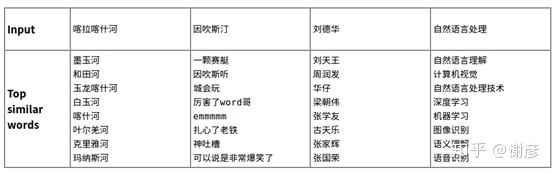
那么何时选择腾讯词向量,何时又需要自己训练模型计算词向量?二者各有利弊,腾讯词向量体量大,速度慢,但涵盖的词和短语非常丰富,准确率也比较高。如果使用模型训练,则可针对某一目标训练,比如判别感情色彩时,某个词的表征和通常情况下的表征很可能有所不同,模型训练需要有足够的训练集,还要考虑模型支持词表(以字为单位还是以词为单位,如何分词),向量维度等等问题,难度更大,选择应视情况而定。
示例:
找近义词
- from gensim.models import KeyedVectors
- file = '/exports/nlp/Tencent_AILab_ChineseEmbedding.txt'
- wv_from_text = KeyedVectors.load_word2vec_format(file, binary=False) # 加载时间比较长
- wv_from_text.init_sims(replace=True)
- word = '膝关节置换手术'
- if word in wv_from_text.wv.vocab.keys():
- vec = wv_from_text[word]
- print(wv_from_text.most_similar(positive=[vec], topn=20))
- else:
- print("没找到")
其运行结果如下图所示,看似比较合理。

有一些专有名词或者短语,可能没收录在词库中,这种情况下可以使用先拆词,对其中各个词分别映射向量,然后取均值的方法计算。
计算词距
- print(wv_from_text.distance("喜欢", "讨厌")) # 0.299
- print(wv_from_text.distance("喜欢", "爱")) # 0.295
- print(wv_from_text.distance("喜欢", "西瓜")) # 0.670
这里指的距离,并不是近义词或者反义词,只是句中该处是否可被另一个词替换的可能性
计算字串距离
- print(wv_from_text.n_similarity(['风景', '怡人'],['山美','水美'])) # 0.60
- print(wv_from_text.n_similarity(['风景', '怡人'],['上','厕所'])) # 0.43

