
- 1Linux下安装mysql8.0(以rpm包安装)_mysql8 rpm安装
- 2软件工程复试面试问题总结(一)_东华大学软件工程复试问题重要程度汇总
- 3[数据结构-6] 详解队列及其两种储存结构的实现_如图所示:当front 和rear被封装在一起作为头节点后,以链接方式存储的队列在进行插
- 4深度学习相关论文_深度学习模型(如resnet、yolo)论文素材
- 5Spark入门(Python版)_pyspark 命令行模式
- 6idea创建空项目时不显示目录结构的解决方法_idea如何显示目录结构
- 7PHY RGMII Interface Timing注意事项_rgmii-rxid
- 8【力扣】203、环形链表 II
- 9C++编译链接_c++ 编译链接
- 10redis的lua脚本
Mamba v2诞生:3 SMA与Mamba-2
赞
踩
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
Mamba的出现为带来了全新的思路和可能性,通过对结构化半可分离矩阵的各种分解方法的理论研究,可以将状态空间模型SSM与注意力机制Attention的变种进行紧密关联,进而提出一种状态空间对偶SSD的理论框架。
状态空间对偶使得研究人员设计一种新的架构 (Mamba-2),其核心层是对 Mamba(选择性SSM)进行改进,速度提高了2-8倍,同时在语言建模方面能够保持对Transformers的压力。
在开始之前提醒下读者,在Mamba不再真正认为SSM是连续的。事实上,正如在原始论文的讨论,Mamba与S4在对不同类型的数据进行建模方面进行了权衡:S4 是一种连续时间模型,擅长对连续数据进行建模,例如音频波形和像素级视觉等感知信号。Mamba S6是一种离散时间模型,擅长对离散数据进行建模,例如语言等标记化数据。
线性注意力机制代表着在注意力运算时去掉了softmax。这点在线性RNN<要是忘记了,记得温习下!>已经讲过了。

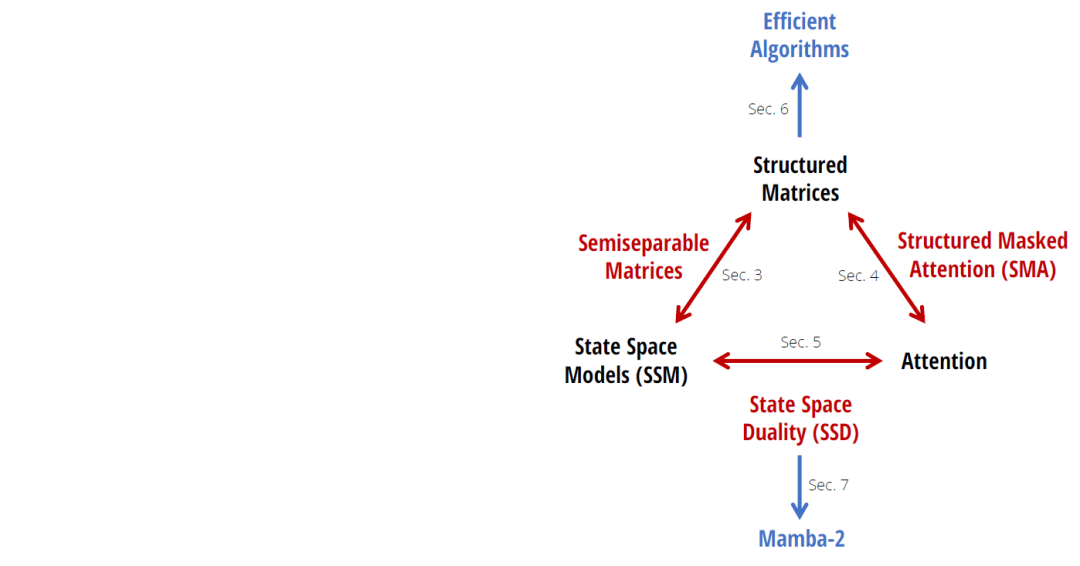
张量收缩
张量收缩这个词一时之间很难解释清楚,后续开专题介绍。大白话的意思就是多个高维的矩阵按照某种方式转化(相乘)压缩到一定的维度,其实传统的矩阵乘法也是其中的一种。
假如用图标来表示,那么如下为各种维度的张量表示:
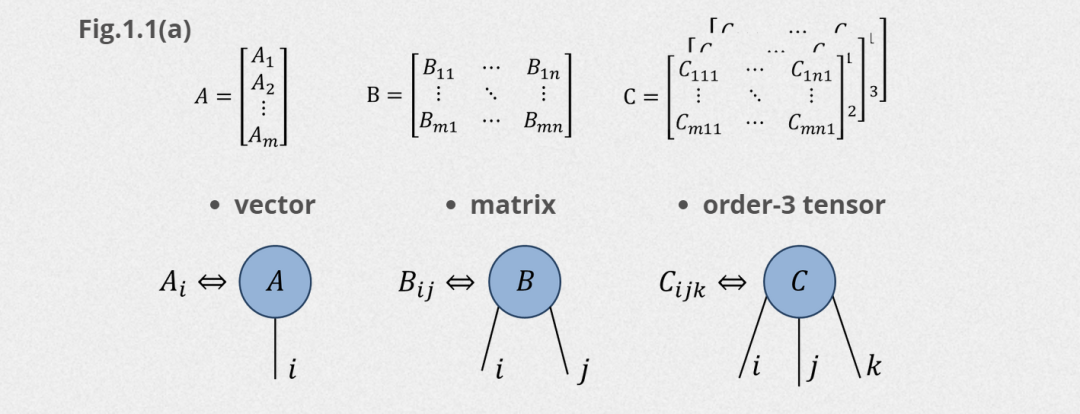
那么多个矩阵之间的相乘就可以用下面的图标进行简化表示:
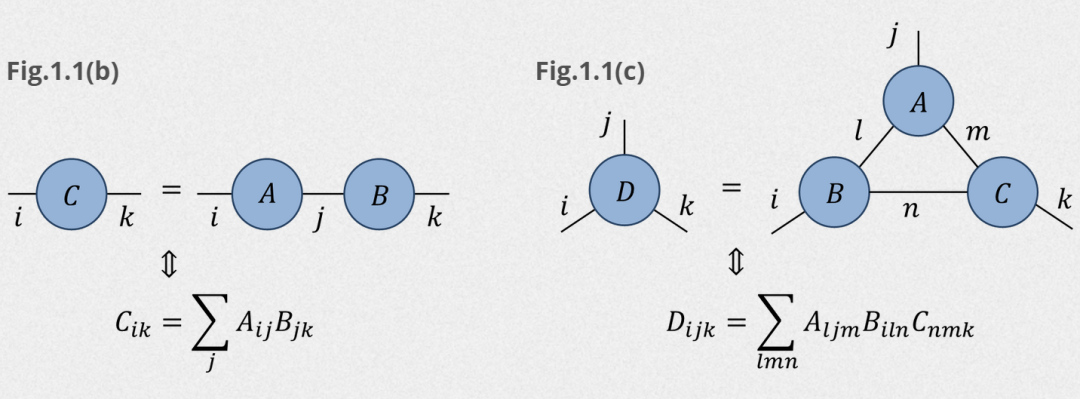
张量收缩在高维张量中使用广泛,例如下面4维的矩阵AB之间要按照某个维度进行压缩,整个过程如下:
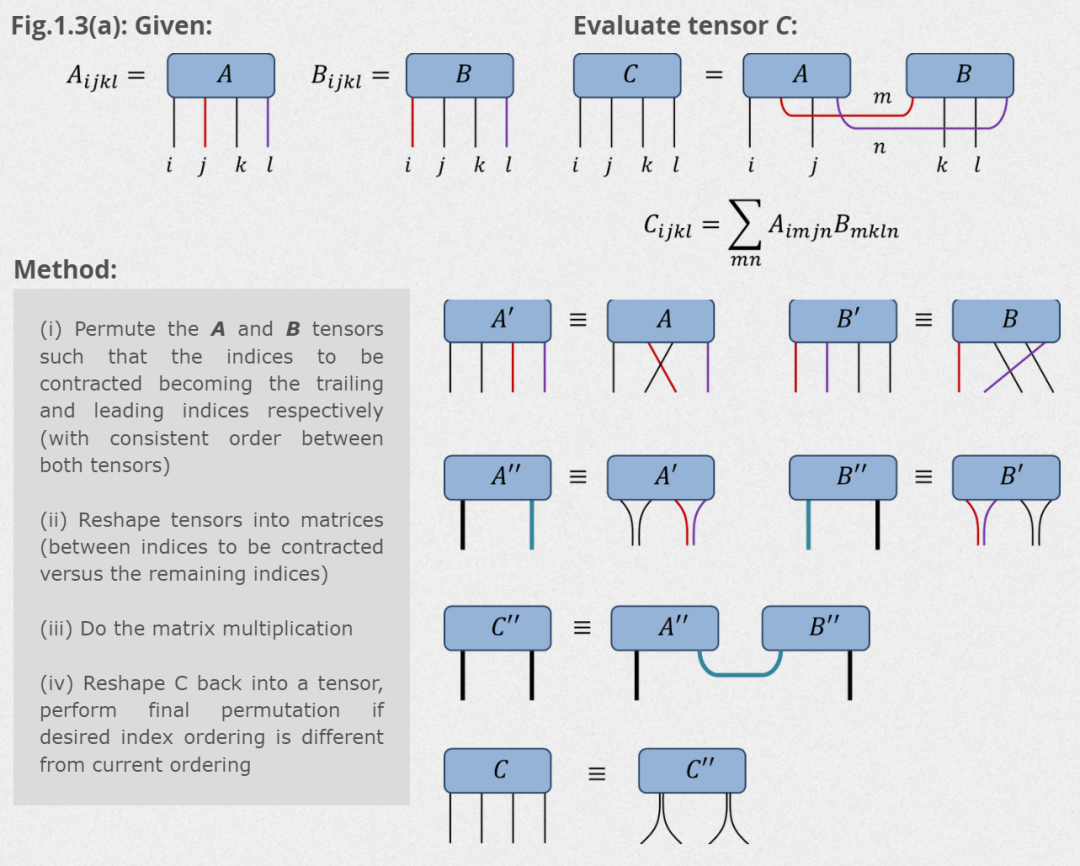
d = 10A = np.random.rand(d,d,d,d) B = np.random.rand(d,d,d,d)Ap = A.transpose(0,2,1,3); Bp = B.transpose(0,3,1,2)App = Ap.reshape(d**2,d**2); Bpp = Bp.reshape(d**2,d**2)Cpp = App @ Bpp; C = Cpp.reshape(d,d,d,d)当然也可以使用numpy的函数einsum,
einsum("some string describing an operation", tensor_1, tensor_2, ...) 。
例如输入,不用这个函数的话,你只能这么写:
n = A.shape[0]out = ( A[t.arange(n), t.arange(n), :, None, None] * B.permute(2, 1, 0)[:, :, :, None] * C[None, None, None, :]).sum(1,3).T若采用einsum函数,则:
out = t.einsum("iij,kji,l->ki", A, B, C)
SMA
Structured Masked Attention
结构化掩蔽注意力 (SMA)(或简称为结构化注意力)被定义为
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

