
- 1BasicVSR_pp video2frame_video2frame-frame2video
- 2斯坦福NLP名课带学详解 | CS224n 第15讲 - NLP文本生成任务(NLP通关指南·完结)
- 3“金三银四” 软件测试工程师要不要跳槽,看完就懂了_为什么三四线城市对测试工程师不友好
- 4AI教母李飞飞创立的World Labs估值超10亿美元_world labs 官网 李飞飞
- 5蓝桥杯-幸运数(python)_【问题描述】 所有个位数为 的正整数,以及所有 的倍数,都被小明
- 6git 远程拉取指定文件
- 7【Android】探究ContentProvider、运行时申请权限的做法、访问其他程序中的数据、创建自己的ContentProvider、实现跨程序数据共享并且解决存在的权限问题导致无法访问。_contentprovider 无法被创建
- 8牛掰!用Python处理Excel的14个常用操作总结!
- 9rabbitm中消息超时怎么办?_rabbitmq 超时
- 10chatgpt赋能python:Python怎么叠加-优化你的网页_python叠加
仅听3秒,AI零样本克隆人声达到人类水平,情绪语调随意改
赞
踩
量子位 | 公众号 QbitAI
零样本、仅听3秒提示音频,即可1:1复刻人声。
还能给生成人声带入情绪,比如“悲伤”的情绪:
“恶心”的情绪:
这就是微软与中国科技大学、香港中文大学(深圳)和浙江大学等机构合作,推出的NaturalSpeech 3系统。

该系统采用了创新的属性分解扩散模型和属性分解语音神经编解码器FACodec,从“表示”和“建模”两个维度对语音数据进行深入研究。通过数据/模型的规模化方法,在多说话人数据集LibriSpeech上首次实现了零样本的人类水平语音合成。

指定特征实现个性化输出
文本到语音合成(TTS)技术作为生成式人工智能的关键分支,在大型语言模型(LLM)的推动下近年来迎来了突飞猛进的发展。特别是随着语音合成技术的进步,它为大模型带来了声音交互的新维度,受到了业界的高度重视。在这一领域内,微软一直是技术研究与产品开发的积极参与者,旨在创造出高度自然的人类语音。为此,微软启动了NaturalSpeech研究项目(https://speechresearch.github.io/)。
该项目为实现其目标,制定了分阶段的实施路线图:
首先,项目聚焦于在单个说话人语音合成上实现与真人相媲美的音质。2022年,NaturalSpeech 1版本在LJSpeech语音合成数据集上的表现,已达到人类录音的音质水平。
随后,项目目标升级,旨在高效生成具有多样化特征的人类语音,如不同说话人、韵律、情感和风格等。2023年,通过引入扩散模型,NaturalSpeech 2实现了零样本的语音合成,标志着技术的进一步突破。
推出NaturalSpeech 3系统。
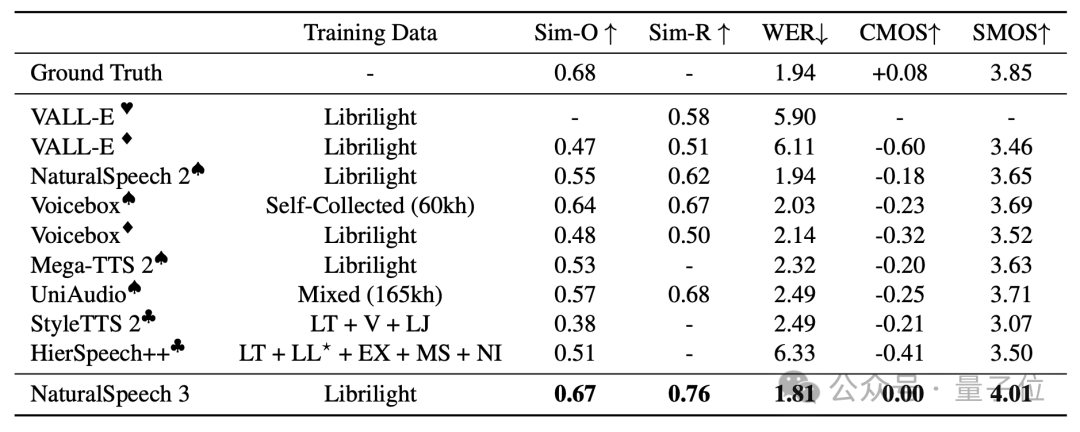
NaturalSpeech 3的”Natural”的一大核心体现就是在LibriSpeech数据集上实现了零样本语音合成达到人类水平。
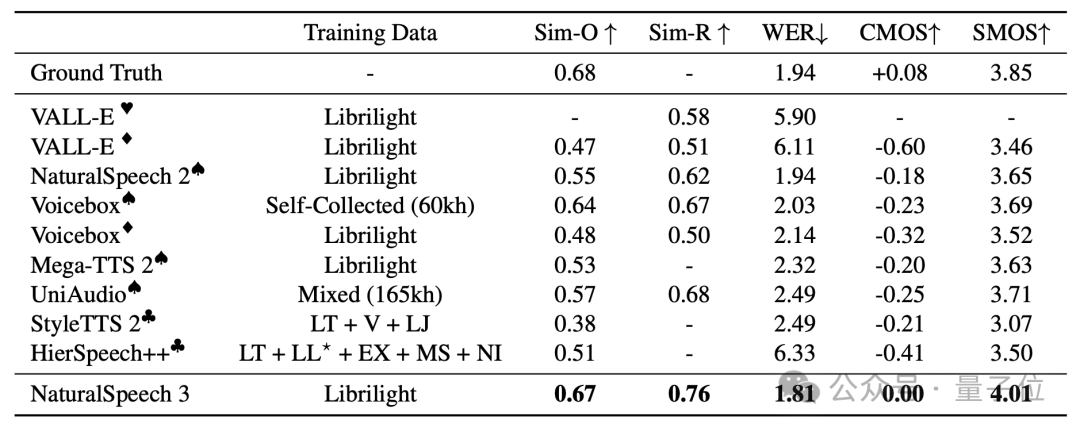
NaturalSpeech 3在LibriSpeech数据集上实现了零样本语音合成对人类录音的-0.08 CMOS(此前的 SOTA 结果为 -0.18)以及超过人类录音的4.01 SMOS (人类录音结果为3.85,而此前的SOTA为3.71),而在WER上,NaturalSpeech 3实现了比人类录音结果(1.94 WER)更低的1.81 WER。
实验结果表明,NaturalSpeech 3的零样本语音生成结果在LibriSpeech数据集上和人类录音水平已经没有统计学上的显著差异。
NaturalSpeech 3的自然不仅体现在能够完美的克隆音色上,还体现在能够自然的模仿提示音频的韵律、情感等,让AI生成的声音具有人类的情绪。
NaturalSpeech 3的技术实现允许对生成的语音进行细致的属性控制,这种方法提供了对语音合成过程中各个维度的精准调节能力。
通过引入特定属性的提示,比如采用语速较快的声音样本作为时长(duration)控制的参考,NaturalSpeech 3能够在保持其他声音属性不变的情况下,精确调整生成语音的语速。
这意味着,用户可以通过指定具有特定特征的样本来引导语音生成过程,进而实现更加个性化和多样化的语音输出。例如下面这个例子:
NaturalSpeech 3的成功秘诀来自于基于属性分解的Codec+Diffusion建模范式以及Data/Model Scaling。
传统TTS系统因训练数据集有限,难以支持高质量的零样本语音合成。而最近的研究通过扩大语料库,虽有所进步,但在声音质量、相似性和韵律方面仍未达到理想水平。
NaturalSpeech 3提出创新的属性分解扩散模型和属性分解神经语音编码器FACodec,通过将语音分解成不同属性的子空间并根据不同的提示(prompt)分别生成,有效地降低了语音建模难度,从而大大提高了语音合成的质量和自然度。
与此同时,NaturalSpeech 3通过将训练数据扩展到20万小时(这是迄今为止公开的研究工作中使用的最大规模数据)以及将模型大小扩展到1B(2B甚至更大的模型正在训练中),进一步提升语音合成的质量和自然度。
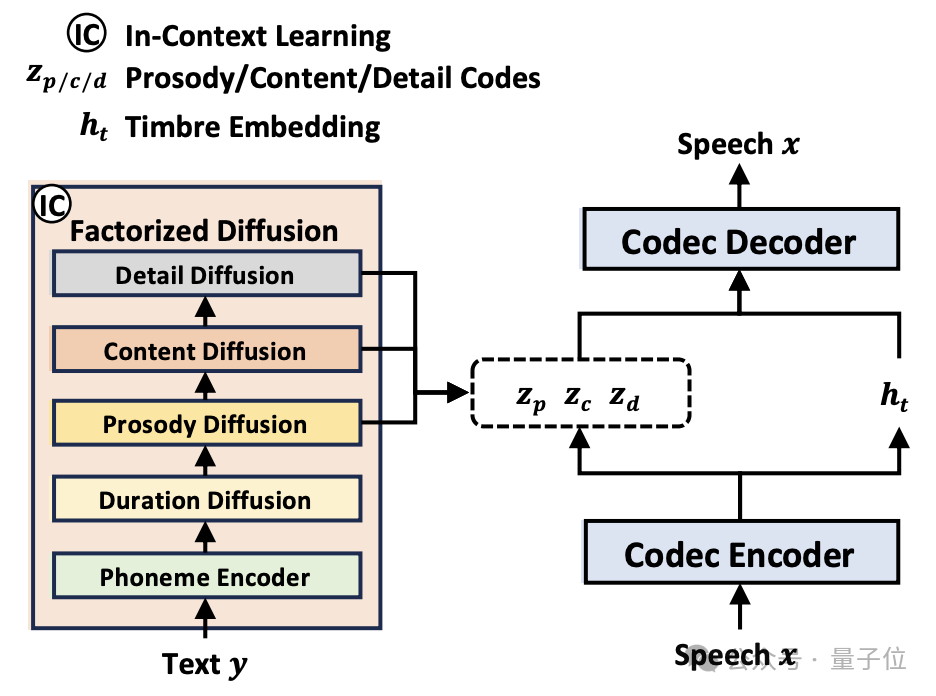
NaturalSpeech 3采用的属性分解神经语音编解码器(FACodec)是一项创新技术。
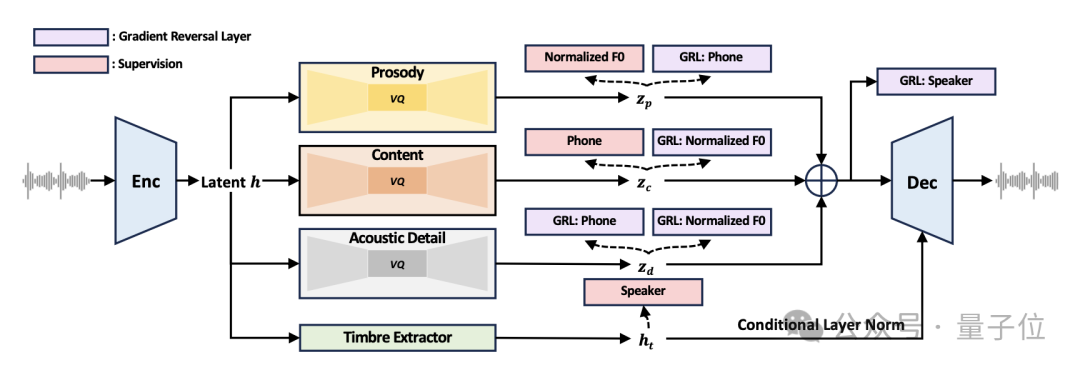
FACodec的核心在于将复杂的语音波形转换为多个解耦子空间,这些子空间分别代表语音的不同属性,如内容、韵律、音色和声学细节。这样的设计使得FACodec能够更精准地控制和重构语音的各个方面,从而生成更自然、更高质量的语音输出。
FACodec通过以下几个关键组件实现其功能:
语音编码器:将原始的语音数据转化到表征空间,为后续的属性分解做准备。
音色提取器:专门负责提取语音的音色属性,即说话人的独特声音特征。
分解向量量化器:分别针对内容、韵律和声学细节,将这些属性转换成量化的、离散的表示形式。这一步是实现属性间解耦的关键。
语音解码器:根据从分解向量量化器得到的各属性表示,重构出高质量的语音波形。
此外,FACodec还结合了多种训练技术,以优化这些组件的性能和相互作用,确保生成的语音既自然又符合目标属性。
这种属性分解和重构的方法不仅简化了TTS对语音表示的建模过程,而且大大增强了语音合成的可控性和灵活性。用户可以通过调整不同的语音属性来生成满足特定需求的语音,如调整音色以模仿特定的说话人,或修改韵律以改变语音的情感表达。
目前语音开源项目Amphion已经支持NaturalSpeech 3的核心组件FACodec,并且已发布预训练模型。
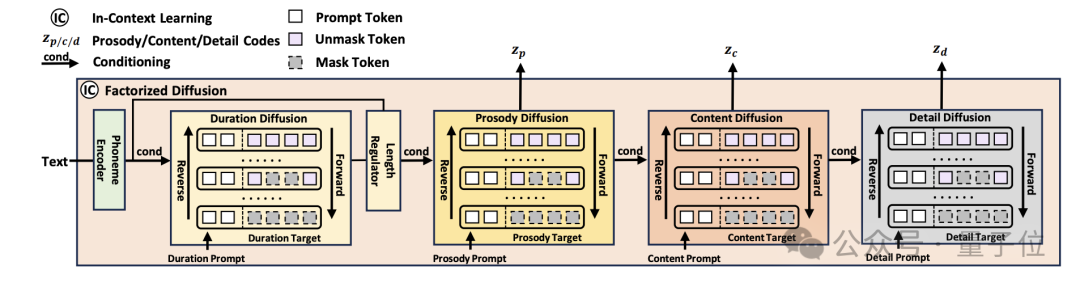
NaturalSpeech 3的另一个创新之处在于其对属性分解扩散模型的采用,这种方法为语音合成带来了新的维度。
通过使用统一的扩散模型并合集多个扩散阶段,分别针对音素持续时间、韵律、内容和声学细节进行建模,NaturalSpeech 3能够更细致且有效地控制语音生成的各个方面。
与传统的语音合成方法相比,这种模块化的扩散模型架构提供了更高的灵活性和精确度,使得生成的语音既自然又富有表现力。
在这种架构中,音色作为一种重要的语音属性,其特征可以直接从提供给系统的提示(prompt)中提取,而不需要像其他属性那样通过独立的模型来建模。
这种设计简化了系统的复杂度,同时保证了音色的一致性和自然性。每个扩散模型只需要接受与其对应的语音属性相关的提示,从而实现了对特定语音属性的精准控制和可控性生成。
SOTA的语音合成效果:经过大量的实验验证,NaturalSpeech 3在语音质量、相似性、韵律和可懂度方面均超越了现有最先进的TTS系统。特别是,在LibriSpeech测试集上,NaturalSpeech 3已经达到了人类录音水平。
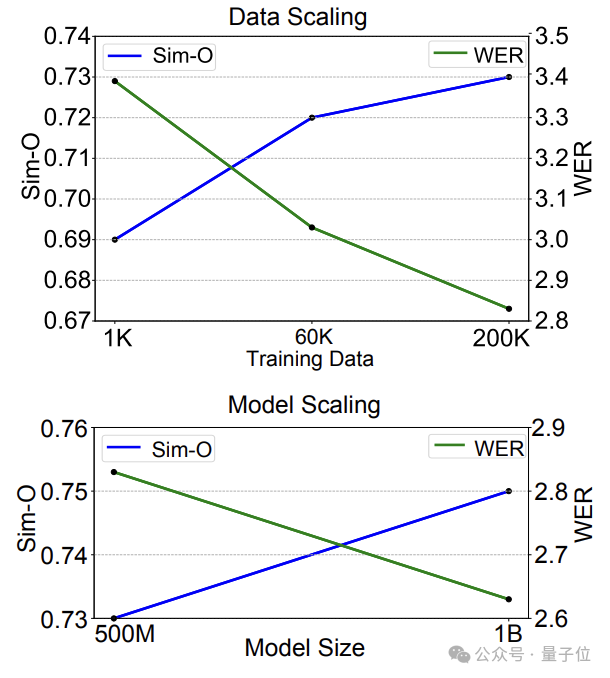
Data/Model Scaling:值得一提的是,NaturalSpeech 3还将模型拓展到 1B 大小、数据量拓展到 20万小时左右,在提升合成语音质量,相似度,可理解性方等面的令人期待的结果,展示了较强的Scaling能力。
该研究团队正在招聘以下方向的研究员和研究实习生:
1)音频(语音/音乐/音效)理解和生成;
2)视频(虚拟人/通用视频)理解和生成;
3)大模型。
研究员工作地点:西雅图;研究实习生工作地点:北京。
如有意向请联系:谭旭(Xu Tan,xuta@microsoft.com)。
传送门:
[1]NaturalSpeech 3 论文链接: https://arxiv.org/abs/2403.03100
[2]NaturalSpeech 3 Demo演示: https://speechresearch.github.io/naturalspeech3
[3]FACodec预训练模型: https://huggingface.co/spaces/amphion/naturalspeech3_facodec
[4]FACodec代码: https://github.com/open-mmlab/Amphion/tree/main/models/codec/ns3_codec

