
- 1Linux云计算 |【第一阶段】SERVICES-DAY3
- 2GoC语言学习(C/C++程序设计语言入门)_goc编程
- 3Python实现数据分析(七)统计学基础_python如何做数学统计分析
- 4第三节、语言模型_符号的二元模型和三元模型是什么
- 5土壤养分检测仪——助力农田监测
- 6国家开放大学计算机应用基础代做,《国家开放大学学习指南》计算机应用基础网上作业答案完整版...
- 7DbGate 开源、免费的 、智能的、NoSQL &SQL 数据库工具_dbgate中文插件
- 8IIS网站只能通过localhost访问,IP和主机名都不行_iis localhost可以访问 ip不能访问
- 9【docker 】Windows10安装 Docker_win10安装docker
- 102023 英特尔On技术创新大会直播 | AI 融合发展之旅_meteor lake架构
ADOP带你了解:NVIDIA H100 GPU:揭开下一代 AI 和 HPC 背后的引擎_h100 osfp
赞
踩
由于人工智能(AI)、高性能计算(HPC)和大数据分析的复杂性,现有的计算资源已无法满足不断增长的市场需求。NVIDIA H100 GPU的出现,凭借其出色的工作负载处理能力,迅速掀起了市场热潮。阅读本文,了解 NVIDIA H100 GPU 互连解决方案如何帮助您实现性能改进和业务增长。
什么是 NVIDIA H100 GPU?
NVIDIA H100 GPU 是 DGX 系列的最新产品,旨在为高性能计算和数据中心应用提供强大的支持。H100 利用专为万亿参数语言模型量身定制的专用 Transformer 引擎来加速数十亿到数万亿的工作负载。这在人工智能和高性能计算的规模上实现了重大飞跃,为每个数据中心提供了前所未有的性能、可扩展性和安全性。它在 AI、HPC 和图形处理领域提供无与伦比的加速,解决了最具挑战性的计算问题。因此,它已成为许多超级计算数据中心的首选。
有关 H100 GPU 的更多信息,您可以阅读以下内容: NVIDIA DGX H100 简介
NVIDIA H100 GPU 与 A100 GPU
A100 是 H100 GPU 的前身,早在 2020 年就已经发布。它基于 7 纳米工艺构建,支持 AI 推理和训练。在性能方面,与A100相比,H100 GPU可以说是一个巨大的飞跃。
性能差异
与上一代A100相比,H100在高吞吐量和性能方面逐渐增强。众所周知,NVIDIA A100 GPU 在各种基准测试中都具有令人印象深刻的性能。在浮点运算方面,A100 为双精度 (FP64) 提供高达 19.5 TFLOPS (TFLOPS) 的浮点运算,为单精度 (FP32) 运算提供高达 39.5 TFLOPS 的浮点运算。NVIDIA H100 GPU 虽然没有提供双精度 (FP64) 和单精度 (FP32) 的特定 TFLOPS 值,但 H100 旨在显着提高计算吞吐量,这对于科学模拟和高性能计算应用中的数据分析至关重要。
在 AI 计算方面,A100 张量运算为 FP16 精度提供高达 312 TFLOPS,为张量浮点 32 (TF32) 运算提供高达 156 TFLOPS。第四代张量核心有望为 H100 带来显着的性能改进,使其成为极其强大的 AI 建模和深度学习工具。

设计功耗比较
除了基线性能的差异外,NVIDIA A100 GPU 和 NVIDIA H100 GPU 在散热设计和能效方面也存在差异。A100 GPU 配备 40 GB HBM2 内存、250W 的 TDP 和相对较低的功耗。H100 PCIe版本的TDP为350W,接近其A100 80GB PCIe版本的300W TDP。因此,A100 GPU 消耗的功率相对较少,需要更多的冷却系统来帮助散热。虽然在某些配置下,两者都可以达到高达 700w 的 TDP,但 H100 GPU 比 A100 GPU 更节能。H100 提高了效率,尤其是在人工智能和深度学习任务方面,可以更好地满足计算性能。
总体而言,NVIDIA H100 GPU的性能水平是A100的三倍,而成本仅高出1.5-2倍。因此,H100的性能更具吸引力。而从技术细节上看,与A100相比,H100的16位推理速度提升了约3.5倍,16位训练速度也提升了2.3倍。
如何使用NVIDIA H100 GPU完成互连?
通过以上内容了解了NVIDIA H100 GPU的优势后,下一步就是研究如何完成网络的H100连接。NVIDIA 通过 NVLink+NVSwitch 互连 GPU,绕过传统的 PCIe 总线,实现更高的带宽和更低的延迟。
NVSwitch 连接
NVIDIA 第三代 NVSwitch 和第四代 NVLink 技术为 NVIDIA H100 GPU 提供了比 A100 GPU 更高速的点对点互连解决方案。NVLink的主要目的是为GPU互联提供高速的点对点网络,并随着GPU架构的演进而发展。
在这种网络架构中,每个 H100 有 18 个 NVLink 连接,分为 4 组,每组连接 4 个 NVSwitches。这 4 个 NVSwitch 芯片共有 18 个 OSFP 接口,用于与 GPU 节点互联互通。每个 NVLink 连接的带宽为 50GB/s,相当于一个 OSFP 端口的带宽为 400Gb/s。DGX H100 服务器有 18 个 OSFP 端口,而 NVLink 交换机有 124 个 NVLink 和 32 个 OSFP 端口。对于包含 32 个 GPU 服务器的单个 SU,需要 18 个 NVLink 交换机进行互连。
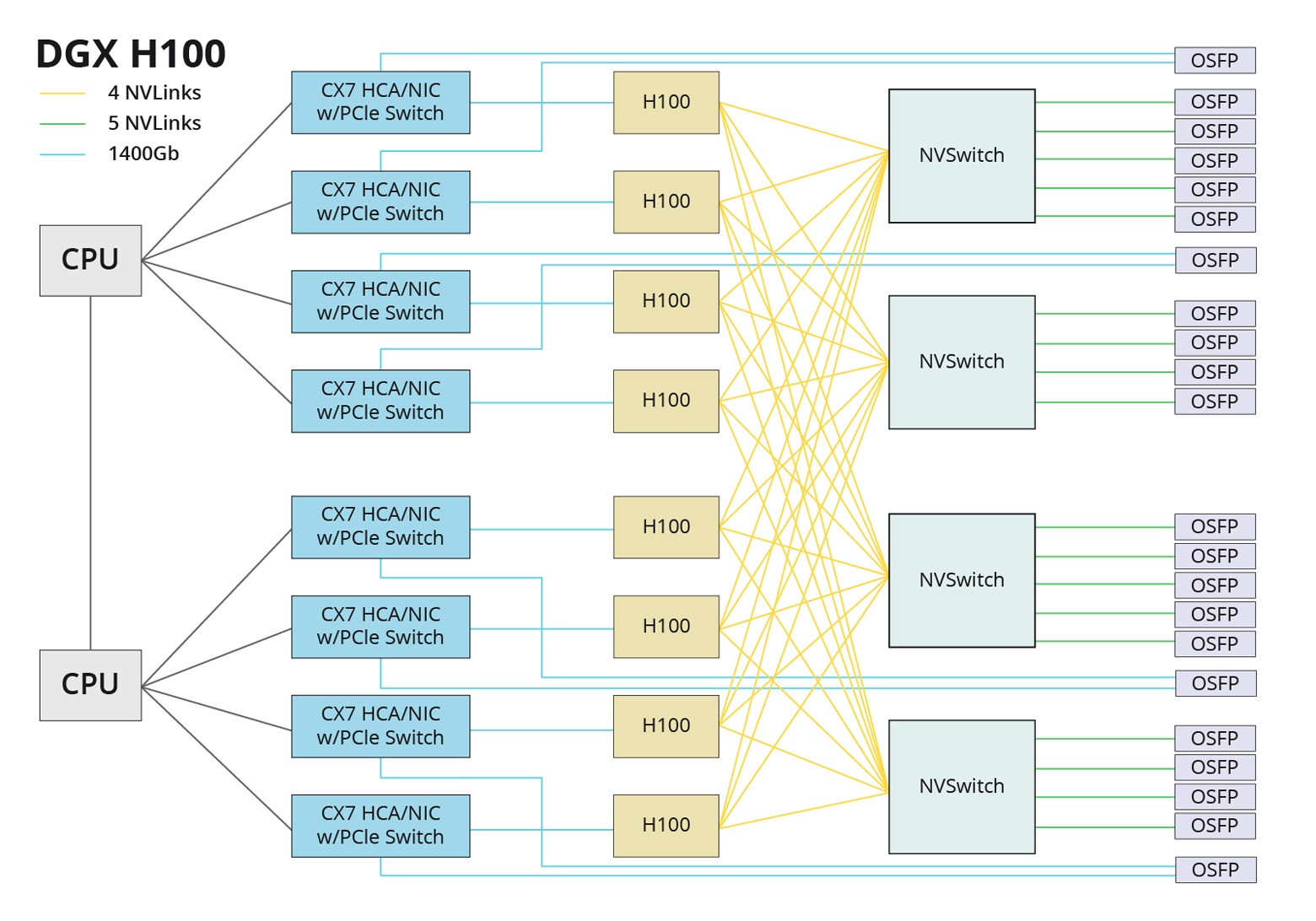
RDMA-InfiniBand 连接
在 IB 网络架构中,单个 HGX H100 8-GPU 主板通过 8 个 PCIe Gen5x16 通道连接到 4 个 PCIe 交换机。GPU 节点之间的互连是通过 PCIe 交换机上的 8 个网络接口卡 (NIC) 实现的。这 8 个网卡通常使用 CX7 400G 网卡,并通过 400G IB 交换机互连。与之前的连接方案相比,InfiniBand连接方案实现了4×800G带宽。

RDMA-RoCE 连接
第三种连接解决方案是通过以太网TCP/IP协议的UDP层使用RoCE-V2(基于以太网的RDMA)。顾名思义,它利用以太网交换机,计算网络架构,以及与IB网络一致的数量。如下图所示。

用先进的H100解决方案赋能未来
探索 ADOP H100 InfiniBand 解决方案
ADOP H100 InfiniBand 解决方案是一种高性能网络技术,专为满足科学计算、人工智能(AI)和云数据中心的需求而设计。这项技术提供了以下几个关键优势:
- 高性能:NVIDIA Quantum InfiniBand 平台提供端到端的高性能网络,适用于处理高分辨率模拟、超大型数据集和高度并行的算法。
- 网络计算:InfiniBand 网络解决方案能够完全卸载网络计算,提供所需的性能提升,同时降低成本和复杂性。
- 高级管理功能:InfiniBand 交换机系统提供超高的性能和端口密度,以及如 NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ 等创新功能。
- 软件支持:MLNX_OFED 和 NVIDIA HPC-X® 等软件套件利用 InfiniBand 网络计算和加速引擎来优化性能,助力科研和行业应用。
探索 ADOP H100 InfiniBand 解决方案,意味着您将能够利用这些先进的技术和功能,为您的数据中心带来前所未有的性能和效率。
ADOP H100 InfiniBand 解决方案的优势
ADOP H100 InfiniBand 解决方案提供了多项优势,特别适用于高性能计算(HPC)和人工智能(AI)领域的数据中心。以下是一些主要优势:
- 超低延迟和高带宽:H100架构通过InfiniBand交换机提供800Gbps的高带宽,确保了具有流控和CRC校验的无损传输。
- PicOS®操作系统:PicOS®提供了一个更具弹性、可编程和可扩展的网络操作系统(NOS),降低了总体拥有成本(TCO)。
- AmpCon™自动化管理平台:AmpCon™使数据中心运营商能够高效地配置、监控、管理和维护现代数据中心织物,实现更高的利用率并降低整体运营成本。
- 简化的GUI基础自动化:自动化交换机配置、部署和无错误配置的规模化。
- 网络虚拟化:使用开放解决方案支持灵活且可扩展的脊柱-叶子数组虚拟化架构。
- 网络可见性:通过SNMP和sFlow获得完整的网络可见性,而gNMI提供高效有效的开放遥测。
这些优势使得ADOP H100 InfiniBand 解决方案成为处理大规模数据和复杂计算任务的理想选择。
最后的想法
NVIDIA H100 GPU将进一步推动人工智能和大规模计算领域的创新,为未来的科研和工程领域带来巨大的性能提升和效率提升。更多以H100为核心的解决方案将不断完善和开发。
ADOP如何提供帮助
专注于高速网络系统的全球技术,我们为 HPC、数据中心、企业和电信解决方案提供高质量的产品和服务。ADOP 致力于提供量身定制的 H100 解决方案。如果您有兴趣,请随时联系ADOP官网。
前沿驱动创新,光学创造未来,ADOP与您精彩前行!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

