
yolo v8环境搭建与简单使用_yolov8环境安装
赞
踩
YOLOv8(You Only Look Once version 8)是一个深度学习框架,用于实现实时对象检测。它是 YOLO 系列的最新迭代,旨在提供更高的准确性和速度。YOLOv8 继承了前代模型的优点,并在此基础上进行了多项改进,包括更复杂的网络架构、更优化的训练流程和更强大的特征提取能力。这些改进共同作用,使得 YOLOv8 在多个标准数据集上达到了前所未有的检测性能。
YOLOv8 的特点:
实时性能: YOLOv8 继续保持 YOLO 系列的实时检测特性,即使在较低的硬件配置上也能达到很高的帧率(FPS)。
高准确度: 通过更深更复杂的网络结构和改进的训练技巧,YOLOv8 在保持高速度的同时,也大幅提高了检测的准确度。
多尺度预测: YOLOv8 引入了改进的多尺度预测技术,可以更好地检测不同大小的对象。
自适应锚框: 新版在自适应调整锚框方面做了优化,可以更准确地预测对象的位置和大小。
一、环境安装
1.1 miniconda安装
1.1.1miniconda安装
- 下载地址:链接
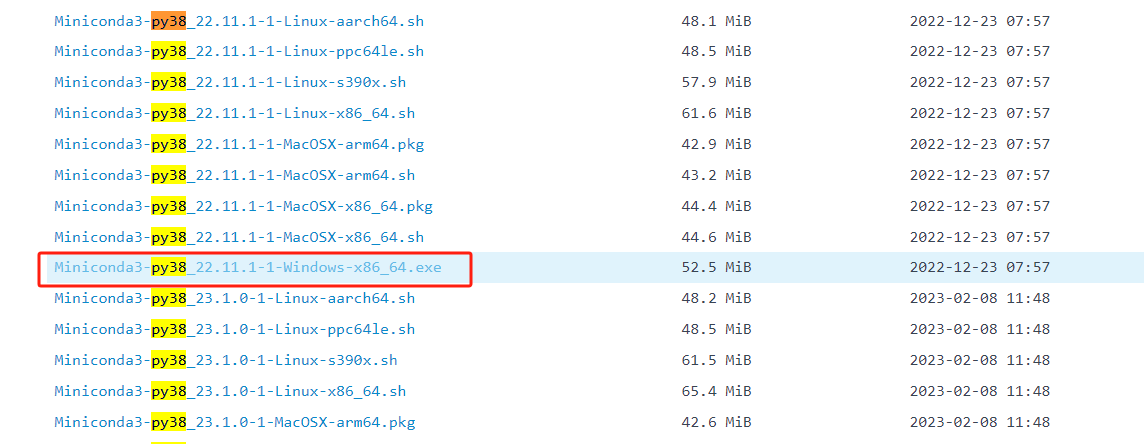
- 如果C盘有空间,最好安装在C盘,且安装目录不要有中文
- 勾选将其添加到Path
1.1.2 conda环境创建
- 命令:
conda create -n yolov8 python=3.8 - 明确指定版本,否则可能会因为版本过高导致有包安装不上
#激活环境
conda activate yolov8
- 1
- 2
1.1.3 pypi配置国内源
- 清华源地址:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
- 设置为默认镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
1.2 pytorch安装
1.2.1 pytorch安装
- 官网地址:链接
- 在一个单独的环境中,能使用pip就尽量使用pip,实在有问题的情况,例如没有合适的编译好的系统版本的安装包,再使用conda进行安装,不要来回混淆
1.2.2 CUDA是否需要安装
- 如果只需要训练、简单推理,则无需单独安装CUDA,直接安装pytorch,如果有部署需求,例如导出TensorRT模型,则需要进行CUDA安装
1.2.2.1 首先查看自身电脑的是否有NVIDIA硬件环境
在电脑桌面右键,打开NVIDIA的控制面板
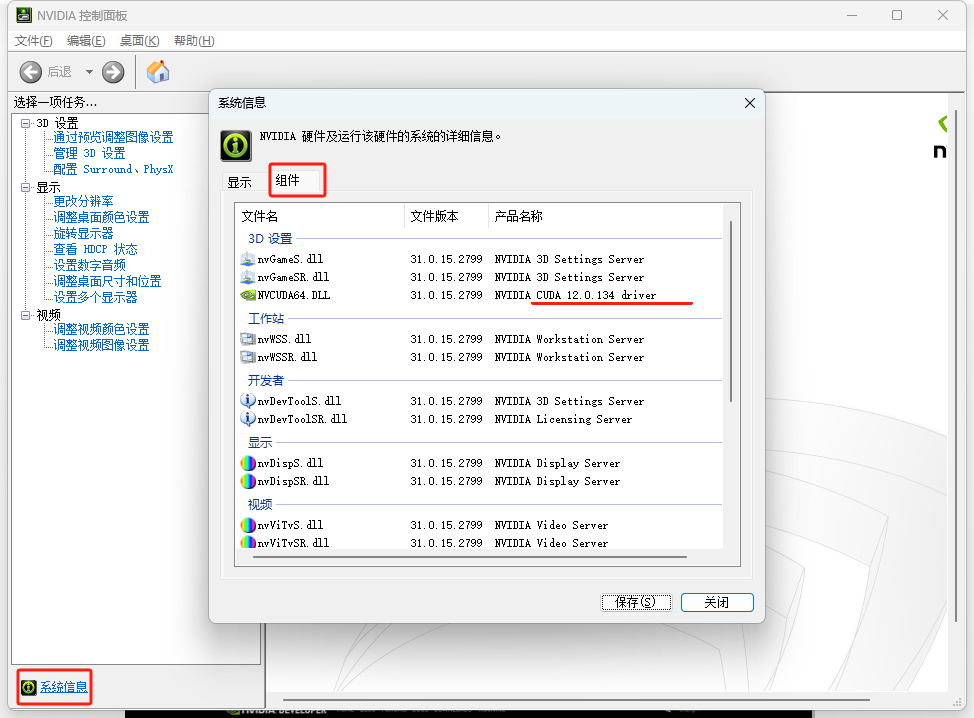
1.2.2.2 下载对应cuda版本的驱动
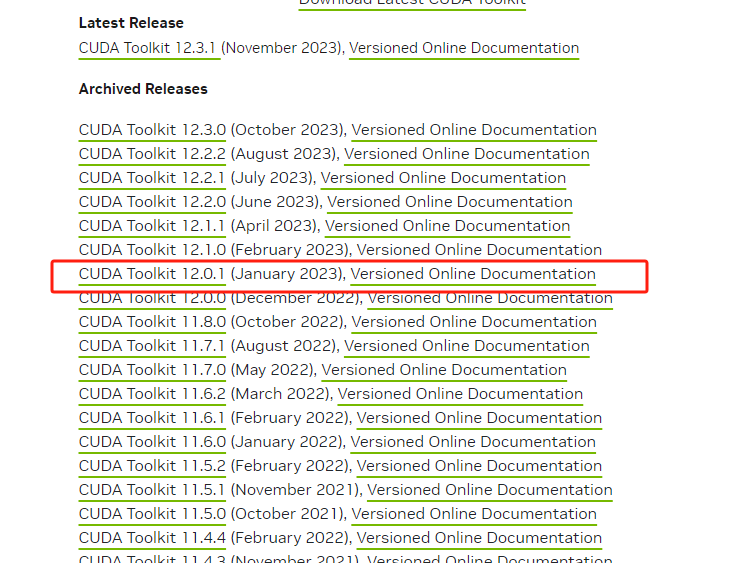
下载地址:链接
选择自己对应的版本下载
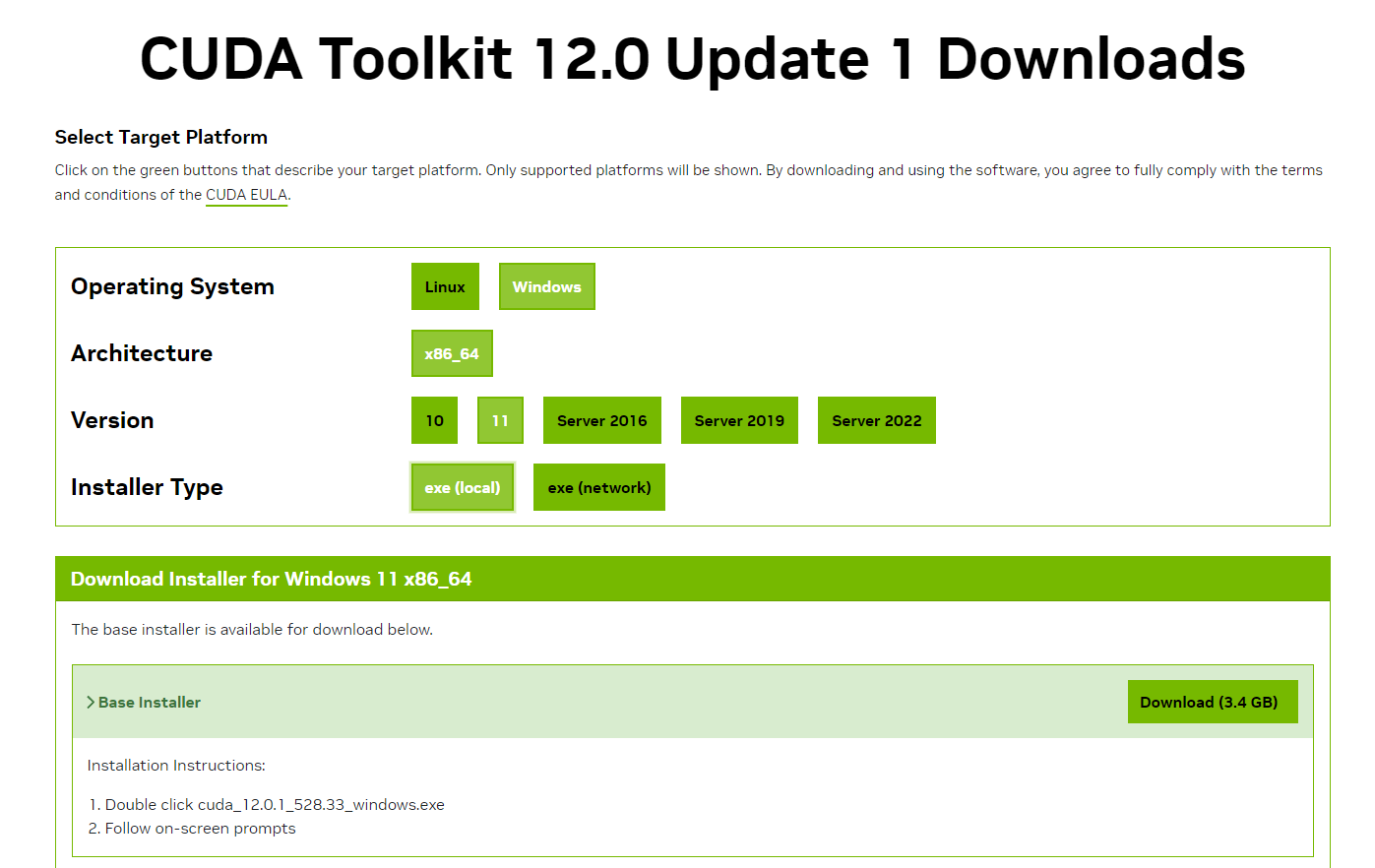
安装时可以默认路径安装,按照提示进行安装即可
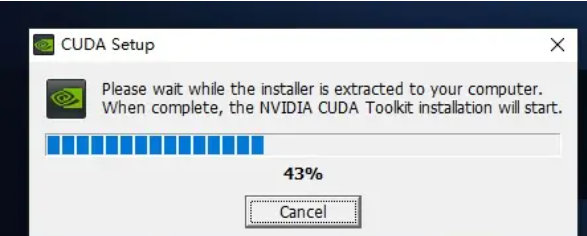
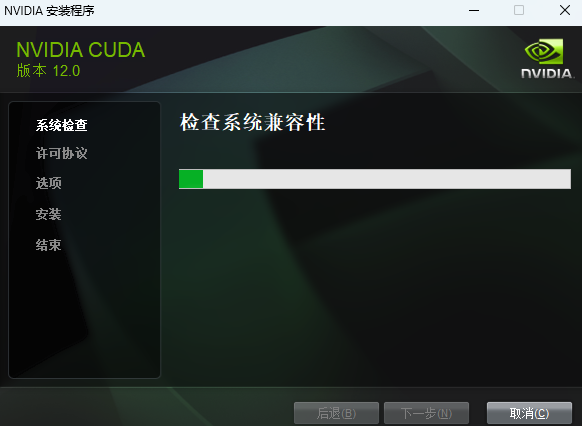
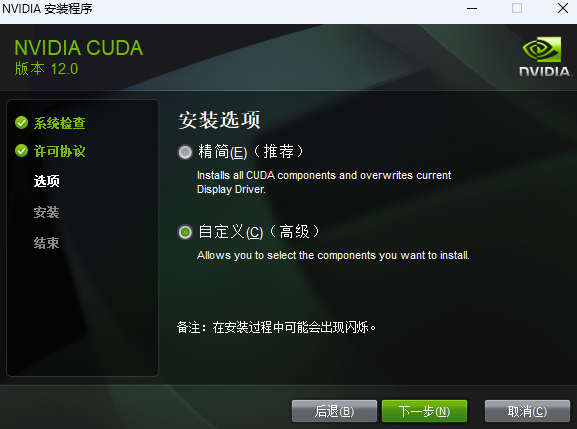
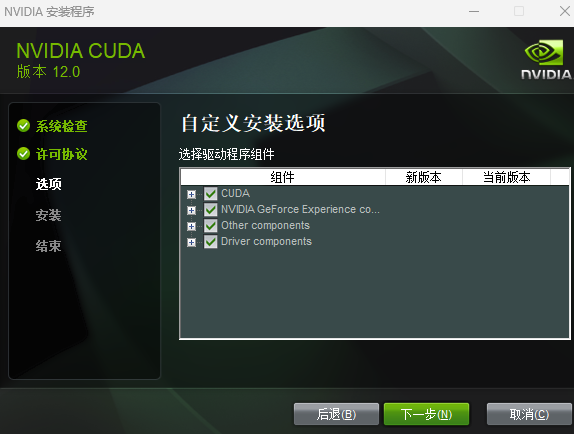
1.2.2.3 下载安装cuDNN
http官网地址 https://developer.nvidia.com/cudnn-downloads 点我跳转
下载cuDNN是需要登录英伟达开发者账户的,注册一个并填写问卷就行了,很简单。
注意:必须选择和你安装的CUDA匹配的版本,我这里选中12.0.1版本的。
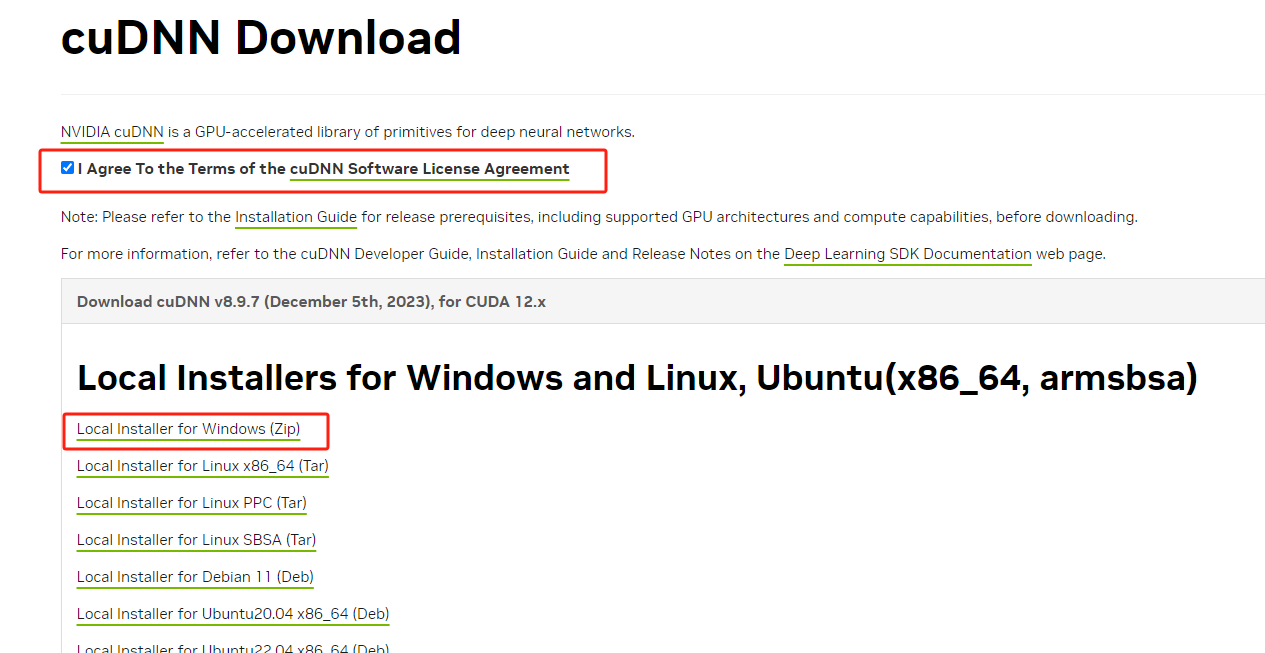
- 将cuDNN解压到D盘
- 将三个文件夹拷贝到到cuda的安装目录下。默认的安装路径为
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0 - 添加环境变量
1 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0\bin
2 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0\include
3 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0\lib
4 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0\libnvvp
- 1
- 2
- 3
- 4
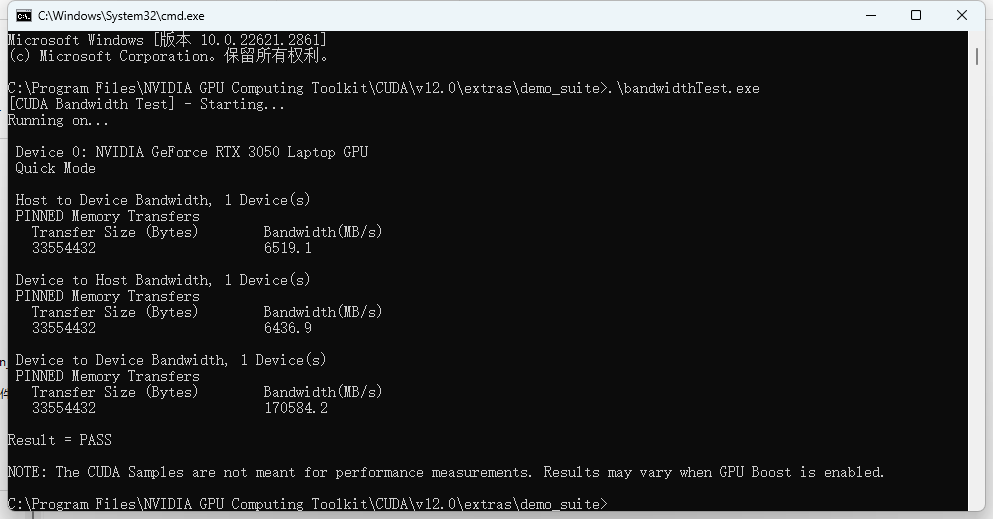
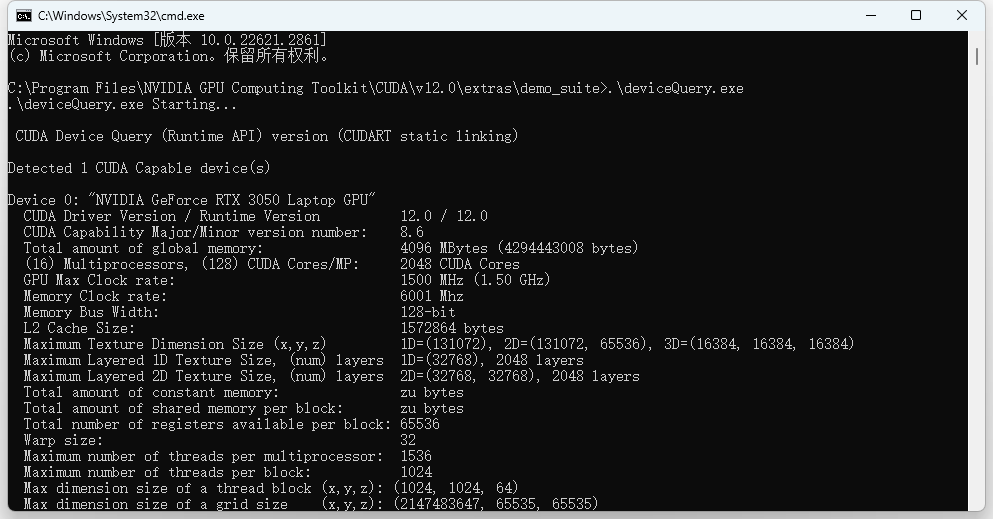
-验证: win+R cmd进入安装目录下,再进入到 extras\demo_suite下,执行.\bandwidthTest.exe和.\deviceQuery.exe,得到下图。
1.2.3Pytorch安装注意事项
- 16XX的显卡,安装cu102版本,否则可能训练出现问题
- 30xx、40xx显卡,需要安装cu111以上版本,否则无法运行
- 这里我的显卡事3050的,使用的安装命令是
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
- 1
1.3 ultralytics(YOLOv8)安装
- 直接使用源码(不是很推荐,无法使用命令行工具) github地址
- pip直接安装(官方推荐,个人不是很推荐)
- pip源码安装(个人推荐)
1.下载github源码
2.解压源码
3.进入解压的ultralytics-main文件夹
4.执行pip install -e . (-e . 参数必须要有,否则后续修改代码无效)
- 1
- 2
- 3
- 4
安装好之后,使用 pip list 查看
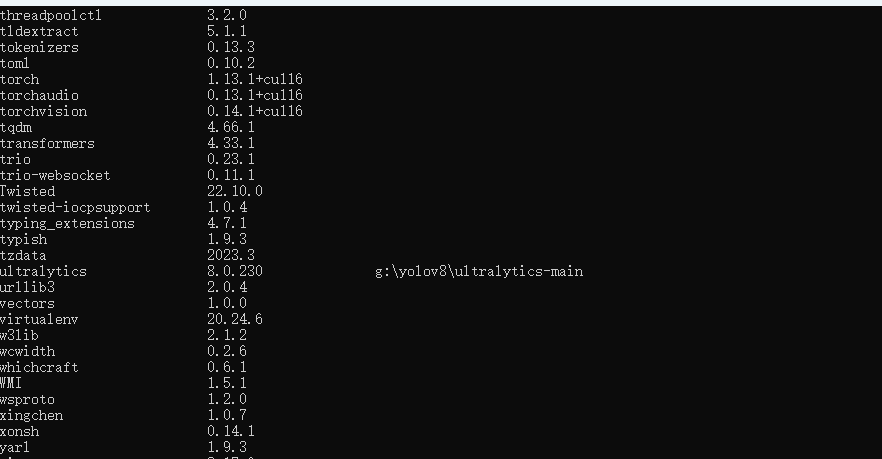
后边的后缀表示这个包的源码在哪个位置
可能会出现的问题:ERROR: Cannot uninstall ‘TBB’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
- 执行pip - V (大写V),会出现一个目录
- 进入目录 Lib\site-packages 删除文件夹:“llvmlite”
- 然后执行 conda uninstall TBB 中间需要输入一次Y
- 然后再重新安即可装
1.3.1 测试
先进入ultralytics-main目录,然后激活环境
conda activate yolov8
再执行命令
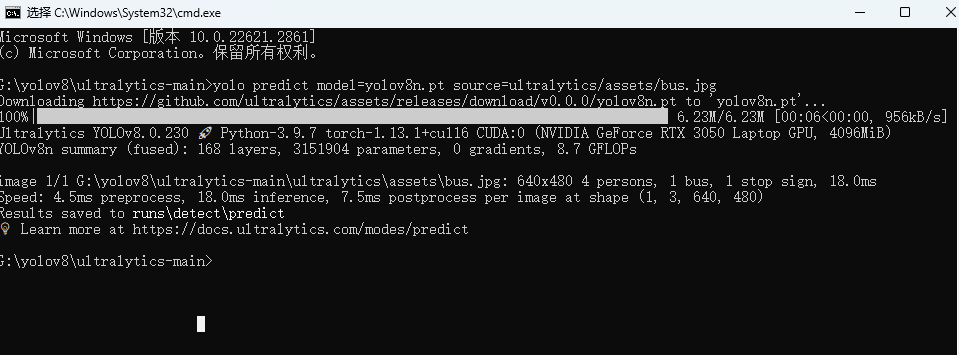
#这个命令需要下载模型,网络不稳定可能需要科学上网
yolo predict model=yolov8n.pt source=ultralytics/assets/bus.jpg
- 1
- 2
1.4 正确使用windows中的终端
因为此前已经创建过虚拟环境了,激活环境conda activate yolov8
二、模型预测
2.1 模型预测的基本使用
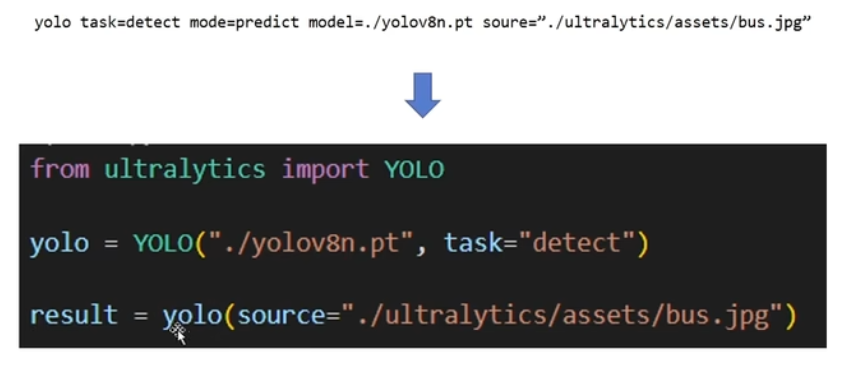
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt" ,task = "detect")
# result=yolo(source="./ultralytics/assets/bus.jpg")#对图片进行检测/这里也可以是视频
# result=yolo(source="screen")#对屏幕进行检测
# result=yolo(source=0)#对摄像头进行检测
# result=yolo(source="./ultralytics/assets/bus.jpg",save=True)#save=True 对检测结果保存
result=yolo(source="./ultralytics/assets/bus.jpg",save=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.2 预测参数详解
YOLOv8现在可以接受输入很多,如下表所示。包括图像、URL、PIL图像、OpenCV、NumPy数组、Torch张量、CSV文件、视频、目录、通配符、YouTube视频和视频流。表格✅指示了每个输入源是否可以在流模式下使用,并给出了每个输入源使用流模式的示例参数
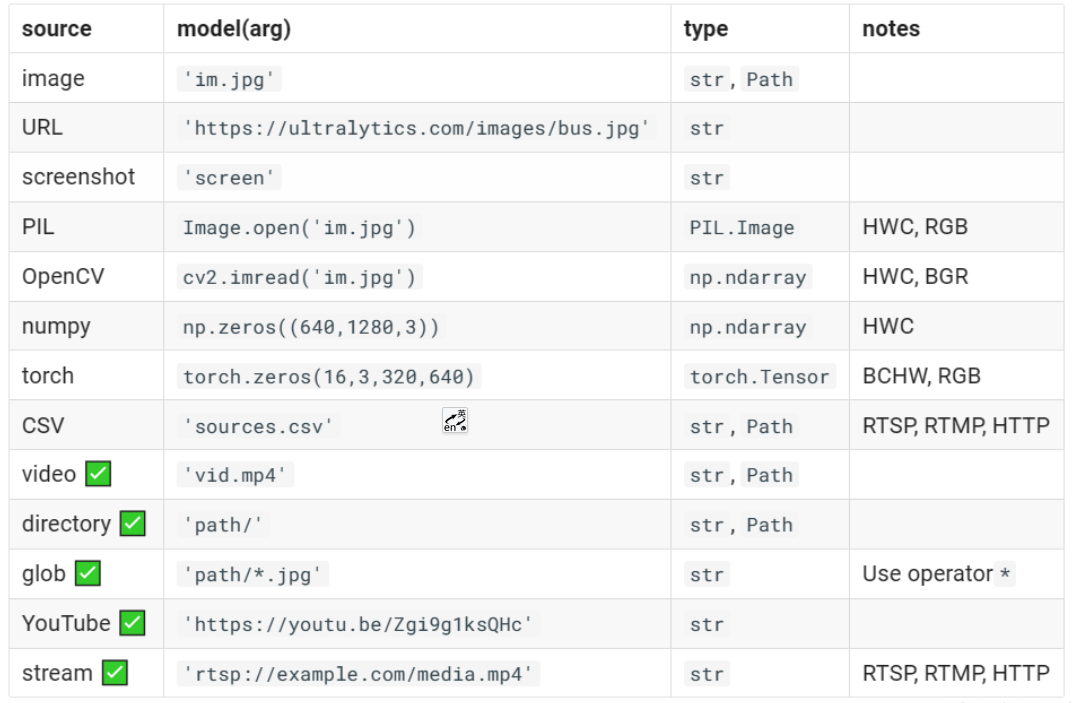
预测参数
| Key | Value | Description |
|---|---|---|
| source | ‘ultralytics/assets’ | source directory for images or videos |
| conf | 0.25 | object confidence threshold for detection |
| iou | 0.7 | intersection over union (IoU) threshold for NMS |
| half | FALSE | use half precision (FP16) |
| device | None | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
| show | FALSE | show results if possible |
| save | FALSE | save images with results |
| save_txt | FALSE | save results as .txt file |
| save_conf | FALSE | save results with confidence scores |
| save_crop | FALSE | save cropped images with results |
| hide_labels | FALSE | hide labels |
| hide_conf | FALSE | hide confidence scores |
| max_det | 300 | maximum number of detections per image |
| vid_stride | FALSE | video frame-rate stride |
| line_width | None | The line width of the bounding boxes. If None, it is scaled to the image size. |
| visualize | FALSE | visualize model features |
| augment | FALSE | apply image augmentation to prediction sources |
| agnostic_nms | FALSE | class-agnostic NMS |
| retina_masks | FALSE | use high-resolution segmentation masks |
| classes | None | filter results by class, i.e. class=0, or class=[0,2,3] |
| boxes | TRUE | Show boxes in segmentation predictions |
下面是每个参数的解释:
- source:输入源的目录,可以是图像或视频文件。
- conf:目标检测的对象置信度阈值。只有置信度高于此阈值的对象才会被检测出来。默认值为0.25。
- iou:非极大值抑制(NMS)的交并比(IoU)阈值。用于在重叠较大的候选框中选择最佳的检测结果。默认值为0.7。
- half:是否使用半精度(FP16)进行推理。半精度可以减少计算量,但可能会牺牲一些精度。默认值为False。
- device:模型运行的设备,可以是cuda设备(cuda device=0/1/2/3)或CPU(device=cpu)。
- show:是否显示检测结果。如果设置为True,则会在屏幕上显示检测到的对象。默认值为False。
- save:是否保存带有检测结果的图像。如果设置为True,则会将检测结果保存为图像文件。默认值为False。
- save_txt:是否将检测结果保存为文本文件(.txt)。默认值为False。
- save_conf:是否将检测结果与置信度分数一起保存。默认值为False。
- save_crop:是否保存裁剪后的带有检测结果的图像。默认值为False。
- hide_labels:是否隐藏标签。如果设置为True,则在显示检测结果时不显示对象标签。默认值为False。
- hide_conf:是否隐藏置信度分数。如果设置为True,则在显示检测结果时不显示置信度分数。默认值为False。
- max_det:每张图像的最大检测数。如果检测到的对象数超过此值,将保留置信度高低来保留。默认值为300。
- vid_stride:视频帧率步长。默认值为False,表示使用默认的帧率。
- line_width:边界框的线宽。如果设置为None,则根据图像大小进行自动缩放。默认值为None。
- visualize:是否可视化模型特征。默认值为False。
- augment:是否对预测源应用图像增强。默认值为False。
- agnostic_nms:是否使用类别无关的NMS。默认值为False。
- retina_masks:是否使用高分辨率的分割掩膜。默认值为False。
- classes:按类别过滤结果。可以指定单个类别(例如class=0)或多个类别(例如class=[0,2,3])。默认值为None,表示不进行类别过滤。
- boxes:在分割预测中显示边界框。默认值为True。
三、数据集构建
3.1 准备数据
这里以视频为例,将视频抽帧处理
import cv2
video = cv2.VideoCapture("./001.mp4")
num=0#计数器
save_setp=30#间隔帧数
while True:
ret,frame=video.read()
if not ret:
break
num+=1
if num%save_setp==0:
cv2.imwrite("./img/"+str(num)+".jpg",frame)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.2 数据标注
环境安装:pip install labelimg
启动:labelimg

3.2.1 基础设置
- 设置打开文件夹和保存文件夹
- 设置自动保存:工具栏 view-auto save mode
- 切换模式
- 点击save保存修改
3.2.2 开始标注
- 双击右侧FileList内的图片打开后,右键create RectBox开始标注
3.2.3 make senc数据集标注工具
- 地址:https://www.makesense.ai/
- 辅助标注:
- pip instll tensorflowjs==2.8.5
- YOLOv5模型导出tfjs
- make scene上传模型
3.3 roboflow公开数据集
- https://public.roboflow.com/object-detection
- https://universe.roboflow.com/
四、模型训练
4.1 训练前准备
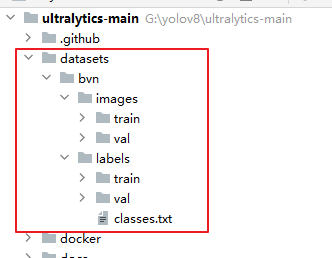
4.1.1 数据集准备:
- images:存放图片
- train:训练集图片
- val: 验证集图片
- labels:存放标签
1.train:训练集标签文件,要与训练集图片名称一一对应
2.val:验证集标签文件,要与验证集图片名称一一对应
此前打标签时导入的文件夹就是训练集,输出结果就是验证集,无非是把目录结构按上述更改一下
4.1.2 文件准备:
源码下载地址: https://github.com/ultralytics/ultralytics
- 准备图片文件夹:再yolov8源码目录下,新建datasets文件夹,将刚才准备好的图片数据复制进该文件夹,bvn为项目名
- 从ultralytics/cfg/datasets文件夹下随便复制一个yaml配置文件至ultralytics-main根目录下
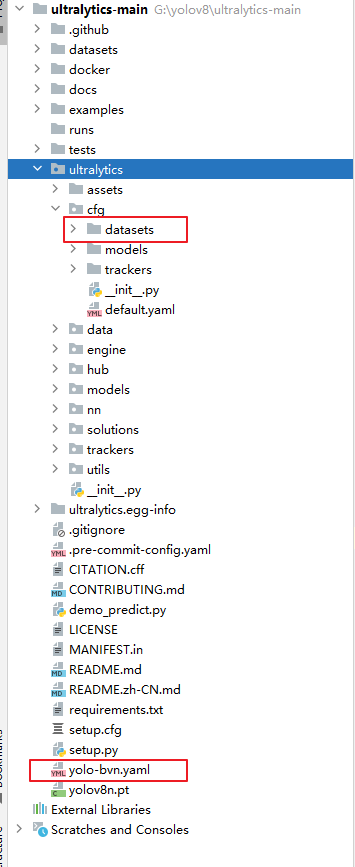
- 改写配置文件
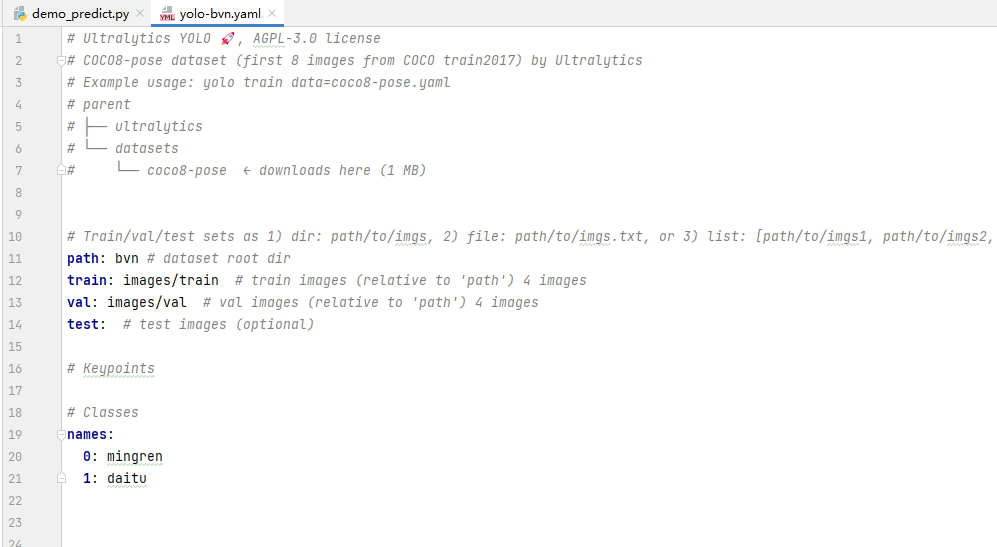
- path为从datasets目录开始算的根文件夹名称
- train与val时训练集与验证集的位置
- names这里就是分类标签,可以按照标注后沈城的calsses.txt文件填下
4.2 模型训练与常用参数

参数说明:
- data:为yaml配置文件
- epochs:训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。训练的轮数越多,模型对数据的学习就越充分,但也增加了训练时间
- batch:每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为**-1**,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
- patience:早停的等待轮数。在训练过程中,如果在一定的轮数内没有观察到模型性能的明显提升,就会停止训练。这个参数确定了等待的轮数,如果超过该轮数仍没有改进,则停止训练。
- imgsz:输入图像的尺寸。这个参数确定了输入图像的大小。可以指定一个整数值表示图像的边长,也可以指定宽度和高度的组合。例如640表示图像的宽度和高度均为640像素。
- save:是否保存训练的检查点和预测结果。当训练过程中保存检查点时,模型的权重和训练状态会被保存下来,以便在需要时进行恢复或继续训练。预测结果也可以被保存下来以供后续分析和评估。
- save_period: 保存检查点的间隔。这个参数确定了保存检查点的频率,例如设置为10表示每隔10个训练轮数保存一次检查点。如果设置为负数(如-1),则禁用保存检查点功能。
- cache: 数据加载时是否使用缓存。这个参数控制是否将数据加载到缓存中,以加快训练过程中的数据读取速度。可以选择在 RAM 内存中缓存数据(True/ram)、在磁盘上缓存数据(disk)或不使用缓存(False)。
- device: 训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 cuda device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
- workers: 数据加载时的工作线程数。在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。这个参数确定了加载数据时使用的线程数,具体的最佳值取决于硬件和数据集的大小。windows系统下需设置为0,否则会报错
11.model:模型文件的路径,可以是预训练的模型权重文件(如yolov8n.pt)或模型配置文件(如yolovn.yaml)
4.2.1 命令行启动训练
yolo task=detect mode=train model=./yolov8n.pt data="data.yaml" workers=1 epochs=50 batch=16
- 1
4.2.2 代码启动训练
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
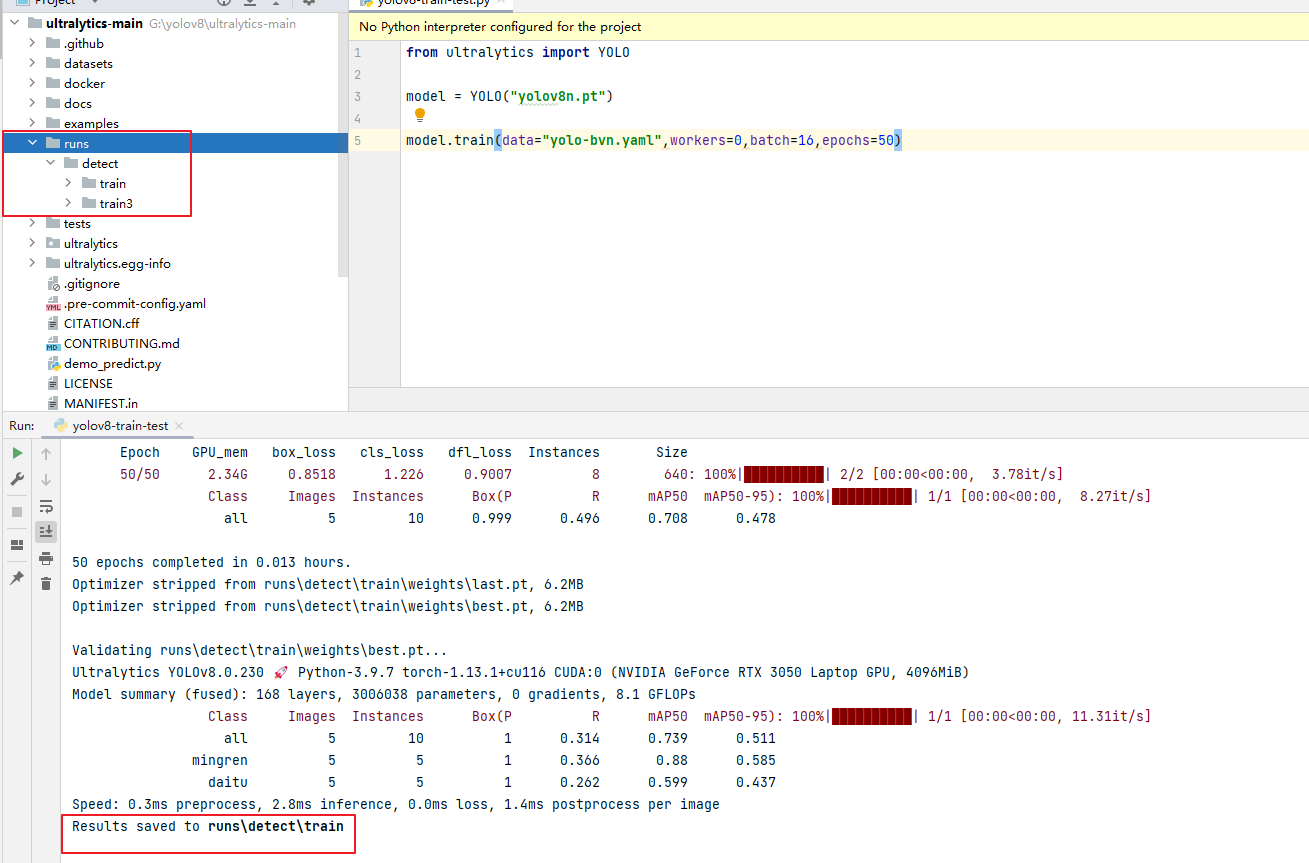
model.train(data="yolo-bvn.yaml",workers=0,batch=16,epochs=50)
- 1
- 2
- 3
- 4
- 5
4.2.3 模型训练结果
模型训练结果会保存至runs目录下
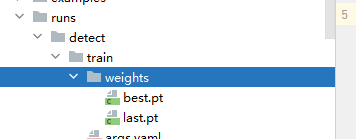
::: tip
模型存储在weights文件夹下
best.pt:是训练出的最好的模型
last.pt:是最后面的模型,如果需要继续训练需要使用
:::
模型测试:
yolo detect predict model=runs/detect/train/weights/best.pt source=001.mp4 show=True
- 1
4.2.4 注意事项

其中AppData是再当前用户目录下
五、工具类
这里把模型检测封装了一个工具类
import os
from datetime import datetime
import cv2
import keyboard
import pyautogui
from ultralytics import YOLO
class Yolov8Util:
yolo = None
flag=True #是否可以运行
def stop(self):
'''
停止运行方法,这里仅对视频和屏幕捕捉这两种方式生效
:return:
'''
self.flag = False
def __init__(self, pt_path):
'''
创建对象
:param pt_path: 模型pt文件路径
'''
self.yolo = YOLO(pt_path, task="detect")
# 绑定crtl+q退出检测
keyboard.add_hotkey('ctrl+q', lambda: self.stop())
def read_video(self, video_path, show=False,
detection_box_color=(0, 0, 225), text_color=(0, 0, 225), font_scale=0.5,
thickness=2, conf_val=0.25, save_path=None, callback=None,
callback_args_dict={}):
'''
读取视频
:param video_path: 视频路径.可以是网络路径,如果为 video_path=0则开启设备默认摄像头
:param conf_val:置信度
:param detection_box_color:矩形边框的颜色,格式为 BGR。格式 (0, 0, 225)
:param text_color:提示文字的颜色,格式为 BGR。格式 (0, 0, 225)
:param font_scale: 字体大小
:param thickness: 线条的粗细,如果是负数,则表示填充。
:param show:是否展示到屏幕
:param save_path: 结果保存文件夹路径,不指定则不保存,只有检测到目标才会保存
:param callback: 回调函数,该回调会将计算好的 【x1,y1,x2,y2坐标与标签名和置信度、原始图片】封装为数组列表传入,回调函数必须指定另一个字典,如这样定义:def call_fun1(results,args_dict):
:param callback_args_dict: 传入回调函数的其他参数,以字典封装
:return:
'''
cap = cv2.VideoCapture(video_path)
self.flag=True
while self.flag:
# 读取一帧图像
ret, frame = cap.read()
if not ret:
break
ann = frame
results = self.yolo(source=frame, show=False, save=False, conf=conf_val)
for result in results:
# 终止程序
if self.flag == False:
return
result_list = []
for item in result:
try:
# 解析检测结果
name = item.names[item.boxes.cls.item()]
conf = item.boxes.conf[0].item()
x1 = int(item.boxes.xyxy[0][0].item())
y1 = int(item.boxes.xyxy[0][1].item())
x2 = int(item.boxes.xyxy[0][2].item())
y2 = int(item.boxes.xyxy[0][3].item())
# 构建返回结果
list_item = [x1, y1, x2, y2, name, conf, ann]
result_list.append(list_item)
# 绘制检测框
cv2.rectangle(frame, (x1, y1), (x2, y2), detection_box_color, thickness)
cv2.putText(frame, f'{name} {conf:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, font_scale,
text_color, thickness)
except IndexError as e:
continue
# cv2.imshow("yolo检测结果", frame)
if show:
cv2.imshow("yolo检测结果", frame)
cv2.waitKey(1) # 延迟一秒 否则不显示
# 判断是否需要保存
if save_path is not None and len(result_list) > 0:
# 获取当前时间(包含微秒)
current_time = datetime.now()
milliseconds = current_time.microsecond // 1000
formatted_time = current_time.strftime("%Y-%m-%d %H-%M-%S-") + f"{milliseconds:03}"
new_save_path = f"{save_path}\\{formatted_time}.jpg"
cv2.imwrite(new_save_path, frame)
print(f"保存检测结果到{new_save_path}")
# 判断是否有回调函数
if callback is not None:
callback(result_list, callback_args_dict)
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()
def read_picture(self, img_path, show=False,
detection_box_color=(0, 0, 225), text_color=(0, 0, 225), font_scale=0.5,
thickness=2, conf_val=0.25, save_path=None, callback=None,
callback_args_dict={}):
'''
读取图片
:param img_path: 图片路径.可以是网络路径
:param conf_val: 置信度
:param detection_box_color:矩形边框的颜色,格式为 BGR。格式 (0, 0, 225)
:param text_color:提示文字的颜色,格式为 BGR。格式 (0, 0, 225)
:param font_scale: 字体大小
:param thickness: 线条的粗细,如果是负数,则表示填充。
:param show:是否展示到屏幕
:param save_path: 结果保存文件夹路径,不指定则不保存
:param callback: 回调函数,该回调会将计算好的 【x1,y1,x2,y2坐标与标签名和置信度、原始图片】封装为数组列表传入,回调函数必须指定另一个字典,如这样定义:def call_fun1(results,args_dict):
:param callback_args_dict: 传入回调函数的其他参数,以字典封装
:return: [x1,y1,x2,y2,检测标签、置信度,原始图像]
'''
img = cv2.imread(img_path)
results = self.yolo(source=img, show=False, save=False, conf=conf_val)
result_list = []
ann = img
for result in results:
for item in result:
try:
# 解析检测结果
name = item.names[item.boxes.cls.item()]
conf = item.boxes.conf[0].item()
x1 = int(item.boxes.xyxy[0][0].item())
y1 = int(item.boxes.xyxy[0][1].item())
x2 = int(item.boxes.xyxy[0][2].item())
y2 = int(item.boxes.xyxy[0][3].item())
# 构建返回结果
list_item = [x1, y1, x2, y2, name, conf, ann]
result_list.append(list_item)
# 绘制检测框
cv2.rectangle(img, (x1, y1), (x2, y2), detection_box_color, thickness)
cv2.putText(img, f'{name} {conf:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, font_scale,
text_color, thickness)
except IndexError as e:
continue
# 判断是否需要保存
if save_path is not None and len(result_list) > 0:
# 获取当前时间(包含微秒)
current_time = datetime.now()
milliseconds = current_time.microsecond // 1000
formatted_time = current_time.strftime("%Y-%m-%d %H-%M-%S-") + f"{milliseconds:03}"
new_save_path = f"{save_path}\\{formatted_time}.jpg"
cv2.imwrite(new_save_path, img)
print(f"保存检测结果到{new_save_path}")
if show:
cv2.imshow("yolo检测结果", img)
# 判断是否有回调函数
if callback is not None:
callback(result_list, callback_args_dict)
return result_list
def read_screen(self, show=False,
detection_box_color=(0, 0, 225), text_color=(0, 0, 225), font_scale=0.5,
thickness=2, conf_val=0.25, save_path=None, callback=None,
callback_args_dict={}):
'''
读取屏幕
:param conf_val: 置信度
:param detection_box_color:矩形边框的颜色,格式为 BGR。格式 (0, 0, 225)
:param text_color:提示文字的颜色,格式为 BGR。格式 (0, 0, 225)
:param font_scale: 字体大小
:param thickness: 线条的粗细,如果是负数,则表示填充。
:param show:是否展示到屏幕
:param save_path: 结果保存文件夹路径,不指定则不保存
:param callback: 回调函数,该回调会将计算好的 【x1,y1,x2,y2坐标与标签名和置信度、原始图片】封装为数组列表传入,回调函数必须指定另一个字典,如这样定义:def call_fun1(results,args_dict):
:param callback_args_dict: 传入回调函数的其他参数,以字典封装
:return: [x1,y1,x2,y2,检测标签、置信度,原始图像]
'''
self.flag = True
while self.flag:
# 截取屏幕图片
im = pyautogui.screenshot()
im.save('screen.jpg')
img = cv2.imread("screen.jpg")
os.remove("screen.jpg")
results = self.yolo(source=img, show=False, save=False, conf=conf_val)
result_list = []
ann = img
for result in results:
# 终止程序
if self.flag == False:
return
for item in result:
try:
# 解析检测结果
name = item.names[item.boxes.cls.item()]
conf = item.boxes.conf[0].item()
x1 = int(item.boxes.xyxy[0][0].item())
y1 = int(item.boxes.xyxy[0][1].item())
x2 = int(item.boxes.xyxy[0][2].item())
y2 = int(item.boxes.xyxy[0][3].item())
# 构建返回结果
list_item = [x1, y1, x2, y2, name, conf, ann]
result_list.append(list_item)
# 绘制检测框
cv2.rectangle(img, (x1, y1), (x2, y2), detection_box_color, thickness)
cv2.putText(img, f'{name} {conf:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, font_scale,
text_color, thickness)
except IndexError as e:
continue
# 判断是否需要保存
if save_path is not None and len(result_list) > 0:
# 获取当前时间(包含微秒)
current_time = datetime.now()
milliseconds = current_time.microsecond // 1000
formatted_time = current_time.strftime("%Y-%m-%d %H-%M-%S-") + f"{milliseconds:03}"
new_save_path = f"{save_path}\\{formatted_time}.jpg"
cv2.imwrite(new_save_path, img)
print(f"保存检测结果到{new_save_path}")
if show:
cv2.imshow("yolo检测结果", img)
cv2.waitKey(1) # 延迟一秒 否则不显示
# 判断是否有回调函数
if callback is not None:
callback(result_list, callback_args_dict)
def func1(list, dict):
print(list)
print(dict)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231

