
- 1C# & Unity 面向对象补全计划 之 访问修饰符
- 2一文掌握IPD体系的核心精华及MM、RM和小IPD流程如何运作_华为mm流程
- 3Selenium与WebDriver:Errno 8 Exec格式错误的多种解决方案_[errno 8] exec format error selenium
- 4C++类对象进行排序_c++类属性排序
- 5Tuxera NTFS for Mac,mac硬盘读取软件怎么使用呢_paragon ntfs for mac和texure 哪个好?
- 6WiFi模块ESP8266同阿里物联网云平台连接(超详细)_esp8266连接阿里云
- 7九州未来深度参与元宇宙标准会议周
- 8蓝牙新篇章:WebKit的Web Bluetooth API深度解析_web 获取蓝牙数据
- 9unity2D游戏开发18导出游戏
- 10约束式编程学习笔记[3] 约束求解算法实例 完全性证明框架 Term Equations及解法及证明_约束求解器公式
Google Gemma2 2B:语言模型的“小时代”到来?
赞
踩
北京时间8月1日凌晨(当地时间7月31日下午),Google发布了其Gemma系列开源语言模型的更新,在AI领域引发了巨大的震动。Google Developer的官方博客宣布,与6月发布的27B和9B参数版本相比,新的2B参数模型在保持卓越性能的同时,实现了“更小、更安全、更透明”的三大突破。

Gemma系列语言模型正在引领着一场“小”的技术革命
Gemma 2 2B 简介
Gemma 2 2B版本,通过蒸馏学习技术得到的”小“模型,不仅优化了NVIDIA TensorRT-LLM库,更在边缘设备到云端的多种硬件上展现出优秀的运行能力。更重要的是,较小的参数量大大降低了研究和开发的门槛,使得Gemma 2 2B能够在Google Colab的免费T4 GPU服务上流畅运行,为用户带来了灵活且成本效益高的解决方案。
Gemma 2 不仅有了更轻量级「Gemma 2 2B」版本,还构建一个安全内容分类器模型「ShieldGemma」和一个模型可解释性工具「Gemma Scope」。具体如下:
- Gemma 2 2B 具有内置安全改进功能,实现了性能与效率的强大平衡;
- ShieldGemma 基于 Gemma 2 构建,用于过滤 AI 模型的输入和输出,确保用户安全;
- Gemma Scope 提供对模型内部工作原理的无与伦比的洞察力。
Google 推出了 Gemma 系列模型,模型设计更为高效和用户友好。Gemma 模型可以轻松运行在各种日常设备上,如智能手机、平板电脑和笔记本电脑,无需特殊硬件或复杂优化。
Gemma 2 2B版本的特点
- 技术: 通过蒸馏学习技术优化
- 性能: 优化了NVIDIA TensorRT-LLM库,在同等规模下提供同类最佳性能,超越同类其他开源模型;
- 部署灵活且经济高效:可在各种硬件上高效运行,从边缘设备和笔记本电脑到使用云部署如 Vertex AI 和 Google Kubernetes Engine (GKE) 。为了进一步提高速度,该模型使用了 NVIDIA TensorRT-LLM 库进行优化,并可作为 NVIDIA NIM 使用。此外,Gemma 2 2B 可与 Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp 以及即将推出的 MediaPipe 无缝集成,以简化开发;
- 开源且易于访问:可用于研究和商业应用,由于它足够小,甚至可以在 Google Colab 的 T4 GPU 免费层上运行,使实验和开发比以往更加简单。
业界反响与开源趋势
在Gemma 2 2B发布后,业界反响热烈。GAIR硅谷自动驾驶峰会(2018)嘉宾、UC Berkeley教授Anca Dragan (推特:@ancadianadragan )第一时间发表多条推文对Gemma 2的SAE机制进行了解读。她表示,如此大的计算资源使得纯粹的学术研究机构难以参与其中,但之后学术界会进一步关注如何利用Gemma Scope的SAE机制来提高模型的解释性和AI的安全性。

计算语言学家、DAIR.AI的联合创始人Elvis Saravia (推特:@omarsar0 )也在第一时间对Gemma 2 2B进行了测试,对Gemma 2的SAE机制给予了高度评价。

随着2024年的到来,大模型的光环似乎正在逐渐褪去,而如何将模型做小,正成为今年语言模型发展的重要趋势。2023年的“百模大战”虽然激烈,但大模型的商业价值有限;相比之下,小模型在成本和效率上展现出了更大的优势。
甚至“暴力美学”的倡导者、OpenAI CEO Sam Altman也早早承认,“大模型”时代可能走向结束,未来我们会通过其他方式来改进它们。

在技术上,通过如蒸馏压缩和参数共享等手段,可以显著降低模型规模同时保持性能。Gemma 2 2B版本的亮眼表现,无疑为下一步的大模型研究提供了重要方向。
Google的另一系列语言模型Gemini,以其不公开源代码的特性,专为Google自家产品及开发者使用,与Gemma系列形成鲜明对比。而META的Llama系列则高举“开源”大旗,向OpenAI的GPT系列发起了强有力的挑战。
在过去一年中,OpenAI的GPT系列一直是这个领域无可争议的“王者”,在LMsys的“大模型竞技场”,GPT-4及其后续版本GPT4-o在大多数时间一直牢牢占据第一的位置,仅有一次被Claude 3.5 Sonnet短暂超越。
但在2024,开始有越来越多的模型向GPT系列发起了冲击。除了Google的Gemini和Gemma系列外,另一有力竞争者是META的Llama系列。与OpenAI的闭源(OpenAI也因此称为"Close AI")路径不同,META的Llama系列则是高举开源大旗的代表。
就在数天前,Meta CEO马克·扎克伯格(Mark Zuckerberg)在“史上最强开源模型”Llama 3.1发布之际,发表了题为“Open Source AI is the Path Forward”的公开信,强调了开源AI在推动AI发展中的重要性。

Gemma 2的发布,不仅是Google在AI领域的一次自我超越,更是对整个行业的一次挑战。无论是“小型化”还是“开源”,都预示着2024年将是语言模型研究的又一个春天。让我们拭目以待,Gemma 2代表的“小模型”将如何重塑AI的未来。
Gemma 2 2B的性能表现
Gemma 2 家族新增 Gemma 2 2B 模型,备受大家期待。谷歌使用先进的 TPU v5e 硬件在庞大的 2 万亿个 token 上训练而成。这个轻量级模型是从更大的模型中蒸馏而来,产生了非常好的结果。由于其占用空间小,特别适合设备应用程序,可能会对移动 AI 和边缘计算产生重大影响。
大模型评测机构LMsys上,Gemma 2 2B的发布也迅速引起了广泛关注。LMsys第一时间转发了Google Deepmind的推文,对超越了参数量10倍于Gemma 2 2B版本的“老前辈”GPT-3.5-Tubro表示祝贺。谷歌的 Gemma 2 2B 模型在 Chatbot Arena Elo Score 排名中胜过大型 AI 聊天机器人,展示了小型、更高效的语言模型的潜力。下图表显示了 Gemma 2 2B 与 GPT-3.5 和 Llama 2 等知名模型相比的卓越性能,挑战了「模型越大越好」的观念。

对于前段时间很多大模型都翻了车的「9.9 和 9.11 谁大」的问题,Gemma 2 2B 也能轻松拿捏。


图源:https://x.com/tuturetom/status/1818823253634564134
模型大小与性能的讨论
从谷歌 Gemma 2 2B 的强大性能也可以看到一种趋势,即「小」模型逐渐拥有了与更大尺寸模型匹敌的底气和效能优势。知名人工智能科学家、Lepton AI 创始人贾扬清提出了一种观点:大语言模型(LLM)的模型大小是否正在走 CNN 的老路呢?
在 ImageNet 时代,看到参数大小快速增长,然后我们转向了更小、更高效的模型。这是在 LLM 时代之前,我们中的许多人可能已经忘记了。
- 大型模型的曙光:我们以 AlexNet(2012)作为基线开始,然后经历了大约 3 年的模型大小增长。VGGNet(2014)在性能和尺寸方面都可称为强大的模型。
- 缩小模型:GoogLeNet(2015)将模型大小从 GB 级缩小到 MB 级,缩小了 100 倍,同时保持了良好的性能。类似工作如 SqueezeNet(2015)和其他工作也遵循类似的趋势。
- 合理的平衡:后来的工作如 ResNet(2015)、ResNeXT(2016)等,都保持了适中的模型大小。请注意,我们实际上很乐意使用更多的算力,但参数高效同样重要。
- 设备端学习?MobileNet(2017)是谷歌的一项特别有趣的工作,占用空间很小,但性能却非常出色。上周,我的一个朋友告诉我「哇,我们仍然在使用 MobileNet,因为它在设备端具有出色的特征嵌入通用性」。是的,嵌入式嵌入是实实在在很好用。
LLM 会遵循同样的趋势吗?

Gemma 2模型技术创新点
ShieldGemma:最先进的安全分类器

技术报告:https://storage.googleapis.com/deepmind-media/gemma/shieldgemma-report.pdf
ShieldGemma 是一套先进的安全分类器,旨在检测和缓解 AI 模型输入和输出中的有害内容,帮助开发者负责任地部署模型。
ShieldGemma 专门针对四个关键危害领域进行设计:
- 仇恨言论
- 骚扰
- 色情内容
- 危险内容

这些开放分类器是对负责任 AI 工具包(Responsible AI Toolkit)中现有安全分类器套件的补充。借助 ShieldGemma,用户可以创建更加安全、更好的 AI 应用。
SOTA 性能:作为安全分类器,ShieldGemma 已经达到行业领先水平;
规模不同:ShieldGemma 提供各种型号以满足不同的需求。2B 模型非常适合在线分类任务,而 9B 和 27B 版本则为不太关心延迟的离线应用程序提供了更高的性能。
如下表所示,ShieldGemma (SG) 模型(2B、9B 和 27B)的表现均优于所有基线模型,包括 GPT-4。

Gemma Scope:让模型更加透明
Gemma Scope 旨在帮助 AI 研究界探索如何构建更易于理解、更可靠的 AI 系统。其为研究人员和开发人员提供了前所未有的透明度,让他们能够了解 Gemma 2 模型的决策过程。Gemma Scope 就像一台强大的显微镜,它使用稀疏自编码器 (SAE) 放大模型的内部工作原理,使其更易于解释。
新模型包含400多个SAEs,用于分析 Gemma 2 2B 和 9B 模型的每一层和子层,为研究人员提供了理解语言模型内部工作原理的强大工具。Google Deepmind 语言模型可解释性团队则是通过官方博客对 Gemma Scope 进行了更多的技术分析。该团队称,Gemma Scope旨在帮助研究人员理解Gemma 2语言模型的内部工作原理,推动可解释性研究,构建更强大的系统,开发模型幻觉保护措施,防范自主AI代理的风险。稀疏自动编码器(SAE)将作为“显微镜”,帮助研究人员观察语言模型内部。
尽管Gemma 2 2B为开发者提供了一种灵活且成本效益高的解决方案,但在训练阶段仍然需要投入大量的计算资源。根据Deepmind博客,Gemma Scope的训练使用了约相当于15%的Gemma 2 9B训练计算资源(或GPT3的22%训练计算资源)。
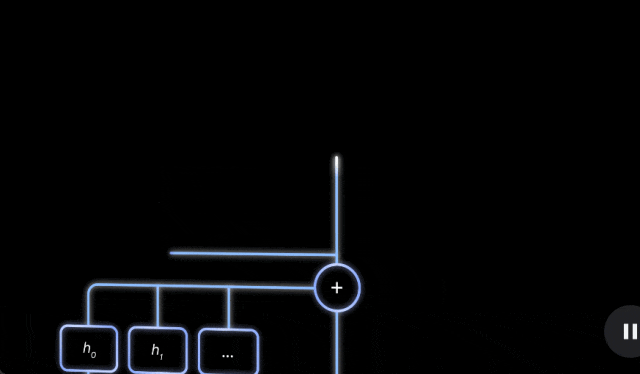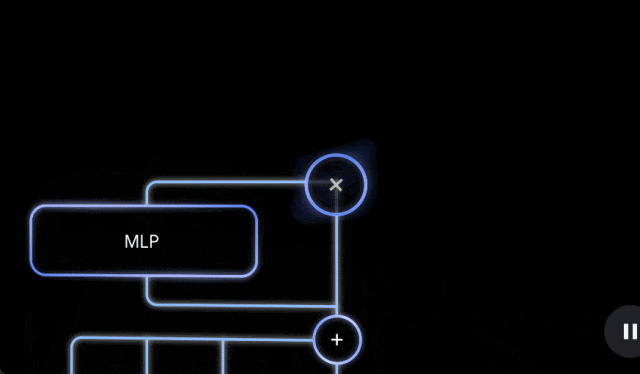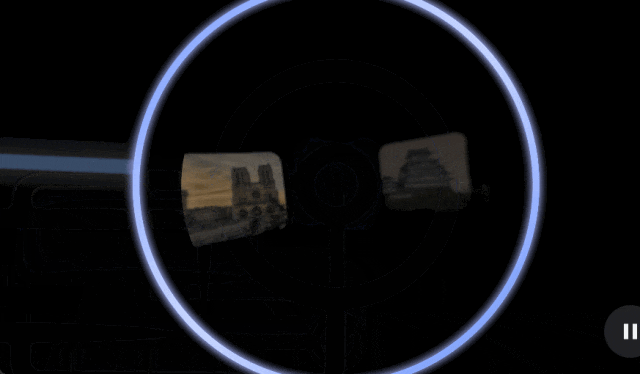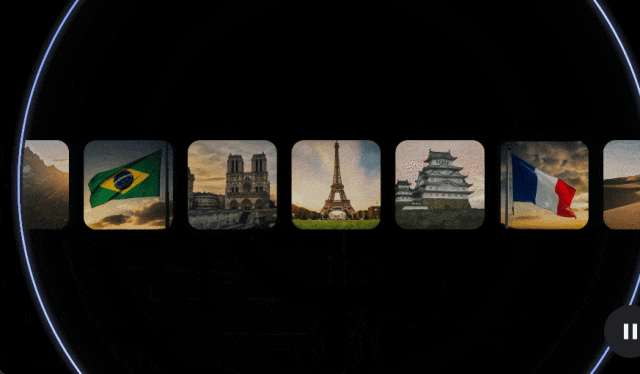
Gemma Scope 技术报告:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdf
SAE 可以帮助用户解析 Gemma 2 处理的那些复杂信息,将其扩展为更易于分析和理解的形式,因而研究人员可以获得有关 Gemma 2 如何识别模式、处理信息并最终做出预测的宝贵见解。
以下是 Gemma Scope 具有开创性的原因:
- 开放的 SAE:超过 400 个免费 SAE,涵盖 Gemma 2 2B 和 9B 的所有层;
- 交互式演示:无需在 Neuronpedia 上编写代码即可探索 SAE 功能并分析模型行为;
- 易于使用的存储库:提供了 SAE 和 Gemma 2 交互的代码和示例。‘
Gemma 2 2B的获取与试用
用户可以从 Kaggle、Hugging Face、Vertex AI Model Garden 下载模型权重。用户还可以在 Google AI Studio 中试用其功能。
下载权重地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
- 试用: 在Google AI Studio中试用其功能
Gemma 2 2B 的出现挑战了人工智能开发领域的主流观点,即模型越大,性能自然就越好。复杂的训练技术、高效的架构和高质量的数据集可以弥补原始参数数量的不足。这一突破可能对该领域产生深远的影响,有可能将焦点从争夺越来越大的模型转移到改进更小、更高效的模型。
Gemma 2 2B 的开发也凸显了模型压缩和蒸馏技术日益增长的重要性。通过有效地将较大模型中的知识提炼成较小的模型,研究人员可以在不牺牲性能的情况下创建更易于访问的 AI 工具。这种方法不仅降低了计算要求,还解决了训练和运行大型 AI 模型对环境影响的担忧。

